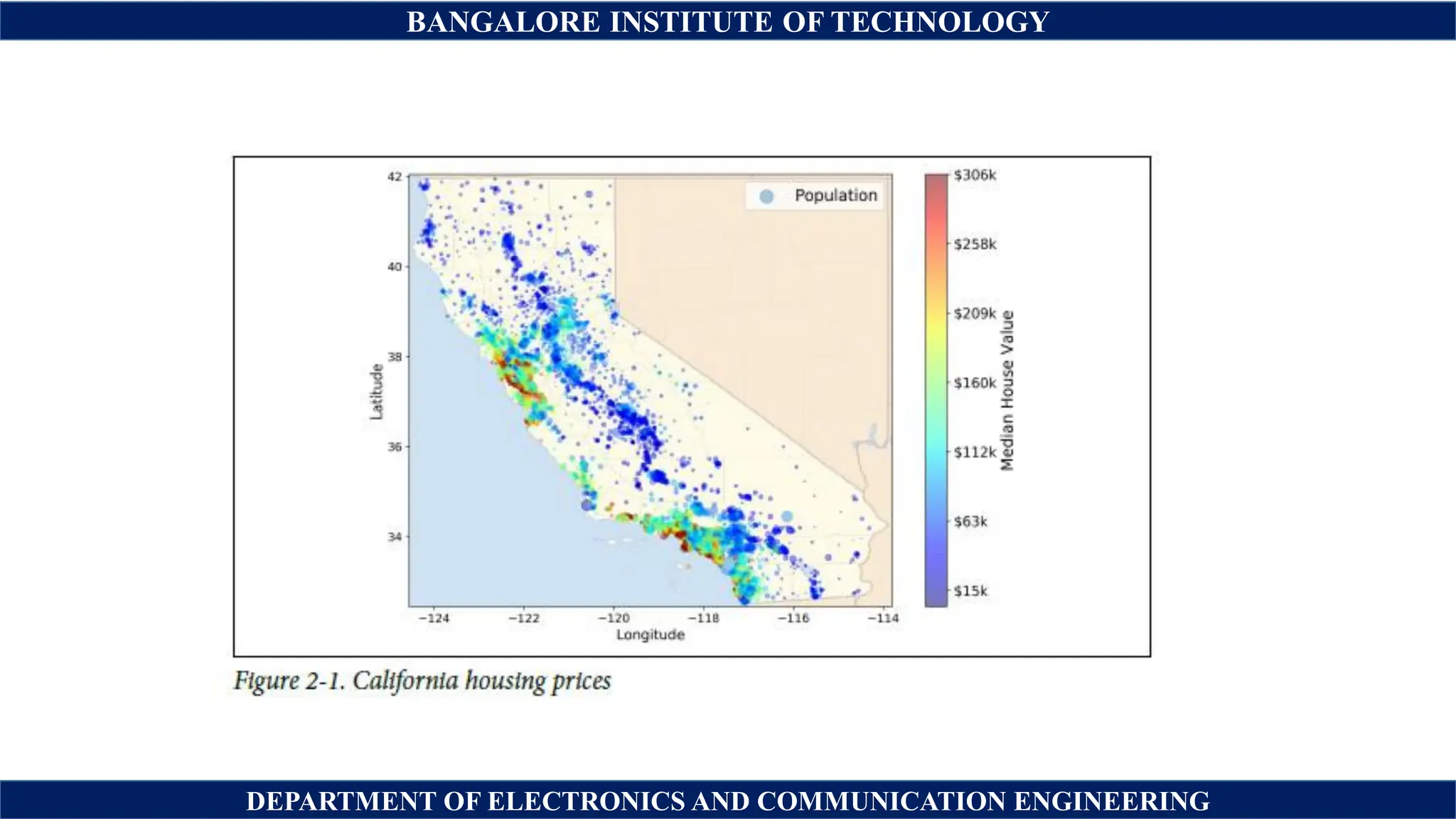
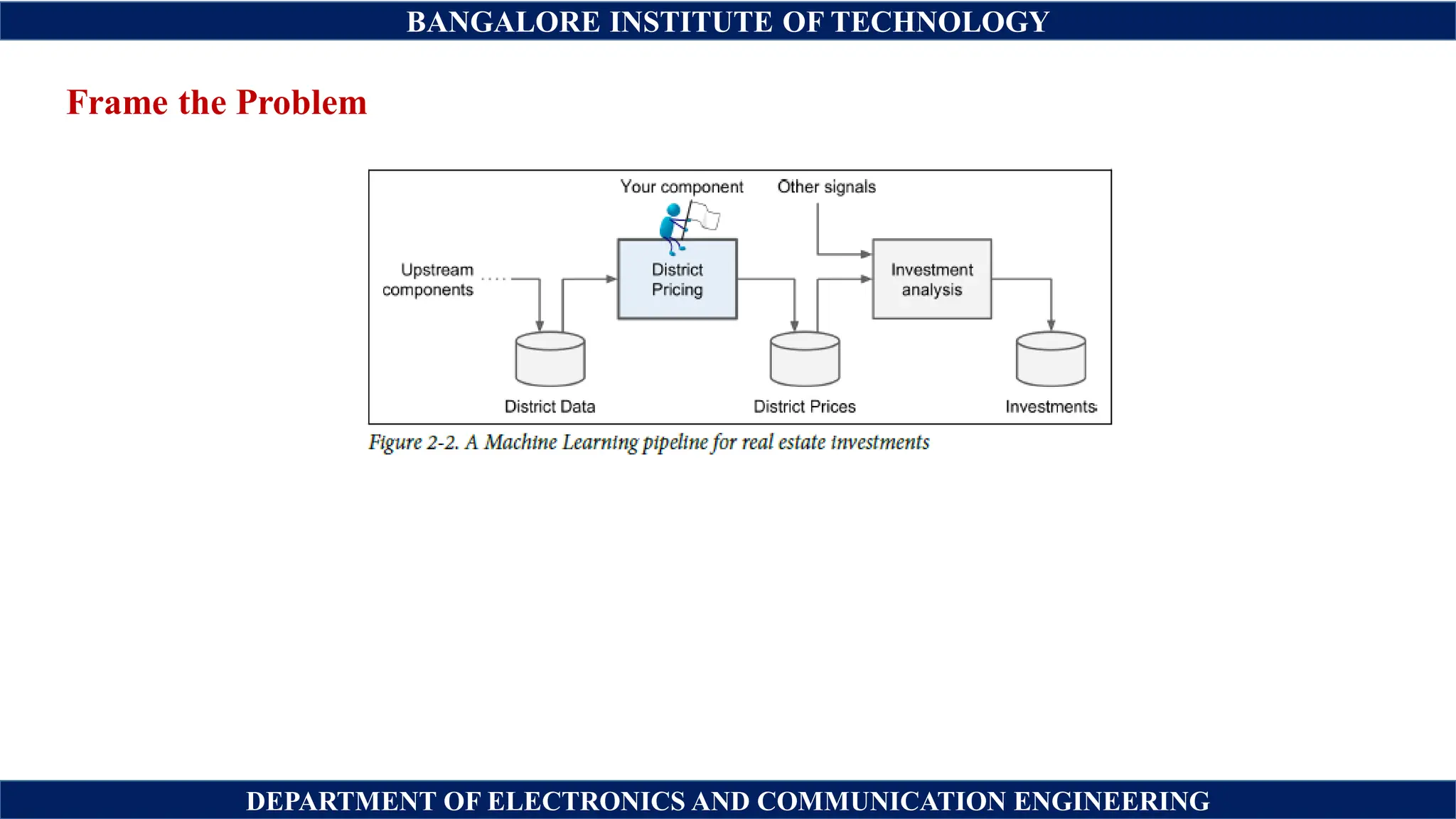
The document outlines a machine learning project focused on predicting California housing prices using the 1990 census dataset, emphasizing data preprocessing, feature selection, and model training. It describes the steps for building a predictive model, including data cleaning, handling categorical attributes, and evaluating model performance. The document also discusses the importance of proper assumptions, data pipelines, and monitoring throughout the machine learning process.






















![BANGALORE INSTITUTE OF TECHNOLOGY
DEPARTMENT OF ELECTRONICS AND COMMUNICATION ENGINEERING
Handling Text and Categorical Attributes
Handling Text and Categorical Attributes:
1.Why It’s Important:
1. Machine learning algorithms typically cannot work directly with text or categorical data, so they must be converted
into numerical representations before feeding them into the model.
2.Types of Categorical Data:
1. Nominal: Categories with no particular order (e.g., city names, product types).
2. Ordinal: Categories with a meaningful order (e.g., education level: high school < college < graduate).
3.Methods for Handling Categorical Data:
1. Label Encoding:
1. For ordinal categorical variables, label encoding assigns a unique integer to each category.
2. Example: If you have an education column with values ["High School", "College", "Graduate"], you could
convert them to [0, 1, 2].](https://image.slidesharecdn.com/module5-250113064645-5466fd9d/75/Module-5-pdf-ISML-ISML-VTU-syallabus-VTU-26-2048.jpg)