This document discusses relational algebra and operations on relational data. It covers unary operations like select and project, binary operations like join and cartesian product, and set operations like union, intersection, and difference. Select chooses tuples that satisfy a condition. Project selects certain attributes. Join combines related tuples from two relations based on a join condition. Cartesian product generates all possible combinations of tuples. Key concepts discussed include join selectivity, equijoin, natural join, and theta join.



![Relational Calculus and Relational Algebra
● Relational Calculus and relational algebra
○ Both originally proposed by Edgar F. Codd in the early 1970s
○ Formally specify operations on relational data
○ Logically equivalent: Any query specified in r. calculus can be specified in r. Algebra; vice versa
● Relational calculus
○ Tuple relational calculus: proposed Edgar F. Codd 1971
○ Domain relational calculus: proposed by by Michel Lacroix and Alain Pirotte 1977
○ Both are based on 1st order predicate logic (and set operations)
● Tuple Relational Calculus (TRC)
○ Specify what the tuples satisfied the conditions to be selected
○ Examples::
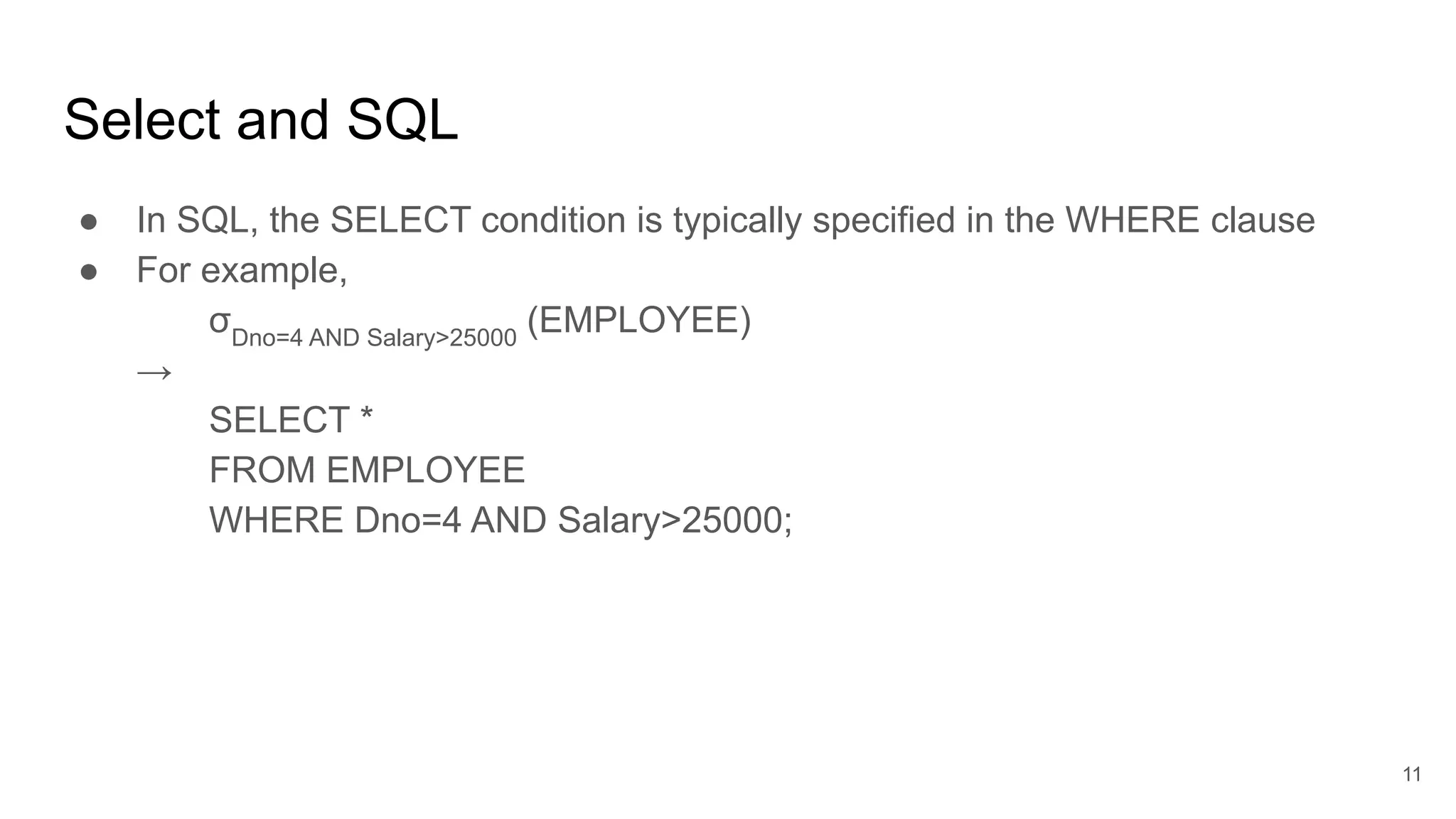
■ {t | t ∈ Employee and t[SALARY] > 60,000 }
● Equivalent to relational algebra: T ← σ SALARY> 60,000
(EMPLOYEE)
■ {t | ∃ r ∈ EMPLOYEE ( t[NAME] = r[NAME] ^ r[SALARY] > 60,000) }
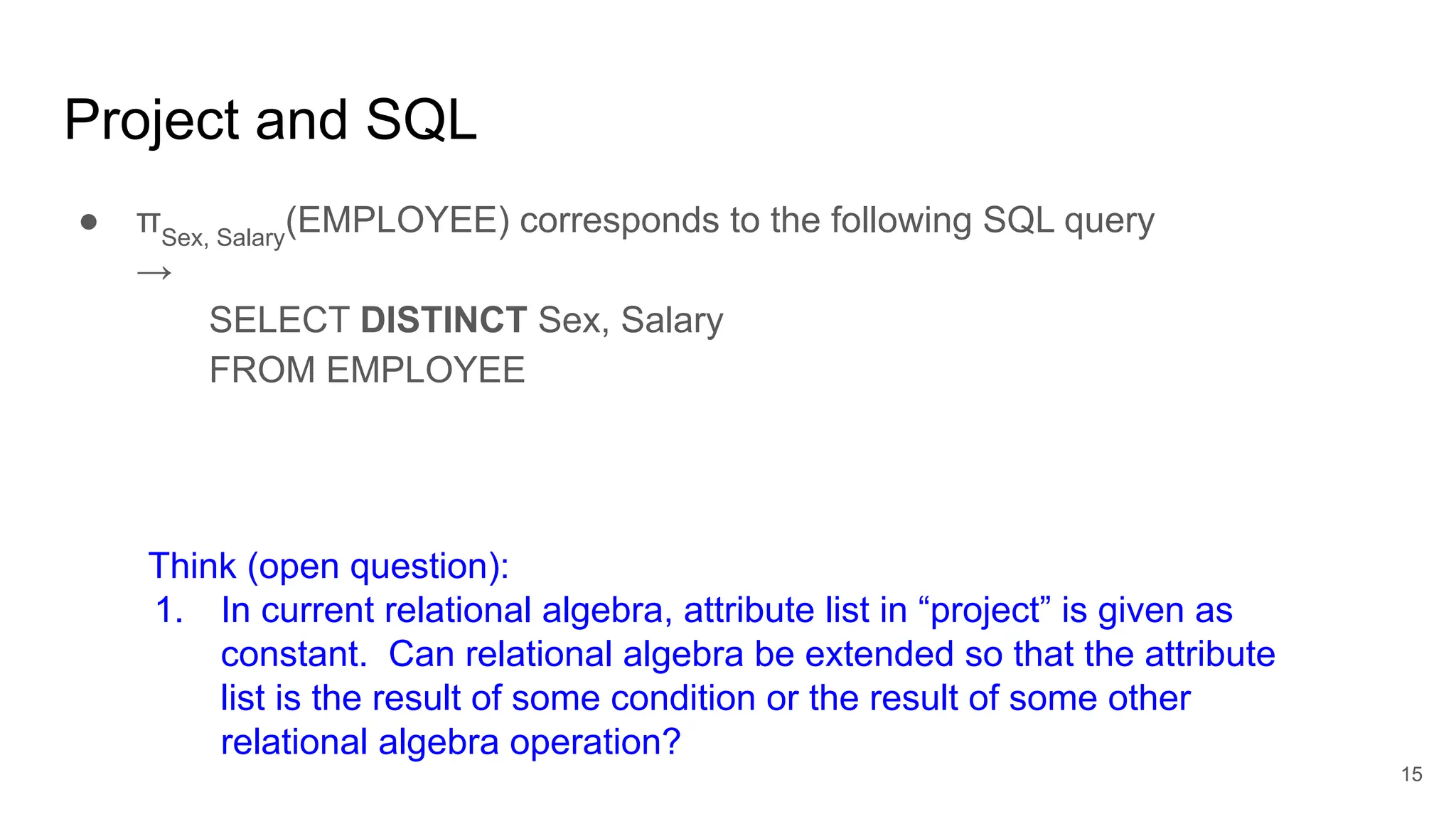
● Equivalent to relational algebra: ΠNAME
( σ SALARY> 60,000
(EMPLOYEE))
4](https://image.slidesharecdn.com/ml111lecture5relationalalgebraandadvancedsql-240220131112-b12f56e3/75/ML111-Lecture-5-Relational-Algebra-and-Advanced-SQL-pdf-4-2048.jpg)






























![Outer Union
● Union between two relations that have some, but not all, attributes in common
● Effect: The same as a FULL OUTER JOIN on the common attributes.
● Assume two relations R(X, Y) and S(X, Z) where attributes X, are union compatible
● Form: The outer union is of the form T(X, Y, Z) = Outer_union(R(X, Y), S(X, Z),
○ Note: the attributes that are union compatible are represented only once in the result, and those attributes that are not union
compatible, i.e., Y and Z, from either relation are also kept in the result relation T(X, Y, Z).
● Content:
○ Tuples t1 in R and t2 in S are said to match if t1[X] = t2[X]
○ Matched tuples will be combined into a single tuple in the result relation T, by taking Y from R and Z from S.
○ Tuples in R or S that have no match are padded with NULL values, and also put into the union.
● For example
○ OUTER UNION between two relations
■ STUDENT(Name, Ssn, Department, Advisor) and INSTRUCTOR(Name, Ssn, Department, Rank)
■ will be STUDENT_OR_INSTRUCTOR(Name, Ssn, Department, Advisor, Rank)
○ All the tuples from both relations are included in the result,
○ Tuples with the same (Name, Ssn, Department) combination will appear only once in the result.
○ Tuples appearing only in STUDENT will have a NULL for the Rank attribute,
○ Tuples appearing only in INSTRUCTOR will have a NULL for the Advisor attribute.
○ A tuple that exists in both relations, which represent a student who is also an instructor, will have values for all its attributes.
41](https://image.slidesharecdn.com/ml111lecture5relationalalgebraandadvancedsql-240220131112-b12f56e3/75/ML111-Lecture-5-Relational-Algebra-and-Advanced-SQL-pdf-41-2048.jpg)