Download as PDF, PPTX

![Software Development is a Social Activity
Source Code stands in direct relation to
organizational structure. [Conway:Datamation:1968]
Developers spent large part of work day
communicating with fellow developers. [Begel:ICSE:2010]
Wednesday, 11 April, 12 2](https://image.slidesharecdn.com/fse11-ds-nb-120411161031-phpapp02/75/Mining-Development-Repositories-to-Study-the-Impact-of-Collaboration-on-Software-Systems-2-2048.jpg)
![Communication is Critical for Success
Communication is the most referenced
problem in distributed development.
[Grinter:GROUP:1999]
[Bird:ACMComm:2009]
Wednesday, 11 April, 12 3](https://image.slidesharecdn.com/fse11-ds-nb-120411161031-phpapp02/75/Mining-Development-Repositories-to-Study-the-Impact-of-Collaboration-on-Software-Systems-3-2048.jpg)




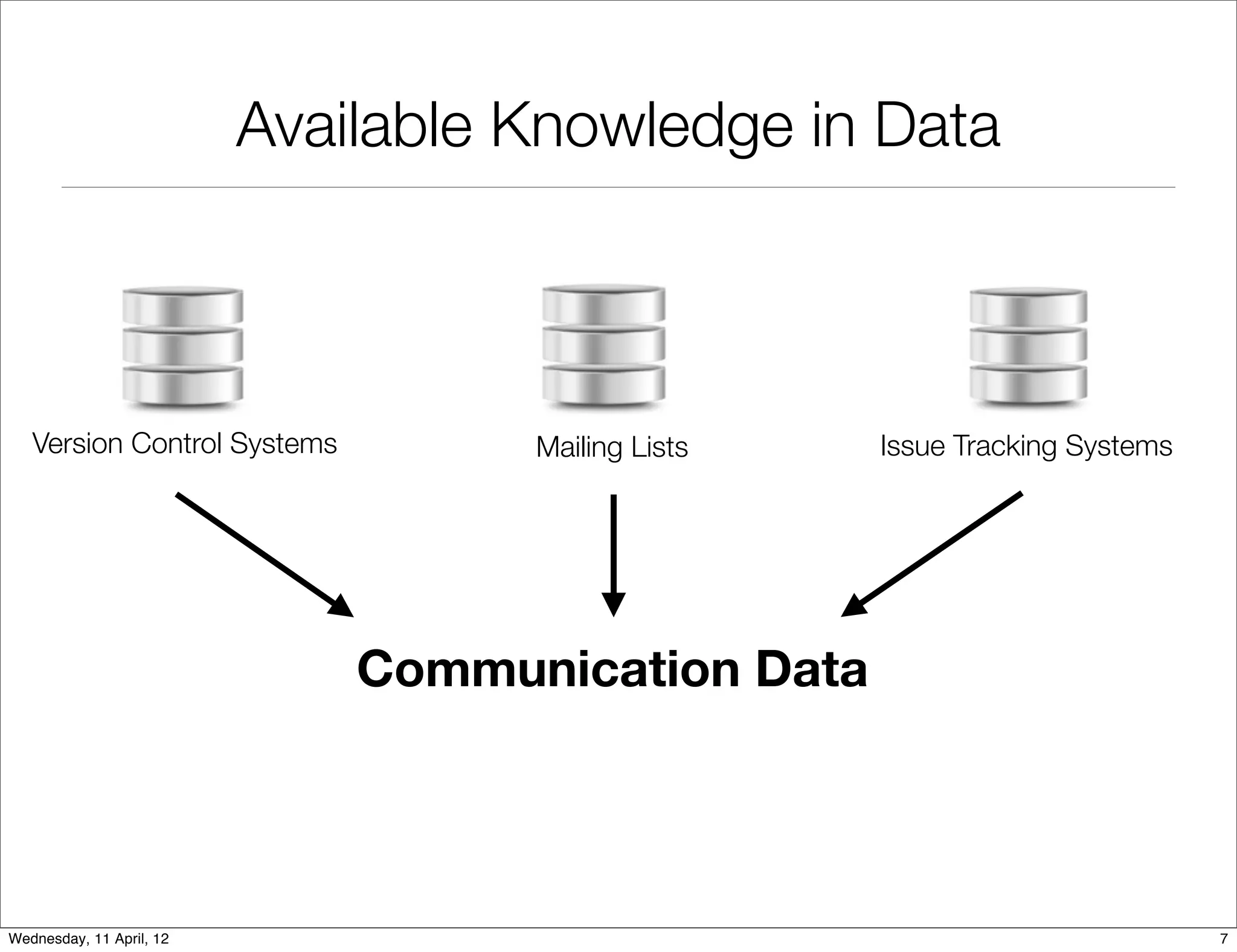
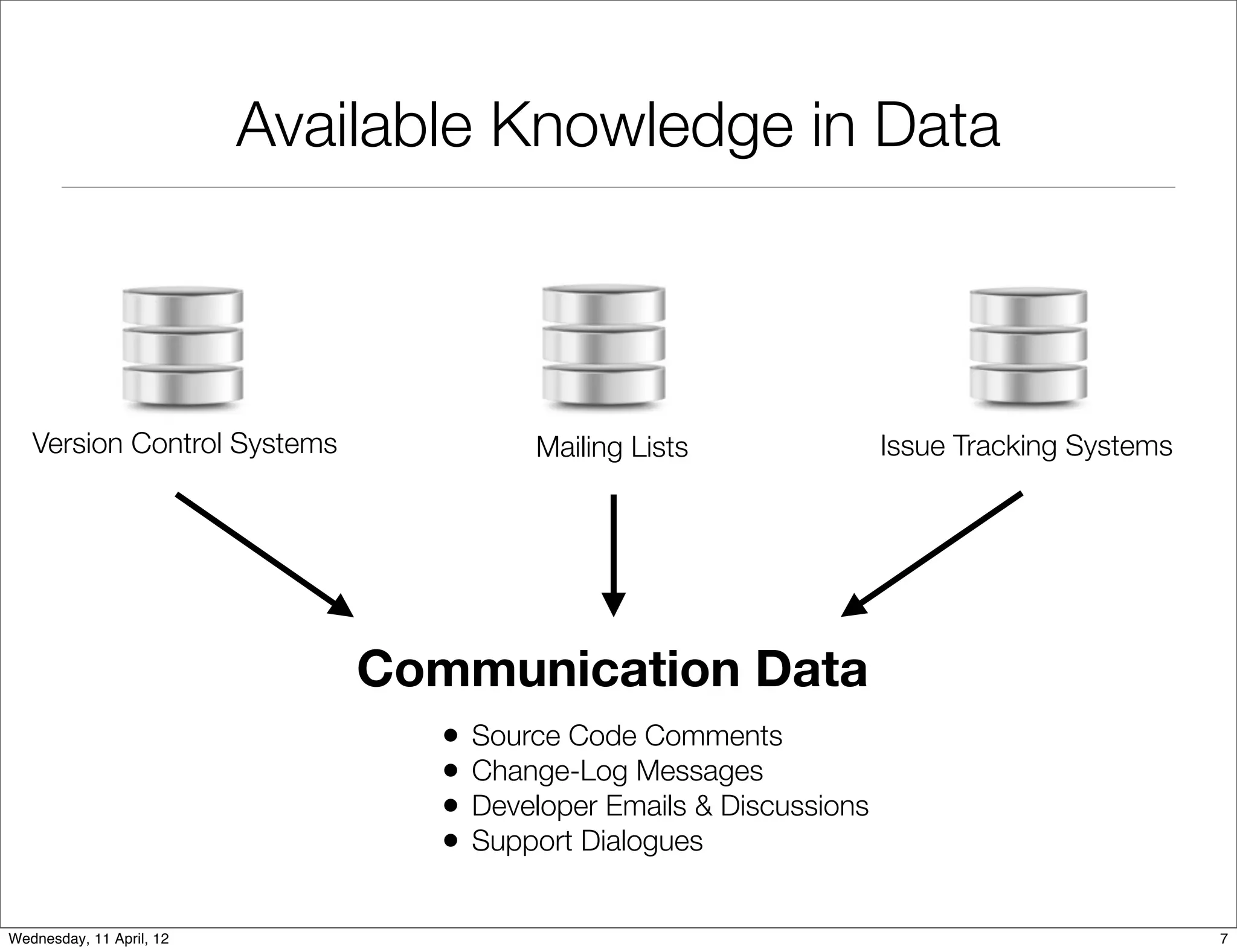
![Communication Data Exists
Mainly as Unstructured Data
In this report, you have defined a parameter named blocksize,
which is given a value of "7|D|1|D". In open script of data set,
there are below lines code:
<script begin>
token=Packages.java.util.StringTokenizer(params["blocksize"],"|");
vec=new Packages.java.util.Vector();
while(token.hasMoreTokens()){
vec.addElement(token.nextToken()); Eclipse #150222
}
params["DateRange"]=java.lang.Integer.parseInt(vec.elementAt(0));
</script end>
Since the value of params["blocksize"] is "7|D|1|D", vec.elementAt(0)
is "7", and then it can not be parsed to int value. In 1.0.1,
the value of params["blocksize"] might be 7|D|1|D, so it can be
parsed to int value of 7.
Extraction and processing of unstructured
data is challenging. [MUD:Workshop:2010]
Wednesday, 11 April, 12 8](https://image.slidesharecdn.com/fse11-ds-nb-120411161031-phpapp02/75/Mining-Development-Repositories-to-Study-the-Impact-of-Collaboration-on-Software-Systems-10-2048.jpg)
![Mining Collaboration Data
[Bettenburg:ICPC:2011]
chnical Information in Un structured Data
A Lightw eight Approach to Uncover Te
Michel Smidt
ams, Ahmed E. Hassan
Build ID: M20070212-1330
Nicolas Bettenburg, Bram Ad Dept. of Computer Science S)
gence Lab
Software Analysis and Intelli
Steps To Reproduce:
Una des a keytyinof Bremen
ng for "M1+S" (ie. Alt+
1. Create a plugin for eclipse that iversi bindione of the top level
inclu
Queen’s University
• Use Spellchecking
as mnem onic
as Bremen, for Help > any
where S is any letter that is used
the mnemonic Germ &So
ftware Updates,
menus. Since eclipse uses "S"
Kingston, Ontario, Canada Email: michelIDE nformatik.u
"S" is sufficient . @i ni-bremen.de
• Empirical validation
cs.queensu.ca
Email: {nicbet,bram,ahmed}@
2. Laun ch the plugin as part of Eclipse our example in #1)
the Help menu (to go along with
3. Press Alt+H to bring down
tes" is missing its mnemonic.
BUG: Notice "Software Upda
nication through email, cha
t, or
More information:
The code after "if (callback.is
Eclipse's MenuManager.
AcceleratorInUse(SWT
java removes the mnemonic,
.ALT | character))" inside
but it seems like Eclipse
level menumanagers like
• Improved on state of the art
Abstract—Developer commu
eratorInUse" only for top
should be checking "isAccel
s mostly of largely uns tructured
issue report comments consist
,Edit,...,Help, etc. :
rma-
File
text, mixed with technical info
data, i.e., natural language ons, source code
jargon, abbreviati
/* (non-Javadoc) onItem#update(java.l
ang.String)
tion such as project-specific
e.action.IContributi
cal artifacts * @see org.eclipse.jfac
patches, stack traces and identifiers. These techni */
of knowle dge on the technical tring property) {
represent a valuable source
public void update(S
applications from
= getItems();
tributionItem items[]
tem, with a wide range of
ICon
part of the sys vo-
s to creating project-specific items.length; i++) {
establishing traceability link en natural
for (int i = 0; i <
e-style delimiters betwe property);
cabularies. However, the fre
items[i].update(
hnical
tent make the mining of tec }
language and technical con general-purpose
t step towards a
[...]
artifacts challenging. As a firs information
}
technique to extractin g all kinds of technical
present a lightweight approach Any status on this bug?
from unstructured data, we guage text. Our
cal artifacts and natural lan
) [...]
for M6 (API) or M7 (non-API by a prototype
to untangle techni are I'd consider any contributions
nical information uncovered
g spell checking tools, which Figure 1. Examples of tech optionalposed Manager with API (Eclipse Platform
approach is based on existin in Menu in this paper.
and
ms and A 3.5 fix enta be to of the approach pro
available across platfor
that behaviour
implemwouldtion makeand to have the WorkbenchActionBuilder contributed
well-understood, fast, readily gh a
of technical artifacts. Throu
off by#208626).in 3.5,
default early gers turn it on
Bug ions contributed MenuMana
impartial to different kinds
and actionSets/editorAct
our approach
MenuManagers
demonstrate that in the correct place).
handcrafted benchmark, we
(if I can find MenuManagers
technical
is able to successfully uncover a wide range of team to make sure we understan
a
d what the
such, mining unstructured dat
I'd like us to work with the SWT
data.
way
sure that we aren't getting in the
information in unstructured or project-specific terms. As
correct platform behavior is, and make
ormation
onics) seems odd to me, in
ge analysis, unstructured dat
a, the exchange of inf
nt behavior (i.e. turning off mnem
is challenging: it is meant for
of that. The curre
Keywords-text mining, langua
we should fix it properly.
automated processing using
general. If we're going to fix this,
technical information. between humans, rather than
presents an example of tech-
computer machinery. Figure 1
I. I NT RO DU CT ION found in unstructured data.
nical information commonly
a unique history of design ering technical information
Every software system has Recent approaches for discov
Wednesday, 11 April, 12 changes, as well as development and e focussed on recognizing 9
ions, software unstructured data [3]–[5] hav](https://image.slidesharecdn.com/fse11-ds-nb-120411161031-phpapp02/75/Mining-Development-Repositories-to-Study-the-Impact-of-Collaboration-on-Software-Systems-11-2048.jpg)










![Findings of our work
(1) Social metrics explain post-release defects
as good as code metrics.
(2) Combination of social metrics and code
metrics is cumulative.
(3) Identify factors that have positive and
negative relationships with defects.
[ICPC‘2010] (Best Paper)
[JEMSE?]
Wednesday, 11 April, 12 15](https://image.slidesharecdn.com/fse11-ds-nb-120411161031-phpapp02/75/Mining-Development-Repositories-to-Study-the-Impact-of-Collaboration-on-Software-Systems-24-2048.jpg)






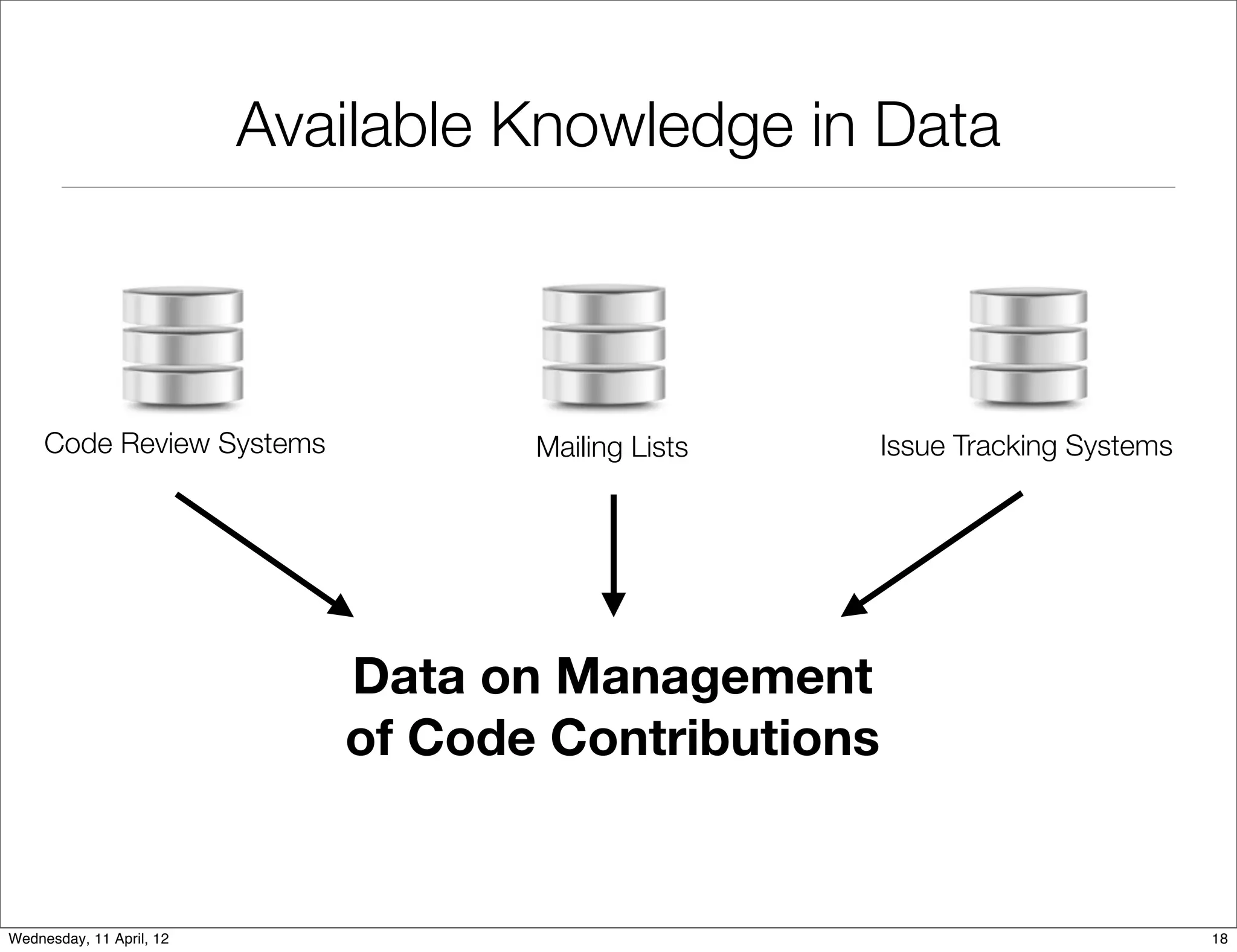
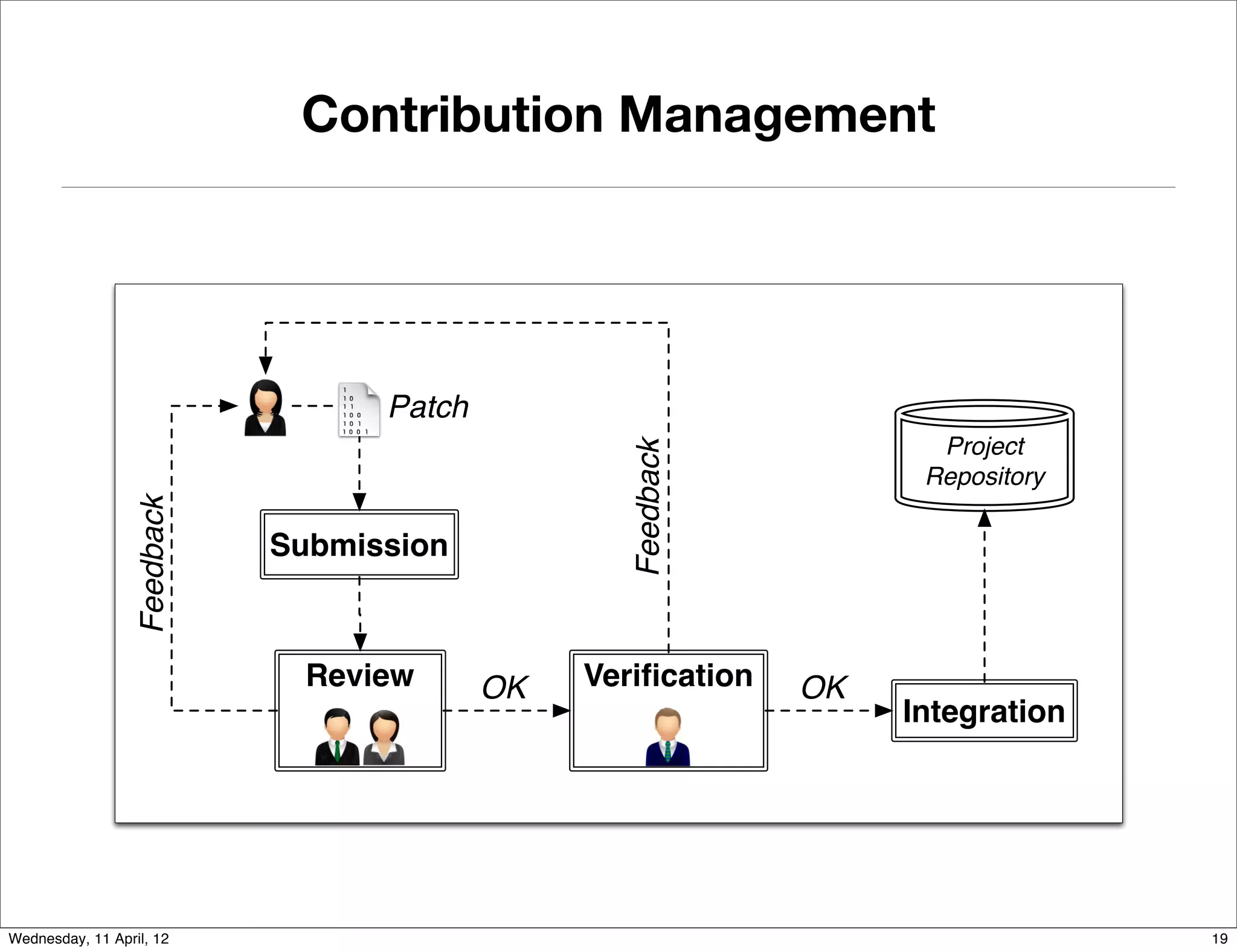

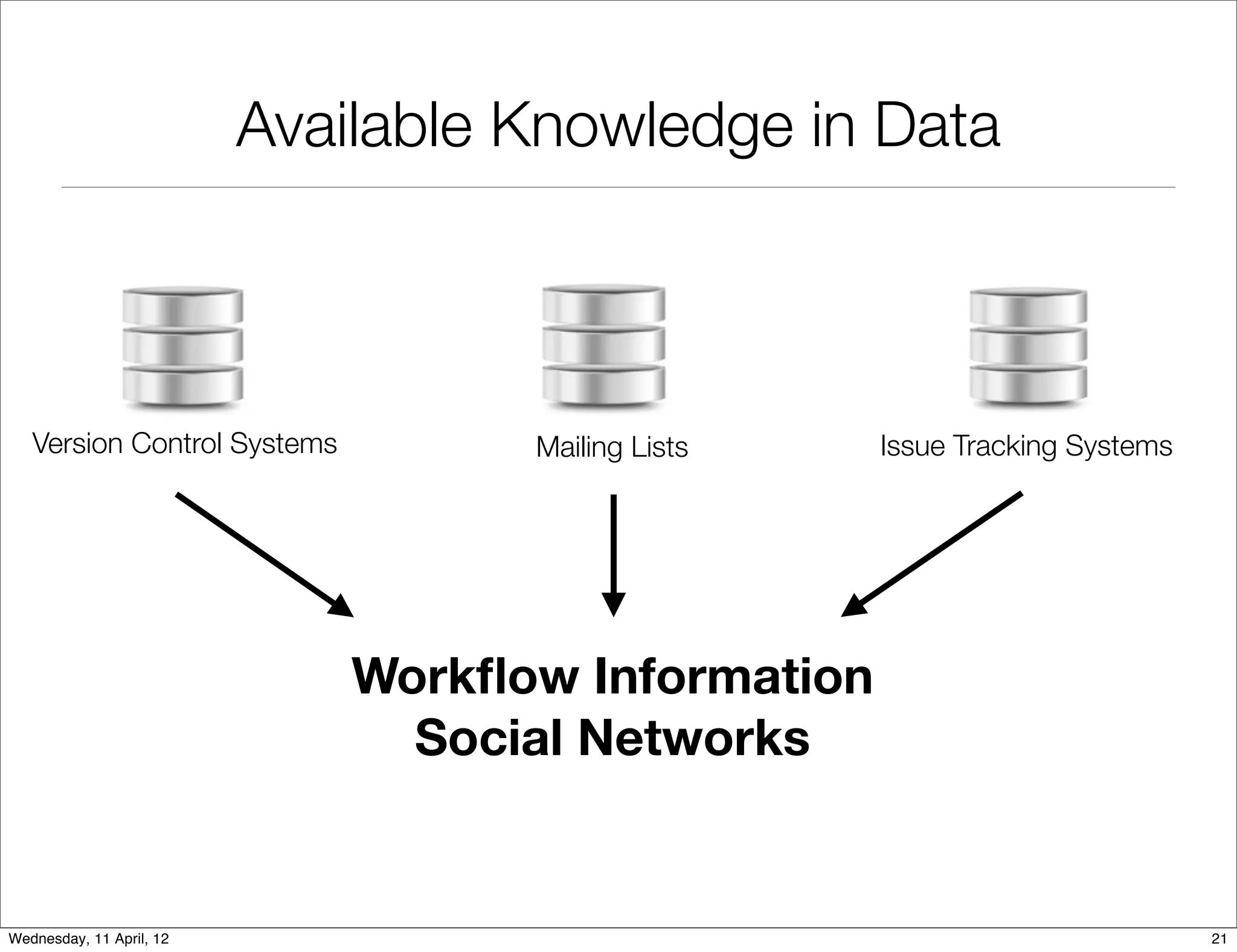
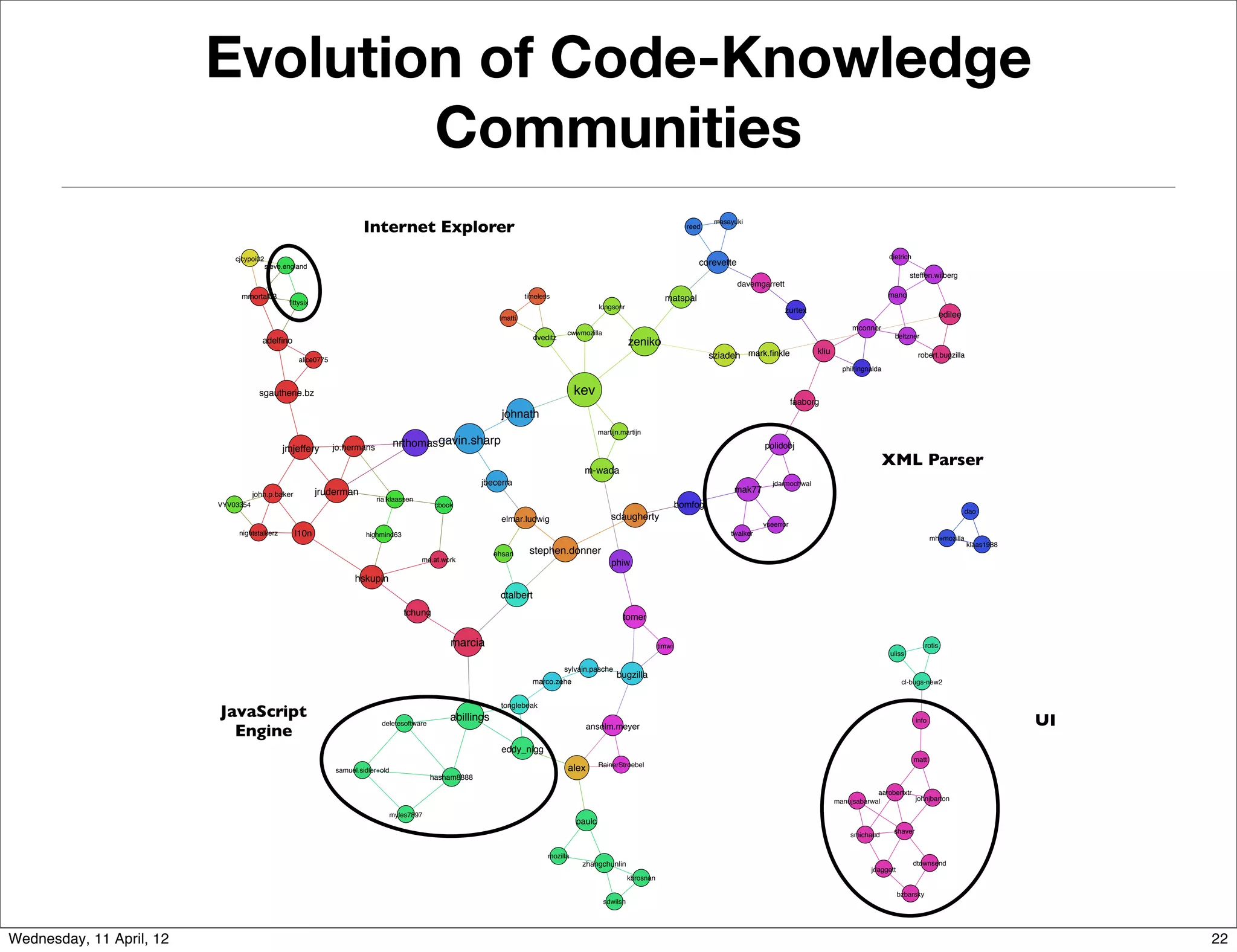


This document proposes an approach to study the impact of collaboration on software systems through mining development repositories. The approach involves: I. Extracting communication data such as source code comments, emails, and issue discussions from version control systems, mailing lists, and issue tracking systems. II. Studying the impact of collaboration on software quality by computing social metrics from the extracted communication data and measuring their relationship to post-release defects. III. Studying the impact of collaboration on the development community by analyzing data on how code contributions are managed, such as feedback and reviews, to understand how contributors, reviewers, and the software are affected by communication.





































































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)

