This document discusses methods for predicting which passengers on the Titanic were most likely to survive using machine learning techniques. It analyzes data on passenger attributes like age, sex, class, and embarkation location. Random forests were selected for making predictions because they are flexible and easy to implement. Decision trees and entropy, which are components of random forests, are explained. The document tests different decision tree models and evaluates a random forest model from sklearn on the Titanic passenger data.




![Embarkation Distribution for train.csv
Figure 3: A pie chart that displays the embarkation distribution in the training set.
The embarkation distribution pie chart indicates that most passengers boarded the ship at Southampton, which was
the last stop. Many crew members were picked up at this port, which could be a strong reason for why Southampton
was such a popular embarkation location.
3 Methods for Predictions
Emerging in the 1990s, machine learning is a field of computer science that explores algorithms that can learn from
and make predictions on given data. Machine learning makes predictions based on known properties learned from
the training data set, rather than solely following a programs instructions. Kaggle suggests that participants apply
the tools of machine learning to predict which passengers survived. When researching common machine learning
techniques to use, we found many researchers’ approaches; the most popular approaches were random forests and
neural networks, which are discuss below. The majority of the researchers suggest random forests, but there are
some that determine survival through neural networks.
3.1 Neural Networks
Neural networks is a common technique that is used to estimate functions that may depend on a large number of
inputs. Some of these inputs may be unknown. This method is inspired by our understanding of how the brain
learns. There are layers which include the inner, hidden, and outer layers. Input vectors are fed into the neural
network and output vectors are given in the end. One example of a neural network for the titanic problem uses
inputs of social class, age (adult or child), and sex. Their network had an error rate of 0.2. One important fact
about the neural network is that it uses weights for the relative importance of each input. Some inputs are more
important, like if the passenger is a child. The overall effect (excitatory or inhibitory) of the neuron is found from
looking at the weights from the input to hidden neurons and also from hidden to output neurons, [5].
3.2 Random Forests
Random forests are a group of decision trees that rate the importance of certain features and predict the outcome of
an input based on the value of the features. The final prediction of a testing set is based off of the the decision trees
that are made based on an inputted training set. When a data point is fed into the tree, the forest will output the
class that is the mode of the classes, otherwise known as classification, or the mean prediction, otherwise known as
regression, of the individual trees. Classification is the result that most of the trees in the forest predict as the final
4](https://image.slidesharecdn.com/69a41052-67c9-4ad6-818d-b9e226833fb6-160202151740/85/milestone-5-stretching-5-320.jpg)
![outcome. Regression is the mean prediction of all of the trees’ final outcomes. Based on these results, the forest will
decide which algorithm results in the better prediction for each input.
3.3 Choosing Random Forest
After careful consideration, we decided to use random forests because it seemed more flexible and easier to implement
than neural networks. We felt that we would have more freedom using Random Forests because it has a larger amount
of resources than neural networks does. In addition, Kaggle suggested it and other people are using it with good
results. Random forests are also good at taking different values from different categories and outputting categorical
results.[3]
We will be using Python to tackle this project. Python has many useful libraries for data analysis. For this project,
we are using Python’s Pandas Library, the sklearn Random Forest Classifier, and its csv libraries. These libraries
are useful because the pandas library can read and write csv files and sklearn has a random forest module which is
a useful tool for creating random forests.
4 Decision Trees
Before discussing Random Forests, we must first define decision trees. Decision trees are a specific type of tree data
structure that make predictions by breaking down a large data set into smaller subsets. A decision node holds a
specific feature and has two or more branches stemming out of it. The first decision it has to make is at the root
node. Based on the input, the node will determine which branch to take in relation to its specified feature. Each
branch will lead to a different decision node. This process continues until it hits a leaf node and cannot branch
anywhere else. The leaf node represents the final outcome for that input. Multiple decision trees make up a random
forest.
4.1 Entropy
Entropy can be used to find the homogeneity of a sample. Entropy normally represents disorder, but in information
theory, it is the expected value of information contained in a message (in our case, the survival of a person on
board). We used conditional entropy to determine the splits in our decision tree. Conditional entropy calculates the
expected value of information given another piece of information. Two kinds of entropy need to be calculated to
make a decision tree: entropy using one attribute and conditional entropy. In relation to our topic, entropy using one
attribute is survival and conditional entropy could be survival given male or female. The equation for the entropy of
one attribute is:
E(S) =
c
i=1
−pi log2 pi (1)
where S is the target (survival), p is the probability that one attribute occurs, and c is the number of possibilities
for that attribute. The equation for conditional entropy of two attributes (or more) is:
E(S) =
c∈X
P(C)E(C) (2)
where S (survival) and X (male, female) represent the attributes, P is the probability of one attribute, E is the
entropy of that attribute, and c is the number of possibilities for that attribute.
To calculate the entropy of a target, in this case target is survival, split the data and calculate entropy for each
branch and subtract from the entropy before the split. Then choose the attribute with the largest information gain,
or the smallest entropy, as the next node because the smaller the entropy, the more accurate the prediction is. Run
this algorithm recursively until all of the data is in the tree. Small entropy values lead to more accurate predictions
because that means less information is gained by knowing the end result. If the entropy is 0, then that means that
you know the end result from the other information given 100% of the time. Like most algorithms, decision trees are
not perfect. Some problems that exist with decision trees include working with continuous attributes, overfitting,
attributes with many values, and dealing with missing values, [2].
5](https://image.slidesharecdn.com/69a41052-67c9-4ad6-818d-b9e226833fb6-160202151740/85/milestone-5-stretching-6-320.jpg)


![e =
f + z2
2N + z f
N − f2
N + z2
4N2
1 + z2
N
(3)
where z = 1.96 (which is the z-value for the confidence level of 95%), f is the error on the data in the training set,
and N is the number of instances covered by the leaf, to find the error at a node with only leaves and its children.
Then we found the weighted sum of the errors of these leaves where the weight is the percentage of values that fall
within that leaf versus the values of the parent. If the weighted sum of the leaves is greater than the error of the
parent node, then we prune the tree by getting rid of those leaves. Below is our pruned version of the entropy tree.
[3]
Figure 6: A flow representation of our Pruned Entropy Tree to counteract overfitting.
Our pruned entropy tree results can be found in the table, Figure 9, in Section 8. This tree was one of our best
algorithms at predicting survival accuracy with a 91% success. The death accuracy did not score as well with 78%
and gave a Kaggle accuracy of 78%.
5 sklearn’s Random Forest
After researching and implementing our own decision trees, we were finally ready to create a random forest. Python’s
sklearn package already comes equipped with a ready-to-use Random Forest tool. The way it works is we feed in the
training set, which is a csv file of 891 passengers with all of the given features along with if they survived (1) or if
8](https://image.slidesharecdn.com/69a41052-67c9-4ad6-818d-b9e226833fb6-160202151740/85/milestone-5-stretching-9-320.jpg)

![train = pd.read_csv(’train.csv’)
test = pd.read_csv(’test.csv’)
cols = [’Pclass’,’SibSp’,’Parch’]
colsRes = [’Survived’]
trainArr = train.as_matrix(cols) #training array
trainArr = trainArr[:]
trainRes = train.as_matrix(colsRes) # training results
rf = RandomForestClassifier(n_estimators=100) # initialize
rf = rf.fit(trainArr, trainRes.ravel()) # fit the data to the algorithm
testArr = test.as_matrix(cols)
results = rf.predict(testArr)
One random forest we made uses the features Pclass, Sibsp, Parch, Sex, Age, Port, and Fare. We also used most of the
standard parameters from sklearn’s random forest package. The only parameters we changed were max features=1
and oob score=True. max features is the number of classification features that are considered when determining the
best split; the standard setting is ‘auto’, or sqrt(n features). Setting this to 1 should create relatively random trees
since every split only considers one feature. This works well because it reduces overfitting. oob score is whether or
not the random forest uses out-of-bag samples to estimate error. The normal setting is False, but setting this to
True also helps to reduce overfitting.
Our best random forest uses the features: Pclass, Sibsp, Parch, Sex, Age, Port, Fare,and Title, and the parameters:
max features=1, oob score=True, and max depth=7. Adding a new feature (Title) allows for more predictive power
because it gives the forest more data to work with. The “new” max depth parameter defines the max depth any one
tree can be grown; the default for this is “None”, which does not restrict the depth the trees can grow to, so the
trees can vary greatly in size and depth. Setting this parameter to a fixed number reduces overfitting farther by not
allowing any trees in the forest to be too large. After “opening” up our previous random forest, we noticed that the
depths of its decision trees do not exceed ten levels. So we tried various max depths under 10 to see if (or which)
depths would make a difference in our results. After some brute forcing, we found that a max depth of 7 yielded
optimal results. The results for all of our random forests are shown in Section 8.
6 Missing Data
In order to use sklearn Random Forest tool, all of our data has to be fully filled in; we cannot have any holes or NaNs
(Python’s symbol for no solution). Some features, like Ticket and Cabin Number, have too many blanks and there
is no reasonable algorithm to guess what they are. So we will not use them as predictions when making our Random
Forest, but we might be able to use them for another purpose. Other features, like Age and Fare, have blanks as
well but these could be filled in with the right algorithm. We start attacking the missing data problem with Age.
6.1 Defining the Problem
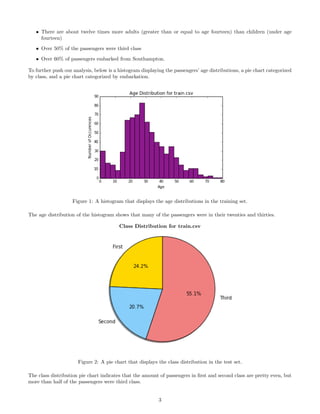
It is pretty clear that Age is one of the most important features and one of the easiest gaps to fill. The bar chart
below shows the number of passengers with an age and with an Age missing in the testing set and training set.
10](https://image.slidesharecdn.com/69a41052-67c9-4ad6-818d-b9e226833fb6-160202151740/85/milestone-5-stretching-11-320.jpg)
![a child (under 14), the missing Age becomes 30. If the matching passenger is an adult (greater than or equal to 14),
the missing Age is changed to 3. If they don’t have a sibling or parent/child, then the passenger with the missing
Age is given the average Age which is 30. Below is the missingAge() algorithm:
def missingAge(passenger):
spSib = passenger.loc[’SibSp’]
parch = passenger.loc[’Parch’]
ticket = passenger.loc[’Ticket’]
age = 30
if spSib > 0:
for i in range(len(lines)):
if lines.loc[i,’Ticket’] == ticket:
if np.isnan(lines.loc[i,’Age’]) == False:
age = lines.loc[i,’Age’]
break
elif parch > 0:
for i in range(len(lines)):
if lines.loc[i,’Ticket’] == ticket:
pcage = lines.loc[i,’Age’]
if pcage < 14:
age = 30
else:
age = 8
break
else:
age = 30
return age
In order for our random forest to work, we must have a csv file that does not have any missing data. So, after
writing the function for missing Age, we generated a new csv file in Python that does not have missing Ages. We
accomplished this by saving the new Age found in the missingAge() function as the passenger’s Age.
7 Non-numeric Values
7.1 Sex and Embark
After filling in Age, we fixed another very important feature: Sex. This feature was not missing any data in either
the testing or training table, but it had entries that were not numeric. We had to change the entries from “female”
and “male” to 0 and 1. This was a fairly easy fix. We added a total of two lines to our random forest code, which
are highlighted below:
train = pd.read_csv(’train.csv’)
train[’Gender’] = train[’Sex’].map({’female’: 0, ’male’: 1}).astype(int) # changing Sex to numbers
test = pd.read_csv(’test.csv’)
test[’Gender’] = test[’Sex’].map({’female’: 0, ’male’: 1}).astype(int) # changing Sex to numbers
Similarly, we had to change the non-numeric Embarked entries to numeric values. Therefore, we changed the entries
from “Q,” “C,” and “S” to 0, 1, and 2 using similar code shown above.
7.2 Title
Another data type we wanted to include in our random forest is the passengers Title. This is another non-numeric
value. In order to change the Titles to numeric values, we assigned each Title a number. Before we assigned the
Titles a number, we had to parse the Title out of the passengers name. The method used to achieve this can be
12](https://image.slidesharecdn.com/69a41052-67c9-4ad6-818d-b9e226833fb6-160202151740/85/milestone-5-stretching-13-320.jpg)
![seen in the code below. The passengers name in the csv file was in the general form last name, title, then first name
as strings. For example, one passengers name is listed as “Kelly, Mr. James.” Our code checks for a period in the
passengers name and then appends the title which is in between the comma and period. The most frequent Title
was given a lower number. For example, the Title ‘Mr’ was given 0, ‘Mrs’ was given 1, and so on. This process was
used for both the test and train csv files. The method to convert from strings to integers is the same method as
explained in the previous subsection. The code had to be modified for each file since the Titles varied between the
files. We added another column to the csv file that contained each passengers assigned Title number. The Python
code can be seen below:
title = list()
if ’.’ in passenger.loc[’Name’]:
title.append(passenger.loc[’Name’].split(’,’)[1].split(’.’)[0].strip())
else:
title.append(’nan’)
8 Our Statistics
To test the accuracy of our forests and decision trees, we submitted multiple csv files with the passenger ID and if they
survived or not (0 or 1) to Kaggle. Kaggle has many different benchmarks (that Kaggle generated) that we can use
to compare how accurate our results are compared to its basic models as well as where we stand in ranking compared
to other teams. “Assume All Perished” is the lowest benchmark, with a score of 62.679%. Another threshold is the
“Gender Based Model” Benchmark where the all females survive and all males die, which has a score of 76.555%.
The “My First Random Forest” benchmark, which scored a 77.512%, is a random forest algorithm that uses the
Python package sklearn with features Age, Sex, Pclass, Fare, Sibsp, Embarked, and Parch. The top benchmark is
the “Gender, Price and Class Based Model” which is based on gender, ticket class, and ticket price, and has a score
of 77.990%. Below is a summary of the benchmarks:
Benchmark: Score
Assume All Perished: 0.62679
Gender Based Model: 0.76555
My First Random Forest: 0.77512
Gender, Price, and Class Based Model: 0.77990
Figure 8: A summary of Kaggle’s benchmarks. The highest score that can be achieved is 1.
We first ran our single decision trees and submitted them to Kaggle to see where we stand compared to other teams.
The score of our Age model is 77.033%. We placed one rank above the Gender Based Survival threshold. The score
of our Entropy model is 78.469% and the score of our Pruned Entropy model is 77.990%. Our highest scoring model,
the Entropy model, is 555 places above the Gender Based Survival threshold and 3 places above the Gender, Price
and Class Based Model.
In addition to our decision trees, we also ran Panda’s random forest tool on the basic features, Pclass, Parch, and
Sibsp, and the basic features plus Sex separately. Our Basic Random Forest obtained a score of .68421, which falls
above the “Assume All Perished Model” benchmark and below the “Gender Based Model” benchmark. These results
were not as good as our “Entropy Tree” submission. Our Basic plus Gender Random Forest was much better than
the previous basic model with a Kaggle Accuracy of .77990, which is around the “Gender, Price, and Class Based
Model” benchmark.
After successfully filling in missing Ages and converting Sex to a numeric form, we ran the Panda’s random forest
tool on all five features: Age, Sex, Pclass, Parch, and Sibsp. Ideally, this random forest should improve our overall
accuracy, but after submitting it to Kaggle we found that it actually performed worse than our Entropy-based trees.
We scored a .71770 on Kaggle, which is above the “Assume All Perished Model” Benchmark but way below the
“Gender Based Model” Benchmark. We also added in the Titles feature (so now your random forest has six features)
after filling in those missing data points and it yielded similar Kaggle results as the Basic Random Forest with Age
and Sex yielded.
13](https://image.slidesharecdn.com/69a41052-67c9-4ad6-818d-b9e226833fb6-160202151740/85/milestone-5-stretching-14-320.jpg)


![corresponding hypothesis.
Our results for this project suggest that we are having an overfitting problem. Bagging is a method that is known to
help reduce this particular obstacle. The above algorithm is a good start to mending our already-existing algorithms
together to yield more accurate results.
References
[1] Berghammer, R. Relations and Kleene Algebra in Computer Science 11th International Conference on Relational
Methods in Computer Science, RelMiCS 2009, and 6th International Conference on Applications of Kleene
Algebra, AKA 2009, Doha, Qatar, November 1-5, 2009 : Proceed. Berlin: Springer, 2009. Print.
[2] “Decision Tree.” Decision Tree. Web. 11 Oct. 2015. http://www.saedsayad.com/decision_tree.htm
[3] “Decision Tree” Decision Tree. Web. 11 Oct. 2015. http://www.saedsayad.com/decision_tree_overfitting.
htm
[4] “Public Leaderboard - Titanic: Machine Learning from Disaster.” Kaggle. 28 Sept. 2012. Web. 28 Oct. 2015.
https://www.kaggle.com/c/titanic/leaderboard
[5] “Titanic Survivor Prediction.” Dans Website. 5 Sept. 2012. Web. 29 Oct. 2015. shttp://logicalgenetics.com/
titanic-survivor-prediction
16](https://image.slidesharecdn.com/69a41052-67c9-4ad6-818d-b9e226833fb6-160202151740/85/milestone-5-stretching-17-320.jpg)



































