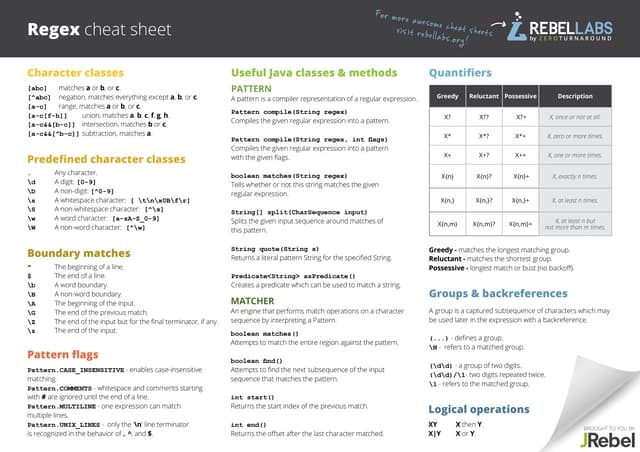
Regular expressions (regexes) are patterns used to match character combinations in strings. This document discusses the history and use of regexes, provides an overview of regex vocabulary including special characters, constructs, and quantifiers, and gives examples of using regexes in Java programs for tasks like validation, splitting strings, and find-and-replace operations. It concludes with examples of validating an address and parsing a properties file using regexes.


![www.luxoft.com
A regular expression, regex or regexp (sometimes called a rational expression) is, in
theoretical computer science and formal language theory, a sequence of characters that
define a search pattern. Usually this pattern is then used by string searching algorithms for
"find" or "find and replace" operations on strings.
^(https?|ftp|file)://[-a-zA-Z0-9+&@#/%?=~_|!:,.;]*[-a-zA-Z0-
9+&@#/%=~_|]
What is Regular Expressions?](https://image.slidesharecdn.com/mikhailkhristophorovintroductiontoregularexpressions-170815075524/75/Mikhail-Khristophorov-Introduction-to-Regular-Expressions-3-2048.jpg)





![www.luxoft.com
Vocabulary
[abc] a, b, or c (simple class)
[^abc] Any character except a, b, or c (negation)
[a-zA-Z] a through z or A through Z, inclusive (range)
[a-d[m-p]] a through d, or m through p: [a-dm-p] (union)
[a-z&&[def]] d, e, or f (intersection)
[a-z&&[^bc]]a through z, except for b and c: [ad-z] (subtraction)
[a-z&&[^m-p]] a through z, and not m through p: [a-lq-z](subtraction)
Character classes](https://image.slidesharecdn.com/mikhailkhristophorovintroductiontoregularexpressions-170815075524/75/Mikhail-Khristophorov-Introduction-to-Regular-Expressions-9-2048.jpg)
![www.luxoft.com
Vocabulary
. Any character (may or may not match line terminators)
d A digit: [0-9]
D A non-digit: [^0-9]
h A horizontal whitespace character: [ txA0u1680u180eu2000-u200au202fu205fu3000]
H A non-horizontal whitespace character: [^h]
s A whitespace character: [ tnx0Bfr]
S A non-whitespace character: [^s]
v A vertical whitespace character: [nx0Bfrx85u2028u2029]
V A non-vertical whitespace character: [^v]
w A word character: [a-zA-Z_0-9]
W A non-word character: [^w]
Predefined character classes](https://image.slidesharecdn.com/mikhailkhristophorovintroductiontoregularexpressions-170815075524/75/Mikhail-Khristophorov-Introduction-to-Regular-Expressions-10-2048.jpg)
![www.luxoft.com
Vocabulary
^ The beginning of a line
$ The end of a line
b A word boundary
B A non-word boundary
A The beginning of the input
G The end of the previous match
Z The end of the input but for the final terminator, if any
z The end of the input
Linebreak matcher
R Any Unicode linebreak sequence, is equivalent to u000Du000A|[u000Au000Bu000Cu000Du0085u2028u2029]
Boundary matchers](https://image.slidesharecdn.com/mikhailkhristophorovintroductiontoregularexpressions-170815075524/75/Mikhail-Khristophorov-Introduction-to-Regular-Expressions-11-2048.jpg)



![www.luxoft.com
Regexes and Java
Lets try to validate is provided string is phone:
String phoneRegex = "(+d*)?(?d{2,3})?[d-]+";
String phone = "+38(048)720-70-01";
String notPhone = "+38(048)asb720-70-01";
Pattern phonePattern = Pattern.compile(phoneRegex);
Matcher phoneMatcher = phonePattern.matcher(phone);
System.out.println("Is phone " + phone + " " + phoneMatcher.matches());
phoneMatcher = phonePattern.matcher(notPhone);
System.out.println("Is phone " + notPhone + " " + phoneMatcher.matches());
Or we can use Pattern.matches() method:
String phoneRegex = "(+d*)?(?d{2,3})?[d-]+";
String phone = "+38(048)720-70-01";
String notPhone = "+38(048)asb720-70-01";
System.out.println("Is phone " + phone + " " + Pattern.matches(phoneRegex, phone));
System.out.println("Is phone " + notPhone + " " + Pattern.matches(phoneRegex, notPhone));
Examples Pattern-Matcher](https://image.slidesharecdn.com/mikhailkhristophorovintroductiontoregularexpressions-170815075524/75/Mikhail-Khristophorov-Introduction-to-Regular-Expressions-15-2048.jpg)
![www.luxoft.com
Regexes and Java
Now lets split the string into words:
String string = "This string contain several words";
Pattern wordSplitPattern = Pattern.compile("s");
String[] words = wordSplitPattern.split(string);
for (String word : words)
{
System.out.println(word);
}
Or we can use Matcher for it:
String string = "This string contain several words";
Pattern wordSplitPattern = Pattern.compile("S+");
Matcher wordSplitMatcher = wordSplitPattern.matcher(string);
while (wordSplitMatcher.find())
{
System.out.println(wordSplitMatcher.group());
}
Examples Pattern-Matcher](https://image.slidesharecdn.com/mikhailkhristophorovintroductiontoregularexpressions-170815075524/75/Mikhail-Khristophorov-Introduction-to-Regular-Expressions-16-2048.jpg)
![www.luxoft.com
Regexes and Java
We can validate phone number only using
String:
String phoneRegex = "(+d*)?(?d{2,3})?[d-]+";
String phone = "+38(048)720-70-01";
String notPhone = "+38(048)asb720-70-01";
System.out.println("Is phone " + phone + " " + phone.matches(phoneRegex));
System.out.println("Is phone " + notPhone + " " + notPhone.matches(phoneRegex));
Method matches in String use Pattern-Matcher
inside:
public boolean matches(String regex) {
return Pattern.matches(regex, this);
}
Examples Strings](https://image.slidesharecdn.com/mikhailkhristophorovintroductiontoregularexpressions-170815075524/75/Mikhail-Khristophorov-Introduction-to-Regular-Expressions-17-2048.jpg)
![www.luxoft.com
Regexes and Java
We can split string using String.split():
String string = "This string contain several words";
String[] words = string.split("s");
for (String word : words)
{
System.out.println(word);
}
String.split() use Pattern.split() inside:
public String[] split(String regex, int limit) {
* * *
return Pattern.compile(regex).split(this, limit);
}
Examples Strings](https://image.slidesharecdn.com/mikhailkhristophorovintroductiontoregularexpressions-170815075524/75/Mikhail-Khristophorov-Introduction-to-Regular-Expressions-18-2048.jpg)