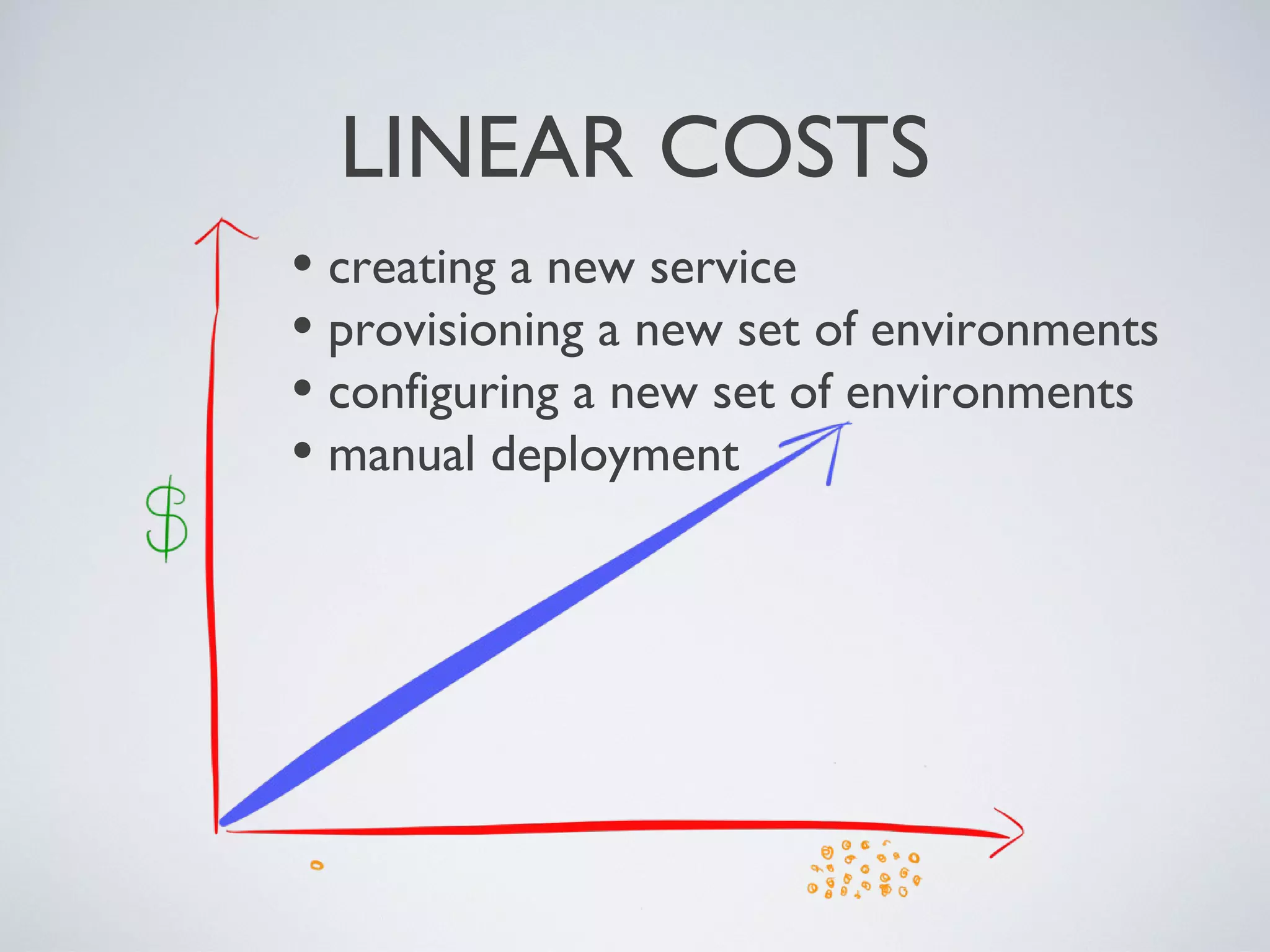
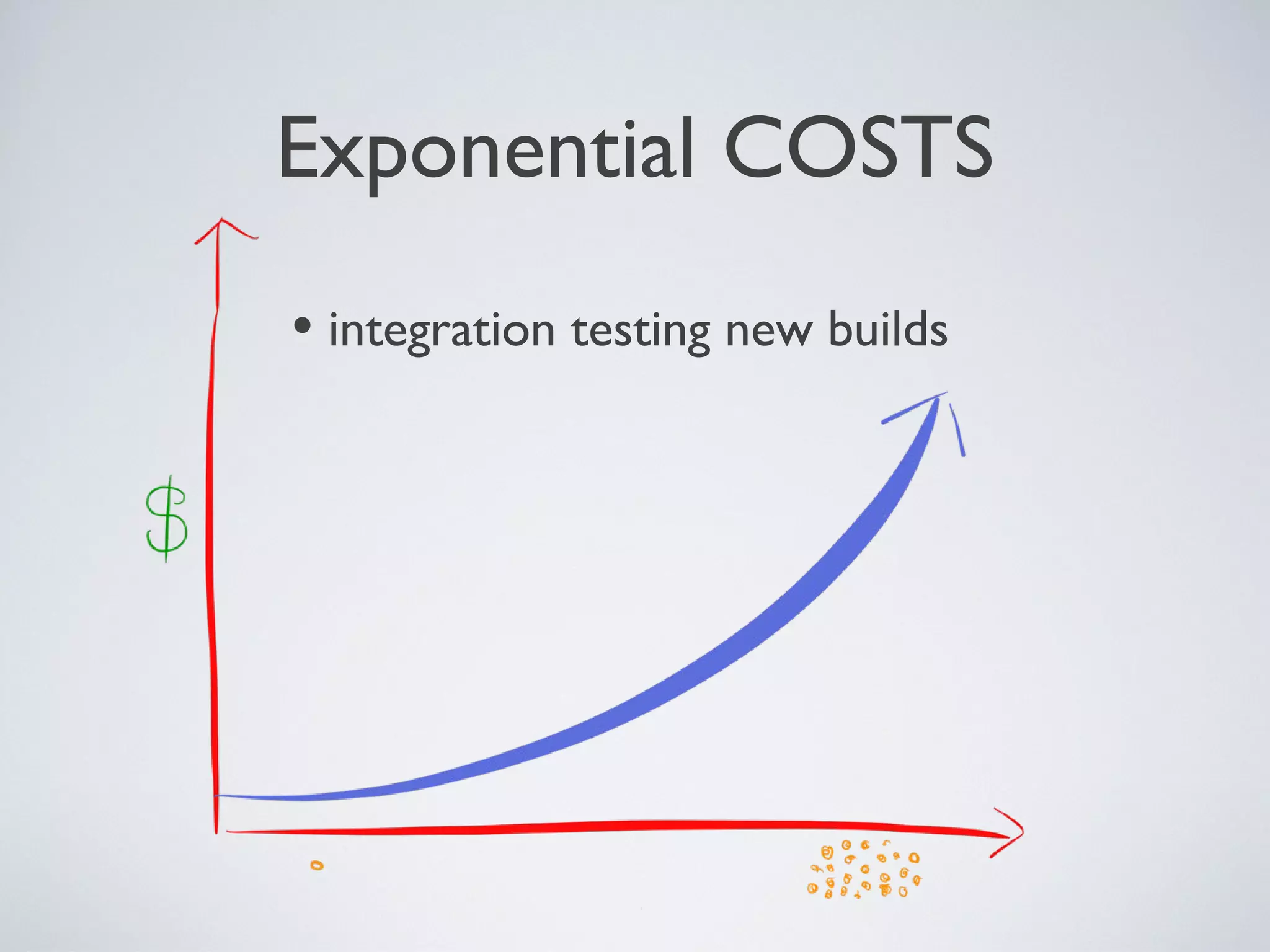
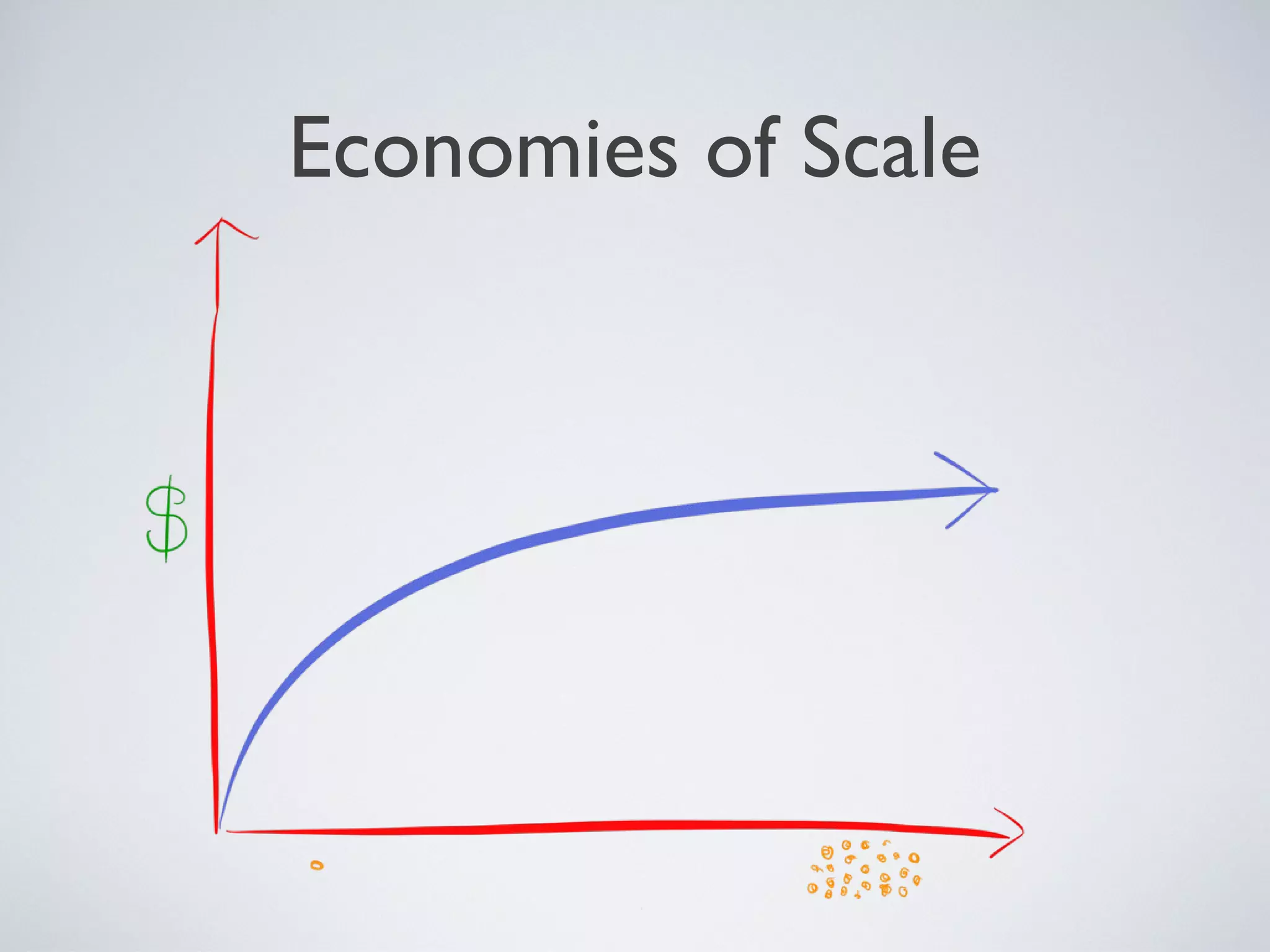
Downloaded 31 times








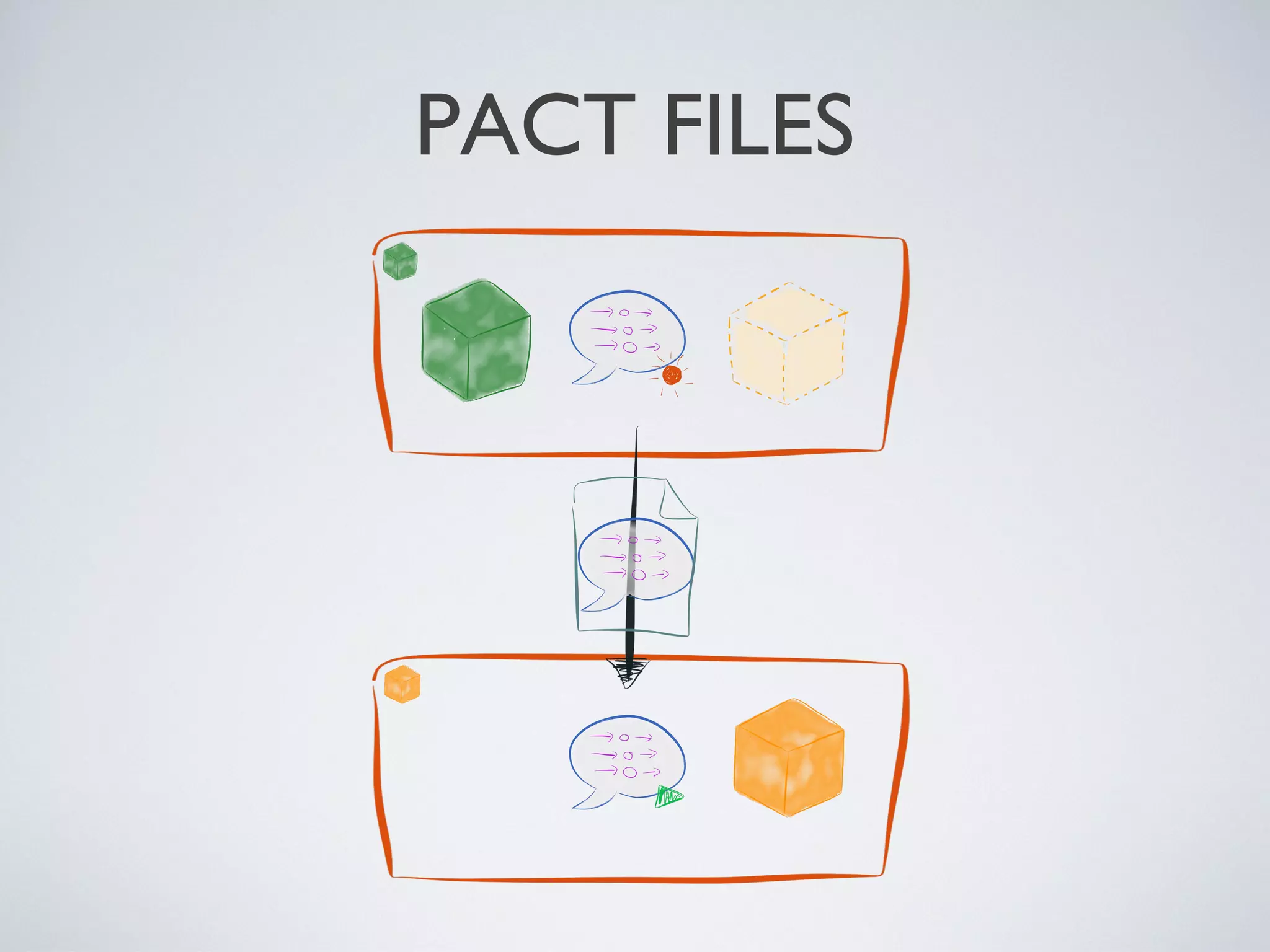
![CONSUMER - RECORD PACT
# spec/time_consumer_spec.rb
require 'pact/consumer/rspec'
require 'httparty'
class TimeConsumer
include HTTParty
base_uri 'localhost:1234'
def get_time
time = JSON.parse(self.class.get('/time').body)
"the time is #{time['hour']}:#{time['minute']} ..."
end
end
Pact.service_consumer 'TimeConsumer' do
has_pact_with 'TimeProvider' do
mock_service :time_provider do
port 1234
end
end
end
describe TimeConsumer do
context 'when telling the time', :pact => true do
it 'formats the time with hours and minutes' do
time_provider.
upon_receiving('a request for the time').
with({ method: :get, path: '/time' }).
will_respond_with({status: 200, body: {'hour' => 10, 'minute' => 45}})
expect(TimeConsumer.new.get_time).to eql('the time is 10:45 ...')
end
end
end
https://github.com/brentsnook/pact_examples
Friday, 20 September 13](https://image.slidesharecdn.com/microservices-130919222041-phpapp01/75/Microservices-Without-the-Macrocost-17-2048.jpg)
![# spec/service_providers/pact_helper.rb
class TimeProvider
def call(env)
[
200,
{"Content-Type" => "application/json"},
[{hour: 10, minute: 45, second: 22}.to_json]
]
end
end
Pact.service_provider "Time Provider" do
app { TimeProvider.new }
honours_pact_with 'Time Consumer' do
pact_uri File.dirname(__FILE__) + '/../pacts/timeconsumer-timeprovider.json'
end
end
PRODUCER - PLAY BACK PACT
https://github.com/brentsnook/pact_examples
Friday, 20 September 13](https://image.slidesharecdn.com/microservices-130919222041-phpapp01/75/Microservices-Without-the-Macrocost-18-2048.jpg)
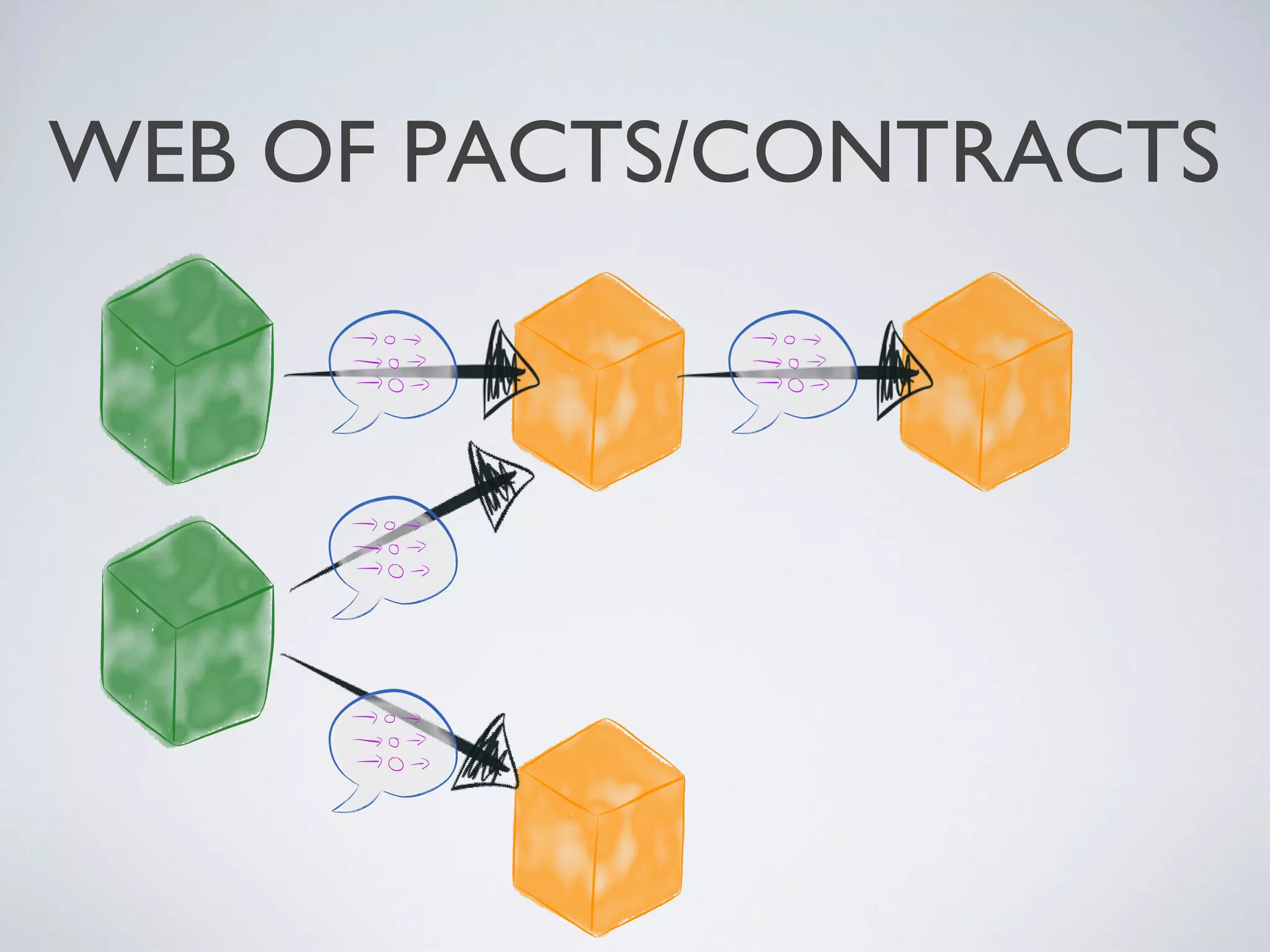




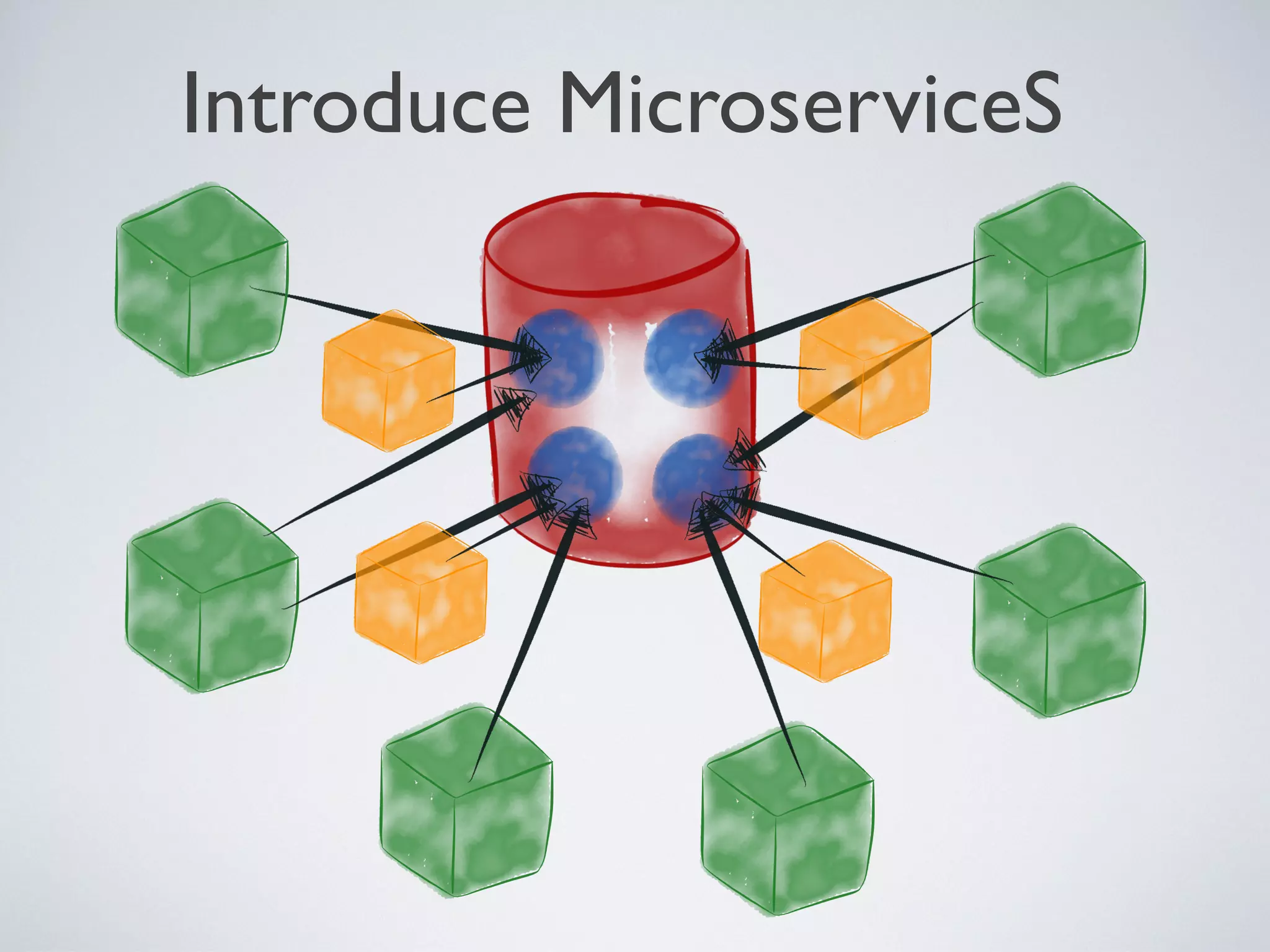
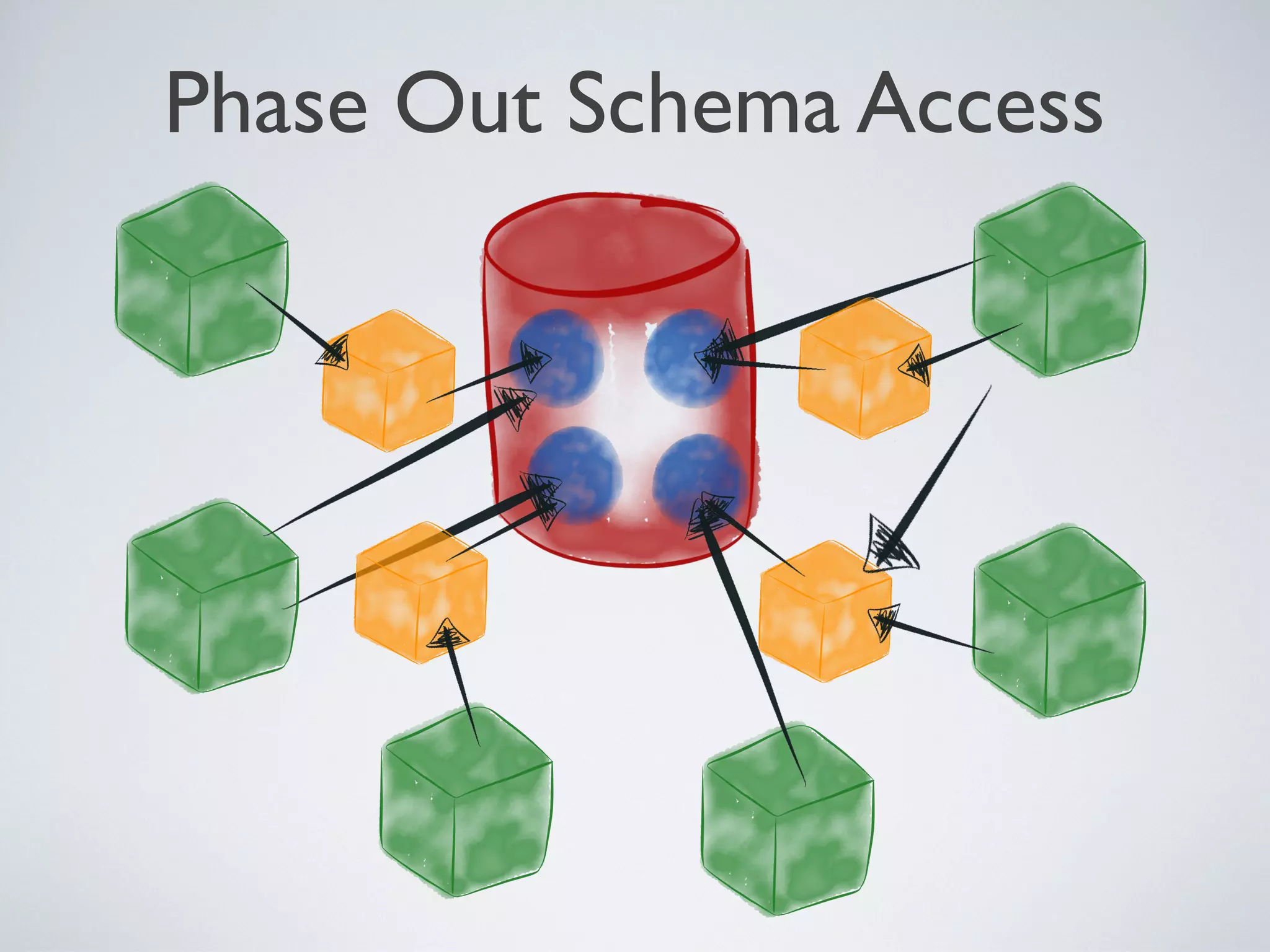
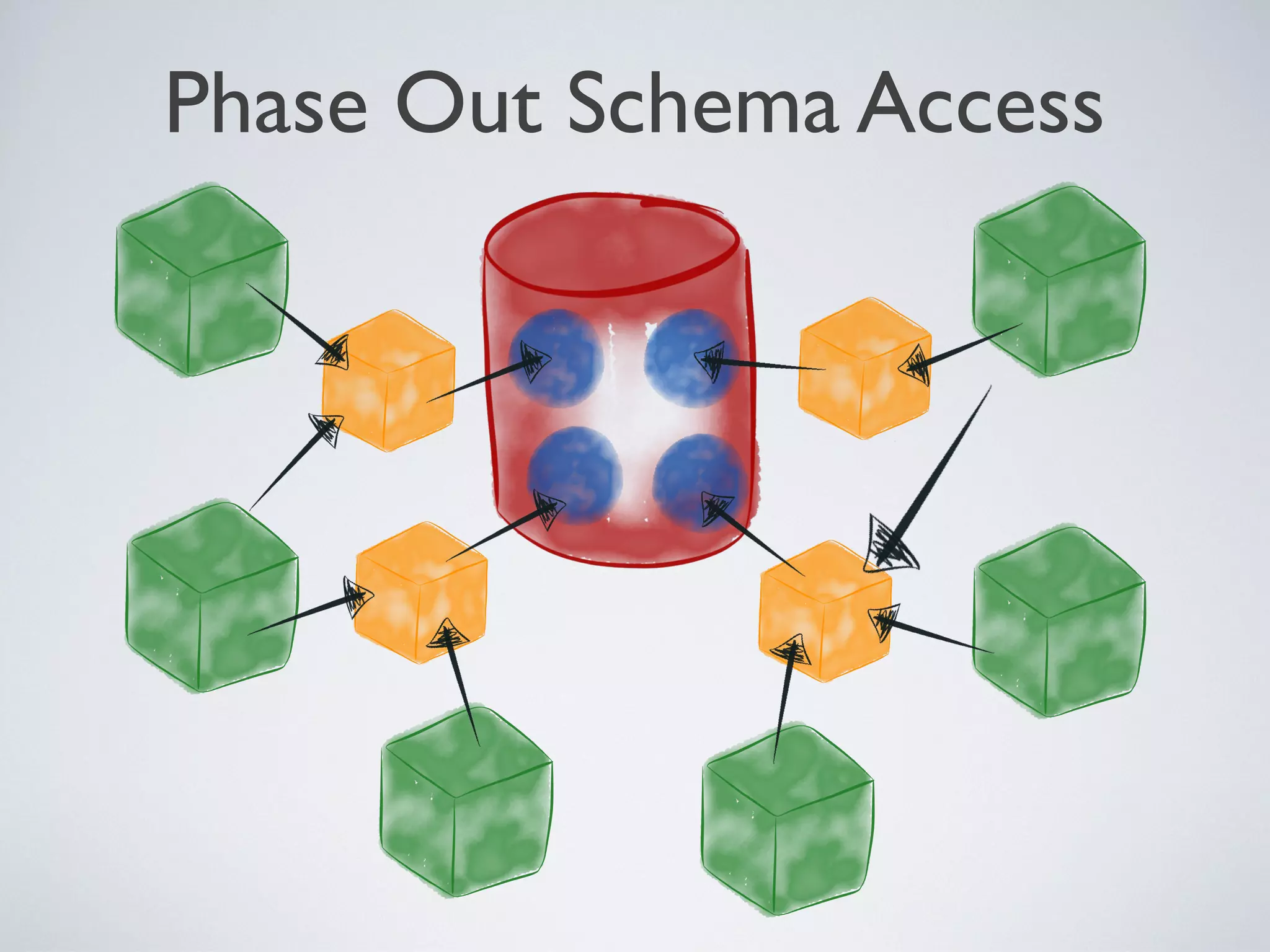
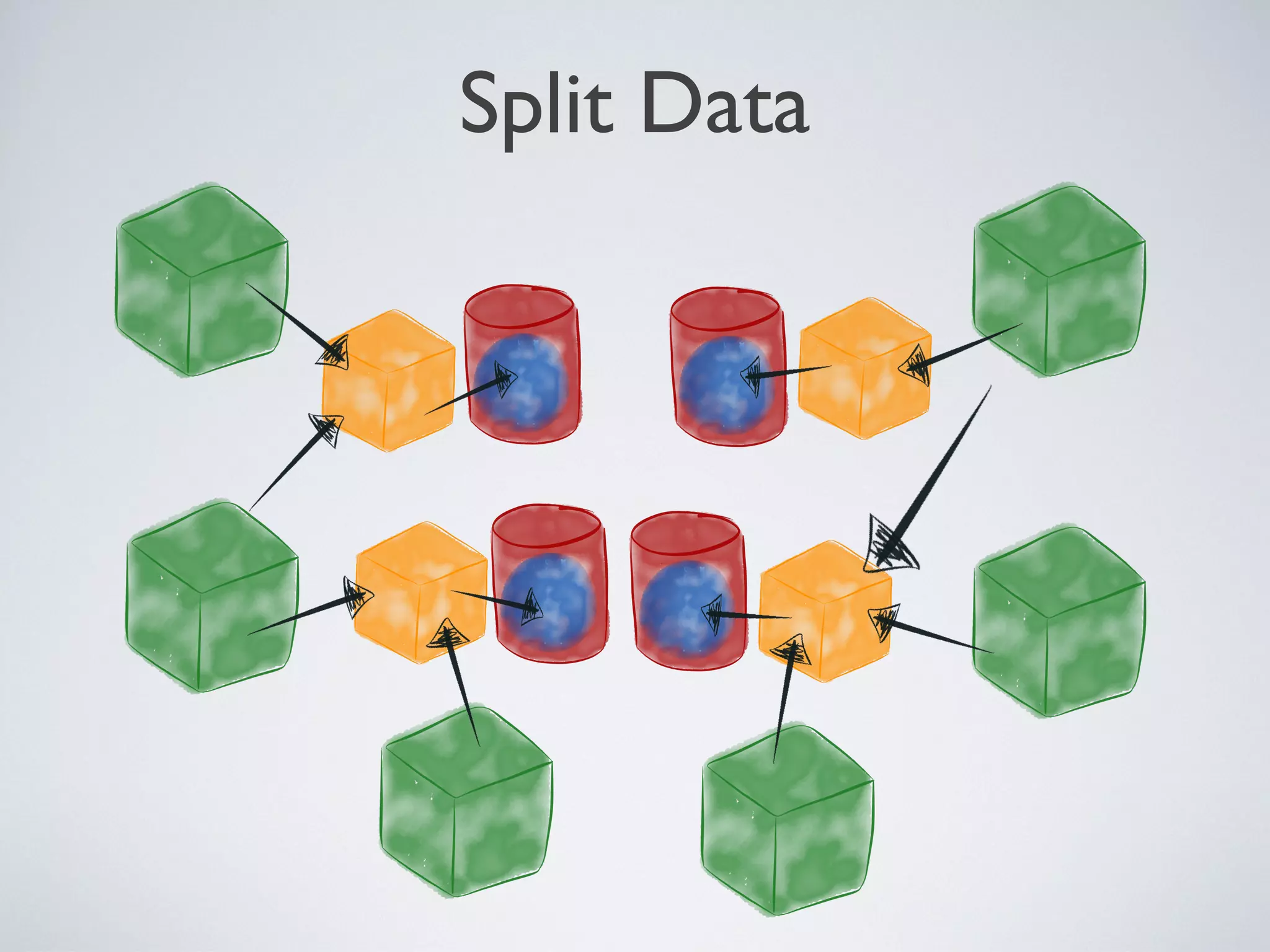
1) Microservices aim to be digestible, disposable, demarcated, decoupled, and defenestrable units that encapsulate specific functions or business capabilities. 2) Many legacy systems have a "God database" architecture where multiple clients are tightly coupled to a single database schema, making it difficult to manage changes. 3) The company introduced microservices by inserting them as intermediaries between clients and the data they need, encapsulating data and standardizing on REST and JSON. This loosened coupling from the database schema over time.





























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















