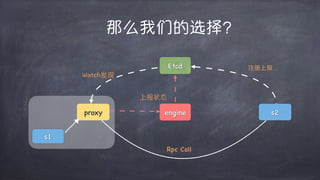
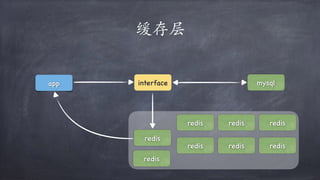
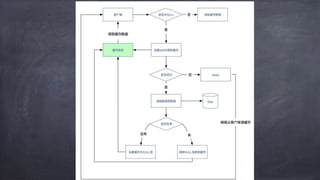
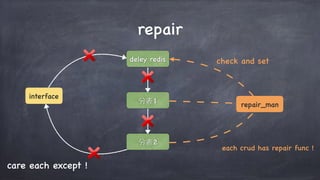
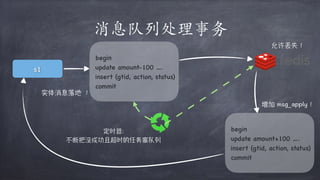
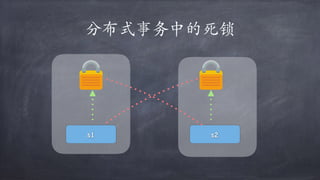
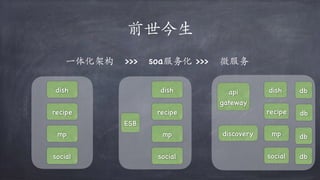
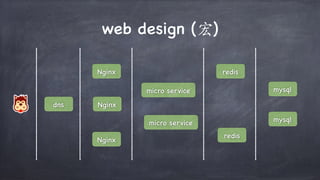
文档讨论了微服务架构的各种方面,包括优点,如松耦合和快速迭代,以及服务发现、缓存层、数据层和接口安全的策略和技术。重点强调了不同的协议组合、分库分表策略和事务处理方法,以解决在微服务环境中遇到的性能和管理挑战。最后,提到部署和监控的最佳实践,以确保分布式系统的有效运行。




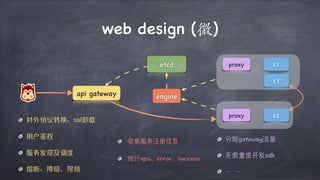


![协议{
"output_type": "json",
"call_func": "add_dish",
"args": [],
"kwargs": {},
"uid": “s123”,
"login": true,
"timeout": 5,
"async": false,
"ip": "",
"sn": "",
"origin": “",
“app_id”: “”,
“timestamp”: “”,
“sign”: “”
} ... ...
{
"code": "",
"error": "",
"res": {}
}](https://image.slidesharecdn.com/microservice-170524040020/85/Micro-service-9-320.jpg)