Download to read offline








![rdf:type
Primae frugiparos fetus mortalibus aegris dididerunt quondam praeclaro nomine Athenae et recreaverunt vitam legesque rogarunt [...]
De rerum natura – Book VI
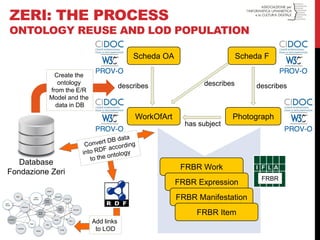
GEOLAT:THE MODEL (SIMPLIFIED)
athenaeWord
bro:TextFragment
bro:Book
isPartOf
rdf:type
bro:LiteraryWork
rdf:type
isPartOf
deRerumNatura
athens
awgo:GreekPolis
rdf:type
geographicSpace1
awgo:GeographicSpace
awgo:locatedIn
bro:identifies
anno1
oa:Annotation
oa:hasTarget
trig:Graph
rdf:type
oa:hasBody
rdf:type
DRN_BookVI
rdf:type
pleiades: 579885
skos:closeMatch](https://image.slidesharecdn.com/methodsandexperiencessilviodiego-francesca-141112090715-conversion-gate02/85/Methods-and-experiences-in-cultural-heritage-enhancement-10-320.jpg)





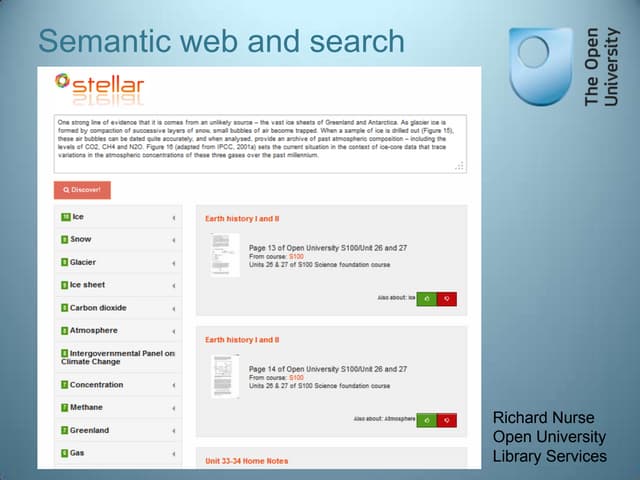
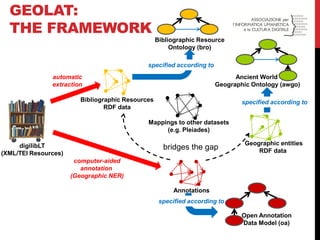
The document discusses a conference on linked open data (LOD) in cultural heritage, focusing on methodologies and experiences related to data conversion, extraction, and ontology creation. Various case studies are presented, including the Zeri photo archive and the digital edition of Vespasiano da Bisticci's letters, highlighting efforts to enhance datasets through LOD practices. It emphasizes the importance of ontology reuse, stand-off markup, and collaborative strategies for populating the LOD cloud.