Download to read offline




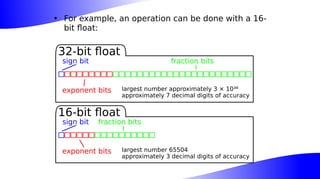











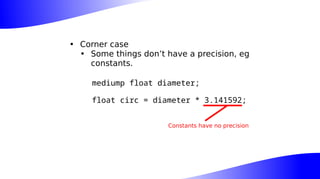








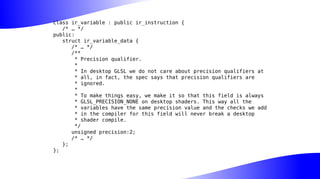





















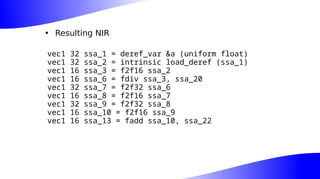
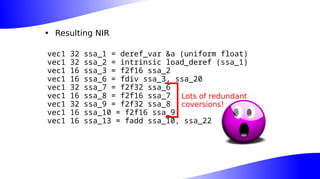




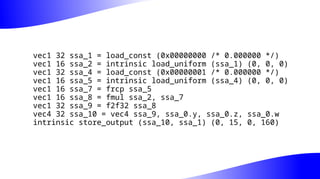
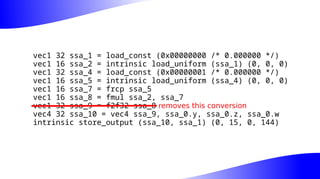
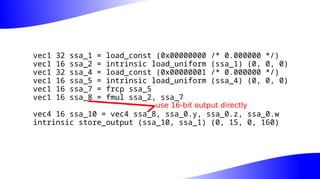









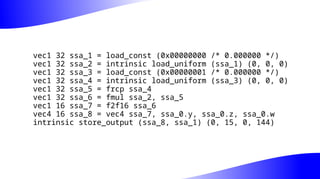
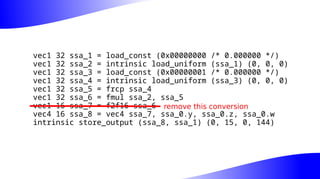
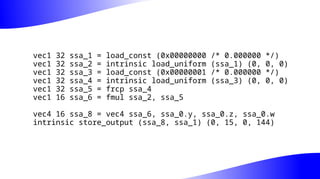
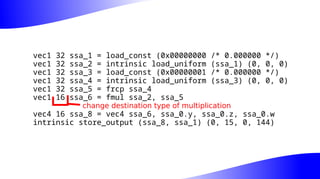
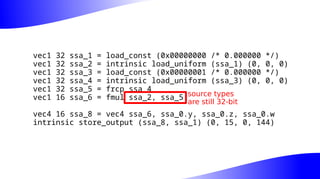





The document outlines the implementation and benefits of 'mediump' precision in Mesa's GLSL ES support, where 'mediump' allows shaders to operate with lower precision for better performance. It discusses the current handling of precision qualifiers in Mesa, plans for improving operations, reducing unnecessary conversions, and optimizing fragment shader outputs on specific hardware. The focus is on updating the optimization passes to lower mediump operations to float16 types while maintaining compatibility with drivers, specifically targeting the Freedreno driver.



































































