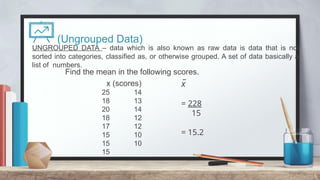
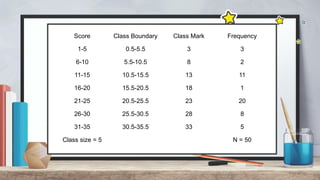
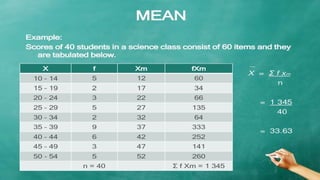
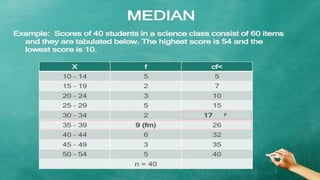
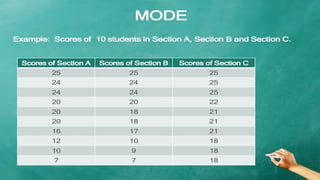
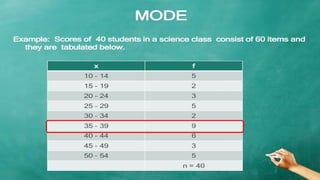
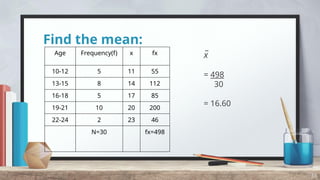
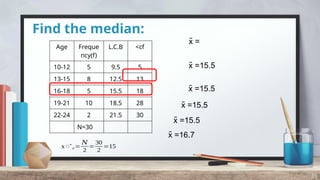
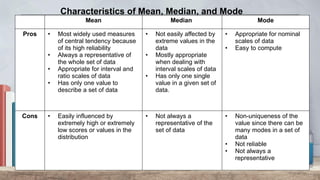
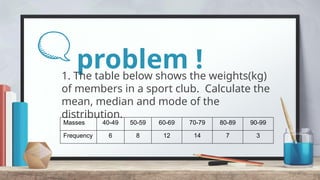
The document explains measures of central tendency, specifically mean, median, and mode, as ways to describe a set of data with a single representative value. It outlines how to compute these measures for both ungrouped and grouped data, including examples and formulas. Additionally, it discusses the pros and cons of each measure, illustrating their applicability and limitations.