The document is a master's thesis submitted by Imad Eddin Jerbi to obtain a Master's degree in Computer Systems and New Technologies. The thesis discusses the construction and morpho-syntactic annotation of a colloquial corpus focusing on Tunisian Arabic. The thesis was supervised by Mariem Ellouze and co-supervised by Ines Zribi and Rahma Boujelbane. It was defended on December 27, 2013 in front of a jury consisting of Lamia Hadrich Belguith, Maher Jaoua, Mariem Ellouze, Ines Zribi, and Rahma Boujelbane.















![Introduction
The Arabic language is speaking by about 300 million people [Al-Shamsi 2006] and
the fourth most spoken language. Thus, it is a major international modern language.
Considering the amount of people it is spoken by, the number of computing resources for
the Arabic language is still few. The Arabic language is a blend of the modern standard
Arabic, used in written and formal spoken discourse, and a collection of related Arabic
dialects. This mixture was dened by Hymes [Hymes 1973] as a linguistic continuum.
Indeed, Arabic dialects present signicant phonological, morphological, lexical, and syn-
tactic dierences among themselves and when compared to the standard written forms.
Furthermore, the presence of diglossia [Ferguson 1959] is a real challenging issue for
Arabic speech language technologies, including corpus creation to support Speech-to-
Text (STT) systems. In addition, other diculties for researchers lie in Arabic dialects
as a morphologically complex language. Also, there is a small amounts of text data for
spoken Arabic due to the non ocially written of this language.
A better set of corpus will support, in the rst place, further research into the area for
example support linguistics researchers in analysis of the Arabic dialects phenomenas. It
also lays the ground for creating new and a better end-user application.
One of the fundamental parts of any application of the Natural Language Processing
(NLP)in a specic language, such as in the Tunisian Dialect (TD), is the existence of
corpora. Indeed, the construction of speech corpora for the TD is fundamental for study-
ing its specication and to advance its NLP application for example speech recognition.
Some small corpus exist nowadays and have been developed by previous researchs. How-
ever, these corpus combined other dialects and they are not specic for the TD also they
do not include any diacritics information. In general, these corpus are either in closed
projects or not freely available. In addition, these corpora do not include any morpho-
syntactic annotation or phonetic information.
The aim of this project is to investigate how to collect and transcribe speech data, the
possibility of using existing tools for transcribing, the choice of the appropriate guidelines.
How to annotate the transcripts?, which methods are used?,
The report is divided in two parts. The rst part presents the state of the art of ex-
isting speech corpora resources for Arabic language. The chapter two lists some morpho-
syntactic annotation methods. The second part describes the used method and resources
to collect, transcribe, and annotate speech data. The third chapter is devoted to present](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-16-2048.jpg)



![Chapter 1
Linguistic Resources
1.1 Introduction
A spoken language corpus is dened as a collection of speech recordings which is ac-
cessible in computer readable form and which comes with annotation and documentation
sucient to allow re-use of the data in-house, or by scientists in other organizations
[Gibbon 1997]. Indeed, creating speech corpora is crucial for the studying of dierent
characteristics of the spoken language. As well as the development of applications which
deal with the voice, for example speech recognition system.
In this chapter, we will answer the following question: How to create a speech corpus?
Therefore, we present methods of speech and text data collection in the next section.
Then, we focus on presenting some available corpora for Arabic language. After that,
we introduced the orthographic transcription task by presenting a literature recap of its
guidelines and tools.
1.2 Speech and Text Data Collection
A prerequisite for a successful development of spoken language resources is a good
denition of the collected speech data. There are three steps in text data collection:
The rst is to precise the source of data (books, novels, chat rooms, etc), type (standard
written language or dialectal), theme (social, news, sport, etc), encoding and format
(transcribed les, web pages, XML les, etc). The second step called data collection,
which is performed using dierent techniques such as harvesting large amounts of data
from the web [Diab 2010] and speech data transcribing [Messaoudi 2004]. As well as an
automatic speech recognition method like used in [Messaoudi 2004, Gauvain 2000] could
be performed to extract text from speech data. The third step consists in adapting and
organizing these data [Diab 2010].
Consequently, speech data collection follows the same steps as text collection. In addition,
speech data with their dierent types (audio or video) and formats (mp3, wave, avi, etc),](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-20-2048.jpg)
![6 Chapter 1. Linguistic Resources
are collected with dierent ways. The easier one, is to download streaming videos and
audios from the Internet. Unfortunately, in this method, we couldn't guarantee the
good quality of data. Otherwise, we need to refer to recording method where we could
x subjects and speakers dialects as we wish. At the same time, we could ensure a best
quality of data. However, we need funding to pay speakers and to buy specic equipments
for recording.
Some annotation tools [Kipp 2011] give the possibility to access directly to the broad-
cast data by using the associated Uniform Resource Locator (URL) which overcame the
step of collection. Regrettably, this feature is currently not available in the used voice
annotation tools.
1.3 Arabic Corpora
The Arabic language is composed of a collection of standard written language (Modern
Standard Arabic) and spoken dialects lanquage. The Arabic dialects are used extensively
in almost all everyday conversations. Therefore, they have a considerable importance.
However, owing to the lack of data and of poor resources, Natural Language Processing
(NLP) technology for Arabic dialectal is still in its infancy. Therefore, basic resources,
tokenizers, and morphological analyzers which are developed for Modern Standard Arabic
(MSA), are yet virtually non-existent for dialectal.
1.3.1 Modern Standard Arabic Corpora
There are many research projects involved in MSA corpora's development such as the
updated version of the Open Source Arabic Corpora (OSAC) described in [Saad 2010]
which include corpora; The British Broadcasting Corporation (BBC) Arabic corpus col-
lected from bbcarabic.com, the Cable News Network (CNN) Arabic corpus collected from
cnnarabic.com, and the Open Source Arabic Corpus (OSAc) collected from multiple sites.
The OSAC corpus contains about 23 Mega after removing the stop words.
Foreign Broadcast Information Service (FBIS) corpus is another corpus for MSA cre-
ated by [Messaoudi 2005] and used in [Vergyri 2004]. The data set comprises a collection
of radio newscasts from various radio stations in the Arabic speaking world (Cairo, Dam-
ascus, Baghdad) totalling approximately 40 hours of speech roughly 240K words. The
transcription of the FBIS corpus was done in Arabic script only and does not contain
any diacritic information.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-21-2048.jpg)
![1.3. Arabic Corpora 7
The Linguistic Data Consortium (LDC) provided the Penn Arabic Treebank
[Duh 2005] which is a data set of newswire text from Agence France Press, An Na-
har News, and Unmah Press transcribed in standard MSA script. There are more than
113,500 tokens which are analyzed and provided with disambiguated morphological in-
formation.
1.3.2 Dialectal Corpora
At present, the major standard dialect corpora are available through the LDC by the
DARPA EARS (Eective, Aordable, Reusable Speech-to-Text) program where develop-
ing robust speech recognition technology to address a range of languages and speaking
styles, and which includes data from the Egyptian, Levantine, Gulf, and Iraqi dialects.
Also, the LDC provides conversational and broadcast speech with their transcripts.
The Levantine Arabic (LA) is presented by the Levantine Arabic QT Training Data
Set [Maamouri 2006a] which is a set of phone conversations of Levantine Arabic speakers
[Duh 2005]. Furthermore, the data set contains approximately 250 hours of telephone
conversations. About 2000 successful calls have been collected which are distributed in
terms of regional dialect (Levantine, Egyptian, Gulf, Iraqi, Moroccan, Saudi, Yemeni).
Also, LA provided both the conversations speech and their transcript.
Moreover, another Arabic colloquial corpora called CALLHOME Egyptian Arabic
Speech (ECA), which has been used in [Duh 2005, Gibbon 1983], was dedicated to the
Egyptian dialect. Indeed, the data set consists of 120 telephone conversations between
native speakers of Egyptian dialect. In fact, ECA corpus contains both dialectal and
MSA words forms. Also, ECA was accompanied by a lexicon containing the morpholog-
ical analysis of all words, an analysis in terms of stem and morphological characteristics
such as person, number, gender, POS, etc.
Last but not least, the Saudi Arabic dialect was represented by the Saudi Accented
Arabic Voice Bank (SAAV B) [Alghamdi 2008] which is very rich in terms of its speech
sound content and speaker diversity within the Saudi Arabia. The duration of the total
recorded speech is 96.37 hours distributed among 60,947 audio les. Indeed, SAAV B
was externally validated and used by IBM Egypt Branch to train their speech recognition
engine.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-22-2048.jpg)
![8 Chapter 1. Linguistic Resources
English-Iraqi corpus is another Arabic corpora mentioned in [Precoda 2007] and which
consists of 40 hours of transcribed speech audio from DARPA's Transtac program.
Many small corpora were developed in order to satisfy specic needs like described
in [Al-Onaizan 1999, Ghazali 2002, Barkat-Defradas 2003] where ten speakers originally
from the western zone (Egyptian Arabic, Syrian, Lebanon and Jordan) and Moroccan
Arabic area (Algeria and Moroccan) who are listening to the story the north wind and
the sun in French and translated spontaneously into their dialects.
Some other research projects are limited to the collection of dialectal text data, for
example the Arabic Online Commentary Dataset (AOC) mentioned in [Zaidan 2011]
created with crawling the websites of three Arabic newspapers (Al-Ghad, Al-Riyadh,
Al-Youm Al-Sabe), the commentary data consists of 52.1M words and includes sentences
from articles in the 150K crawled webpages. In fact, 41% of the data content had dialectal
words.
Additional to the AOC, an Arabic-Dialect/English Parallel Text was developed by
Raytheon Bolt, Beranek and Newman (BBN) technologies, LDC and Sakhr Software.
Infact, this corpus contains approximately 3.5 million tokens from Arabic dialect sentences
with their English translations. Data in this corpus consist of Arabic web text that was
ltered automatically from a large Arabic text corpora provided by the LDC.
1.4 Orthographic Transcription
The acoustic signal of audio content may correspond to speech, music or noise, but also
mixtures of speech, music and noise. In addition to that, there is a variety of speakers and
topics in the same record. Indeed, transcribers can work on a given subject successively
or simultaneously. The sound quality of the recording (delity) may vary signicantly
over time.
Dierent stages of transcription work are: the segmentation of the soundtrack, the
identication of turns and speakers, the orthographic transcription, and verication. De-
pending on the choice of the transcriber, these steps can be conducted in parallel or
sequential manner instead of long portion of the signal.
The diculty of transcribing depends on the number of speakers involved in the record-
ings and their clear pronunciation. Processing many les in quick succession does not
make the work faster as the exhaustion slows down the process. Also, it is preferable](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-23-2048.jpg)
![1.4. Orthographic Transcription 9
to take a rest between each le. In [Al-Sulaiti 2004] the average time for transcribing
a ve-minute Arabic spoken record for a non-professional typist, without including any
enriched orthographic annotation, is 1:50:42. The average time is the average between
the shortest and the longest time taken in transcription.
The step of annotation aim at structure the recording, which means to be segmented
and to describe the acoustic signal at dierent levels deemed relevant for the further
processing. The transcription could not reect neither the audio record perfectly nor
pronunciation of a same subject/term, and could be the subject of a deepen study on
semantic and syntax, pronunciation analysis.
Manual transcription of audio recordings such as radio or television streaming, will ad-
vance research in automatic transcription, indexing and archiving. Indeed, the transcrip-
tion will provide a linguistic resource and data that make possible the construction of an
automatic recognition system, which will be then used to produce automatic transcrip-
tion.
1.4.1 Transcription Software
There are dierent types of tools for labelling and annotation of speech corpora.
Some of them are addressed for audio formats such as Transcriber [Barras 2000], Praat
[D.Weenink 2013], SoundIndex1
, and AMADAT 2
, and other for video formats for exam-
ple Anvil [Kipp 2011] and EUDICO Linguistic Annotator (ELAN) [Dreuw 2008].
• Transcriber is a free software and has been used in many projects such as
[Messaoudi 2005, Piu 2007, Fromont 2012] and becoming very popular due to its
simplicity and eciency as it provides in an easier way transcribing and labelling.
• Praat is a productivity tool for phoneticians. It allows speech analysis, synthesis, la-
belling and segmentation, speech manipulation, statistics, learning algorithms, and
manipulation package includes statistical stu,produces publication-quality graph-
ics.
• SoundIndex is a tool that allows user to write tags audio at any level in the
hierarchy of an XML le by setting values for attributes such as the start and the
end of audio in the sound editor. The interpretation of tags audio is written in
XSL.
1Software documentation on http://michel.jacobson.free.fr/soundIndex/Sommaire.htm.
2AMADAT User Guidelines on http://projects.ldc.upenn.edu/EARS/Arabic/EARS_AMADAT.htm.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-24-2048.jpg)
![10 Chapter 1. Linguistic Resources
• Arabic Multi-Dialectal Transcription Tool (AMADAT) allows transcribing speech,
and gives a very helpful functionality that provides a correction level.
• Anvil is a free video annotation tool. It oers frame-accurate, hierarchical multi-
layered annotation driven by user-dened annotation schemes. The color-coded
elements which have been noted on multiple tracks in time-alignment had been
shown by the initiative board. Also, special features are cross-level links, non-
temporal objects and are as project tool for managing multiple annotations. It
allows the importation of data from the widely used, public domain phonetic tools
Praat and XWaves. Anvil's data les are XML-bad.
• ELAN is an annotation tool that allows creating, editing, visualizing and search-
ing annotations for video and audio data. This software aims to provide a sound
technological basis for the annotation and exploitation of multi-media recordings.
Adding to that, ELAN is specically designed for the analysis of language, sign
language, and gesture, yet it can be used in media corpora, with video and/or audio
data, for purposes of annotation, analysis and documentation.
1.4.2 Transcription Guidelines
The transcription process follows specic agreements to provide structured records in
thematic content, speakers, and other speech information. These tools produce informa-
tion which are called annotations. Nowadays, a lot of conventions have been made in
NLP projects to satisfy the need of homogeneous transcription manner and to provide
annotation enrichments. Generally, these conventions are depending on the used speech
data format and on the transcription tool.
When a speech corpus is transcribed into a written text, the transcriber is immediately
confronted with the following question: What are the reects of the oral speech realty in
a corpus?
A set of rules for writing speech corpora are designed to provide an enriched ortho-
graphic transcription. These conventions establish the annotated phenomena. Numerous
studies have been carried out in prepared speech, as for example for broadcast news
[Cam 2008].
However, conversational speech refers to an activity more informal, in which partici-
pants have constantly managed topic, dened speakers and distinguished speech turns
which correspond to changes in speaker [Gro 2007, Cam 2008, André 2008]. As a conse-
quence, numerous phenomena appear such as hesitations, repeats, feedback, backchan-](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-25-2048.jpg)
![1.4. Orthographic Transcription 11
nels, etc. Other phonetic phenomena such as non-standard elision, reduction phenomena
[Meunier 2011], truncated words, and more generally, non-standard pronunciations are
also very frequent. All these phenomena can impact on the phonetization.
Hence, identifying dierent types of pause; long pause between turn-taking and short
pause between words, is very useful for a further purpose such as the development of a
voice recognition system [Alotaibi 2010].
In [Gro 2007] conventions focus on segment structures presented by elongation, trun-
cation, aspirations, sigh. The spontaneous oral production is a real problem in term of
annotation awing to according to [Shriberg 1994]:
Disuencies show regularities in a variety of dimensions. These regularities
can help guide and constrain models of spoken language production. In addi-
tion they can be modeled in applications to improve the automatic processing
of spontaneous speech.
Another denition of disuencies in [Piu 2007]:
Disuencies (repeats, word-fragments, self-repairs, aborted constructs, etc)
inherent in any spontaneous speech production constitute a real diculty in
terms of annotation. Indeed, the annotation of these phenomena seems not
easily automatizable, because their study needs an interpretative judgement.
In fact, there are dierent types of disuencies as described in [Piu 2007]:
• Repetition disuency is among the most frequent types of disuency in conversa-
tional speech (accounting for over 20% of disuencies), according to [Cole 2005]:
Repetition disuencies occur when the speaker makes a premature com-
mitment to the production of a constituent, perhaps as a strategy for
holding the oor, and then hesitates while the appropriate phonetic plan
is formed.
• Self-correction as described in [Kurdi 2003] is the substitution of a word or series
of words from an others, to modify or correct a part of the statement.
• In [Pallaud 2002] high lighted primers as an interruption morpheme being enuncia-
tion. Generally, disuencies could be combined simultaneously with the association
of at least two of phenomena mentioned above.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-26-2048.jpg)
![12 Chapter 1. Linguistic Resources
In [Dipper 2009]:
Transcription guidelines specify how to transcribe letters that do not have a
modern equivalent. They also specify which letter forms represent variants
of one and the same character, and which letters are to be transcribed as
dierent characters.
In [Cam 2008] there are numerous transcription rules related to the speech-text such
as how to write letters, punctuation, numbers, Internet addresses, acronyms, spelling,
abbreviations, hesitations, repetitions, truncation, absent or unknown words. Also a
list of markups was used to identify noise, pronunciation problems, back channel, and
comments.
In [André 2008] the specic pronunciations were recorded with the SAMPA phonetic
alphabet. General roles for transcribing the short vowels spelling, and diacritics have
been presented by The LDC Guidelines For Transcribing Levantine Arabic
3
.
1.5 Conclusion
Despite all the attempts made by the LDC and the other research projects to provide
speech corpora for Arabic dialects, some languages like Arabic Tunisian Dialects (TD)
still needs more improvements in corpus construction. Yet, these attempts knew several
challenges. Some of them are related to Arabic language and to general NLP issue.
Moreover, there are some problems that could be noticeable during the process of speech
transcription such as the ambiguity of the word transcription. Another problem accrued
when multiple sound sources are present, then it is necessary to focus on the transcription
source most emerging. As well, when two speakers are talking in the foreground, we could
transcribe both through the mechanism of super imposed speech.
3The Guidelines are available on the LDC website http://ldc.upenn.edu/Projects/EARS/Arabic/
www.Guidelines_Levantine_MSA.htm](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-27-2048.jpg)
![Chapter 2
Morpho-Syntactic Annotation
2.1 Introduction
A transcript could be annotated by adding linguistic information for each word. In
[Sawaf 2010] a denition of linguistic Annotation is: Corpus annotation is the practice
of adding interpretative, especially linguistic, information to a text corpus, by coding
added to the electronic representation of the text itself. Indeed, grammatical tagging is
the task of associating a label or a tag for each word in the text to indicate its grammatical
classication.
Generally speaking, the morpho-syntactic annotation process relies on word structure
as described in [Al-Taani 2009]. Accordingly, patterns and axes are used to deter-
mine the word grammatical class following a dened rules. Moreover, this process
diers according to the used data and resources. Therefore, approaches used in the
morpho-syntactic annotation process vary from supervised to unsupervised as described
in [Jurafsky 2008].
In the following sections we introduce morpho-syntactic annotation methods for the Mod-
ern Standard Arabic (MSA) language and Tunisian Dialect (TD) languages.
2.2 Morpho-syntactic Annotation Methods for MSA
Language
The morpho-syntactic annotation process for MSA has been performed using dif-
ferent approaches such as statistical approach [Al-Shamsi 2006] and learning approach
[Bosch 2005]. Recently, some works combine approches to improve the performance of
the developped tagger. In the following, a description of some works.
The statistical approach was used in the work of [Al-Shamsi 2006] to handle the POST
of Arabic text. Indeed, the developed method was based on the HMM and followed these](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-28-2048.jpg)
![14 Chapter 2. Morpho-Syntactic Annotation
steps:
1. Creation of a set of tags,
2. Employment of Buckwalter's stemmer to stem Arabic text from the used corpus
which contains 9.15 MB of native Arabic articles,
3. Manually correction of tagging errors,
4. Design and construction of an HMM-based model of Arabic POS tags,
5. Training of the developed POST on the annotated corpus.
The proposed method achieved an F-measure score of 97%.
Another tagging system for Arabic POST was proposed by [Hadj 2009]. The POS
tagging task of the system is based on the sentence structure and combines morphological
analysis with HMM:
- The morphological analysis was aimed to reduce the size of the tags lexicon by seg-
menting words in their prexes, stems, and suxes.
- The HMM was used to represent the sentence structure in order to take in account
the logical linguistic sequencing.
Each possible state of the HMM presents a tag. The transitions between those states
are governed by the syntax of the sentence.
The training corpus data is composed of some old texts extracted from Books of third
century. These data were manually tagged using the developed tagset. The system
evaluation was based on the same corpus. The obtained result achieves a recognition rate
of 96%, which is considering as very promising compared to the size of tagged data.
In addition to the statistical approaches, recent applications tend to explore the use of
a machine learning methods to handle the Arabic morphology and POS tagging process.
Indeed, a memory-based learning approach was developed by [Bosch 2005] in order to
morphologically analysis and part-of-speech tagging of written Arabic. The learning
classication task in the memory-based learning was performed by employing the k-
nearest neighbor classier that searches for the k nearest neighbors. The memory-based
learning, which is a supervised inductive learning algorithm, treats a set of labeled training
instances as points in a multi-dimensional feature space. Then, stores these instances as
such in an instance base in memory. Furthermore, [Bosch 2005] employed a modied](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-29-2048.jpg)
![2.2. Morpho-syntactic Annotation Methods for MSA Language 15
value dierence metric distance function to determine the similarity of pairs of values
of a feature. The used metric explores the conditional probabilities of the two values
conditioned on the classes to determine their similarity.
In order to train and test the developed approach, [Bosch 2005] exploited the Arabic
Treebank 1 (version 2.0) corpus which is consisting of 166,068 tagged words. Evaluat-
ing the morphological analyzer was based on predicting the part-of- speech tags of the
segments, the positions of the segmentations, and all letter transformations between the
surface form and the analysis. The obtained results in term of precision, recall, and F-
score are consequently 0.41, 0.43 and 0.42. Also, the POS tagger attained an accuracy of
66.4% on unknown words, and 91.5% on all words in held-out data.
Furthermore, combining the morpho-syntactic analysis generated from the morpholog-
ical analyzer and the part-of-speech predicted by the tagger yields a joint accuracy of
58.1%. This accuracy represents the correctly predicted tags and corresponds to the full
analysis for unknown words. The main limitation of the memory-based learning approach,
as concluded in [Bosch 2005], was its inability to recognize the stem of an unknown word
and accordingly the appropriate vowel insertions.
Another approach combine statistical and rule-based techniques was introduced by
[Khoja 2001] in order to construct an Arabic part-of-speech tagger. First, the developed
approach is based on: The use of traditional Arabic grammatical theory to determine
rules used while stemming a word. These rules are used to determinate stem or root by
removing axes (prexes, suxes and inxes). Second, this approach used lexical and
contextual probabilities. The lexical probability is the probability of a word having a
certain grammatical class. Whereas the contextual probability is the probability of one
tag following another tag. These probabilities are calculated from the tagged training
corpus.
The used method consists on searching a word in the lexicon to determine its possible
tags. The words not found in the lexicon are then stemmed using a combination of axes
to determine the tag of the word. Finally, in order to disambiguate ambiguous words and
unknown words, [Khoja 2001] used a statistical tagger that was based on the Viterbi
algorithm [Jelinek 1976].
In order to train the tagger and to construct the lexicon, [Khoja 2001] used a corpus
that contains 50,000 words in Modern Standard Arabic extracted from the Saudi Al-](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-30-2048.jpg)
![16 Chapter 2. Morpho-Syntactic Annotation
Jazirah newspaper. That is manually tagged. The constricted lexicon contains 9,986
words. In order to test the developed tagger, four corpora (85159 words) were collected
from newspapers and papers in social science. In addition to MSA words the test corpus
contained some colloquial words. The statistical tagger achieved an accuracy of around
90% when disambiguating ambiguous words.
Furthermore, [Khoja 2001] used Arabic dictionary (4,748 roots) to test the developed
stemmer. The obtained result in terms of accuracy achieves 97%. As well the unana-
lyzed words are generally foreign terms and proper nouns, as incorrect writing words,
[Khoja 2001] conclude that employing a pre-processing component could solve the prob-
lem.
2.3 Morpho-syntactic Annotation Methods for Di-
alects Arabic Language
In [Maamouri 2006b] a description of a supervised approach was used to annotate di-
alect Arabic data. Indeed, a word list of the Levantine Arabic Treebank (LATB) data
was used to manually annotate the most frequent surface forms. Then, perform the pat-
tern matching operations to identify potential new prex-stem-sux combinations among
the remaining unannotated words in the list.
Furthermore, the Morphological/Part-of-Speech/Gloss (MPG) tagging included morpho-
logical analysis, POST, and glossing.
The evaluation of the developed system was based after and before by using dictionary.
The evaluation result shows that there is more than 10% reduction of annotation error.
Another supervised approach in [Duh 2005] was designed for tagging the dialectal Ara-
bic using LCA data. The developed system is based on using a statistical trigram tagger
in the form of a HMM and Baseline POST. Indeed, a statistical modeling and cross-
dialectal data sharing techniques were used to enhance the performance of the baseline
tagger. The adopted approach requires only original text data from several varieties of
Arabic and a morphological analyzer for MSA. So, there is no dialect-specic tools were
used.
To evaluate the developed system, [Duh 2005] compare between the obtained results
with those received ones when using:](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-31-2048.jpg)
![2.3. Morpho-syntactic Annotation Methods for Dialects Arabic Language17
- a supervised tagger which were trained on hand-annotated data.
- a state-of-the-art MSA tagger applied to Egyptian Arabic.
As a result, there is 10% improvement of the ECA tagger.
Additionally to the supervised approaches, other projects tend toward the use of un-
supervised approach for example [Chiang 2006].
An Arabic dialects parser was described in [Chiang 2006] where three frameworks were
constructed for leveraging MSA corpora in order to parse LA. This process was based
on knowledge about the lexical, morphological, and syntactic dierences between MSA
and LA .
[Chiang 2006] evaluated three methods:
• Sentence transduction : in which the LA sentence to be parsed is turned into an
MSA sentence and then parsed with an MSA parser;
• Treebank transduction : in which the MSA treebank is turned into an LA treebank;
• Grammar transduction : in which an MSA grammar is turned into an LA grammar
which is then used for parsing LA.
The used MSA treebanks data, comprises 17,617 sentences and 588,244 tokens. Indeed,
it is composed of four dierent lexicons: Small lexicon with uniform probabilities, small
lexicon with EM-based probabilities, big lexicon with uniform probabilities, and big lex-
icon with EM-based probabilities.
To evaluate the developed parser, [Chiang 2006] used data that comprise 10% MSA tree-
banks and 2051 sentences and 10,644 tokens from the Levantine treebank LATB. The
major limitation in this method as concluded in [Chiang 2006] is the non employment of
a demonstration of cost-eectiveness.
Another approach described in [Al-Sabbagh 2012] used a function-based annotation
scheme in which words are annotated based on their grammatical functions. Indeed, the
grammatical categories in which morpho-syntactic structures and grammatical functions
could be dierent from each other. The developed method was based on the implemen-
tation of a Brill's Transformation-Based POS Tagging algorithm.
The developed tagger was trained on a manually-annotated Twitter-based Egyptian Ara-
bic corpus which is composed of 22,834 tweets and contains 423,691 tokens. In order to
evaluate the developed POS tagger, ten cross validation were performed. The obtained](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-32-2048.jpg)
![18 Chapter 2. Morpho-Syntactic Annotation
results in term of F-measure are 87.6% for the task of POS tagging without semantic
feature labeling and 82.3% for the task of POS tagging with tokenization and semantic
features. The problem faced while analyzing is related to the three-letter and two-letter
words which are highly ambiguous and they can have multiple readings based on the
short vowel pattern.
Example:
The word ‰g
F
can be analyzed by the tagged as a:
Noun: meaning grandfather or seriousness.
Adverb: meaning seriously.
To solve this problem, [Al-Sabbagh 2012] concluded that a word sense disambiguation
modules is fundamental to improve performance on highly ambiguous words.
2.4 Conclusion
In this chapter, we introduced methods of morpho-syntactic annotation for MSA and
dialectal Arabic. The employment of approaches in morpho-syntactic annotation task
such as statistical and learning approach depend on the used resources data. Indeed, the
unsupervised techniques are not suitable for poor language resources such as the dialectal
languages. Therefore, the POS Tagging process for colloquial Arabic still needs more
improvement in term of corpus collection and annotation.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-33-2048.jpg)


![Chapter 3
Data Collection and Transcription
3.1 Introduction
The transcribing process consists of two basic steps: The rst one is performed to pro-
vide voice data in order to be transcribed later. The second step consists in transcribing
the voice data by following directives that we have established. Indeed, to allow a better
representation of spontaneous speech phenomena, these directives take in consideration
the TD transcript specication. More details about those two steps are described in the
following sections.
3.2 Speech Collection
The aim of this section is to provide speech data which is the rst step in corpus
creation. Choice of the speech data content and type is very important and could be
the key of further use of our corpus. That is to say, we choose to provide both audio
and video speech to improve the use of our corpus in new research tendency especially in
video annotation [Kipp 2011].
Furthermore, including dierent TD (Sfaxian dialect, Sahel dialect, etc) will improve
the representativeness of the TD in our corpus. To provide speech data, we used broadcast
conversational speech to be the main source of speech data in our corpus as used in these
two projects [Lamel 2007] and [Belgacem 2010]. These streaming are generally radio and
television talk shows, debates, and interactive programs where the general public are
invited to participate in discussion by telephone.
In general, the commune conversational dialect in Tunisia is the dialect of the capital,
the same used in national TV and radio stations and by the majority of educated people.
Consequently, we have allocated the largest part of our corpus to this dialect.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-36-2048.jpg)
![22 Chapter 3. Data Collection and Transcription
Providing speech data with a variety of themes will increase the size of the vocabulary
in our corpus and will be very useful for further application for example theme classica-
tion [Bischo 2009]. Indeed, we dened the following theme's list in our data selection:
Religious, Political, Cooking, Health, and Social. The latter could include record-
ings that refer to more than one theme. We also dene the Other tag to assign other
types of themes.
Figure 3.1 shows the proportion of each theme in our corpus.
Figure 3.1: The proportion of themes in the corpus
Having a good amount of spoken recordings is fundamental in the design of the corpus.
Also, a high sound quality is required and will be useful for other future processing
for example in voice recognition system. In addition, we provided both individual and
multiple speakers in our collection to identify dierent aspects of conversational speech.
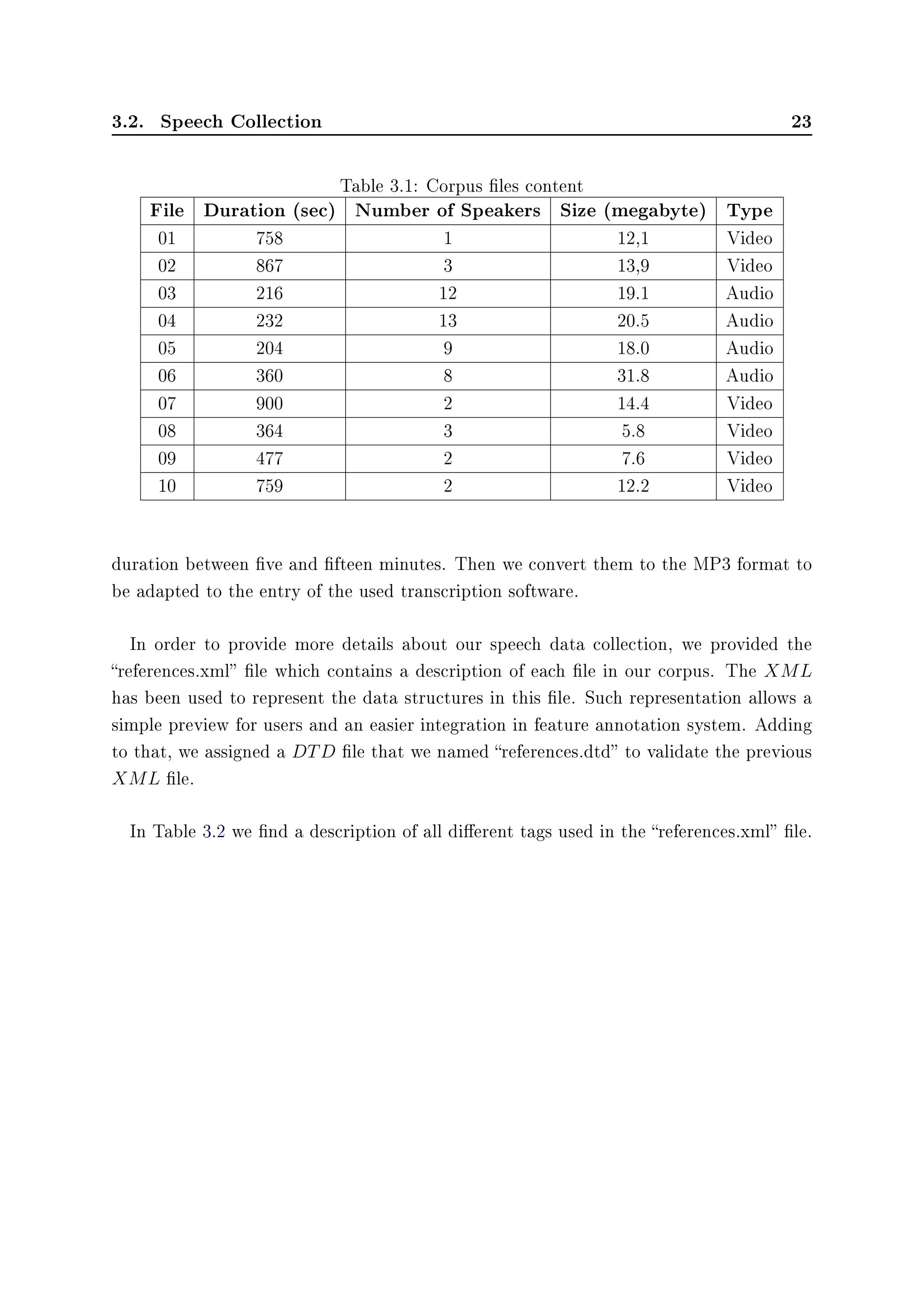
In table 3.1 a description of each transcription le in our corpus. The transcribed les
achieved a duration of 1 hour and 25 minutes and 37 seconds.
The collected data les generally have a long duration that exceeds fteen minutes; to
simplify the transcription task we split these records in order to obtain sequences with](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-37-2048.jpg)
![24 Chapter 3. Data Collection and Transcription
Table 3.2: Description of tags used in the references XML le
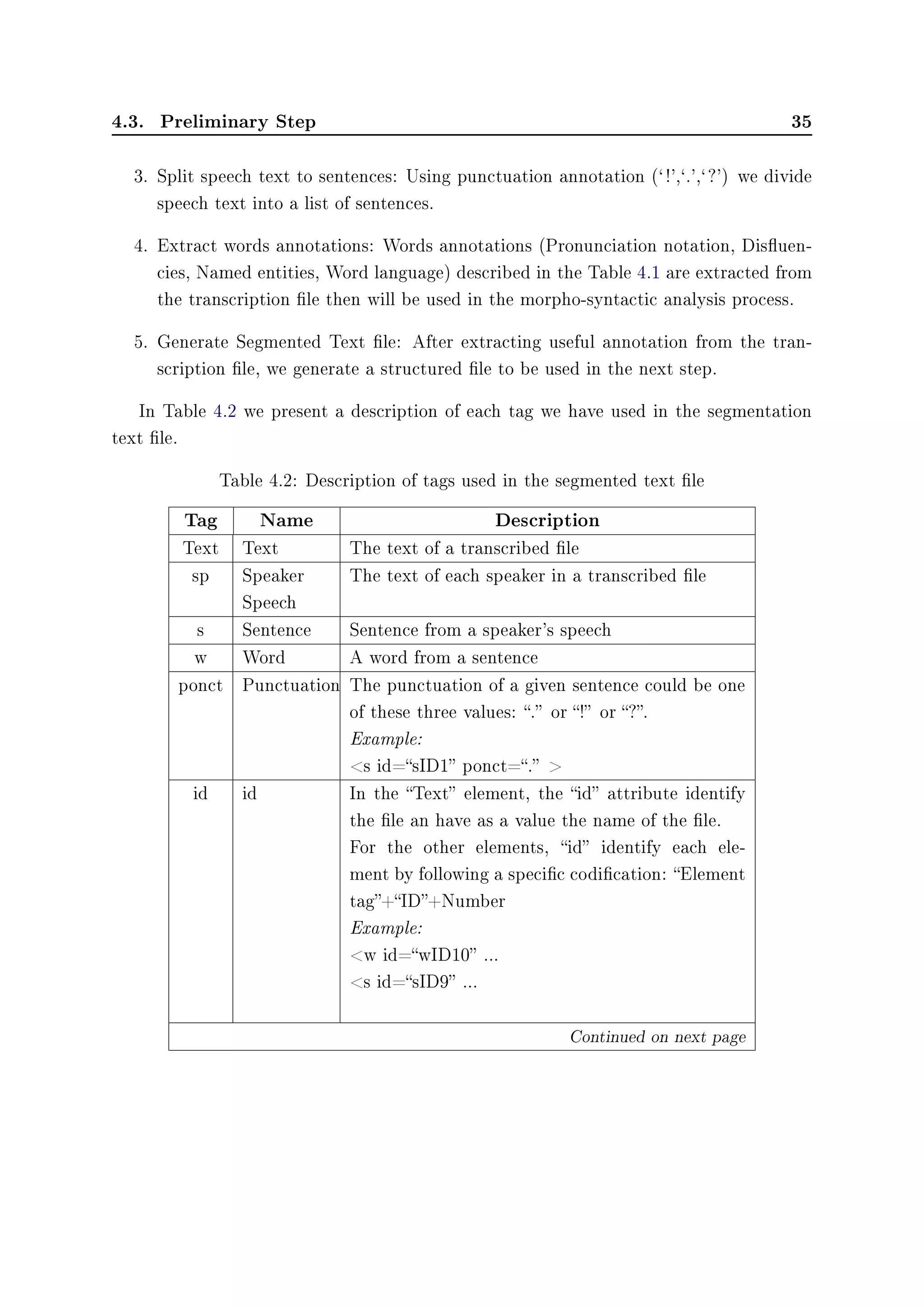
Label Type Name Unit Description
ID Integer Identier Identier of record
NAM String Name Name of record
DUR Integer Duration sec Duration of record
TOP List Topic Topic of record
NBMASP Integer Number of
male speaker
Number of
male speakers in a record
NBFESP Integer Number of
female speaker
Number of female speakers
in a record
FISI Float File Size megabyte File Size of a record record
SOFITY List Source File
Type
Source File Type of a record
(TV or Radio)
SONAM String Source Name Source Name of a record
SOFIEX String Source File
Extension
Source File Extension of a
record
SOFISI Float Source File
Size
megabyte Source File Size of a giving
record
SOTY List Source Type Source Type of a giving
record (Audio or Video)
SODA Date Source Date Source Date of a record
SOLI String Source Link Source Link of a record
3.3 Transcription Process
The speech annotation process includes the segmentation of the sound track, the iden-
tication of turns and speakers, and the orthographic transcription. We applied these
steps in a parallel manner taking in consideration notes in Orthographic Transcription
of Tunisian Arabic [Zribi 2013] and in the Directive of Transcription and Annotation
of Tunisian Dialects.
The rst voice le (duration of 12:38 sec) was transcribed in the beginning with the
Speech Assessment Methods Phonetic Alphabet (SAMPA) for Arabic. We thought that
using SAMPA for Arabic will allow a better representation of phonetics. However,
during transcribing process we nd that it is better to use the Arabic script including
diacritics instead of the SAMPA for Arabic. So we adopt the Arabic transcript in the](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-39-2048.jpg)
![3.3. Transcription Process 25
transcription process.
Transcribing Arabic spoken recordings is a very long task, especially when using Arabic
script and diacritics. For example, a recording that lasts 3 minutes 52 sec, yet took more
then 4 hours. Actually, the transcribing of each minute takes at least one hour; 15-
20 minutes for the identication of turns and speakers, 40-45 minutes for transcribing,
following rules in our directives.
3.3.1 Transcription Tools
There is a variety of transcribing tools (SoundIndex, AMADAT, XWaves, etc) for voice
data. We selected Transcriber [Barras 2000] and Praat [D.Weenink 2013] to handle the
transcribing task. The software Transcriber was adopted according to the following
advantages:
Simple user interface:
• Supports many languages (including English, French and Arabic).
• Easier way to manipulate the voice interval.
• Supports the use of keyboard shortcuts in annotation.
Very rich in term of annotation:
• Dened annotation events (noise list, lexical list, named entities list, etc).
• Possibility of edit or add additional annotation.
Input le Flexibility:
• Accepts long speech File duration.
• Supports various le formats (au, wav, snd, mp3, ogg, wav, etc).
Better output representation:
• Supports many types of encoding (UTF-8, ISO-8859-6, etc).
• The output File follows a description schema.
Concerning Praat software, the choice was related to our ANLP research group needs.
In addition, Praat gives a better representation of speech overlapping and allows speech
analyzes.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-40-2048.jpg)
![26 Chapter 3. Data Collection and Transcription
3.3.2 Transcribing Guidelines
Transcription guidelines are made in order to be followed during the annotation process
of our speech data. We elaborated the Orthographic Transcription of Tunisian Arabic
directives [Zribi 2013] which are adapted from the Enriched Orthographic Transcription
(TOE in French) [Bigi 2012]. To deal with the TD, some rules have been modied or
removed. As the Standard orthographic transcription doesn't take into consideration the
observed phenomena of speech (elisions, disuency, liaison, noise, etc), we enriched our
directives with them.
The Directive of Transcription and Annotation of Tunisian Dialects directive was
made to give additional annotation concerning phonemic and phonetic in speech data.
Indeed, examples were included to show the application of these rules in the Transcriber
software. The directive was adapted from the ESTER2 convention [Cam 2008]. The
taking directive took in consideration the specicity of the Arabic language and the TD.
The following is a description of some conventions:
a) The identication of turns and speakers
- Sections :
We dened two sections in the audio document: the relevant section identied by
the title report and the not transcribed section identied by the title nontrans.
The sections not transcribed contains more than fteen seconds such as:
• Advertising, weather passages, generic emission,
• Applause,
• Music, songs,
• The beginning or the end of another show dierent from the current emission,
• Silence.
The other sections are relevant, so they are the only sections that we segment and
transcribe. The other sections are relevant, so they are the only sections that we
segment and transcribe as illustrated the example in Figure 3.2. The concept of
Sections is absent in Praat software, so we don't take in consideration these roles
while using it.
- Turn-taking
First, we identify each speaker involved in the audio document.
There are two types of speakers:](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-41-2048.jpg)
![3.3. Transcription Process 27
Figure 3.2: Sections and Turns in Transcriber
• Global: 1
speakers identied by the syntax First Last name.
• Local: 2
speakers identied with the syntax First Last name if possible.
Otherwise, we notice them by the syntax speaker # n; where n is the number
1 to n corresponding to the speakers order.
The same speaker must always appear with the same identier, also, the list of
speakers must contain only speakers involved in the audio document. In addition,
we complete all information relative to these speakers such as gender and dialect.
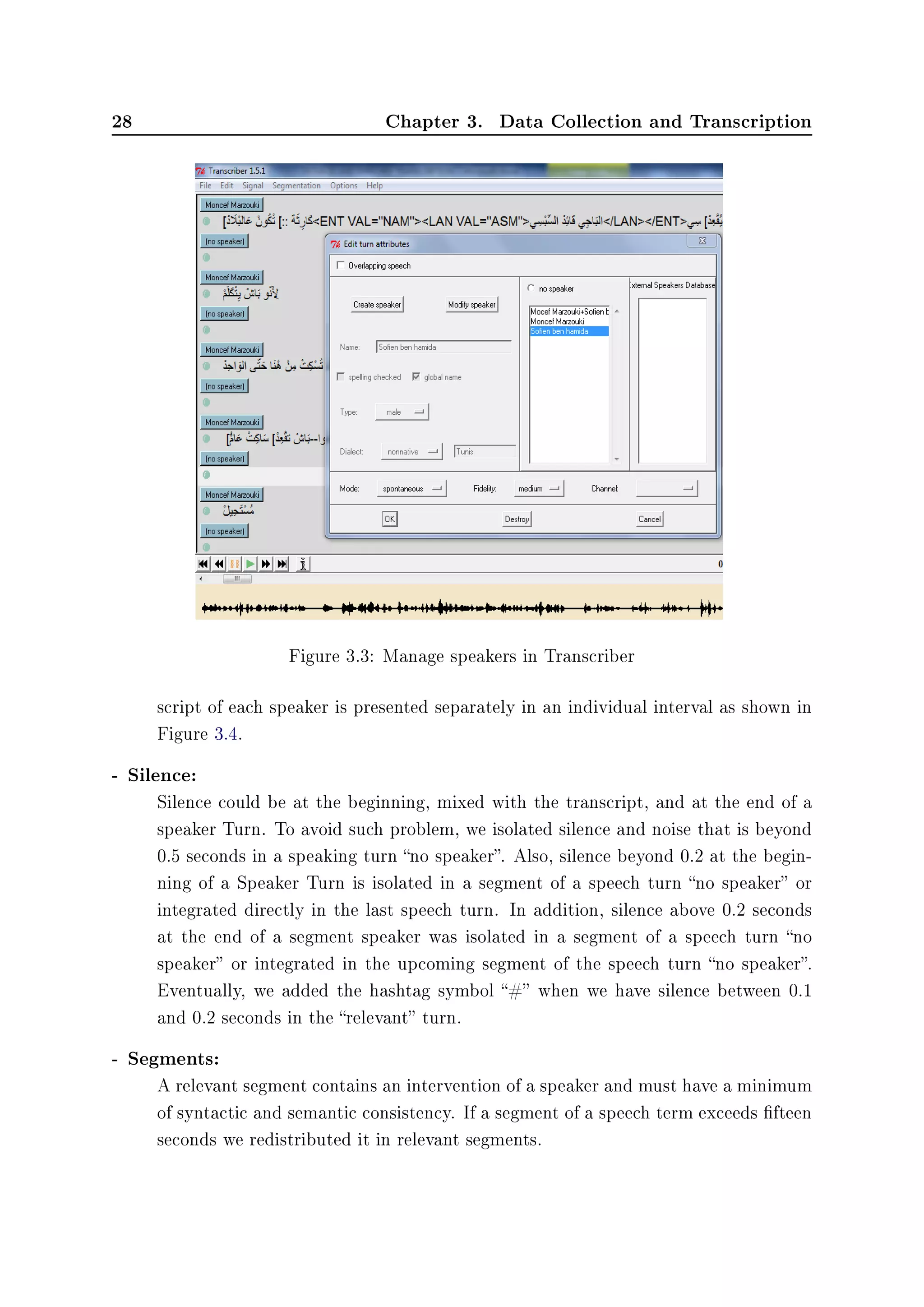
Second, we attribute the name of speaker to the Speech Turn. Although, speech
turns that do not contain speaker speech, are identied by the syntax no speaker.
The example in Figure 3.3 illustrates how to manage speakers in Transcriber soft-
ware.
To solve the problem of speech overlapping, we adapted the solution mentioned in
[Barras 2000] where we create a new speaker that we named with the syntax First
Last name speaker 1+ First Last name speaker 2.
Praat software gives a better representation of speech overlapping. In fact, the
1It is common to several audio speakers, such as the presenter, journalists, etc
2These are unknown speakers that intervene by telephone for example.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-42-2048.jpg)

![30 Chapter 3. Data Collection and Transcription
- Transcription of ta marbuta:
The ta marbuta (
è) should be written at the end of the word whether it is pro-
nounced /a/ or /t/.
Example:
ék e
©
®
u (an apple), É
©
®¢Ë d
éƒ d
» (book of child)
- Code switching:
MSA, TD and foreign languages coexist in the daily speech of Tunisian people.
The transcription of the MSA words should respect the transcription conventions
of the Arabic language.
The foreign words and MSA words should be written respectively using this form:
[lan:X, text or word, SAMPA pronunciation] and [lan:ASM, text or word]. We use
the SAMPA of the specic language for writing the speaker's pronunciation.
Example:
• MSA word: [lan:MSA, r
F
e
t» ]
• French word: [lan:Fr, informatique, ?anfurmati:ku]
• English word: [lan:En, network, na:twirk]
- Atypical accords:
We choose the standard orthographic transcription of the words as they have been
said.
Example:
ù
ë eu
F
é« g
©
m
Ì
9d (the holidays are wonderful) instead of
ét
ë eu
F
é« g
©
m
Ì
9d
- Personal pronouns:
Pronouns must be transcribed as found in this list:
e
©
u d (I), ú
æ
©
u d
(You), Õ
æ
©
u d
/ eÓñ
t
©
u d
(You), e
©
tm
©
9
/ e
©
tk
d (We), ñë (He), ù
ë (She), eÓñë (They)
- Names of months and days:
The names of the months and days must be transcribed as in the MSA language.
- Axes and clitics:
The Table 3.3 lists the dialectal clitics.
Note: the È d should be written even if it is pronounced l.
This rule is practical also for transcribing words which start with a sun or moon
letter.
- Named entities:](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-45-2048.jpg)
![3.3. Transcription Process 31
Table 3.3: Clitics in the TD language
Clitic Enclitic
Pronominal enclitic ¼, è, ð, eë, Ñë, Õ», e
©
u, ø
Negation enclitic
€
Interrogation enclitic ú
æ
…
Proclitic ð, È, r
F
, ¼, ¨, È d, Ð
We used these representations for annotating t
%
…
, PERSON NAME , ½Ó ,
Place name.
Examples:
t
%
…
, ú
q
F
m
F
Ì
9d ˆ eÔ
«
- Characters:
The following phonemes /v/, /g/ and /p/ does'nt exist in the Arabic language. To
transcribe them we add ' after these letters.
- Incorrect word:
When the speaker replaces a letter with an incorrect one, we keep the original letter
and we add to it the corresponding correct one. We have to represent these updates,
as the following example:
x{Correct letter, Original letter}x, x is a letter of the word.
c) Rules of marking
Transcribe what is heard (hesitation, repetition, onomatopoeia, etc). The transcript
should be close to the signal.
- Noise:
We insert the tag [i] to indicate breathing-inspiration or [e] to indicate breathing-
expiration of the speaker. Insert tag [b] to indicate a noise:
• Mouth noises (cough, throat noise, laughters, kisses, whisper, etc),
• Rustling of papers,
• Microphone noise.
Insert tag [musique] to indicate music.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-46-2048.jpg)




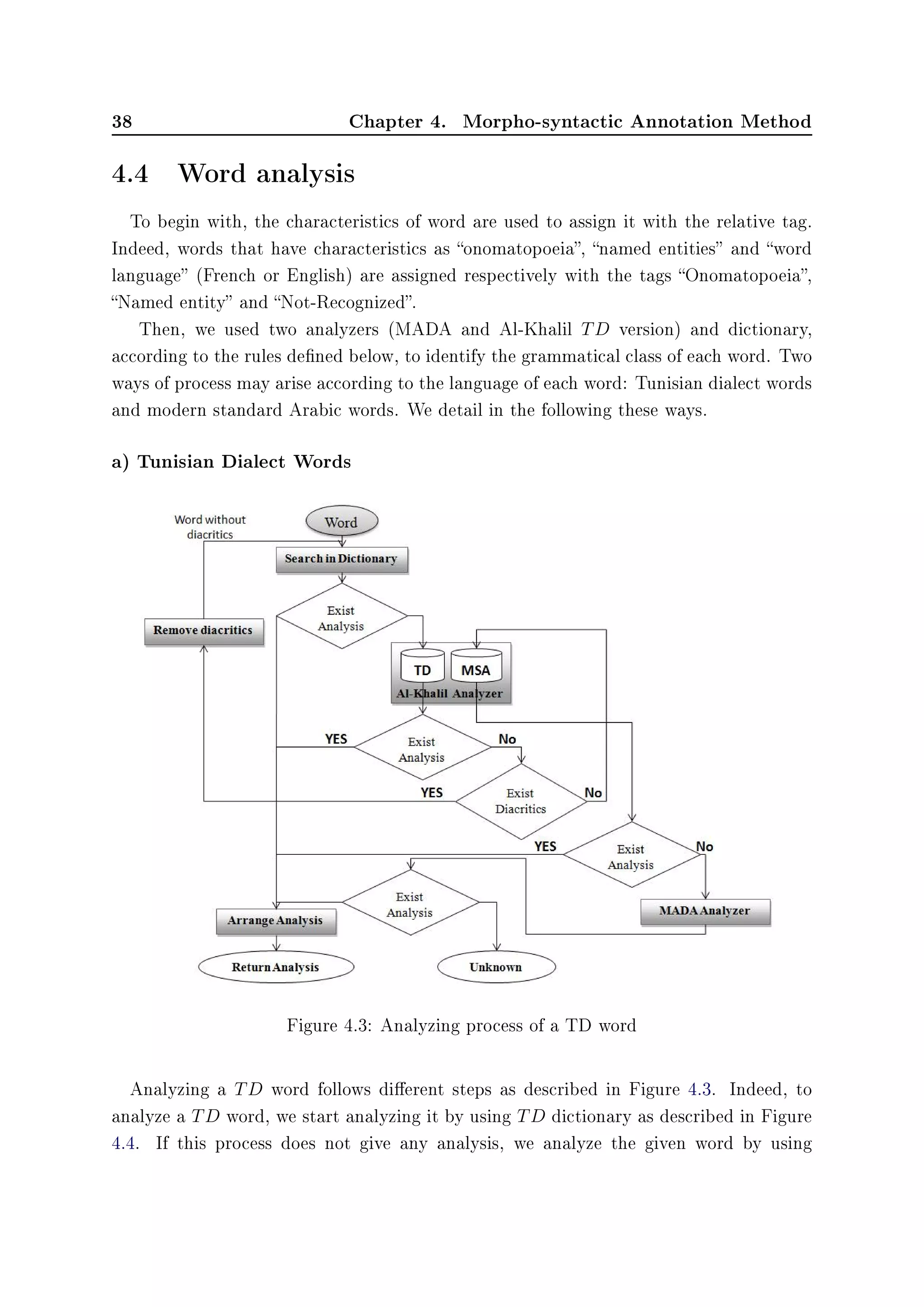
![4.4. Word analysis 39
Al-Khalil TD version analyzer. If the analyzed word is neither recognized by the TD
dictionary or Al-Khalil analyzer, we remove its diacritics and we reanalyze it with the
TD dictionary.
Analyzing a word without diacritics allows us to solve the problem of dierence in
writing diacritics of same words. For example word ©
Ẃ)
could be written ©
Ẃ)
or
©
Ẃ)
according to the dialect of the speaker.
If these process do not lead to any analysis, we reanalyse the given word without
diacritics by using Al-Khalil TD version analyzer. Finally, if there is no possible analysis
we analyze the given word with MADA analyzer. Indeed, many words without diacritics
are written at the same as in MSA or TD. Thus, analyzing these words with a MSA
analyzer could succeed in getting possible analysis.
During this process, if there is more than one analysis we precede to organize them.
When there is no possible analysis for a given word in our method, we assign it with
the tag unknown. Furthermore, our system allows the user to interfere by choosing the
correct one or by adding a new analysis. In the following Figure 4.4, more details about
the used procedure mentioned above.
Figure 4.3 illustrates these steps. Furthermore, our system allows the user to interfere
by updating analysis or by adding other analysis.
Analyzing with TD Dictionary:
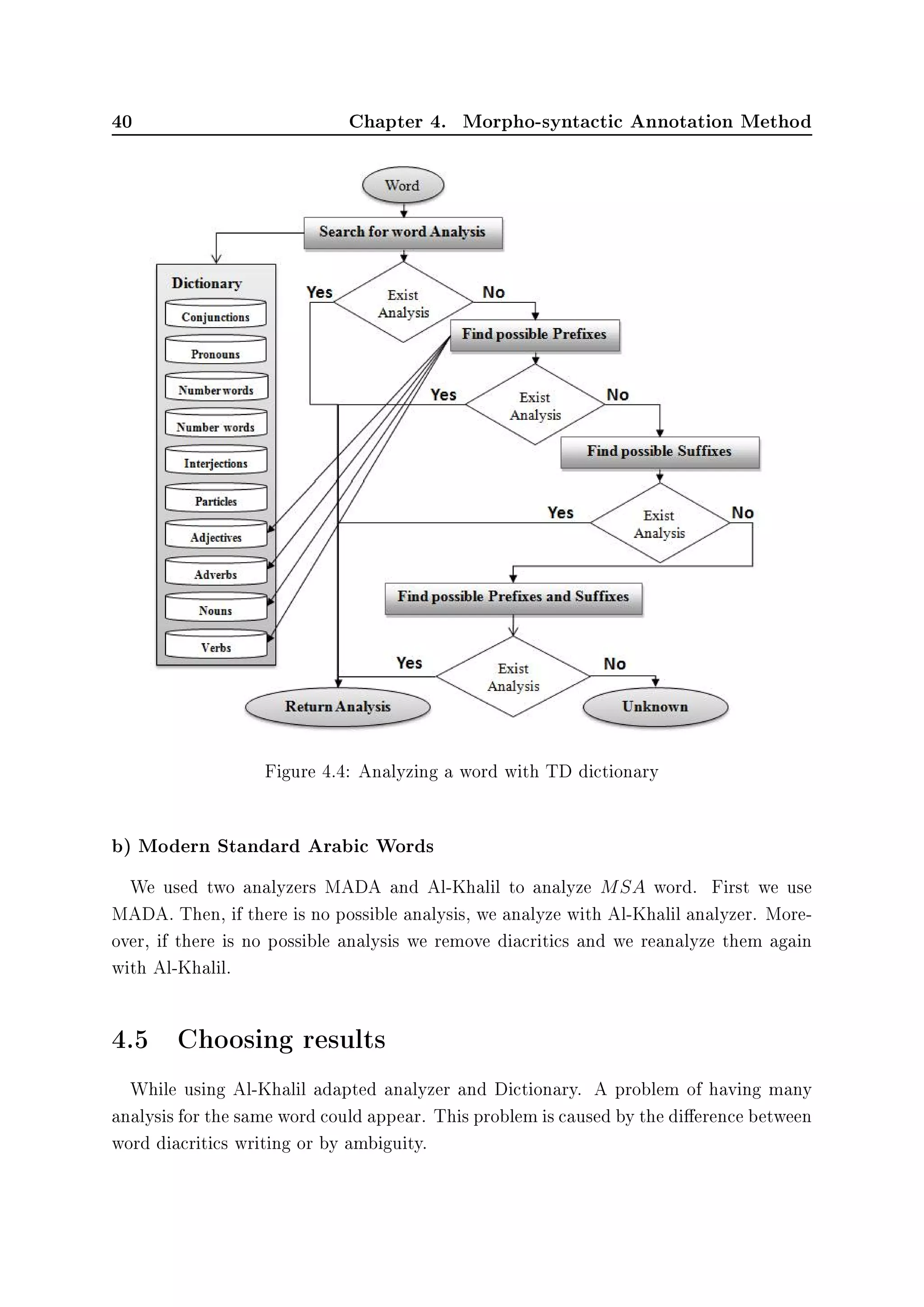
Analyzing a word using TD dictionary is handled by applying a morpheme segmenta-
tion method as used in [Yang 2007]. Figure 4.4 shows the dierent steps which had been
taken to analyze a word with the TD dictionary. These steps are executed sequentially
until we get an analysis result.
First, we search in the TD dictionary according to this order: Conjunctions, Pronouns,
Number words, Interjections, Particles, Adjectives, Adverbs, Nouns, Verbs. Second, we
look sequentially at Adverbs, Nouns, Verbs dictionary through trying all possible TD
prexes. Third, we do the same task with suxes. Finally, we resume the same procedure
with prexes and suxes.
Analysis Ranking:
We classify and conrm each word analysis according to the following order: TD
Dictionary, Al-Khalil TD version analyzer, MADA analyzer. Furthermore, if these tools
and resources give the same analysis, we keep one of them.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-54-2048.jpg)
![4.5. Choosing results 41
Problem with Al-Khalil analysis:
Usually, Al-Khalil adapted analyzer return a list of analysis for a given word with dif-
ferent information (gender, prex, sux, gender, number, person,voice, etc). In general,
this problem which is related to the ambiguity in Arabic language.
Problem while using dictionary:
The problem in dictionary analysis is related to word diacritics writing. To solve
the problem, we try to classify these results by comparing their distance to the original
word. Indeed, we used the Levenshtein distance [Haldar 2011] for measuring the dierence
between two sequences or words.
Mathematically, the Levenshtein distance between two strings a, b is given by
leva,b(|a|, |b|) where:
leva,b(i, j) =
0 , i = j = 0
i , j = 0 and i 0
j , i = 0 and j 0
min
leva,b(i − 1, j) + 1
leva,b(i, j − 1) + 1
leva,b(i − 1, j − 1) + [ai = bj]
, else
• leva,b(i − 1, j) + 1: The minimum corresponds to removing (from a to b).
• leva,b(i, j − 1) + 1: The minimum corresponds to insertion (from a to b).
• leva,b(i − 1, j − 1) + [ai = bj] : The minimum corresponds to match or mismatch
(from a to b), depending on whether the respective symbols are the same.
Example:
Original word: e
©
t(
‚Ó
Word returned while analyzing: e
©
t(
‚
Ó
⇒ Distance between two words is 2 as calculated in Table 4.3.
When we have analysis from both Al-Khalil TD version analyzer and TD dictionary
(case that we have problem with diacritics writing), we used the dictionary analysis to
conrm Al-Khalil analysis if they have the same grammatical function.
Finally, we generate the annotation le as described in the following section.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-56-2048.jpg)


![Chapter 5
Realization and Performance
Evaluation
5.1 Introduction
The expansion of NLP application for dialectal requires a high amount of resources
in terms of data and tools. By developing a morpho-syntactic annotation tool for the
TD language, we facilitate the morpho-syntactic annotation task which promotes to the
build of corpus.
In this chapter, we introduced the used tools and resources used in our tool. Then, we
present our TD annotation tool by explaining the dierent modules, functionality, and
by providing some details about the development environment. Finally, we experiment
our tool and we discuss the results obtained in dierent assessments.
5.2 Tools and Resources
The morpho-syntactic annotation process contains several tasks that can be handled
using tools and resources. In this section, we introduced the used analyzers and dictionary.
5.2.1 Al-Khalil analyzer
The Al-Khalil analyzer was developed to produce tags for a given text by executing a
morphological analysis of the text. The lexical resource consists of several classes that
handle vowelled and unvocalized words. The main process is based on using patterns for
both verbal and nominal words; Arabic word roots and axes.
Indeed, according to [Altabba 2010] Al-Khalil analyzer is still the best morphological
analyzer for Arabic. In addition, Al-Khalil won the rst prize at a competition by The
Arab League Educational, Cultural Scientic Organization (ALESCO) in 2010.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-60-2048.jpg)
![46 Chapter 5. Realization and Performance Evaluation
5.2.2 MADA analyzer
The MADA+TOKAN toolkit is a morphological analyzer that is introduced by
[Habash 2009] and used to derive extensive morphological and contextual information
from Arabic text. Indeed, the toolkit includes many tasks; high-accuracy part-of-speech
tagging, diacritization, lemmatization, disambiguation, stemming, and glossing. In ad-
dition, MADA classies the analysis results and gives as an output the more suitable
analysis to the current context of each word.
The analysis results carry a complete diacritic, lexemic, glossary and morphological
information. Also, TOKAN takes the information provided by MADA to generate to-
kenized output in a wide variety of customizable formats which allow an easier extraction
and manipulation. In addition, MADA achieved an accuracy score of 86% in predicting
full diacritization and 96% on basic morphological choice and on lemmatization.
5.2.3 Al-Khalil TD version
Recent research in our ANLP group [Amouri 2013] conducted the study of the dialect
language by adapting the Al-Khalil analyzer to the TD language. Thanks to the enrich-
ment of the transformation rules, the adapted analyzer achieves a score of 81.17% and
96.64% in terms of recall and accuracy for verbs correctly analyzed.
5.2.4 Tunisian Dialect Dictionary
The TD dictionary [Ayed 2013, Boujelbane 2013] were constructed using lexical units
in the Arabic Tree bank corpus and their parts of speech, to convert words from the MSA
to TD language. The obtained results consist on an XML lexical database composed
of nine dictionaries (Conjunctions, Pronouns, Number words, Interjections, Particles,
Adjectives, Adverbs, Nouns, Verbs).
5.3 Tunisian Dialect Annotation Tool
This section is dedicated to present our TD annotation Tool. Indeed, the rst part
will clarify the usefulness of our system and its functionality. The second part is divided
to clarify details, characteristics, and the development environment.](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-61-2048.jpg)
















![Appendix A
TD Enriched Orthographic
Transcription
We utilize and adapt transcription conventions [Bertrand 2008] which are made by LPL
laboratory. These conventions are developed for the transcription of conversational French
corpus. We add some precisions and we modify certain rules for transcription of Tunisian
dialect.
A.1 Inter-pausal units segmentation
Before any kind of transcription (and annotation), the one-hour long speech signal
should be segmented in inter-pausal units (henceforth IPU). An IPU is a speech sequence
between silent pauses which have a minimal duration of 200ms.
A.2 Conventions
The transcription is principally an orthographic transcription. We use punctuation
marks for delimiting phrase boundaries in the transcription. We added precisions about
particular pronunciations, and some other details. If needed, phonetic transcription is
coded with Buckwalter transliteration [Habash 2007]. The most usual cases are com-
mented here:
A.2.1 Typographic rules
a- Abbreviations
Our transcription doesn't note any abbreviation.
Example:
t
%
…
,ú
¯ ð
©
€ ÖÏ d
©
’
©
tÖÏ d € ñ
t»ˆ](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-80-2048.jpg)
![66 Appendix A. TD Enriched Orthographic Transcription
b- Numbers
Numbers have to be written in letters.
Examples:
‰g d
ð
èå
„«
©
¬ f
d
c- Titles
Movies, books, newspaper titles are written between quotation marks.
Examples:
sk
F
©
®
u
ú
Î
« l
F
×
e
©
uu
F
ø
‰
©
t« e
Ó
‡
©
u(ð)È ½Ë
d- Acronyms, patronyms, toponyms
We use a t
%
…
-½Ó-©
ƒ code:
• t
%
…
for toponym,
• ½Ó for patronym,
• and ©
ƒ (from sigle) for acronym.
The form is:t
%
…
-½Ó-©
ƒ, Ortho. Ortho is the orthographic transcription. Specic
care must be put to acronyms whose pronunciation has the same form as spelled letters.
(see spelled letters).
Examples:
½Ó,
¯ e
©
®“
t
%
…
, ú
Ϋ ‰Òm
×
e- Spelled letters
Spelled words are transcribed as particular pronunciation (between square brackets: let-
ters, comma, and suggested pronunciation).
Example:
[e
u e
u
F
©
Ë
d,
su
F
d]](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-81-2048.jpg)
![A.2. Conventions 67
f- Onomatopoeia
We used a standard lexical list of onomatopoeia; if the onomatopeia does not exist, it is
transcribed as a non-standard realization. (This list will be ameliorate later).
..,%
è d ,%
Ð d
,% è e
u
F
,% è è ,% è d
ñu
d
g- Other-languages words
In that case, we use this form for annotating other languages word: [lan: language or-
thography, pronunciation]. We put in square brackets, and separated by comma, the
language, the standard transcription in the foreign language, and the speaker's pronun-
ciation (in SAMPA alphabet1).
Examples:
[lan:Fr, deux, d2]
[lan:En, network, ne?w3:k]
[lan:ASM,
s
F
»
€]
h- Undeterminable morphologic variants
Graphic variants are noted between braces, separated by commas.
Example:
{ils ont tué, il l'a tué}
{ñÊ
t
¯,d
ñÊ
t
¯}
A.2.2 Pronunciation notation
a- Elisions
The characters related to the omitted phonemes are written between parentheses.
Example:
Ð(ð)
€ pronounced /mÅ¡/ is noted
€ñÓ.
r
F
(d)
€ pronounced /bÅ¡/ is noted
€ e
u
F
.
b- Atypical accords
We choose the standard orthographic transcription of the words as they have been said.
Example:
é« g
©
m
Ì
9d ù
ë e
u
F
(instead of
é« g
©
m
Ì
9d
ét
ë e
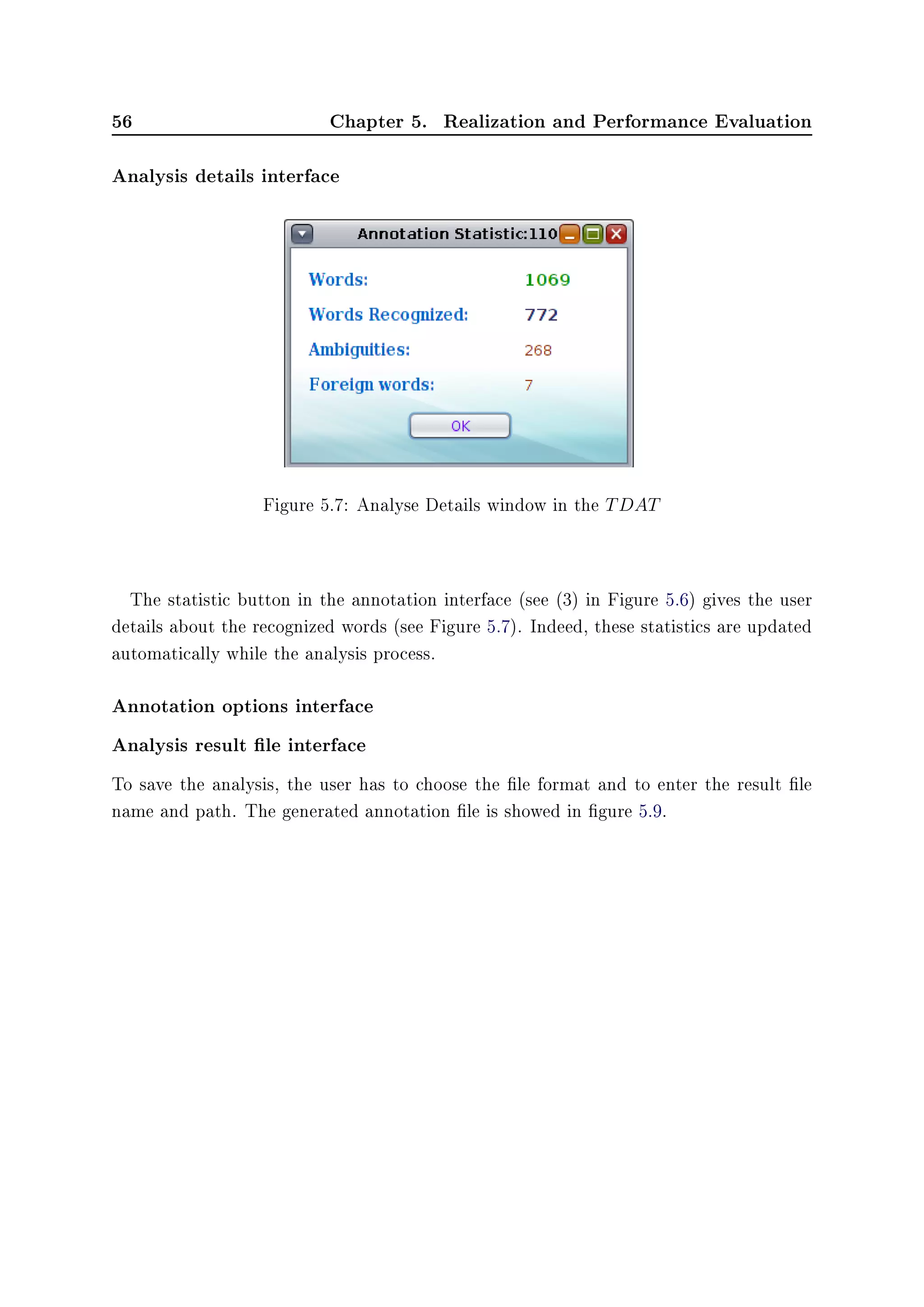
u
F
)](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-82-2048.jpg)





![Bibliography
[Al-Onaizan 1999] Y. Al-Onaizan, J. Curin, M. Jahr, K. Knight, J. Laerty, I. D.
Melamed, F. J. Och, D. Purdy, N. A. Smith and D. Yarowsky. Statistical machine
translation: Final report. Summer workshop on language engineering, center for
language and speech processing, baltimore, md, Johns Hopkins University, 1999.
(Cited on page 8.)
[Al-Sabbagh 2012] R. Al-Sabbagh and R. Girju. A Supervised POS Tagger for Written
Arabic Social Networking Corpora. In In J. Jancsary, editeur, Proceedings of
KONVENS 2012, numéro 3952. OGAI, September 2012. (Cited on pages 17
and 18.)
[Al-Shamsi 2006] F. Al-Shamsi and A. Guessoum. A Hidden Markov Model-Based POS
Tagger for Arabic. In 8es Journées internationales d`Analyse statistique des Don-
nées Textuelles (JADT), 2006. (Cited on pages 1 and 13.)
[Al-Sulaiti 2004] L. Al-Sulaiti. Designing and Developing a Corpus of Contemporary
Arabic. PhD thesis, The University of Leeds School of Computing, March 2004.
(Cited on page 9.)
[Al-Taani 2009] A. Al-Taani and S. Abu Al-Rub. A Rule-Based Approach for Tagging
Non-Vocalized Arabic Words. In The International Arab Journal of Information
Technology, volume 6, Jordan, July 2009. Department of Computer Sciences,
Yarmouk University. (Cited on page 13.)
[Alghamdi 2008] M. Alghamdi, F. Alhargan, M. Alkanhal, A. Alkhairy, M. Eldesouki and
A. Alenazi. Saudi Accented Arabic Voice Bank. pages 4562, King Abdulaziz City
for Science and Technology (KACST), Riyadh, Saudi Arabia, 2008. Computer and
Electronic Research Institute. (Cited on page 7.)
[Alotaibi 2010] Y. Ajami Alotaibi and S. A. Selouani. Investigating the Adaptation of
Arabic Speech Recognition Systems to Foreign Accented Speakers. In The 10th In-
ternational Conference on Information Science, Signal Processing and their Appli-
cations (ISSPA'10), pages 646649, Kuala Lumpur, May 2010. (Cited on page 11.)
[Altabba 2010] M. Altabba, A. Al-Zaraee and M. A. Shukairy. An arabic morphological
analyzer and part- of-speech tagger. Master's thesis, Arab International Univer-
sity, Damascus, Syria, 2010. (Cited on page 45.)](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-88-2048.jpg)
![74 Bibliography
[Amouri 2013] M. Amouri, M. Ellouze Khemakhem and Ines Zribi. Morphological ana-
lyzer for the tunisian dialect: verbs case. Master's thesis, FSEGS, 2013. (Cited
on page 46.)
[André 2008] V. André, C. Benzitoun, E. Canut, J. M. Debaisieux, B. Gaie and
E. Jacquey. Conventions de transcription en vue d`un alignement texte-son avec
Transcriber. Traitement de corpus oraux en français, Nancy Université - ATILF
UMR 7118, 2008. (Cited on pages 10 and 12.)
[Ayed 2013] S. Ben Ayed, M. Ellouze Khemakhem and R. Boujelbane. Rules of linguistic
transformation of the standard arabic to colloquial arabic for automatic speech
recognition. Master's thesis, FSEGS, 2013. (Cited on page 46.)
[Barkat-Defradas 2003] M. Barkat-Defradas, L. Vasilescu and F. Pellegrino. Stratégies
perceptuelles et identication automatique des langues. Laboratoire Dynamique
du Langage (UMR CNRS 5596) Institut des Sciences de l'Homme, 2003. (Cited
on page 8.)
[Barras 2000] C. Barras, E. Georois, Z. Wu and M. Liberman. Transcriber: development
and use of a tool for assisting speech corpora production. vol. 28, 2000. (Cited on
pages 9, 25 and 27.)
[Belgacem 2010] M. Belgacem, G. Antoniadis and L. Besacier. Automatic Identication
of Arabic Dialects. In Nicoletta Calzolari (Conference Chair), Khalid Choukri,
Bente Maegaard, Joseph Mariani, Jan Odijk, Stelios Piperidis, Mike Rosner and
Daniel Tapias, editeurs, Proceedings of the Seventh International Conference on
Language Resources and Evaluation (LREC'10). Université de Grenoble, France
Laboratoire LIDILEM LIG : GETALP, European Language Resources Associ-
ation (ELRA), May 2010. (Cited on page 21.)
[Bertrand 2008] R. Bertrand, P. Blache, R. Espesser, G. Ferré, C. Meunier, B. Priego-
Valverde and S. Rauzy. Annotation et Exploitation Multimodale de Parole Con-
versationnelle. In Corpus of Interactional Data, editeur, Traitement automatique
des langues (TAL), volume 49, pages 105134, 2008. (Cited on page 65.)
[Bigi 2012] B. Bigi, P. Péri and R. Bertrand. Orthographic Transcription: which En-
richment is required for phonetization? In Language Resources and Evaluation
Conference, Istanbul (Turkey), May 2012. Laboratoire Parole et Langage CNRS.
(Cited on page 26.)](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-89-2048.jpg)
![Bibliography 75
[Bischo 2009] K. Bischo, C. S. Firan, R. Paiu, W. Nejdl, C. Laurier and M. Sordo.
Music Mood and Theme Classication - a Hybrid Approach. The International
Society for Music Information Retrieval, pages 657662, 2009. (Cited on page 22.)
[Bosch 2005] A. Van Den Bosch, E. Marsi and A. Soudi. Memory-based morphological
analysis and part-of-speech tagging of Arabic M. Ann Arbor. In Proceedongs of
the ACL Workshop on Computational Approaches to Semitic Languages, pages
18. Association for Computational Linguistics, M. Ann Arbor, June 2005. (Cited
on pages 13, 14 and 15.)
[Boujelbane 2013] R. Boujelbane. Génération de corpus en dialecte tunisien pour
l'adaptation de modéles de langage. TALN-RÉCITAL, Les Sables d`Olonne, pages
1721, Juin 2013. (Cited on page 46.)
[Cam 2008] Campagne d`évaluation des Systémes de Transcription Enrichie d`Émissions
Radiophoniques. Transcription détaillée et enrichie, 0.1 édition, 01 2008. (Cited
on pages 10, 12 and 26.)
[Chiang 2006] D. Chiang, M. T. Diab, N. Habash, O. Rambow and S. Shareef. Parsing
Arabic Dialects. In Diana McCarthy and Shuly Wintner, editeurs, EACL. The
Association for Computer Linguistics, 2006. (Cited on page 17.)
[Cole 2005] J. Cole, M. Hasegawa-Johnson, C. Shih, H. Kim, E. Lee, H. Lu, Y. Mo and
T. Yoon. Prosodic parallelism as a cue to repetition disuency. In Proceedings
of Disuency in Spontaneous Speech (DISS) Workshop, USA, September 2005.
University of Illinois at Urbana-Champaign. (Cited on page 11.)
[Diab 2010] M. Diab, N. Habash, O. Rambow, M. Altantawy and Y. Benajiba. CO-
LABA: Arabic Dialect Annotation and Processing. In Workshop on Semitic Lan-
guages, editeur, Proceedings of the Language Resources and Evaluation Confer-
ence (LREC), Malta, 2010. (Cited on page 5.)
[Dipper 2009] S. Dipper and M. Schnurrenberger. OTTO: A Tool for Diplomatic Tran-
scription of Historical Texts. In Zygmunt Vetulani, editeur, LTC, volume 6562 of
Lecture Notes in Computer Science, pages 456467, Germany, 2009. Linguistics
Department Ruhr University Bochum, Springer. (Cited on page 12.)
[Dreuw 2008] P. Dreuw and H. Ney. Towards Automatic Sign Language Annotation for
the ELAN Tool. In LREC Workshop on the Representation and Processing of
Sign Languages: Construction and Exploitation of Sign Language Corpora, June
2008. (Cited on page 9.)](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-90-2048.jpg)
![76 Bibliography
[Duh 2005] K. Duh and K. Kirchho. POS Tagging of Dialectal Arabic: A Minimally
Supervised Approach. Proceeding Semitic '05 Proceedings of the ACL Workshop
on Computational Approaches to Semitic Languages, pages 5562, 2005. (Cited
on pages 7 and 16.)
[D.Weenink 2013] D.Weenink. Speech signal processing with praat. April 2013. (Cited
on pages 9 and 25.)
[Ferguson 1959] C. A. Ferguson. Diglossia: In Language in Culture and Society. New
York: Harper and Row, vol. 439, 1959. (Cited on page 1.)
[Fromont 2012] R. Fromont and J. Hay. LaBB-CAT: an Annotation Store. In In
Proceedings of Australasian Language Technology Association Workshop, page
113−117, Dunedin, New Zealand, December 2012. (Cited on page 9.)
[Gauvain 2000] J. L. Gauvain and L. Lamel. Fast decoding for indexation of broadcast
data. In INTERSPEECH, pages 794797, 2000. (Cited on page 5.)
[Ghazali 2002] S. Ghazali, R. Hamdi and M. Barkat. Speech Rhythm Variation in Ara-
bic Dialects. In Proceedings of Prosody 2002, pages 331334, Aix-en-Provence,
2002. Institut Supérieur des langues, Université 7 Novembre à Carthage, Tunisia
,Laboratoire Dynamique du Langage. (Cited on page 8.)
[Gibbon 1983] D. Gibbon, R. Moore and R. Winski, editeurs. An arabist's guide to
egyptian colloquial. 1983. (Cited on page 7.)
[Gibbon 1997] D. Gibbon, R. Moore and R. Winski, editeurs. Handbook of standards
and resources for spoken language systems, volume 886. Berlin, Germany: Walter
de Gruyter, University of Bielefeld, DRA Speech Research Unit, and Vocalis, 1997.
(Cited on page 5.)
[Gro 2007] Groupe ICOR, UMR 5191 ICAR (CNRS - Lyon 2). Convention ICOR, 11
2007. (Cited on pages 10 and 11.)
[Habash 2007] N. Habash, A. Soudi and T. Buckwalter. In arabic computational mor-
phology: Knowledge-basedand empirical methods. 978-1-4020-6045-8. On Arabic
Transliteration, 2007. (Cited on page 65.)
[Habash 2009] N. Habash, O. Rambow and R. Roth. MADA+TOKAN: A Toolkit for
Arabic Tokenization, Diacritization, Morphological Disambiguation, POS Tag-
ging, Stemming and Lemmatization. Proceedings of the 2nd International Con-](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-91-2048.jpg)
![Bibliography 77
ference on Arabic Language Resources and Tools (MEDAR), April 2009. Cairo,
Egypt. (Cited on page 46.)
[Hadj 2009] Y. Ould Mohamed El Hadj, I. A. Al-Sughayeir and A. M. Al-Ansari. Arabic
Part-Of-Speech Tagging using the Sentence Structure. In Khalid Choukri and
Bente Maegaard, editeurs, Proceedings of the Second International Conference on
Arabic Language Resources and Tools, Cairo, Egypt, April 2009. The MEDAR
Consortium. (Cited on page 14.)
[Haldar 2011] R. Haldar and D. Mukhopadhyay. Levenshtein Distance Technique in
Dictionary Lookup Methods: An Improved Approach. The Computing Research
Repository, page 1101.1232, January 2011. (Cited on page 41.)
[Hymes 1973] D. Hymes. Speech and Language: On the Origins and Foundations of
Inequality among Speakers. Deadalus, pages 5986, 1973. (Cited on page 1.)
[Jelinek 1976] F. Jelinek. Continuous Speech Recognition by Statistical Methods. Pro-
ceedings of the IEEEE, pages 532556, 1976. (Cited on page 15.)
[Jurafsky 2008] D. Jurafsky and J. H. Martin. Speech and language processing: An in-
troduction to natural language processing , computational linguistics, and speech
recognition. Numeéro 988 de ISBN-13: 978-0131873216. Prentice Hall, 2 édition,
May 2008. (Cited on page 13.)
[Khoja 2001] S. Khoja. APT: Arabic Part-of-speech Tagger. In In proceedings of the
student workshop at the second meeting of the north American chapter of the
association for computational linguistics (NAACL2001), Carnegie Mellon Univer-
sity, Pennsylvania, 2001. (Cited on pages 15 and 16.)
[Kipp 2011] M. Kipp, N. Tan and J. C. Martin. ANVIL: Annotation of Video and Lan-
guage Data 5.0. In Language Documentation Conservation, pages 8894. LIMSI-
CNRS, 2011. (Cited on pages 6, 9 and 21.)
[Kurdi 2003] M. Z. Kurdi. Contribution à l`analyse du langage oral spontané. PhD thesis,
Université de Grenoble I, 2003. (Cited on page 11.)
[Lamel 2007] L. Lamel, A. Messaoudi and J. L. Gauvain. Improved acoustic modeling for
transcribing Arabic broadcast data. In INTERSPEECH, pages 20772080, Spoken
Language Processing Group CNRS-LIMSI, BP 133 91403 Orsay cedex, France,
2007. ISCA. (Cited on page 21.)](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-92-2048.jpg)
![78 Bibliography
[Maamouri 2006a] M. Maamouri. Levantine Arabic QT Training Data Set 5. Linguistic
Data Consortium, 2006. (Cited on page 7.)
[Maamouri 2006b] M. Maamouri, A. Bies, T. Buckwalter, M. Diab, N. Habash, O. Ram-
bow and D. Tabessi. Developing and Using a Pilot Dialectal Arabic Treebank. In
Proceedings of the International Conference on Language Resources and Evalua-
tion (LREC), 2006. (Cited on page 16.)
[Messaoudi 2004] A. Messaoudi, L. Lamel and J. L. Gauvain. Transcription of Arabic
Broadcast News. In International Conference on Speech and Language Processing,
pages 521524, Jeju Island, october 2004. (Cited on page 5.)
[Messaoudi 2005] A. Messaoudi, L. Lamel and J. L. Gauvain. Modeling Vowels for Arabic
BN Transcription. INTERSPEECH, Sep 2005. (Cited on pages 6 and 9.)
[Meunier 2011] C. Meunier and R. Espesser. Is phoneme inventory a good predictor for
vocal tract use in casual speech? In Proceedings of the 17th International Congress
of Phonetic Sciences (ICPhS 2011), Hong-Kong, China, August 2011. Laboratoire
Parole et Langage, Université de Provence. (Cited on page 11.)
[Pallaud 2002] B. Pallaud. Les amorces de mots comme faits autonymiques en langage
oral. Recherches sur le Français parlé, 2002. (Cited on page 11.)
[Piu 2007] M. Piu and R. Bove. Annotation des disuences dans les corpus oraux. In
RÉCITAL 2007 Toulouse. Équipe DELIC Université de Provence, 2007. (Cited
on pages 9 and 11.)
[Precoda 2007] K. Precoda, J. Zheng, D. Vergyri, H. Franco, C. Richey, K. Colleen,
A. Kathol and S. S. Kajarekar. Iraqcomm: a next generation translation system.
In INTERSPEECH, pages 28412844. ISCA, 2007. (Cited on page 8.)
[Saad 2010] M. K. Saad and W. Ashour. OSAC: Open Source Arabic Corpora Cyprus.
6th ArchEng International Symposiums, no. EEECS`10 the 6th International Sym-
posium on Electrical and Electronics Engineering and Computer Science, pages
118123, 2010. European University of Lefke. (Cited on page 6.)
[Sawaf 2010] H. Sawaf. Arabic Dialect Handling in Hybrid Machine Translation. pages
4952, 2010. (Cited on page 13.)
[Shriberg 1994] E. E. Shriberg. Preliminaries to a Theory of Speech Disuencies. PhD
thesis, UNIVERSITY OF CALIFORNIA, BERKELEY, 1994. (Cited on page 11.)](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-93-2048.jpg)
![Bibliography 79
[Vergyri 2004] D. Vergyri and K. Kirchho. Automatic diacritization of Arabic for Acous-
tic Modeling in Speech Recognition. In Computational Approaches to Arabic
Script-based Languages, 2004. (Cited on page 6.)
[Yang 2007] M. Yang, J. Zheng and A. Kathol. A Semi-Supervised Learning Approach
for Morpheme Segmentation for An Arabic Dialect. INTERSPEECH ISCA, pages
15011504, 2007. (Cited on page 39.)
[Zaidan 2011] O. F. Zaidan and C. Callison Burch. The Arabic Online Commentary
Dataset: an Annotated Dataset of Informal Arabic with High Dialectal Content.
Baltimore, MD 21218, USA, 2011. Dept. of Computer Science, Johns Hopkins
University. (Cited on page 8.)
[Zribi 2013] I. Zribi, M. Graja, M. Ellouze Khmekhem, M. Jaoua and L. Hadrich Bel-
guith. Orthographic Transcription for Spoken Tunisian Arabic. Computational
Linguistics and Intelligent Text Processing Lecture Notes in Computer Science,
vol. 7816, pages 153163, 2013. (Cited on pages 24 and 26.)](https://image.slidesharecdn.com/97f6d458-6fbf-422a-9161-4f997594aa3c-151212131635/75/Master-Thesis-94-2048.jpg)





































































