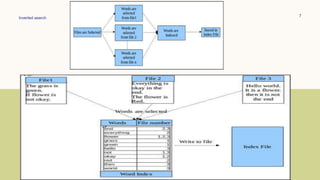
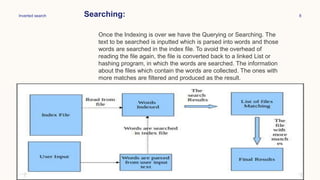
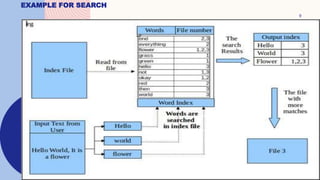
This document discusses the design and implementation of an inverted index search program. It begins with an introduction to inverted indexes, describing them as data structures that map content like words to their locations in documents, allowing for fast full-text searches. It then outlines the important tasks of indexing and querying - indexing involves creating a database of words from input files, while querying searches the index database for input search terms. The design section provides more details on how indexing and querying would work, such as hashing words and storing them in a linked list with file references. Examples are also given of how the search program would call indexing to build the database, search it, and update it as needed.