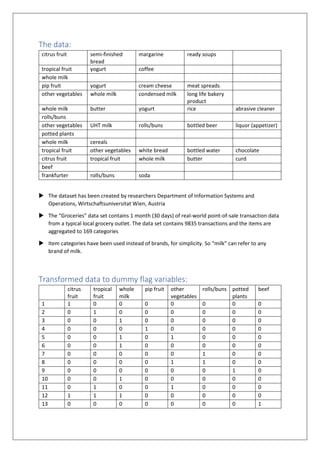
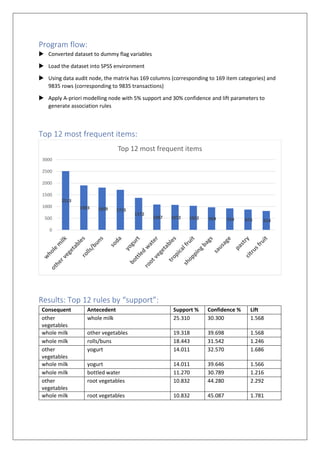
The document details a market basket analysis using the Apriori algorithm on a groceries dataset, implemented to identify frequently purchased items and generate association rules. The data contains 9835 transactions aggregating 169 item categories, analyzed to establish metrics for support, confidence, and lift among items bought together. Key findings include the dominance of 'whole milk' and 'other vegetables' in the top rules by support and confidence, with interesting insights from the rules sorted by lift that suggest less common item associations.