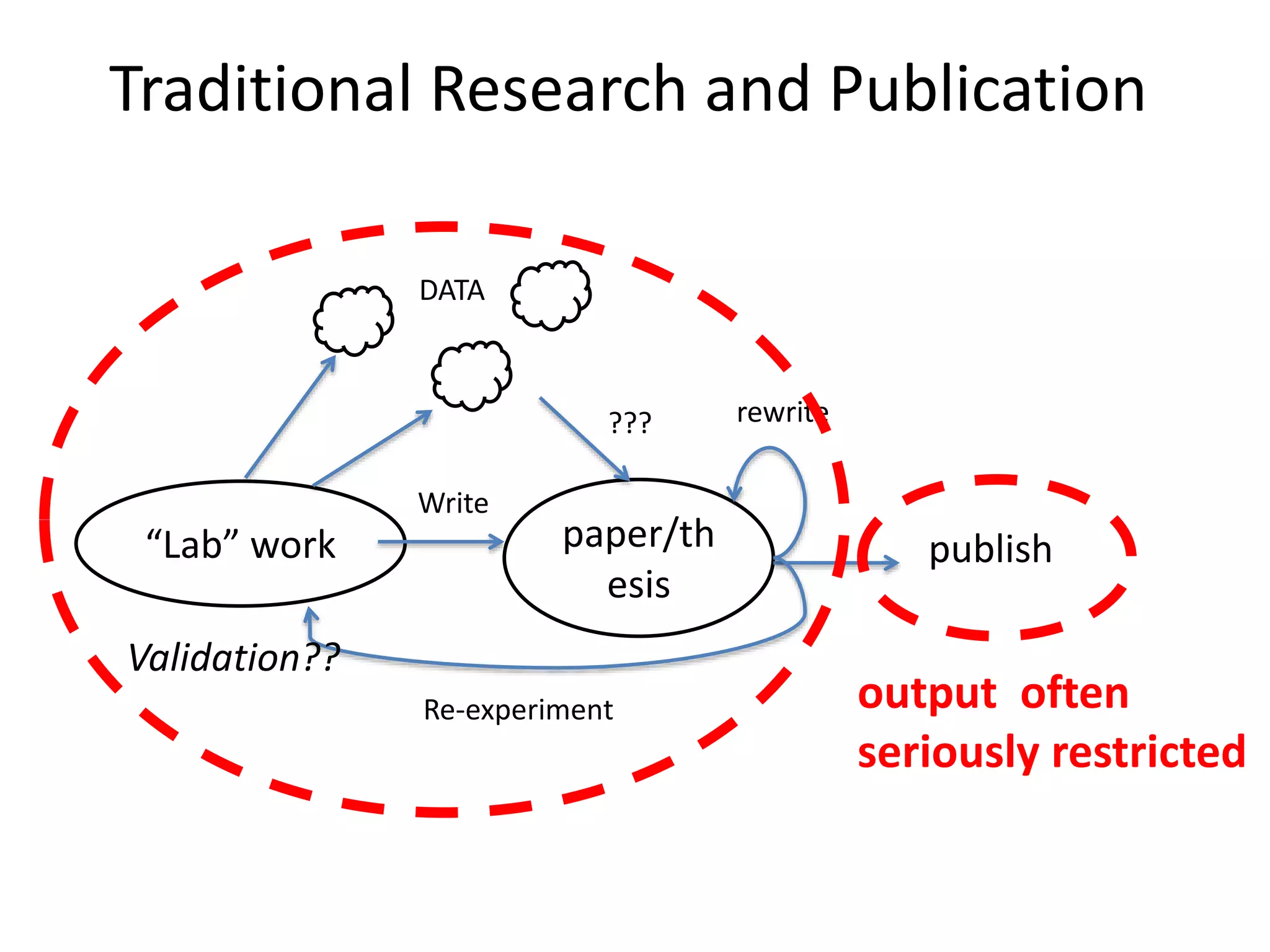
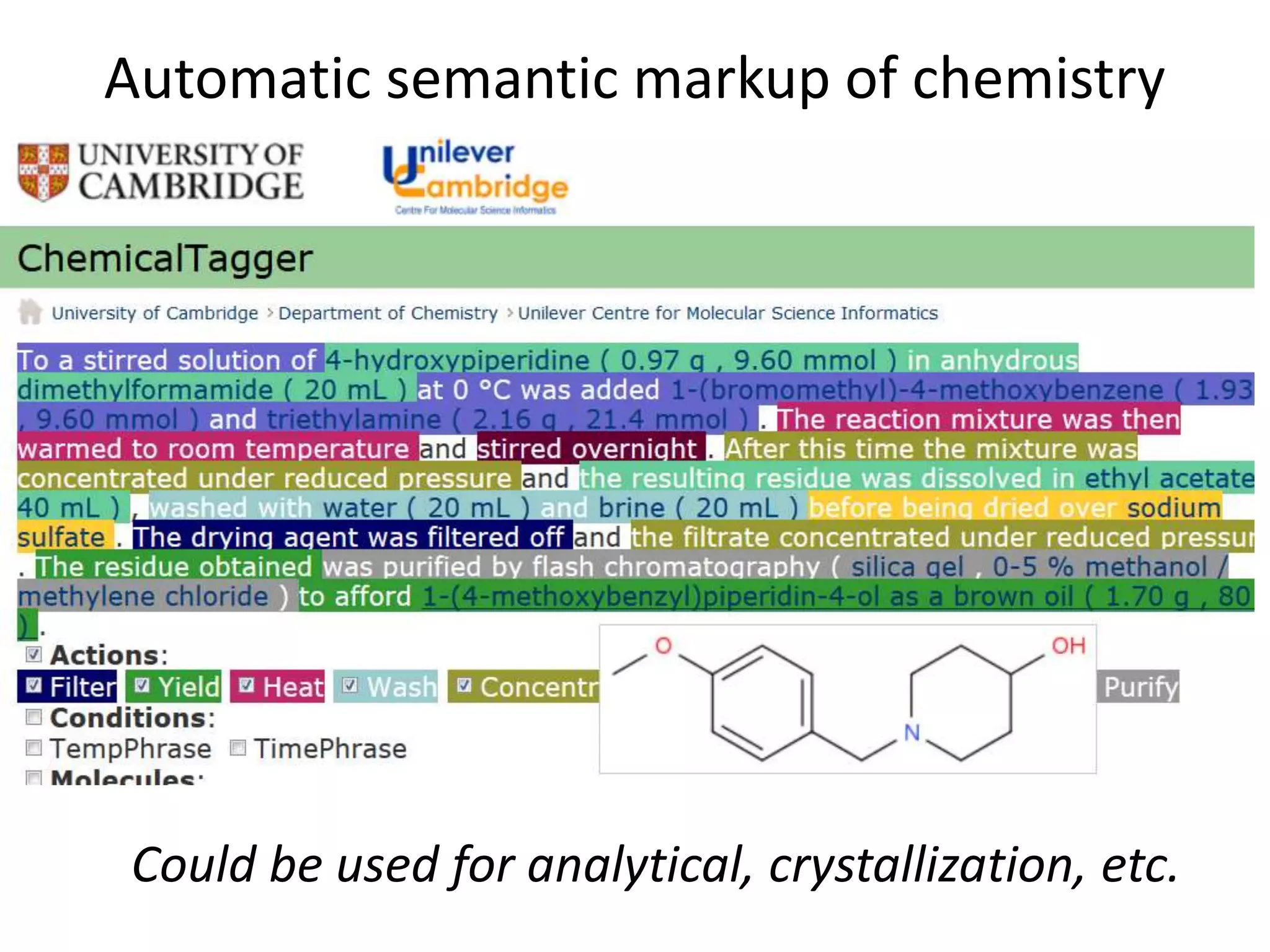
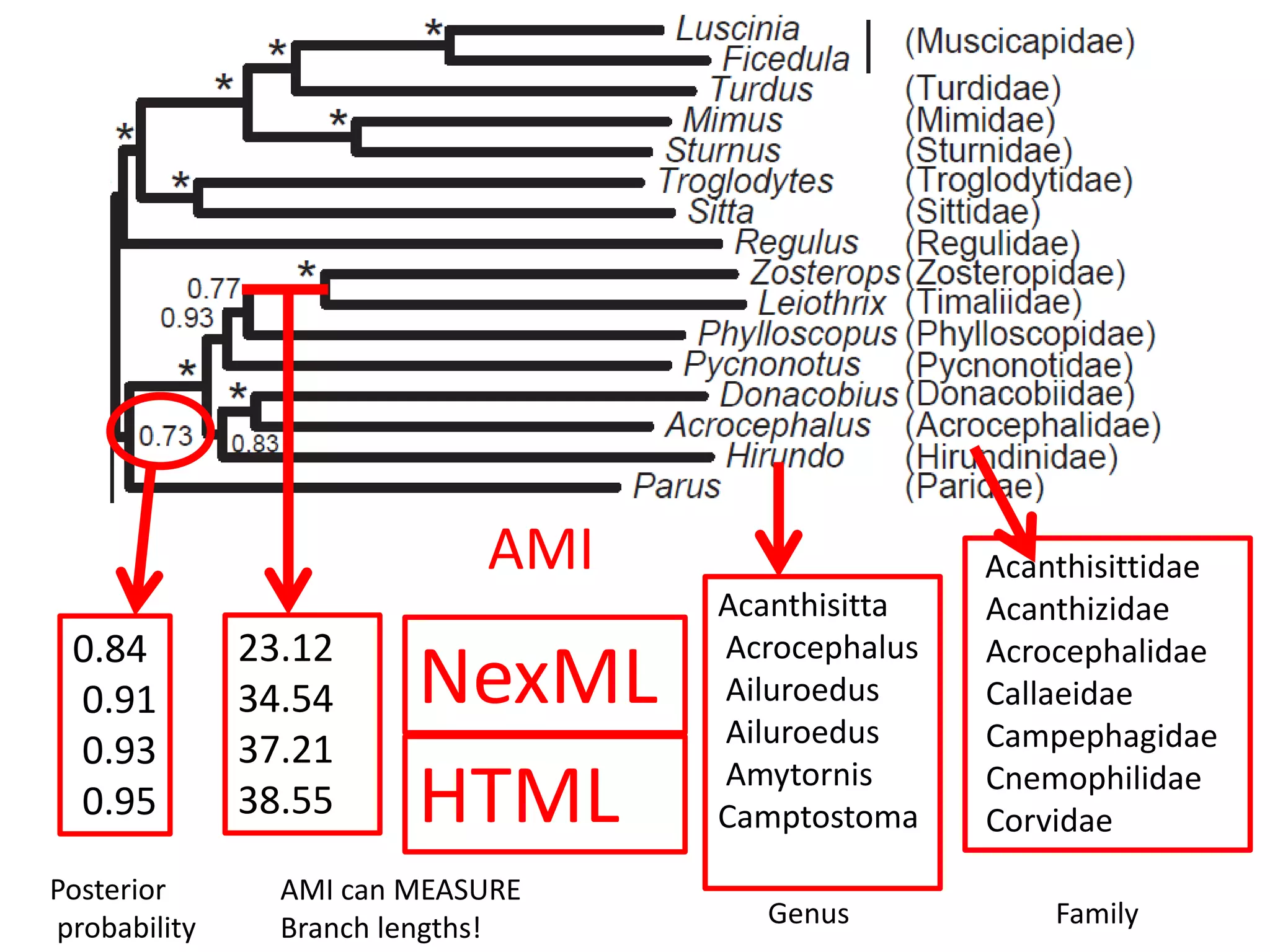
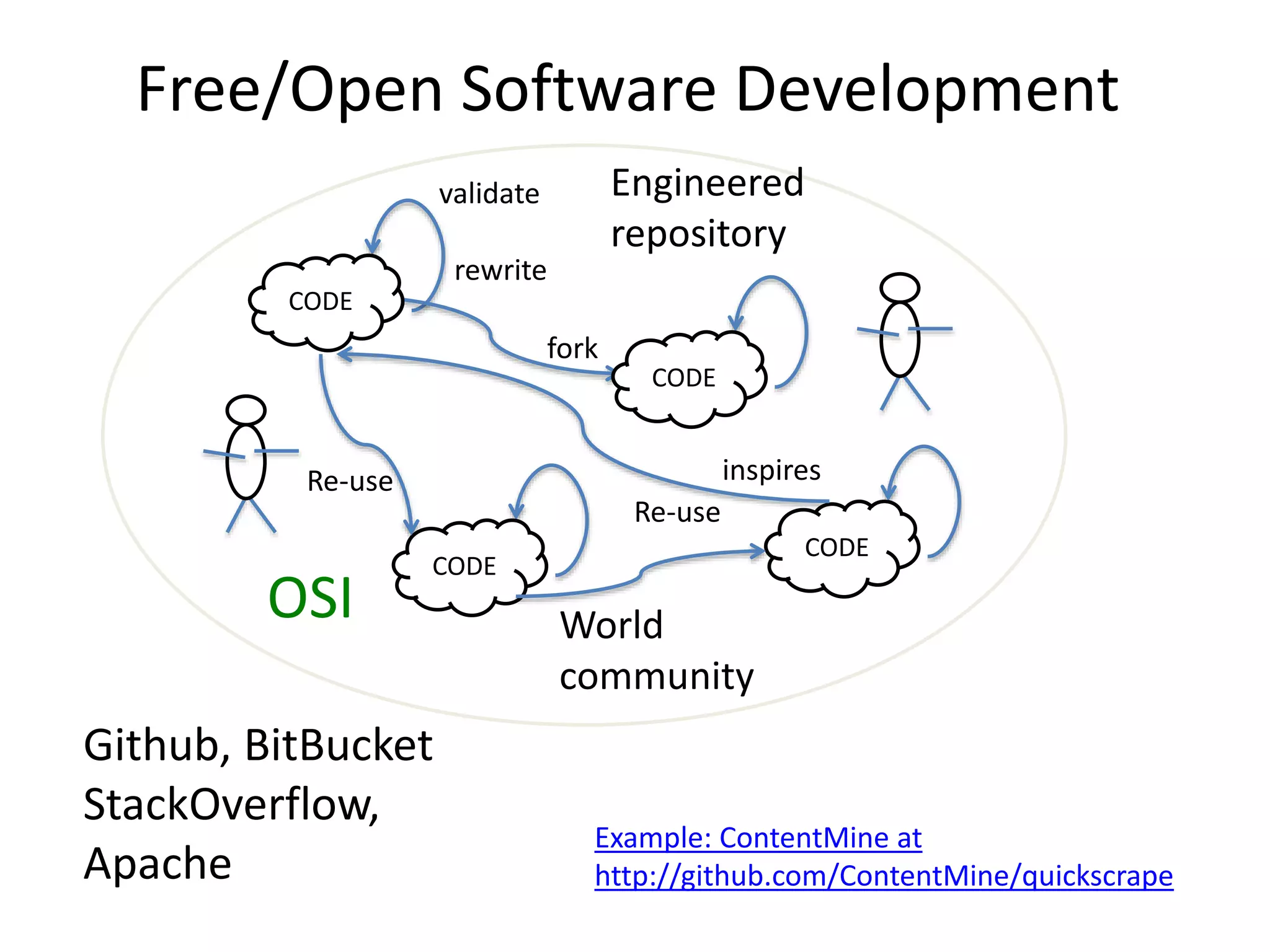
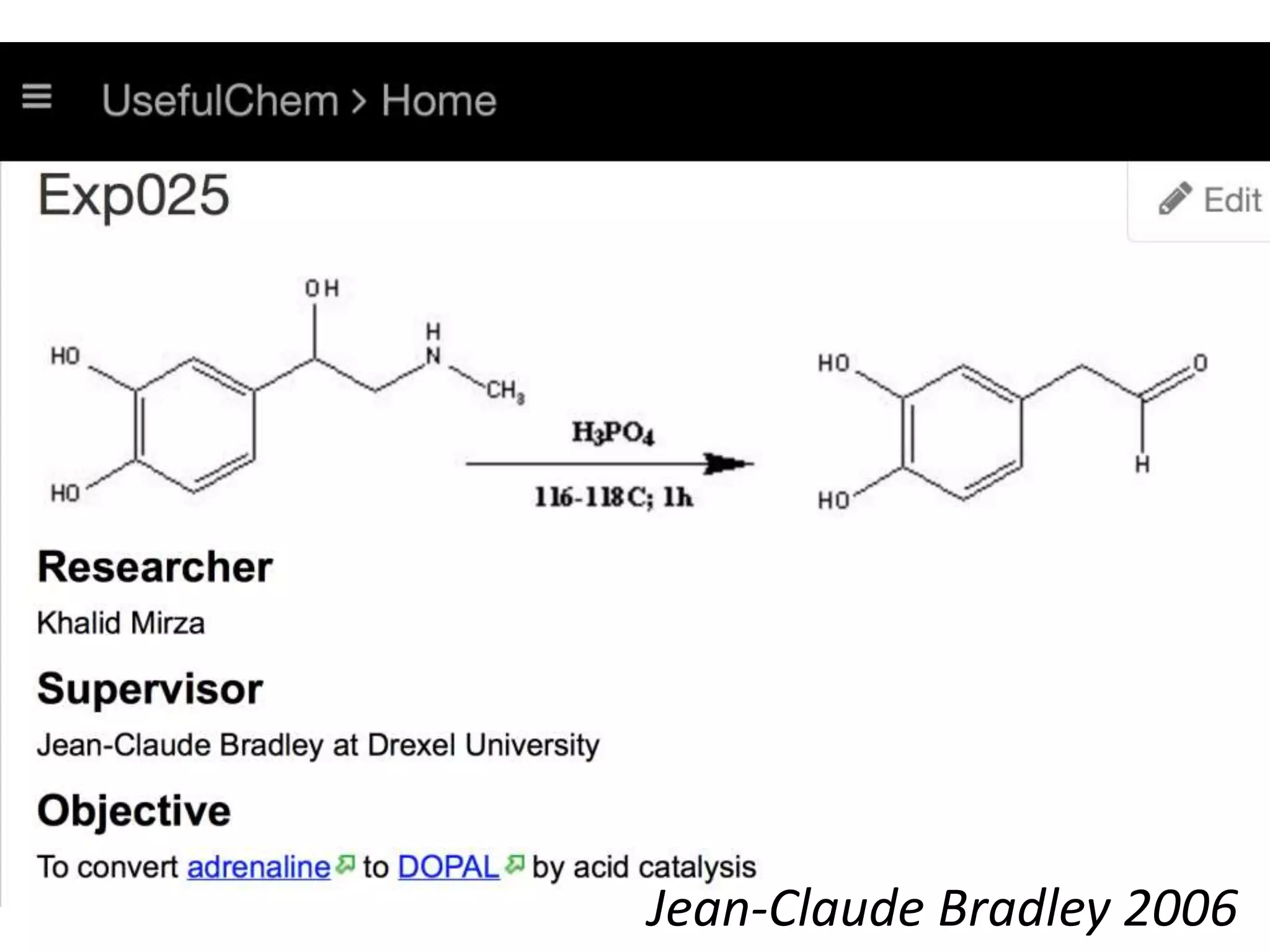
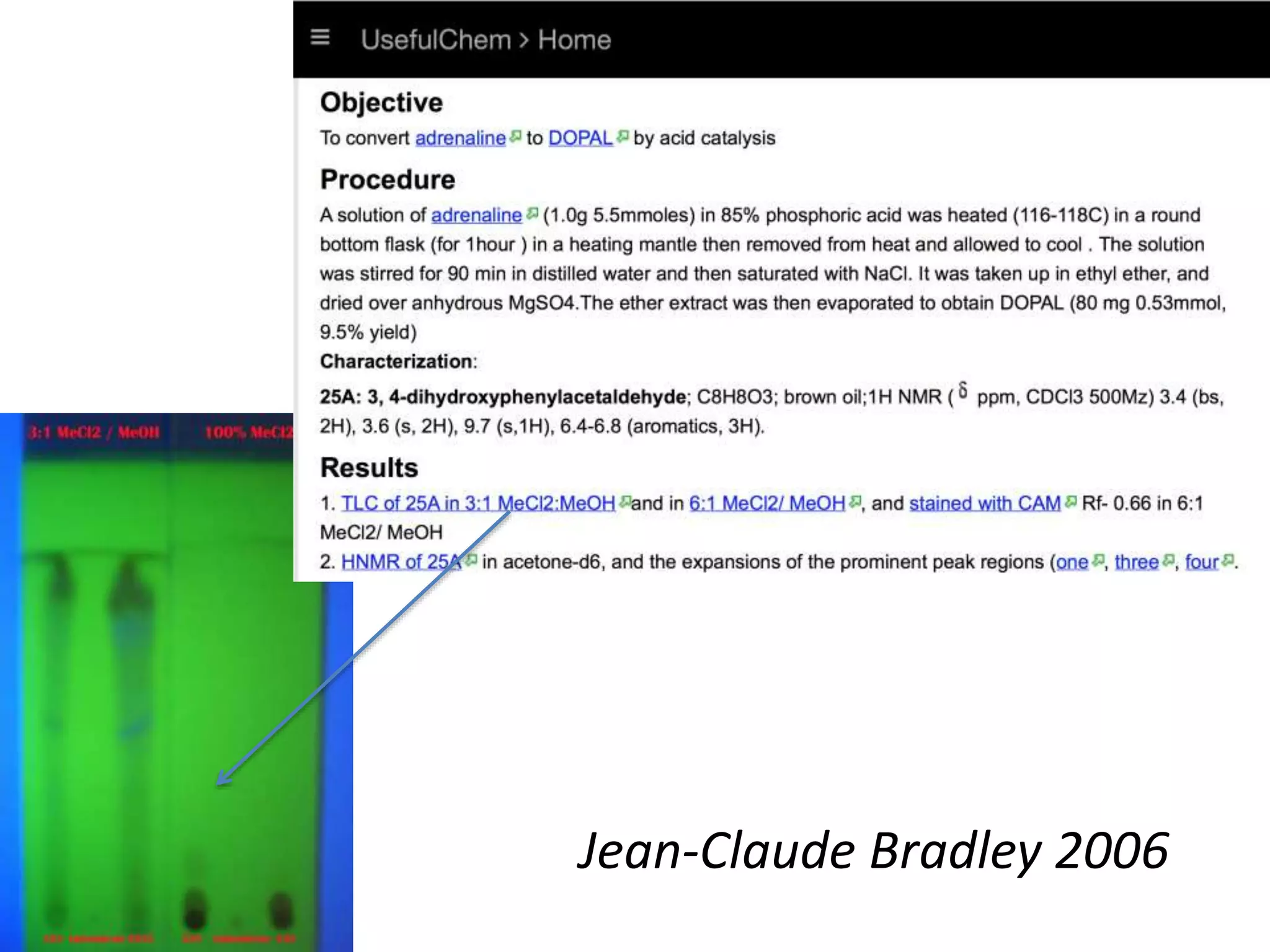
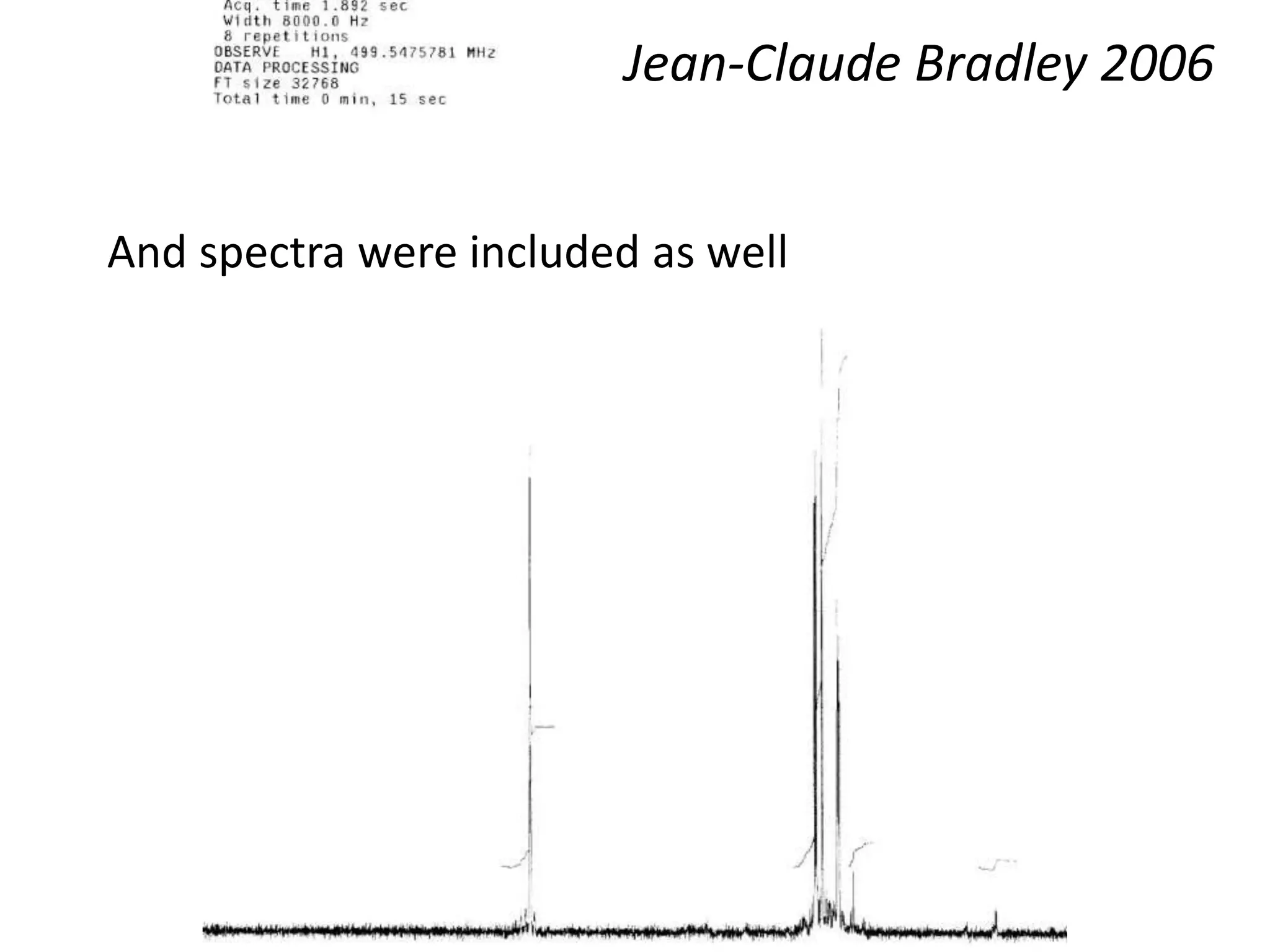
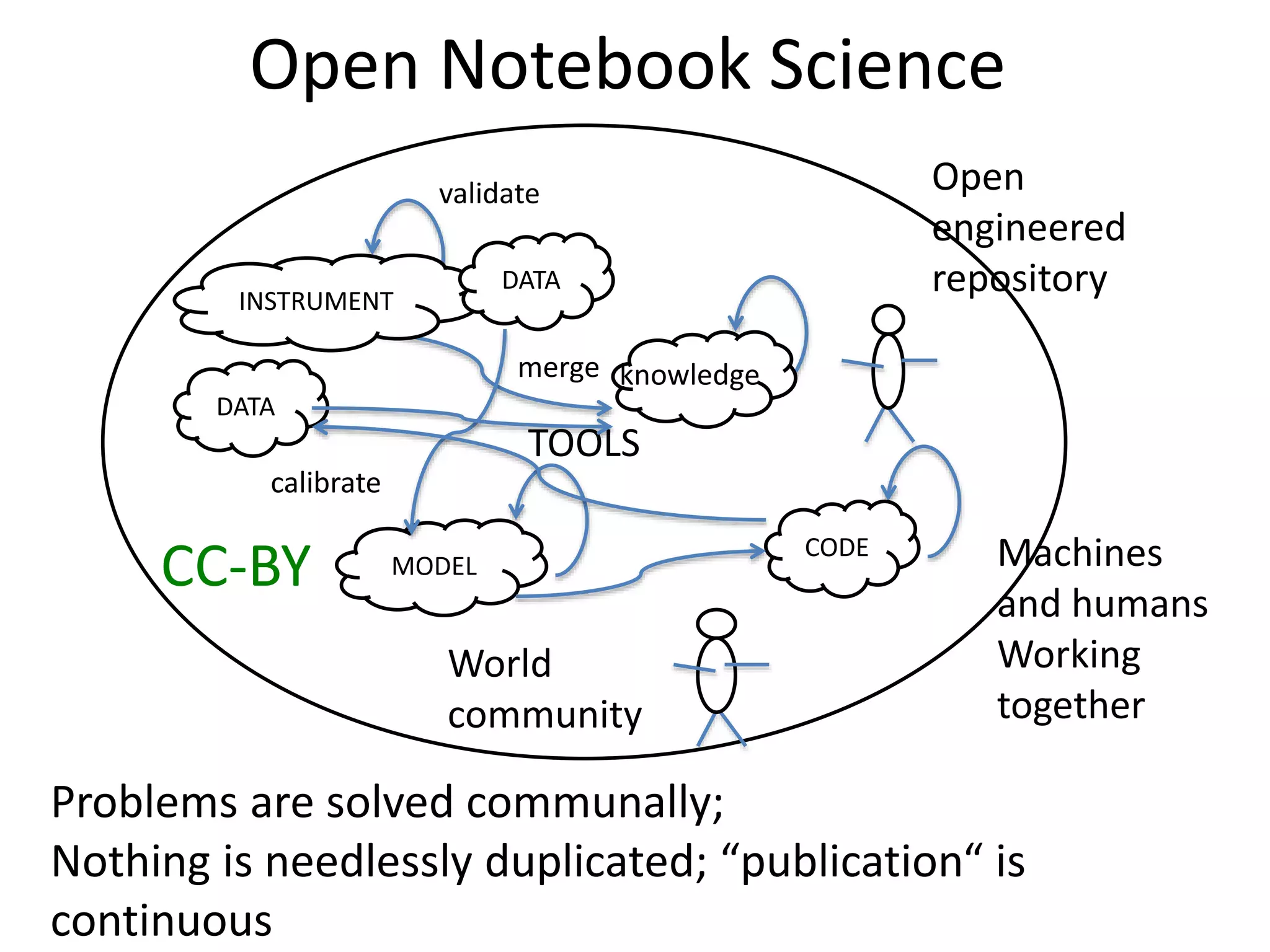
The document discusses the significant waste associated with traditional thesis management and publication, estimating a loss exceeding $10 billion annually. It advocates for open scientific practices, such as open notebook science and content mining, to enhance accessibility and the utility of research outputs. The author highlights the need for reform in how universities handle theses and proposes collaborative, open approaches to research and data sharing.







![…three problems—flawed design, non-
publication, and poor reporting—together
meant >85% of research funds were wasted, a
global total loss >100 billion USD per year.
[Lancet 2009]
[Even more] waste clearly occurs after
publication: from poor access, poor
dissemination, and poor uptake of the findings
of research. [PLOS Medicine 2014-05-27]
Bad publication wastes science](https://image.slidesharecdn.com/etd2014b-140724051249-phpapp02/75/Making-Theses-USEFUL-8-2048.jpg)






![http://www.budapestopenaccessinitiative.org/read
… an unprecedented public good. …
… completely free and unrestricted access to [peer-
reviewed literature] by all scientists, scholars, teachers,
students, and other curious minds. …
…Removing access barriers to this literature will
accelerate research, enrich education, share the
learning of the rich with the poor and the poor with
the rich, make this literature as useful as it can be, and
lay the foundation for uniting humanity in a common
intellectual conversation and quest for knowledge.
(Budapest Open Access Initiative, 2003)](https://image.slidesharecdn.com/etd2014b-140724051249-phpapp02/75/Making-Theses-USEFUL-16-2048.jpg)



![Elsevier wants to control Open Data
[asked by Michelle Brook]](https://image.slidesharecdn.com/etd2014b-140724051249-phpapp02/75/Making-Theses-USEFUL-20-2048.jpg)













































![Open scholarship [a FOSTER open science talk]](https://cdn.slidesharecdn.com/ss_thumbnails/openscholarshipfoster-140904081612-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























































