Downloaded 453 times


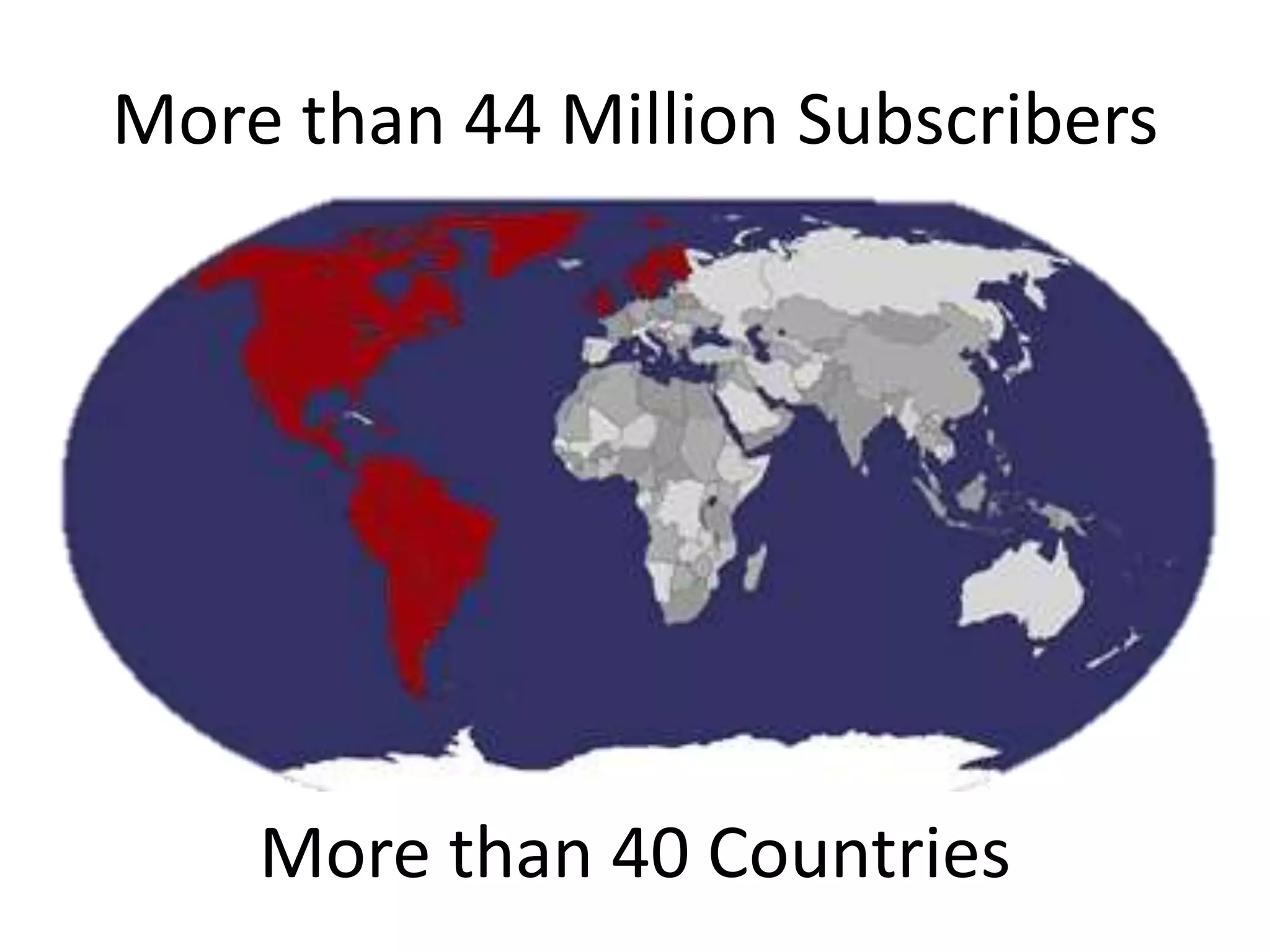










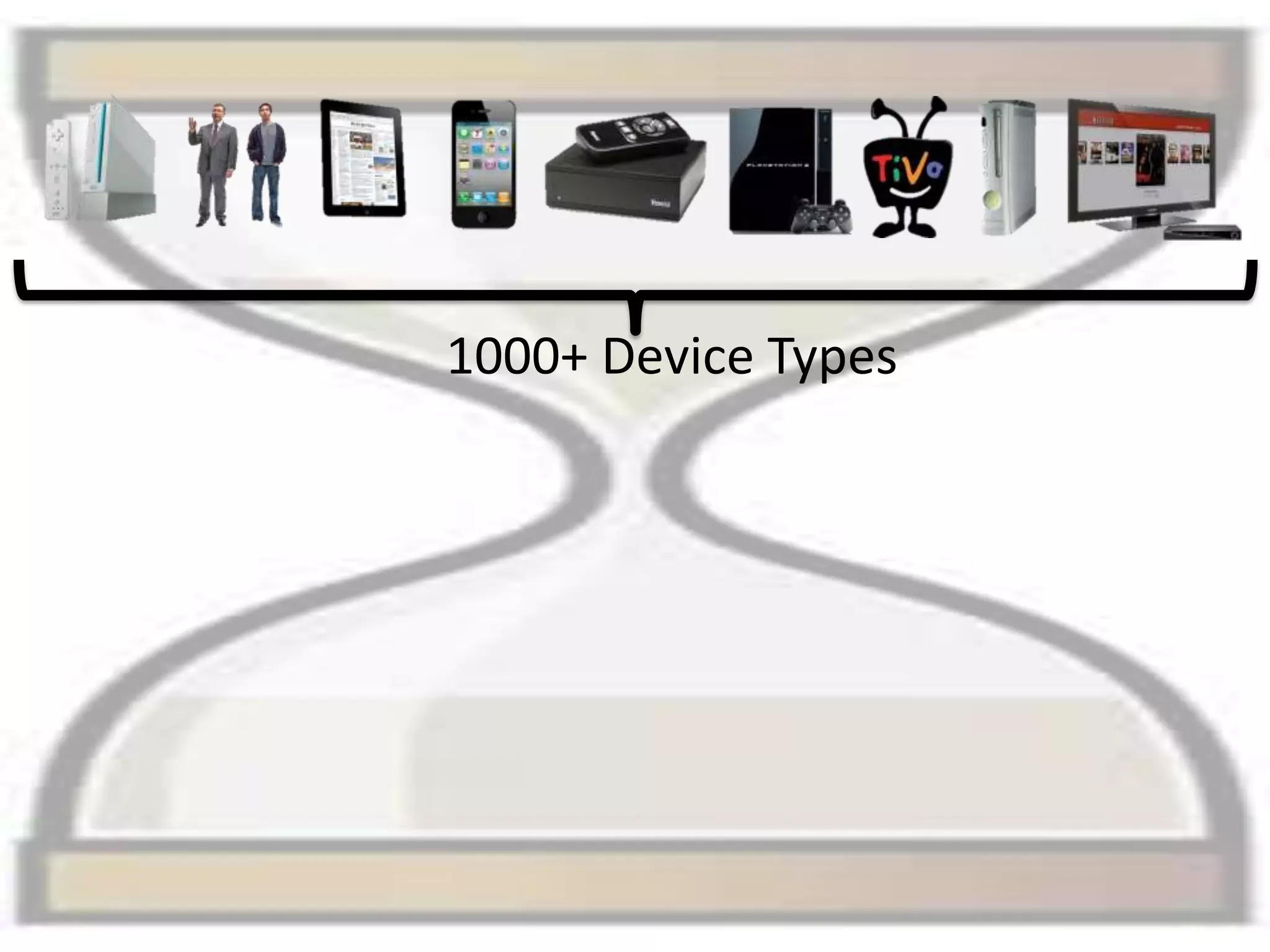
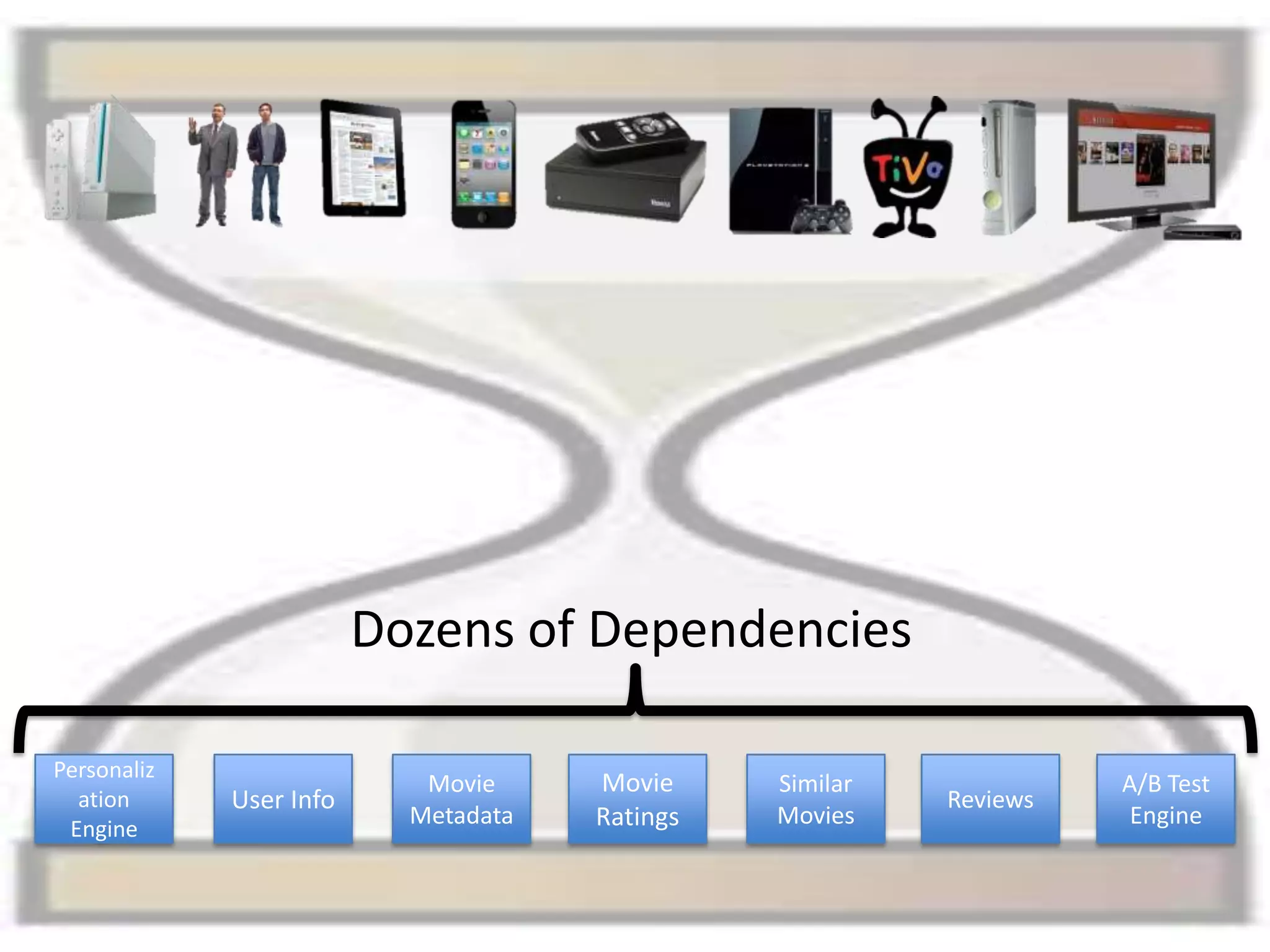
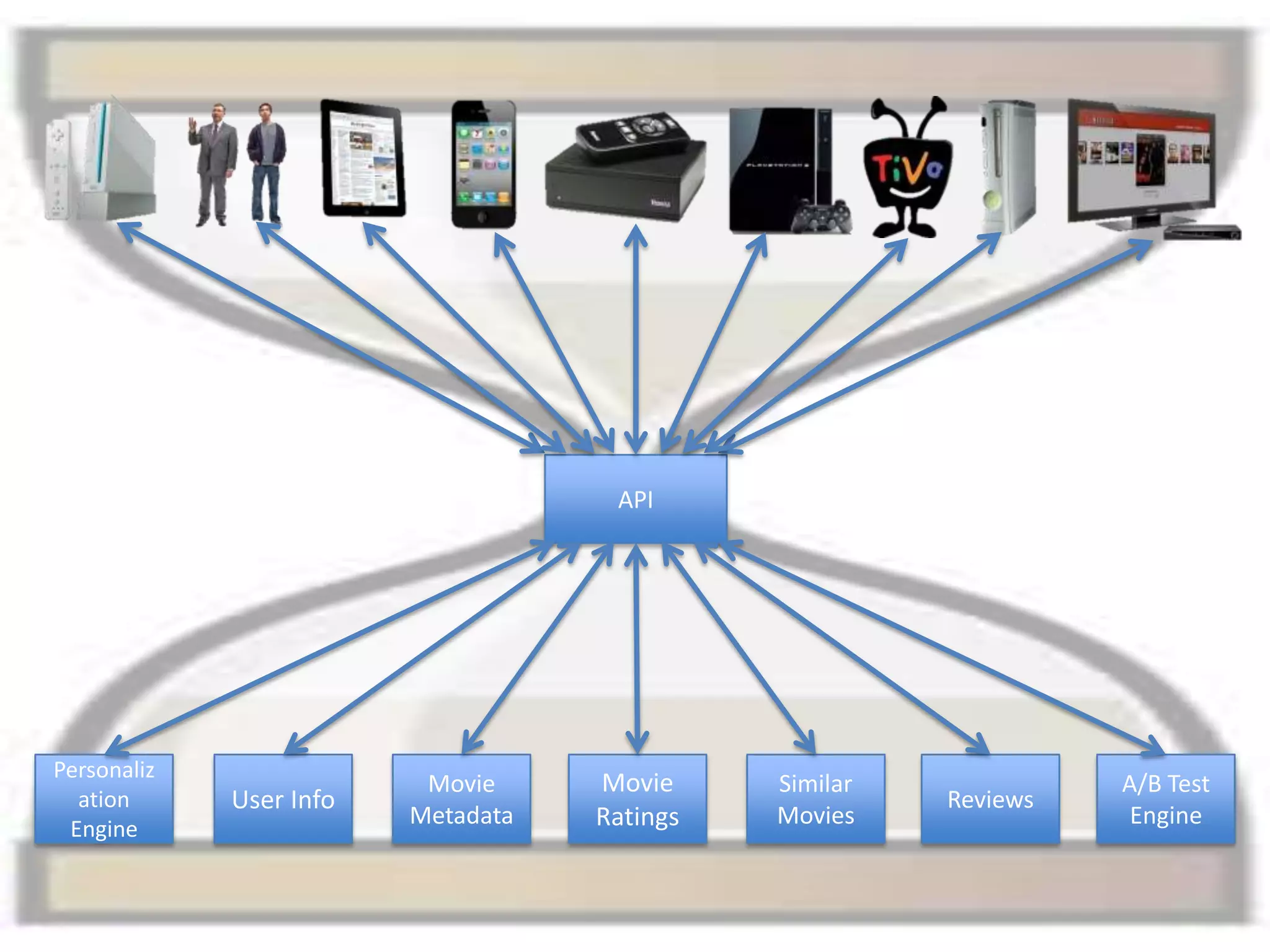
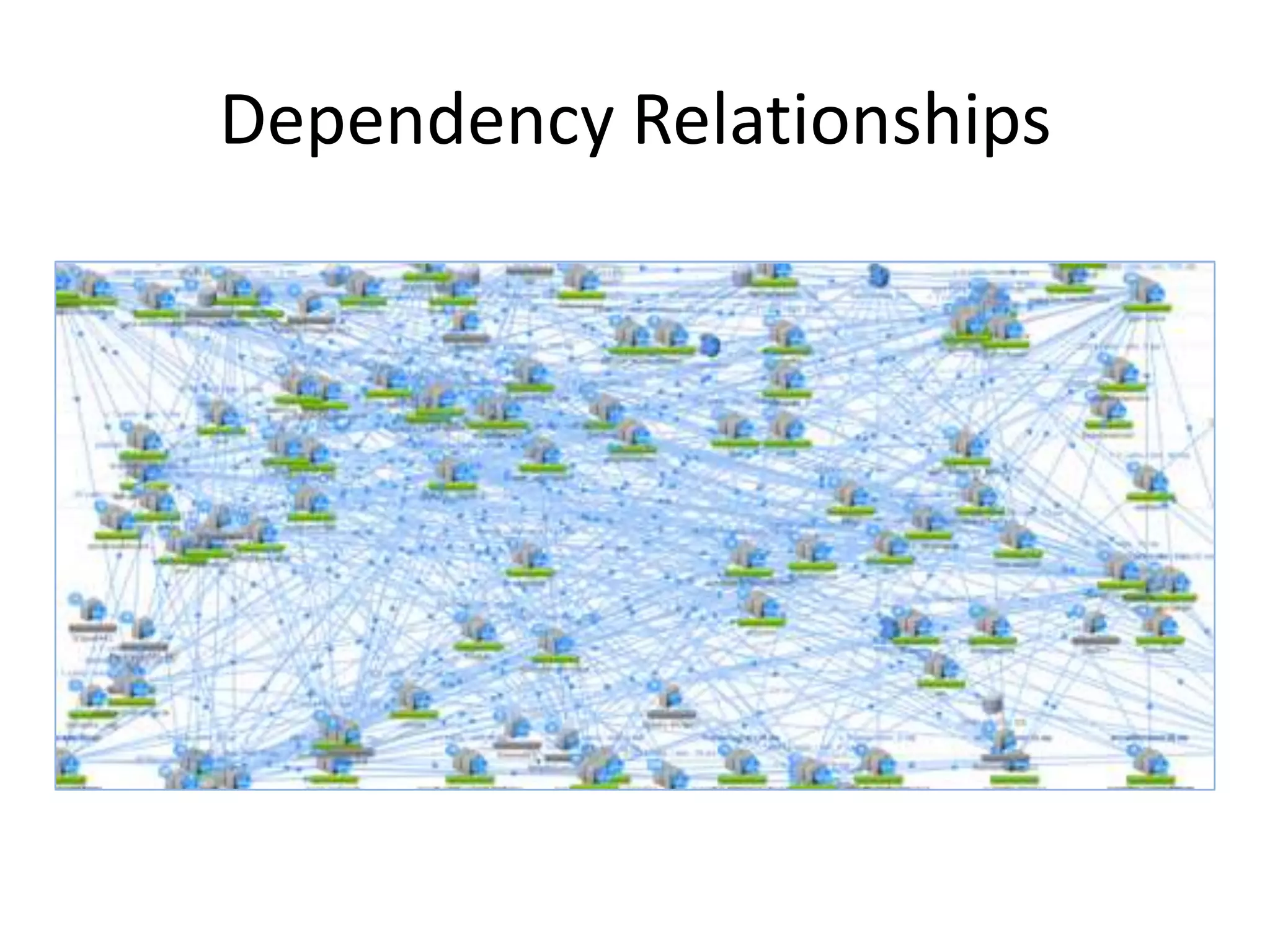








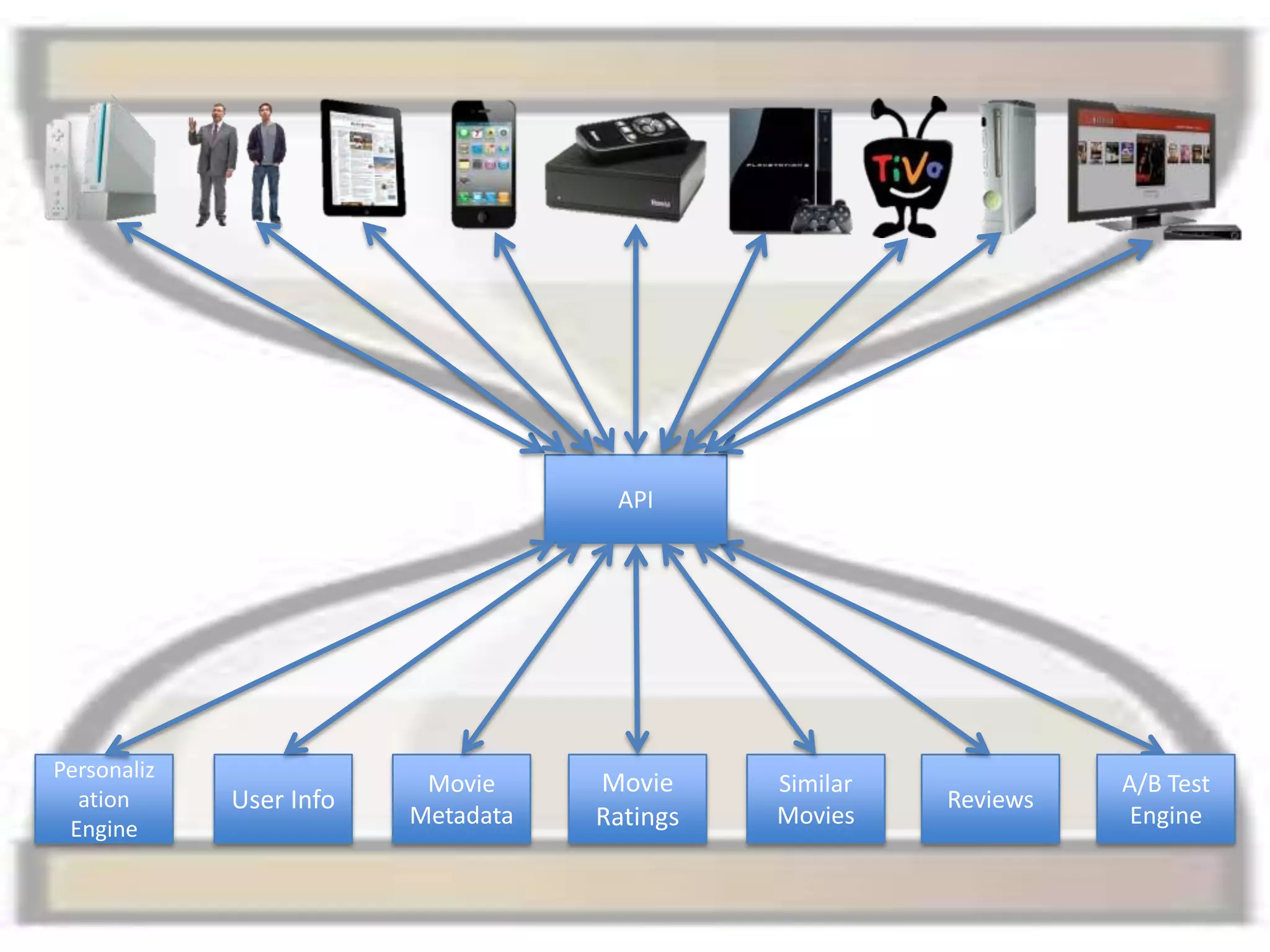
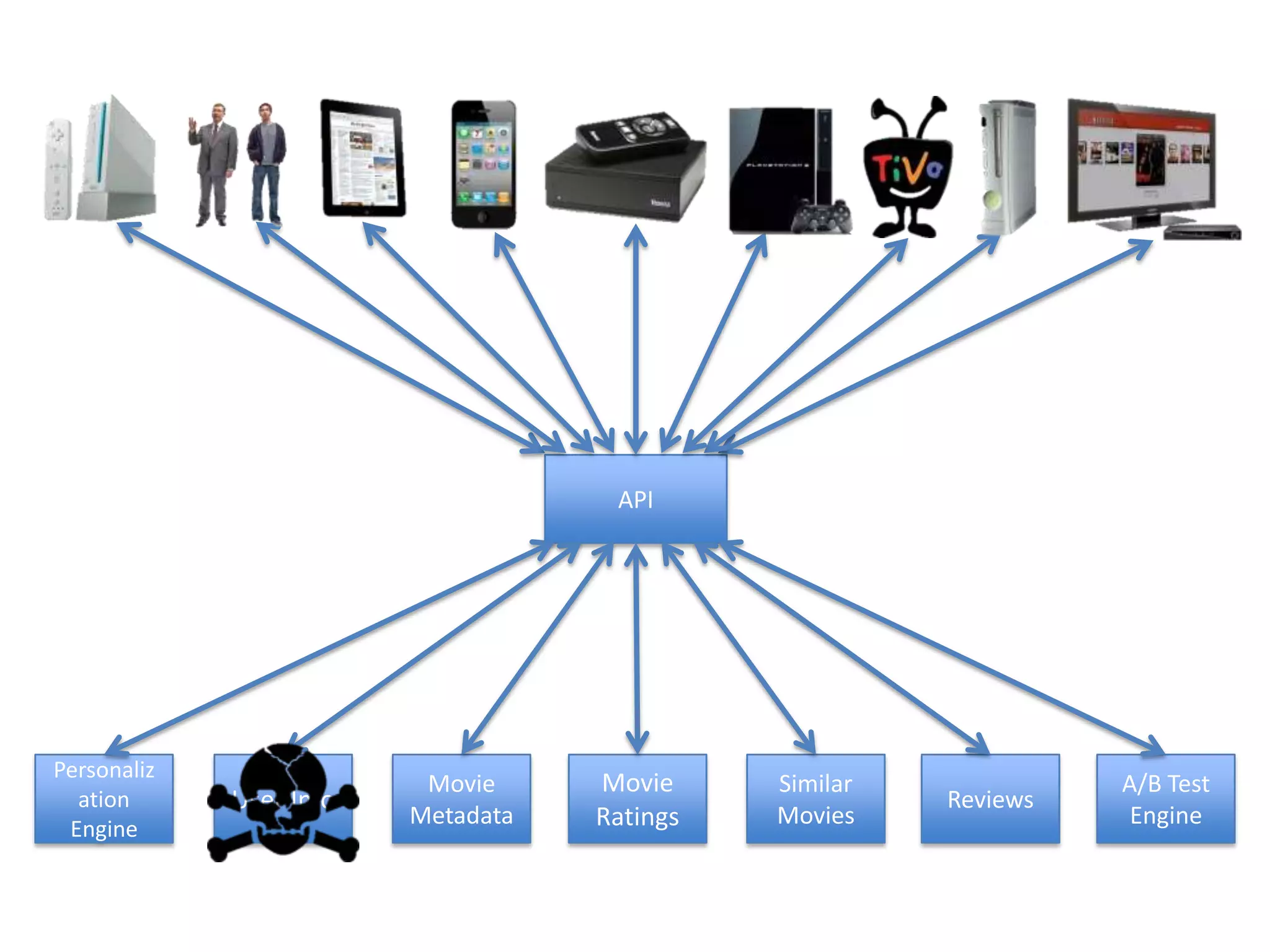

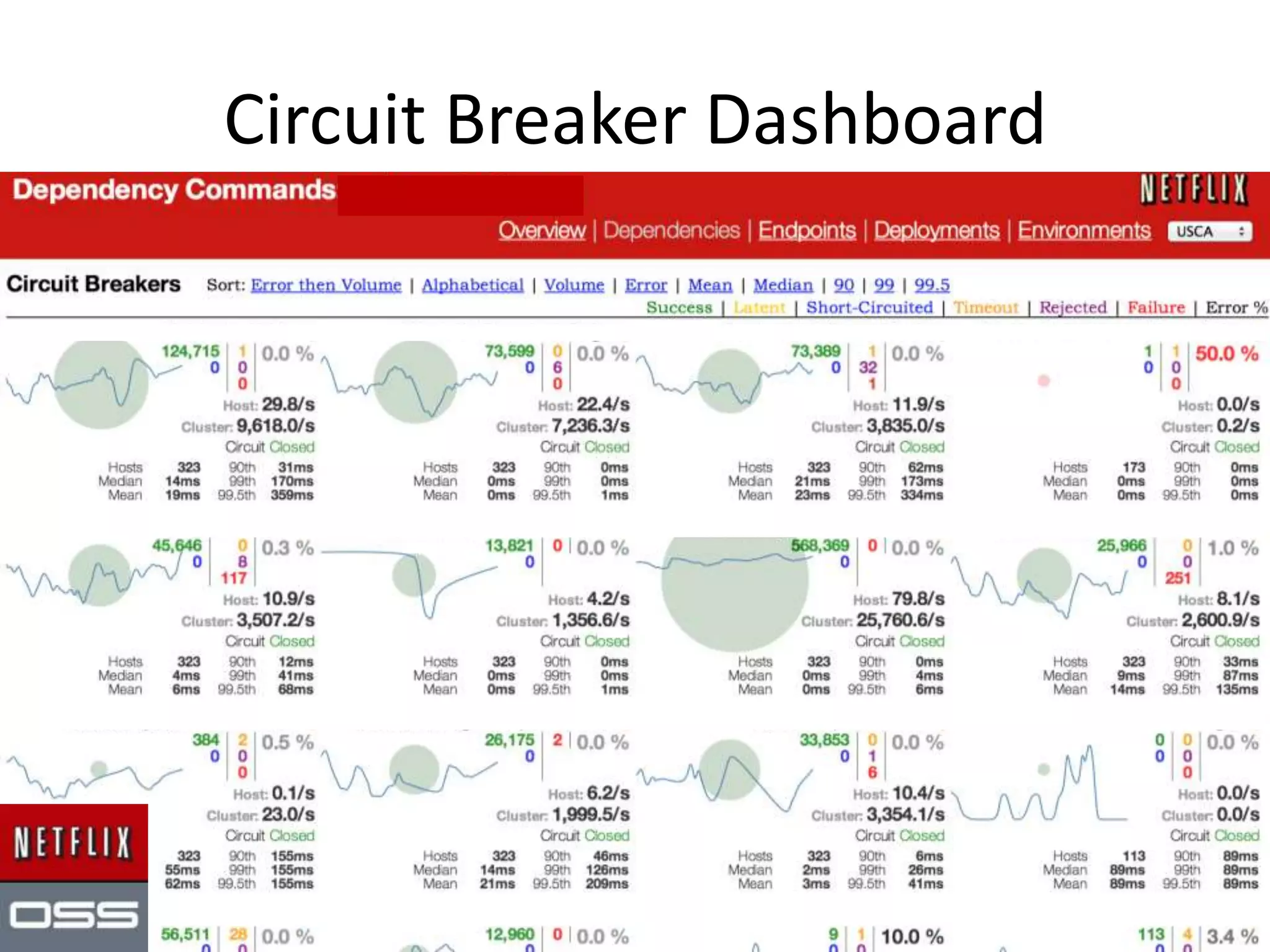
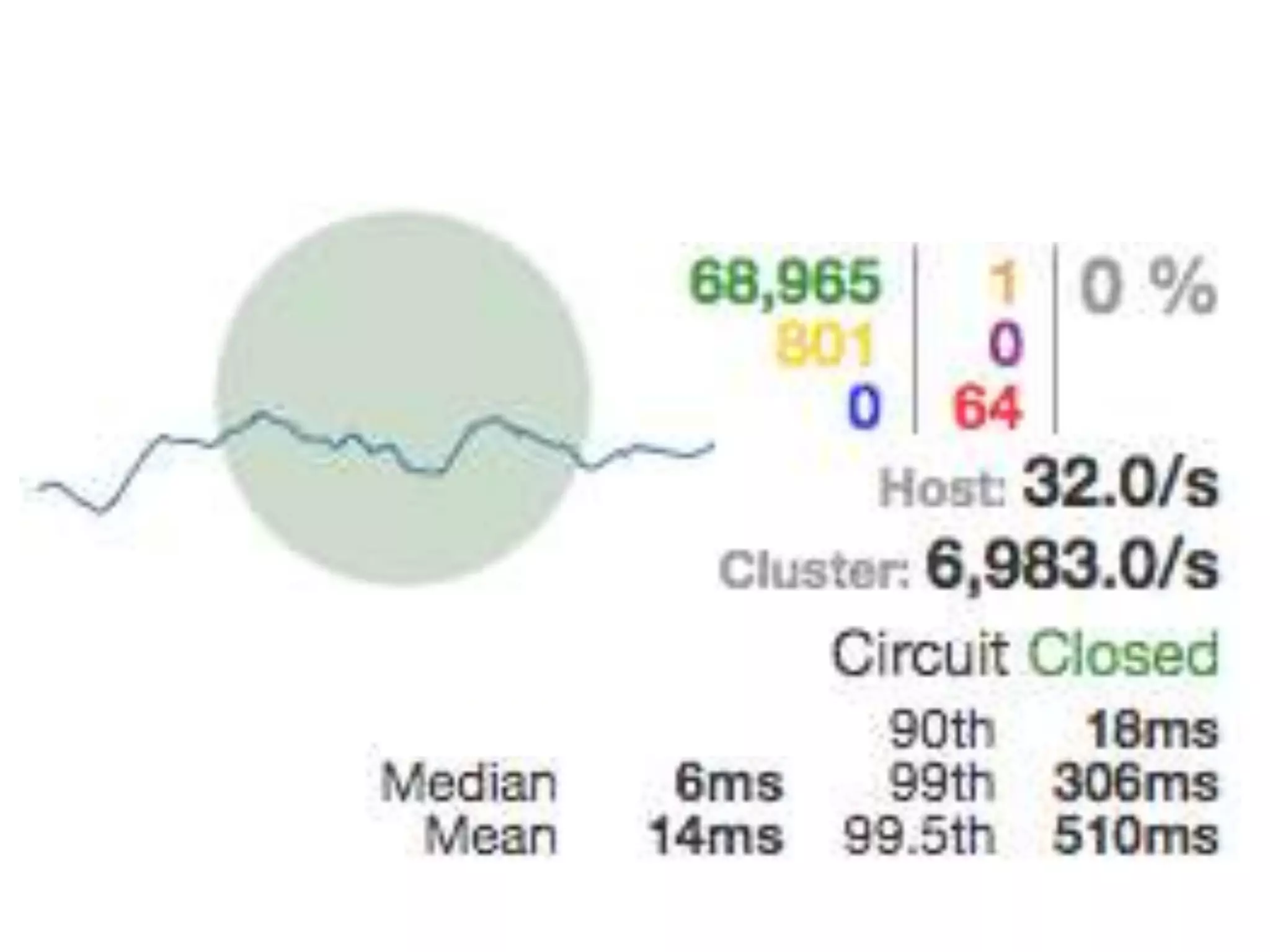
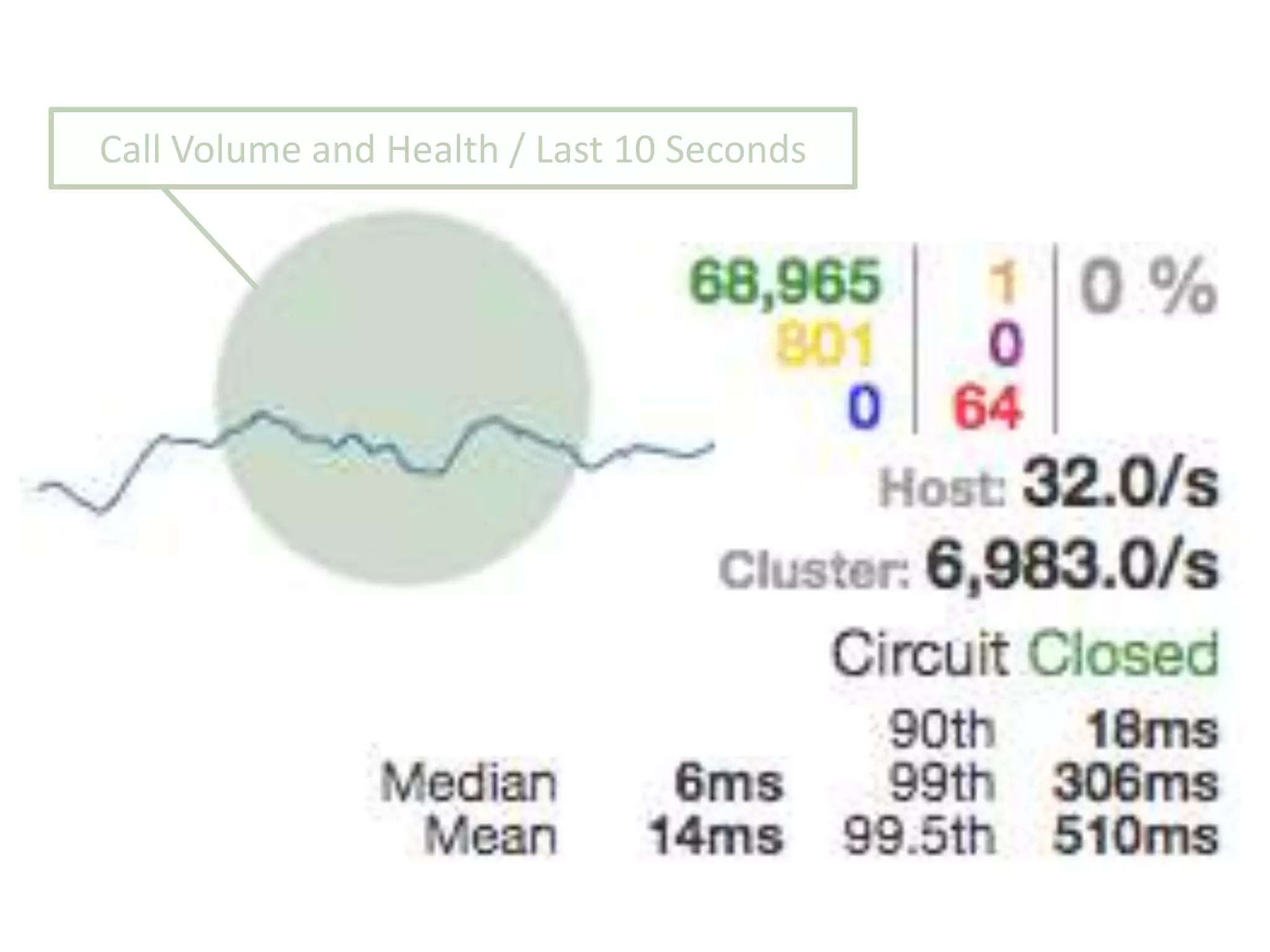
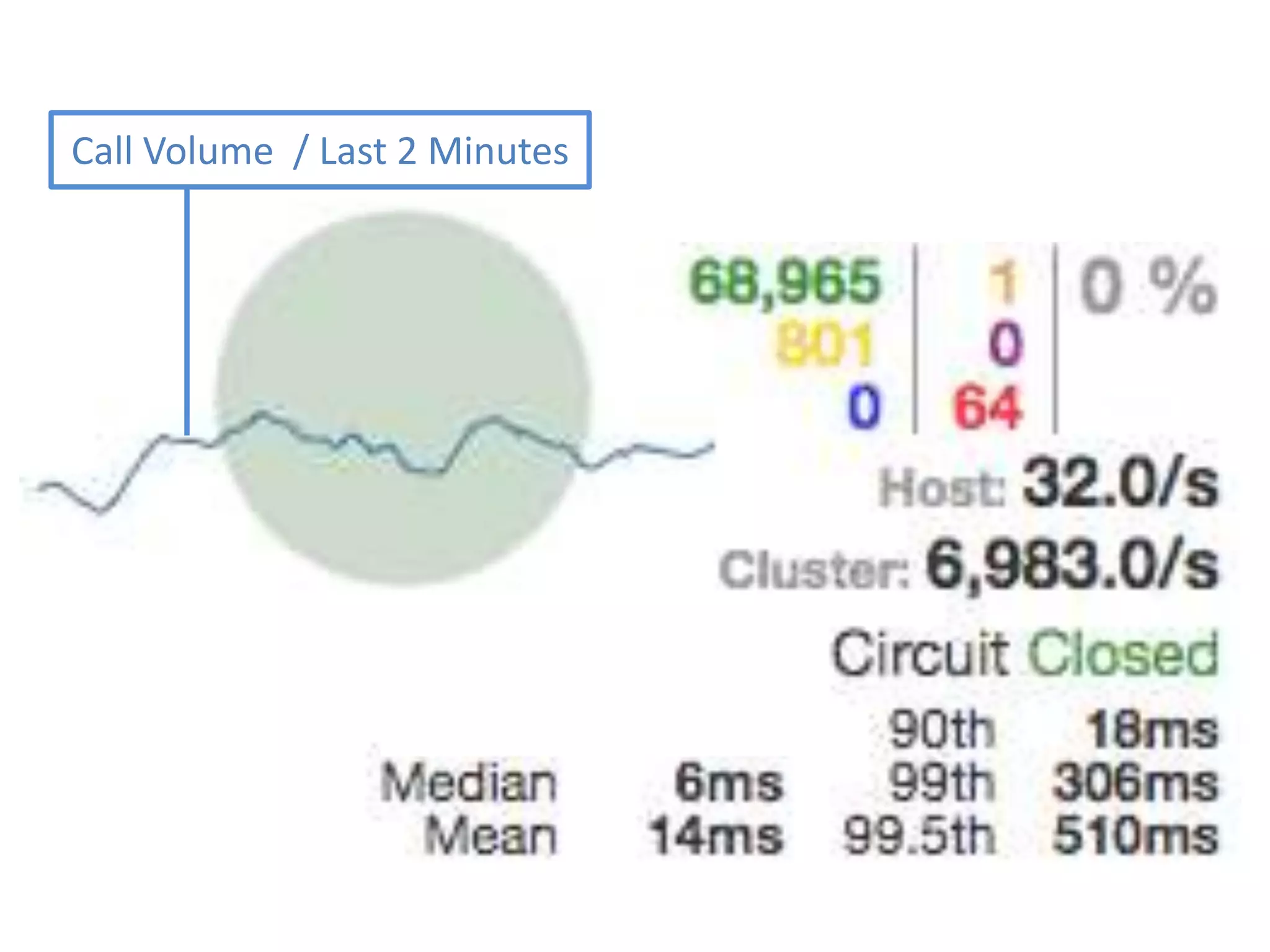
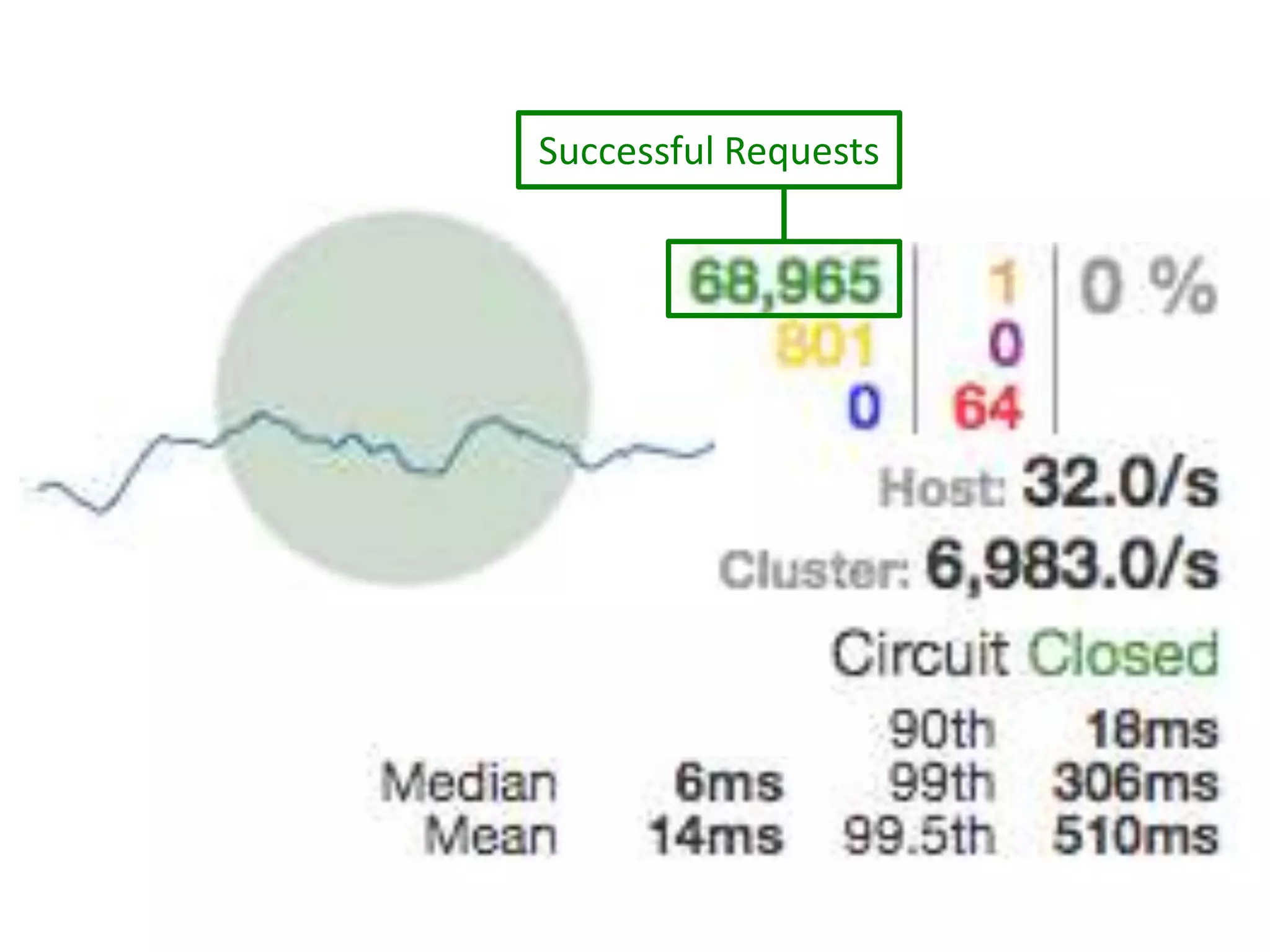
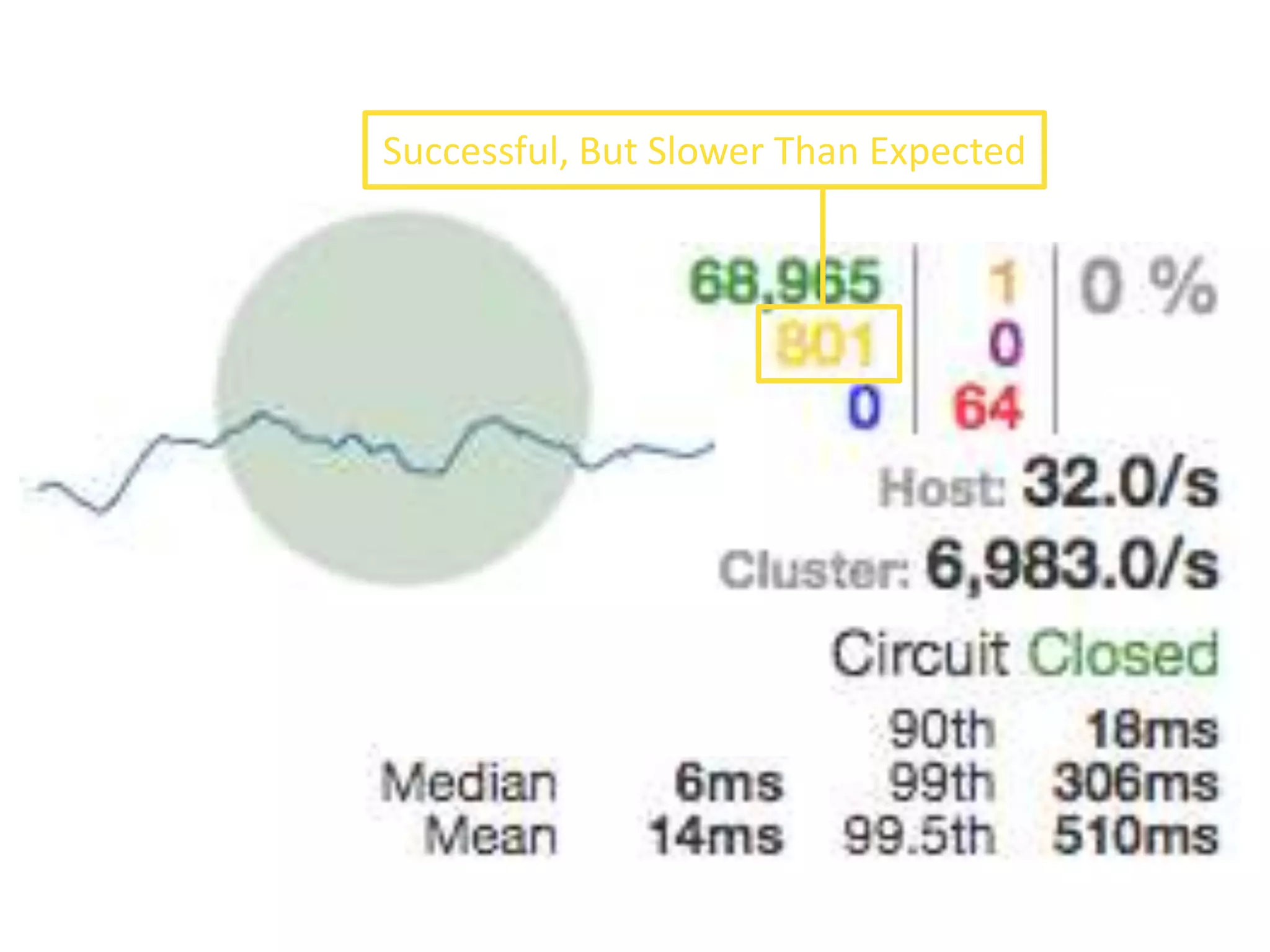
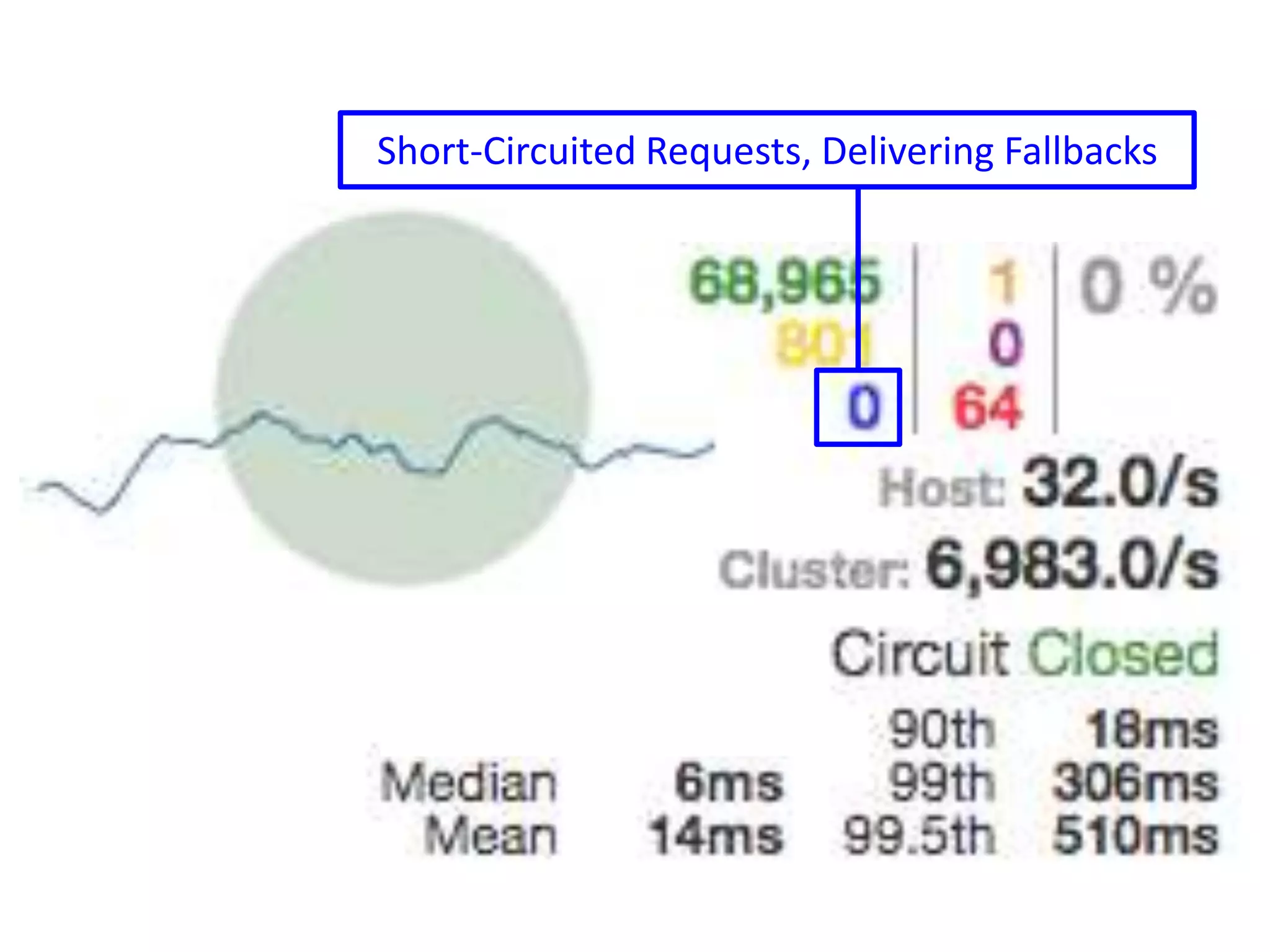
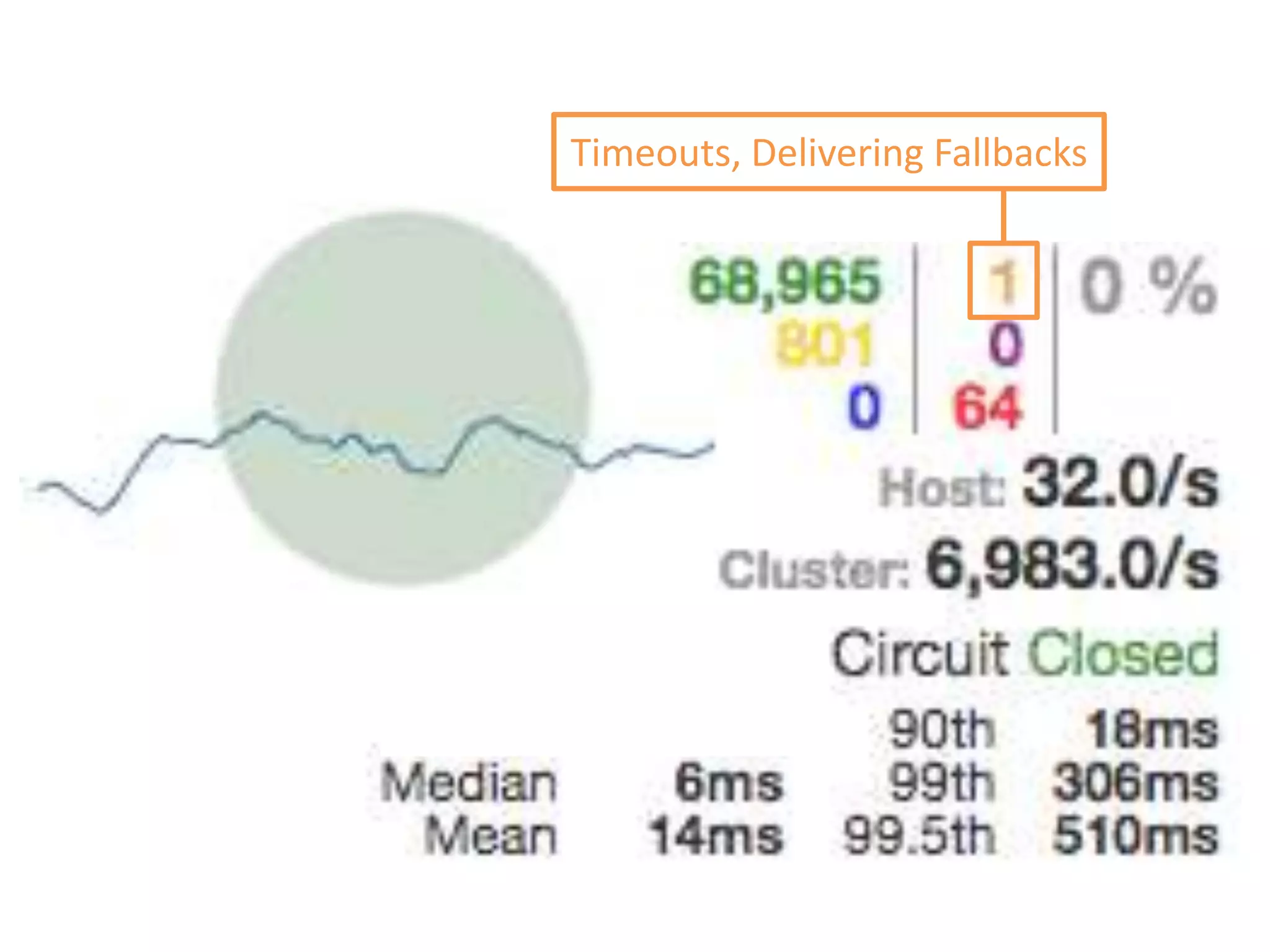
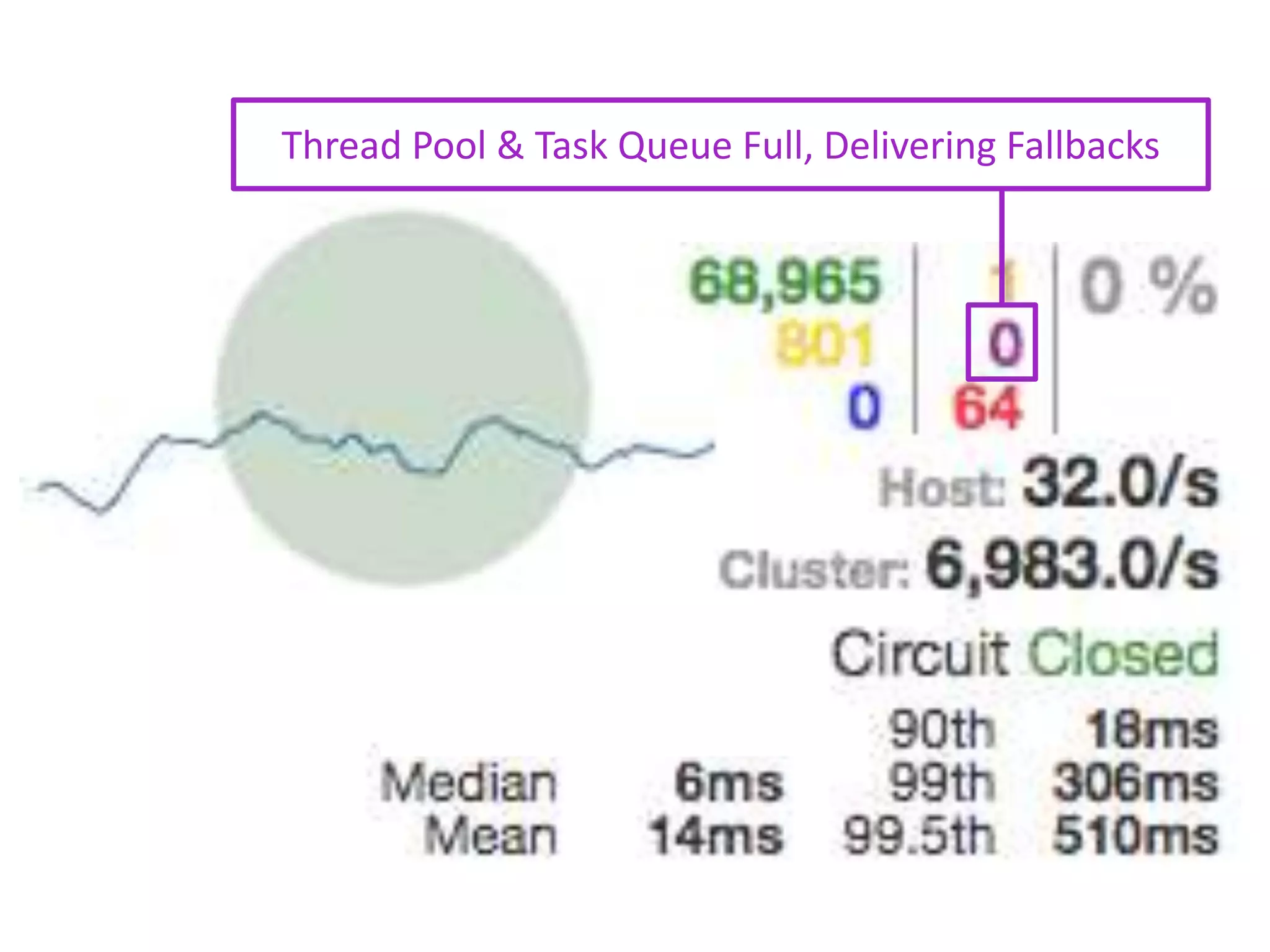
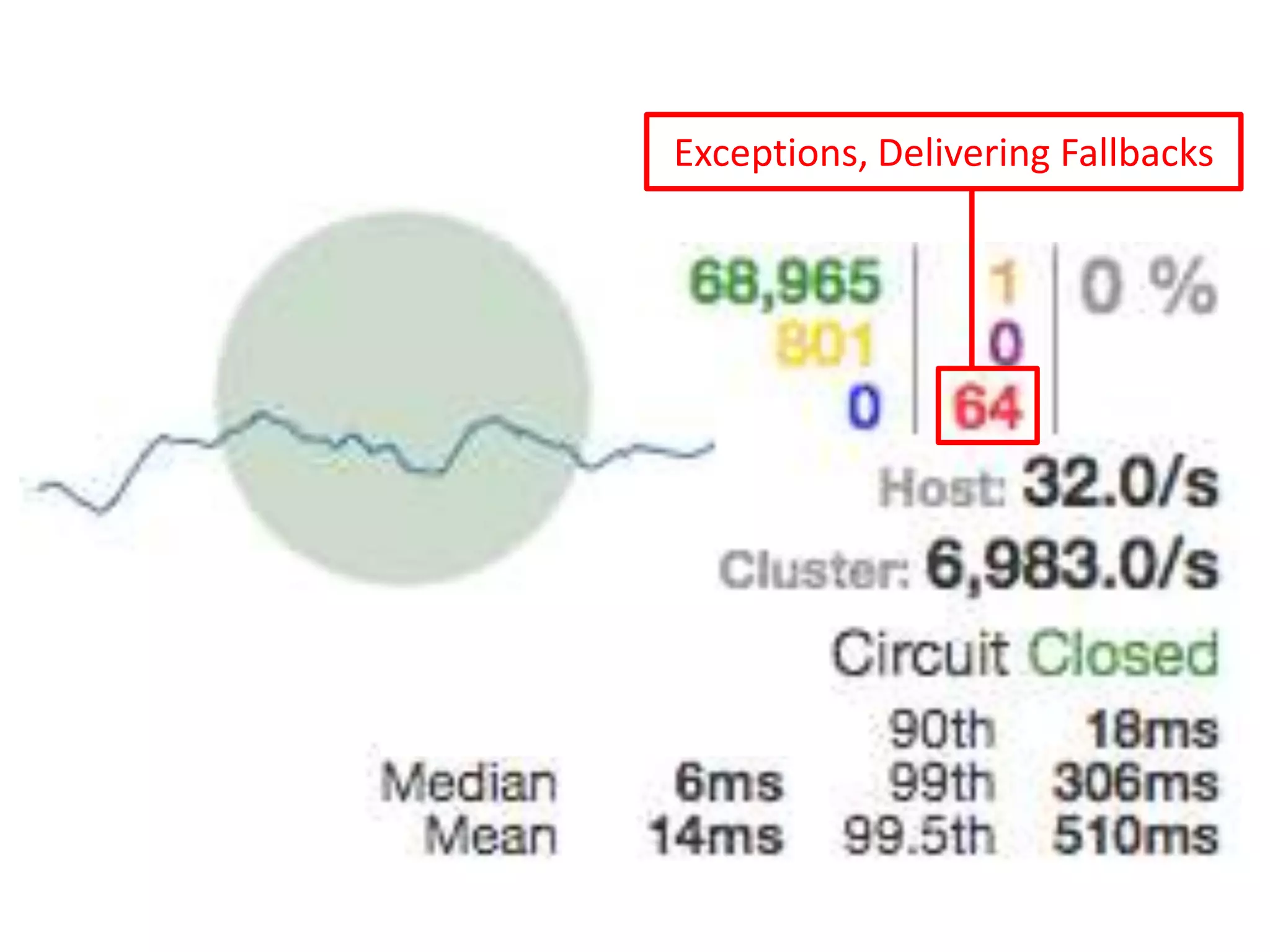
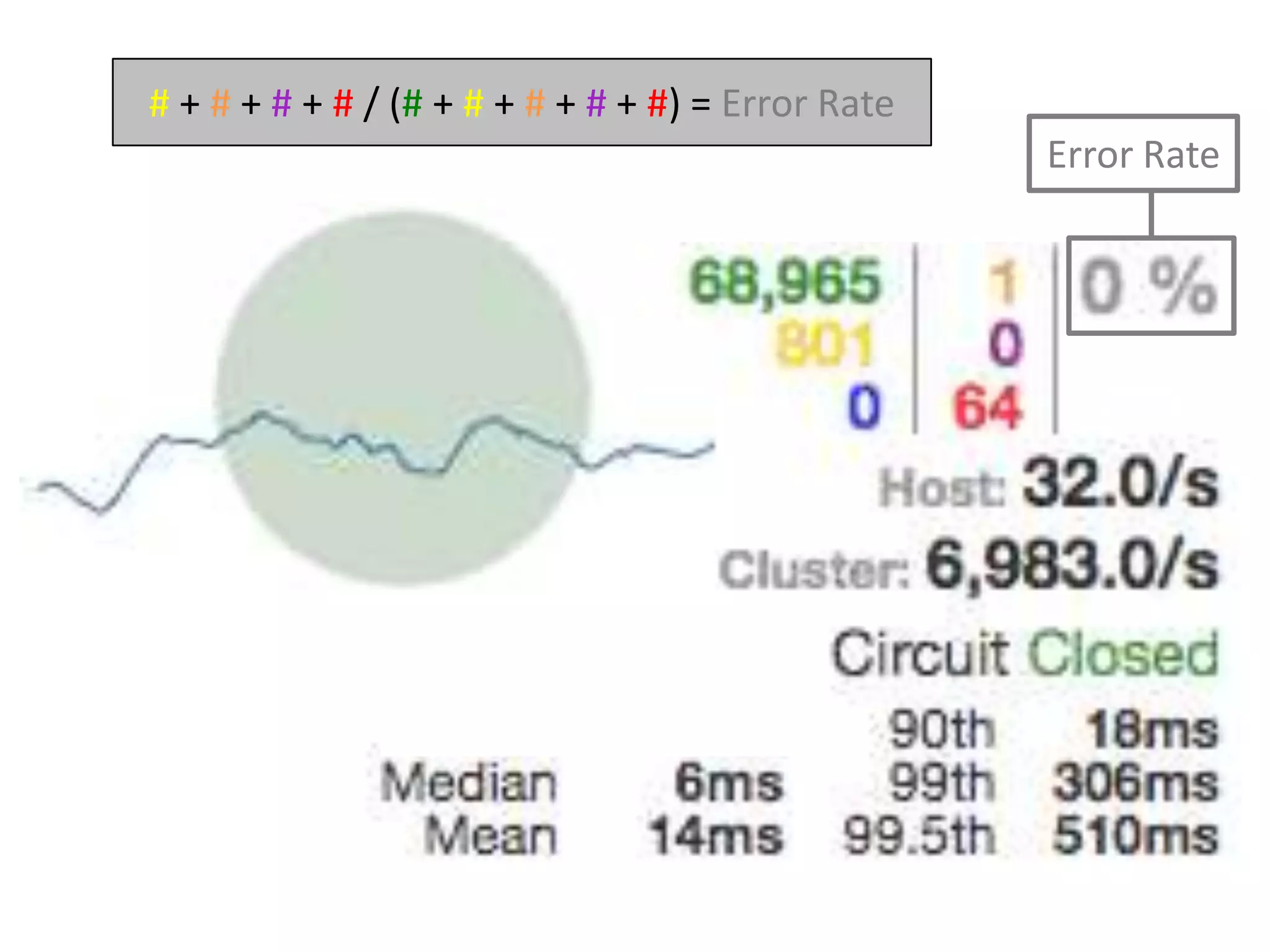
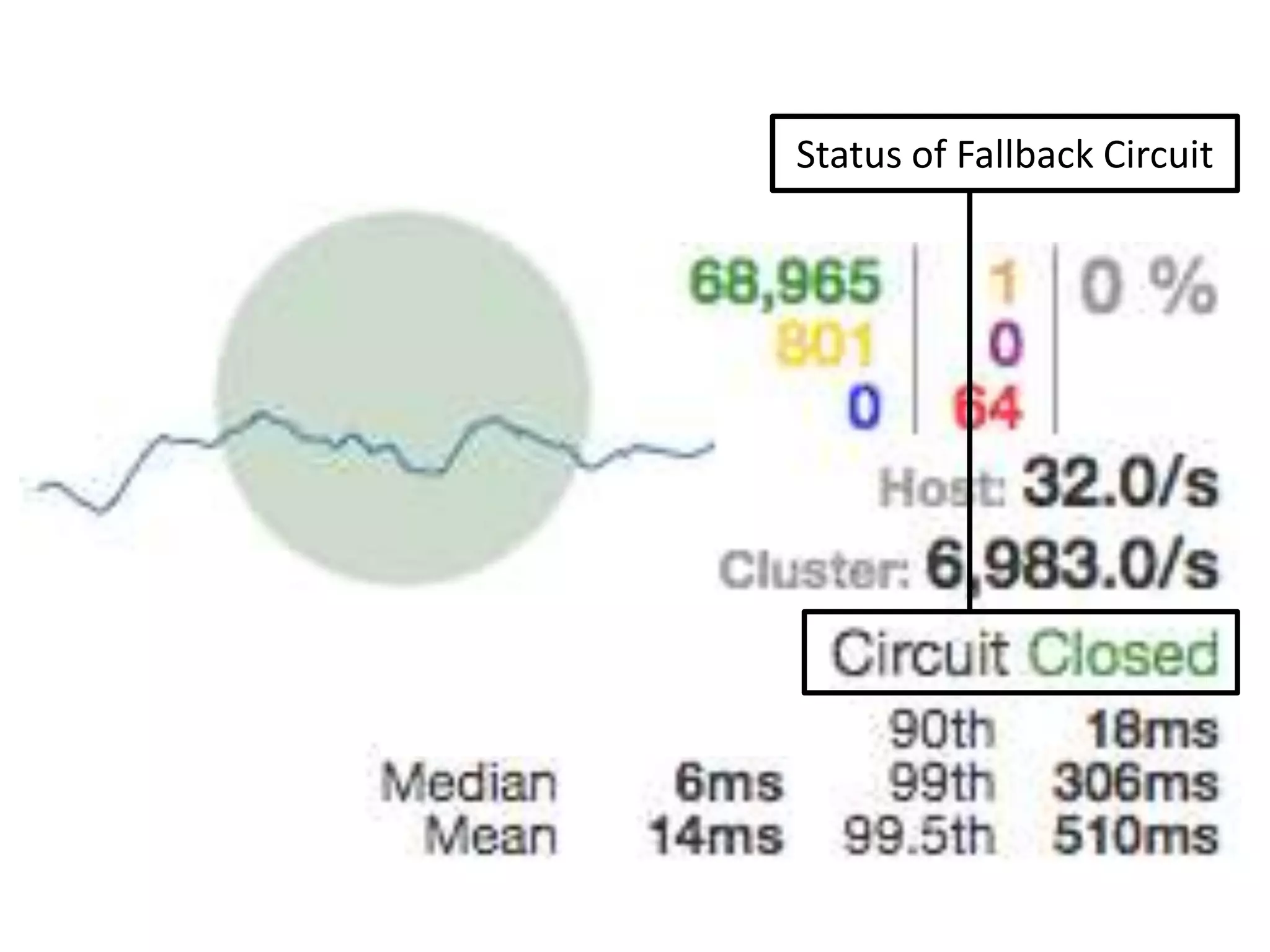
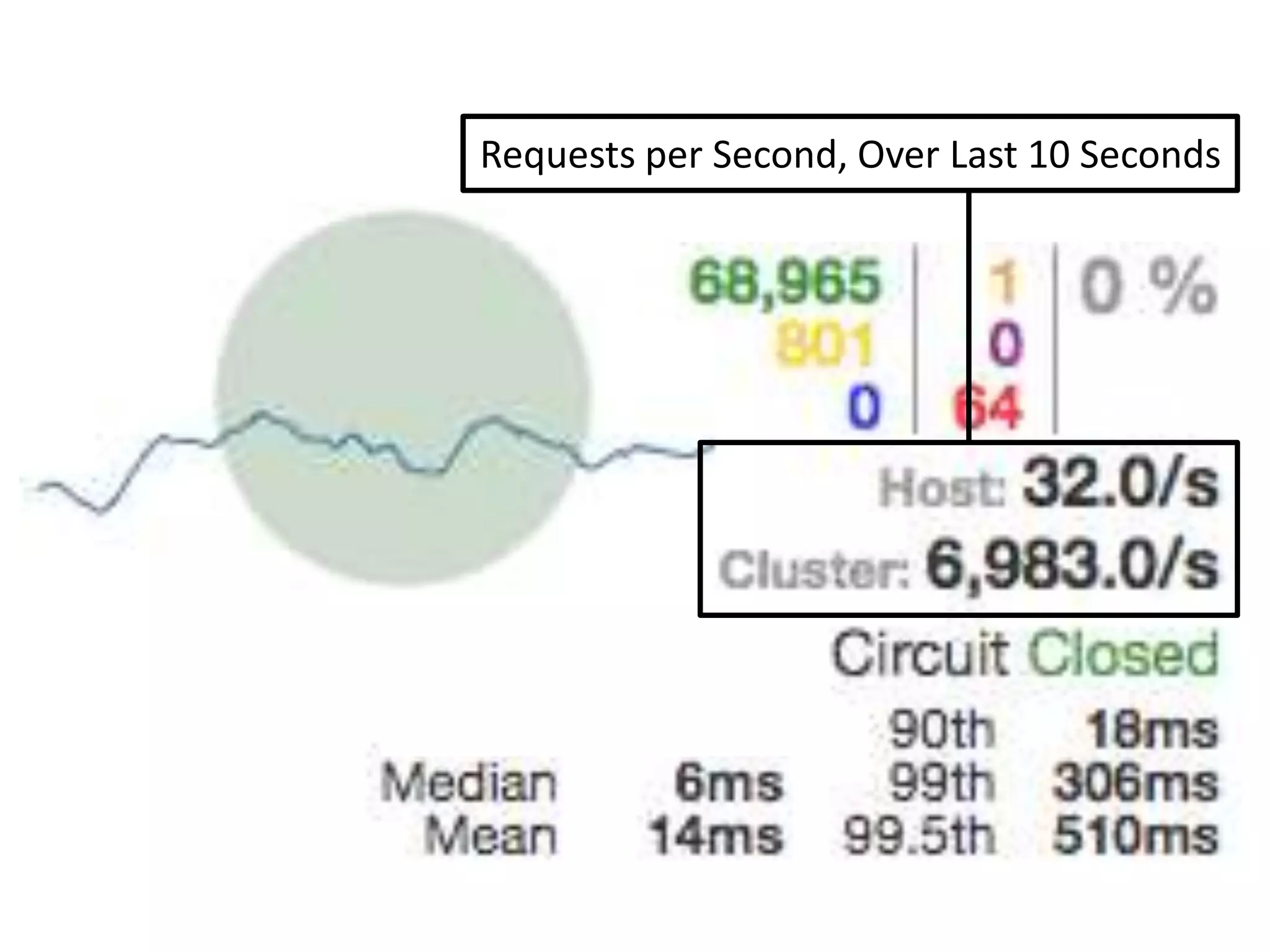
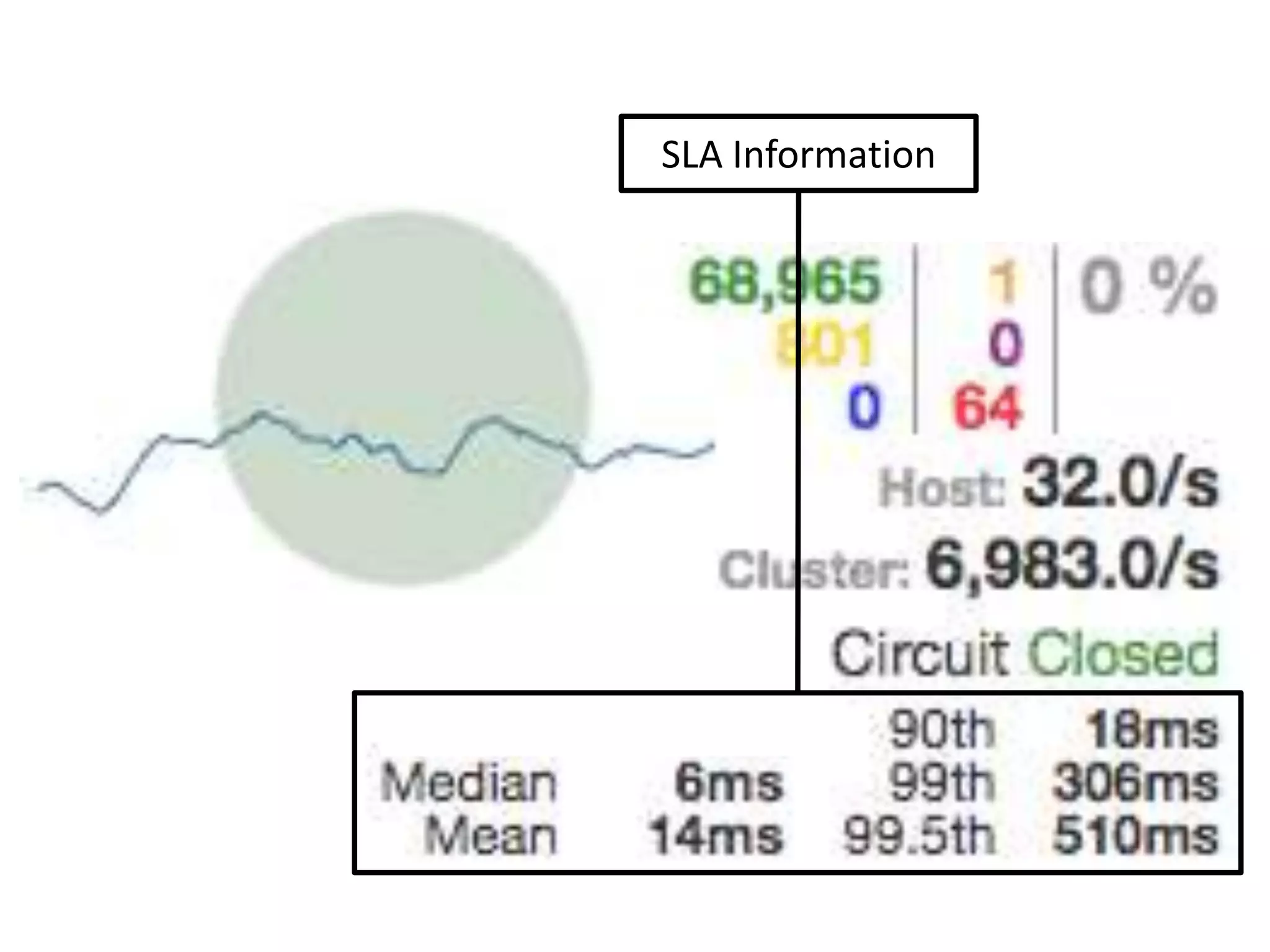
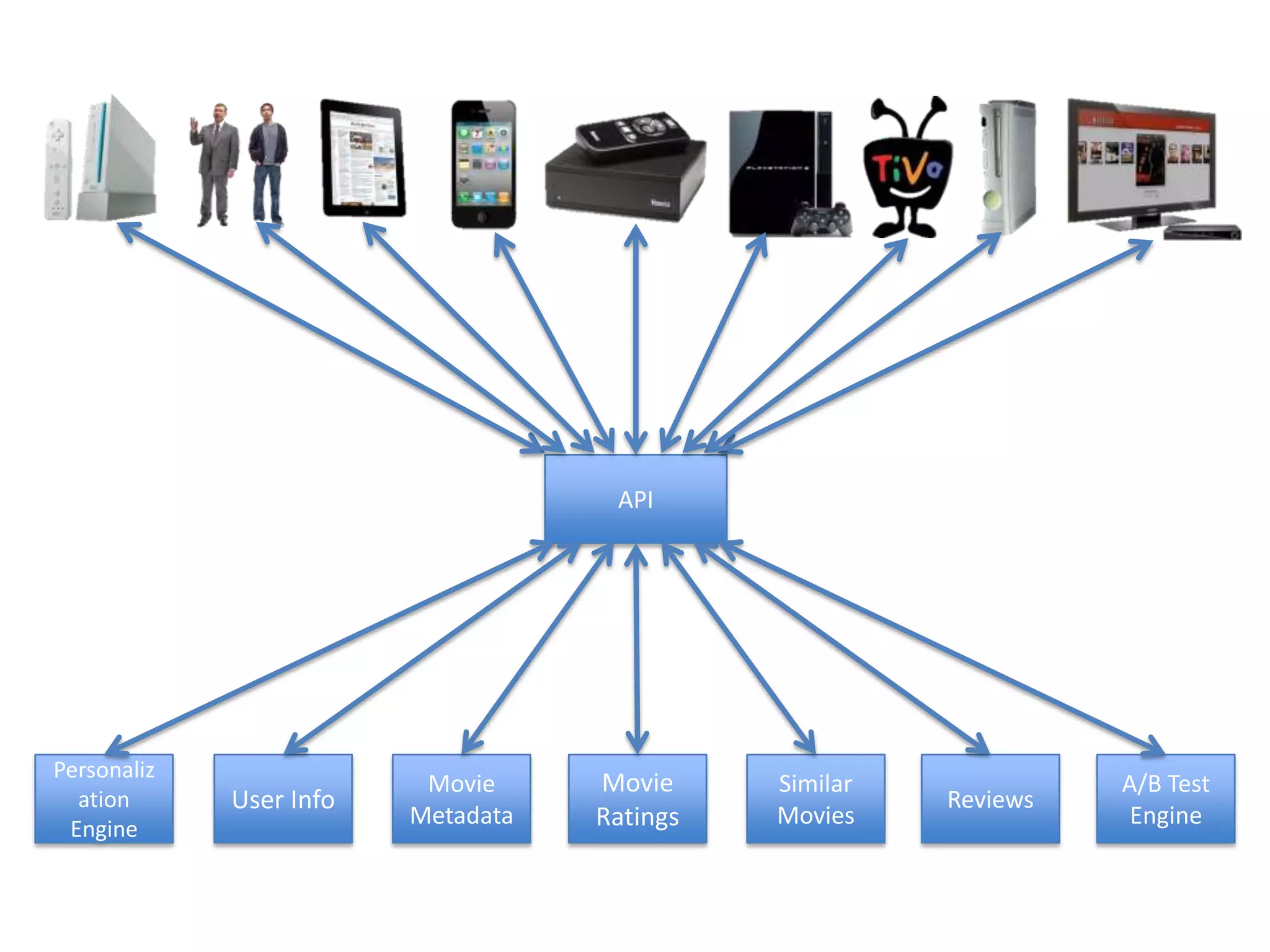
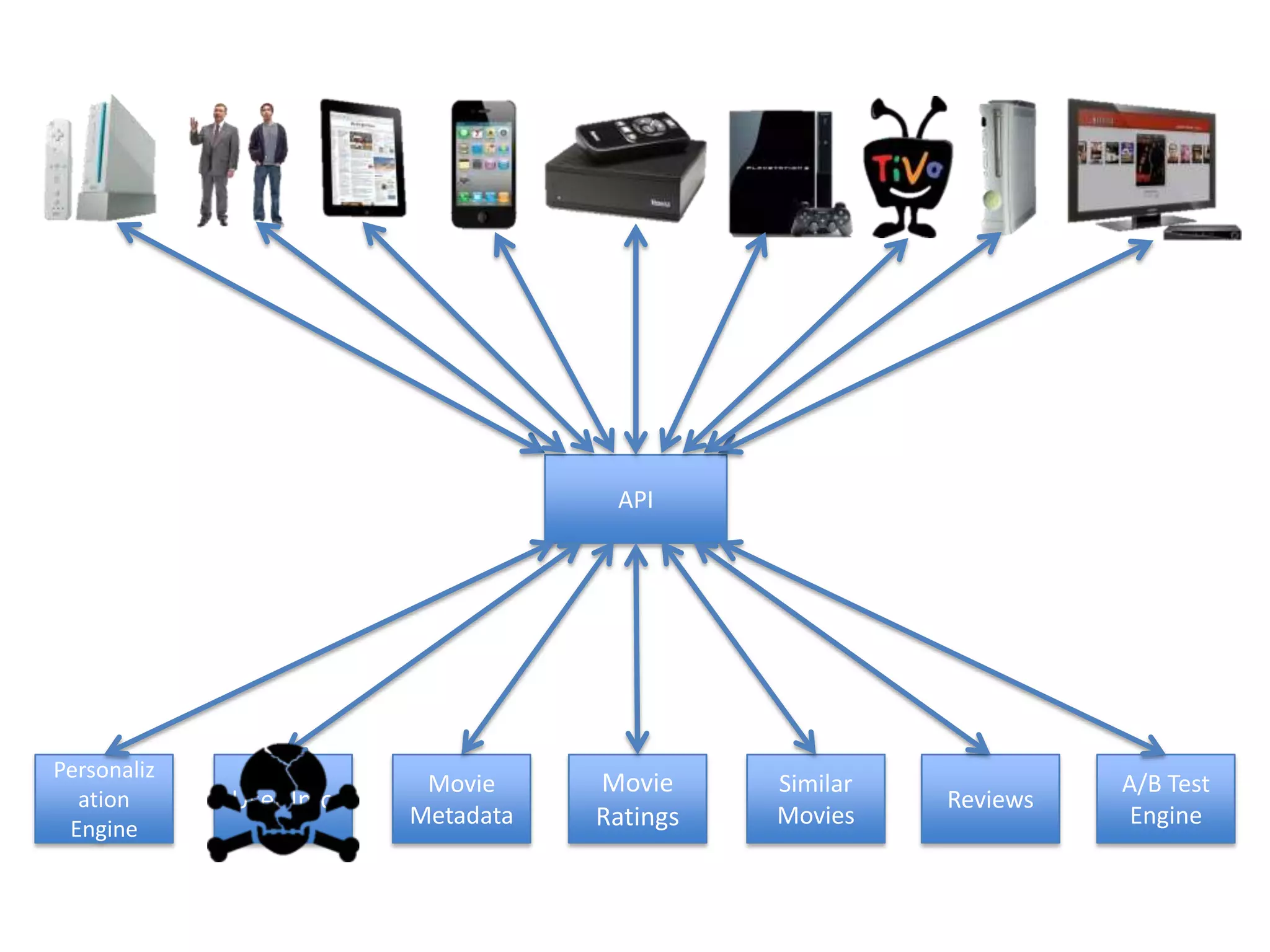
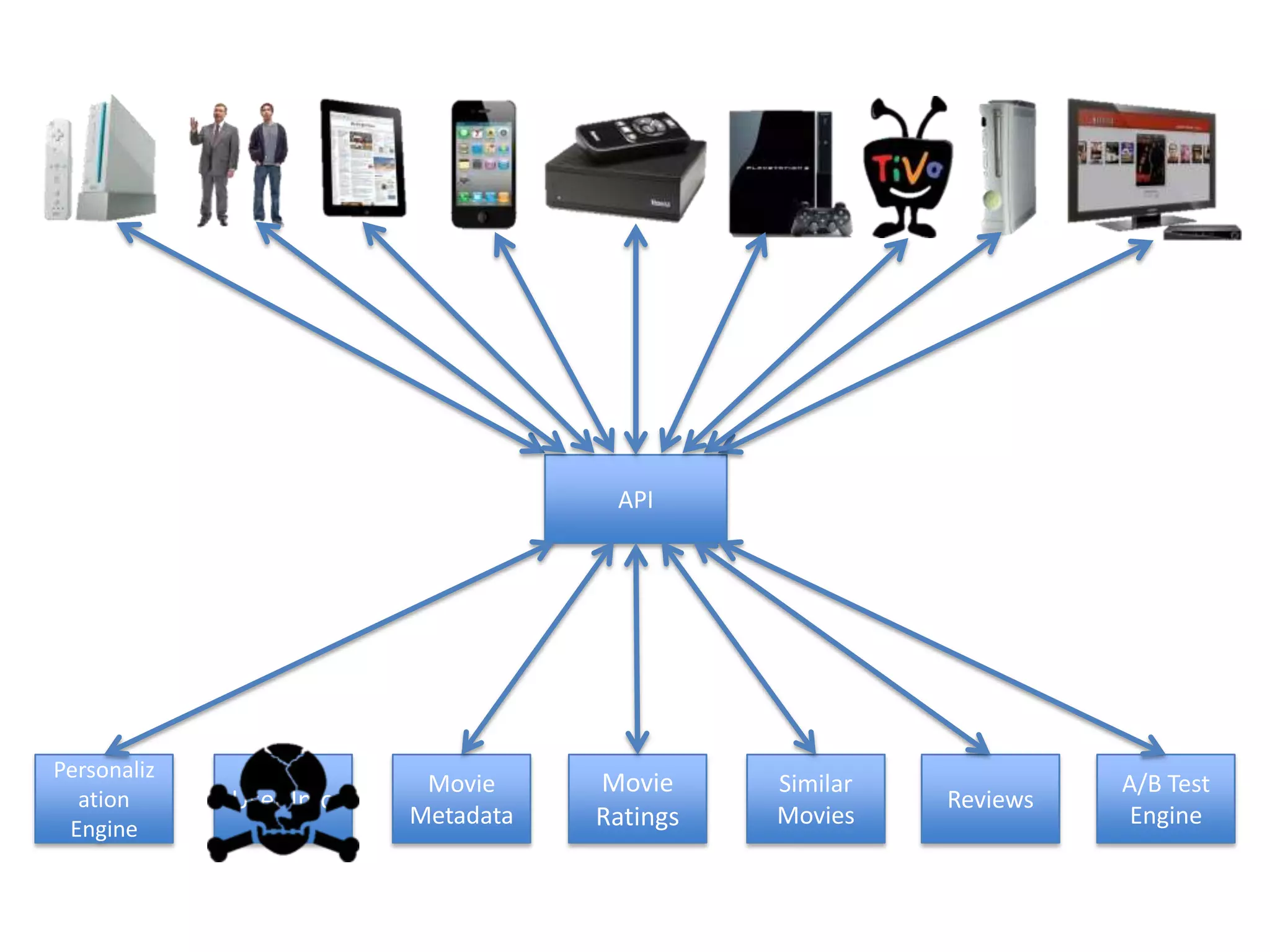
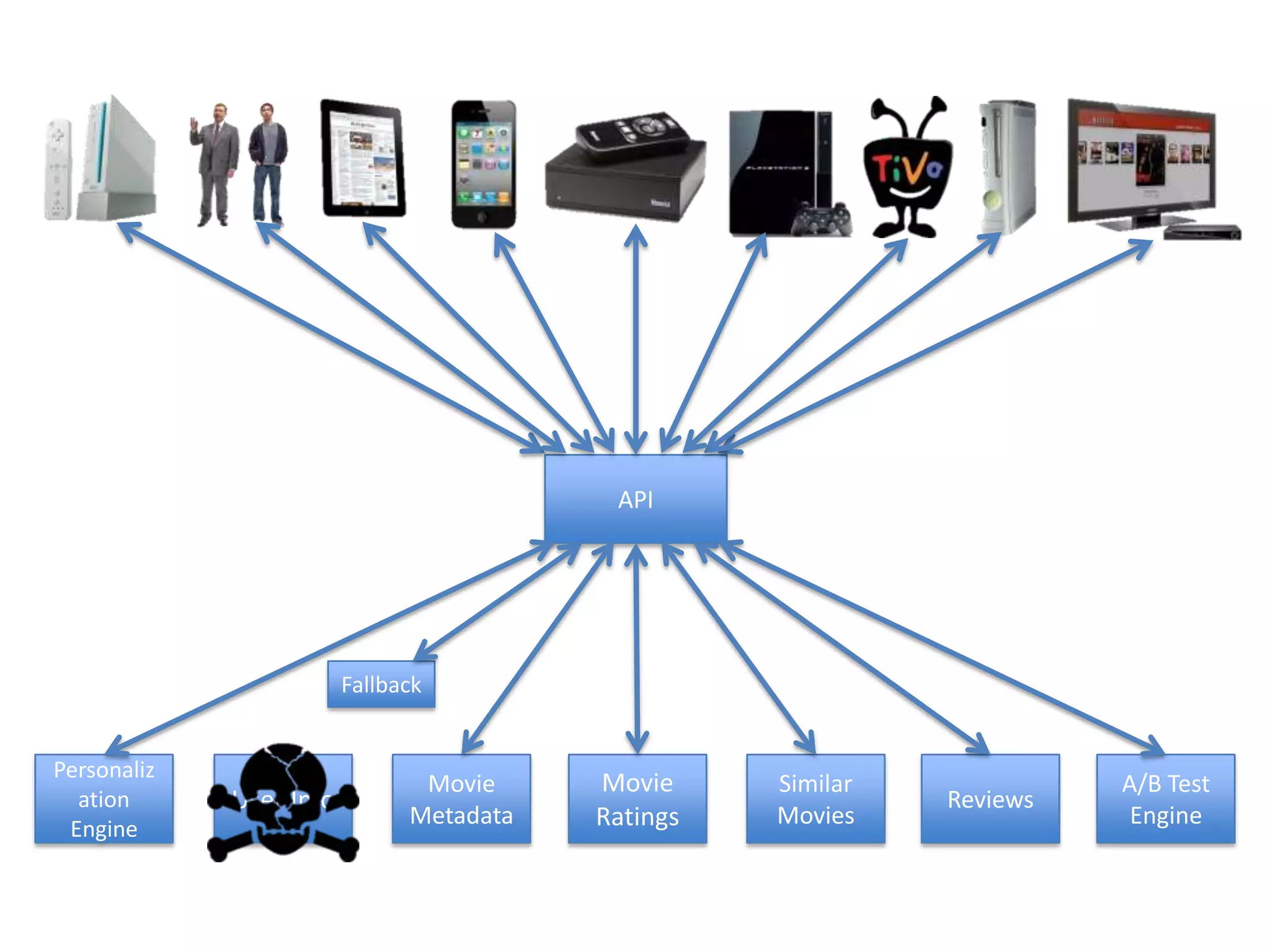
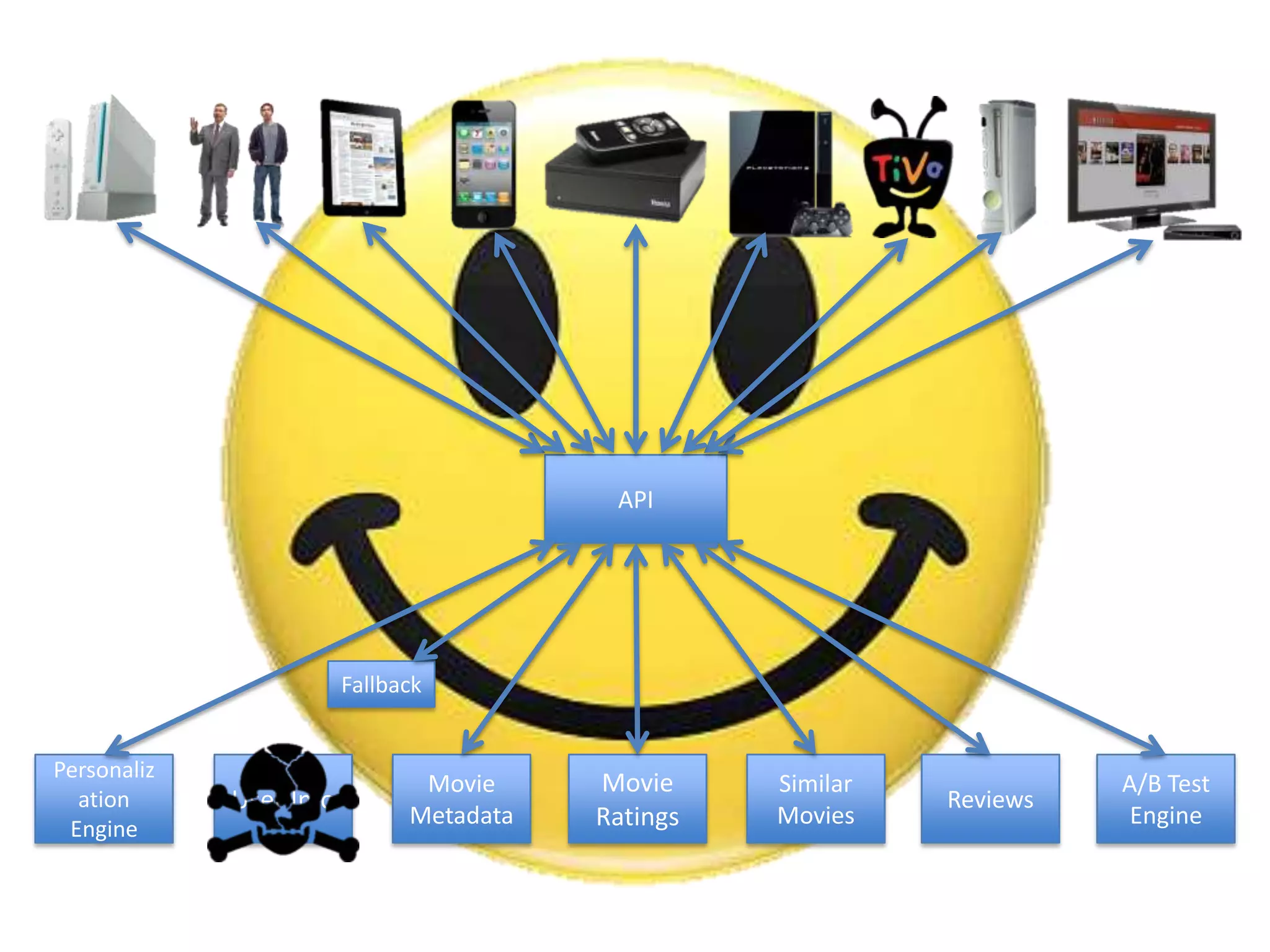



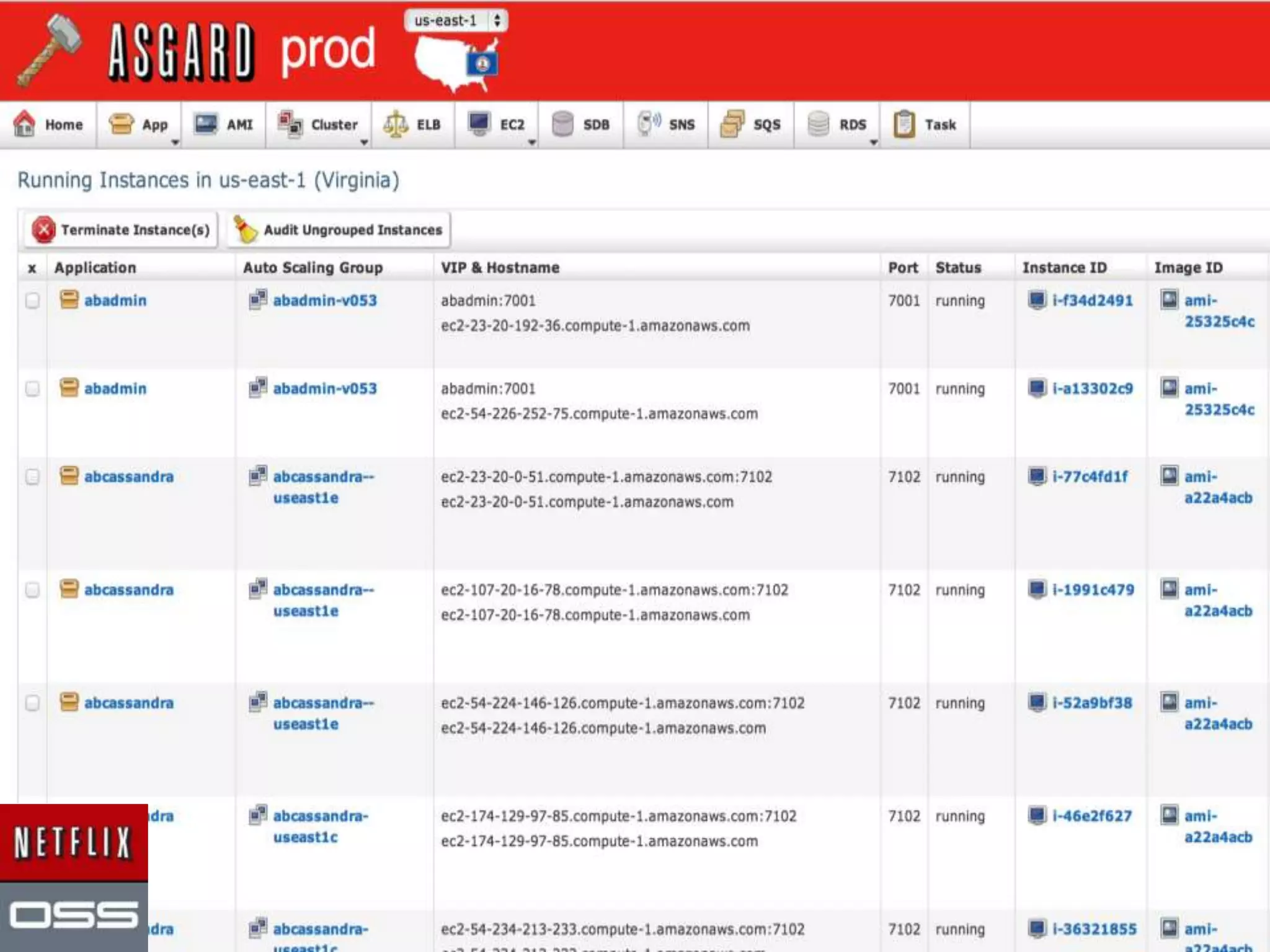
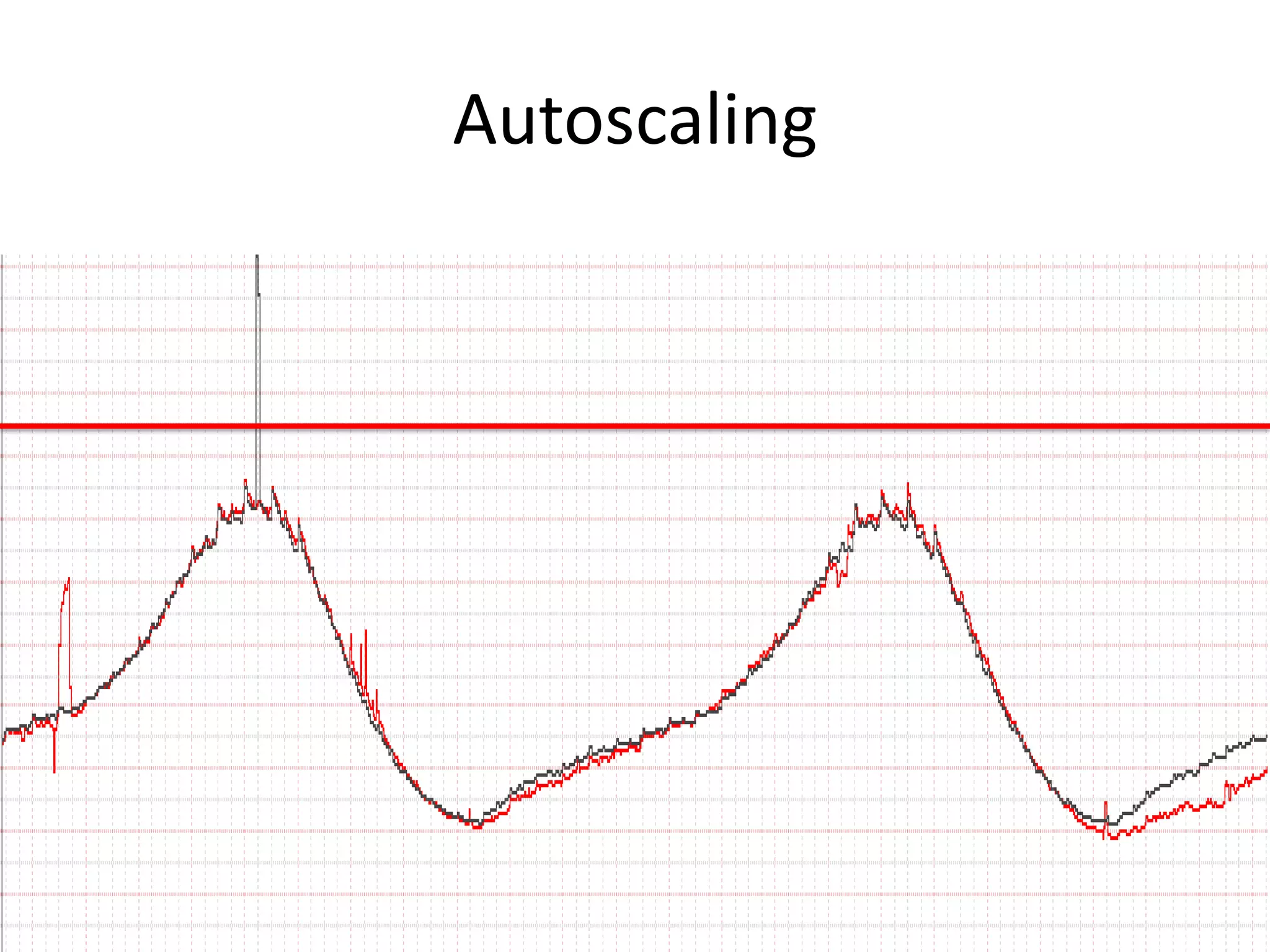



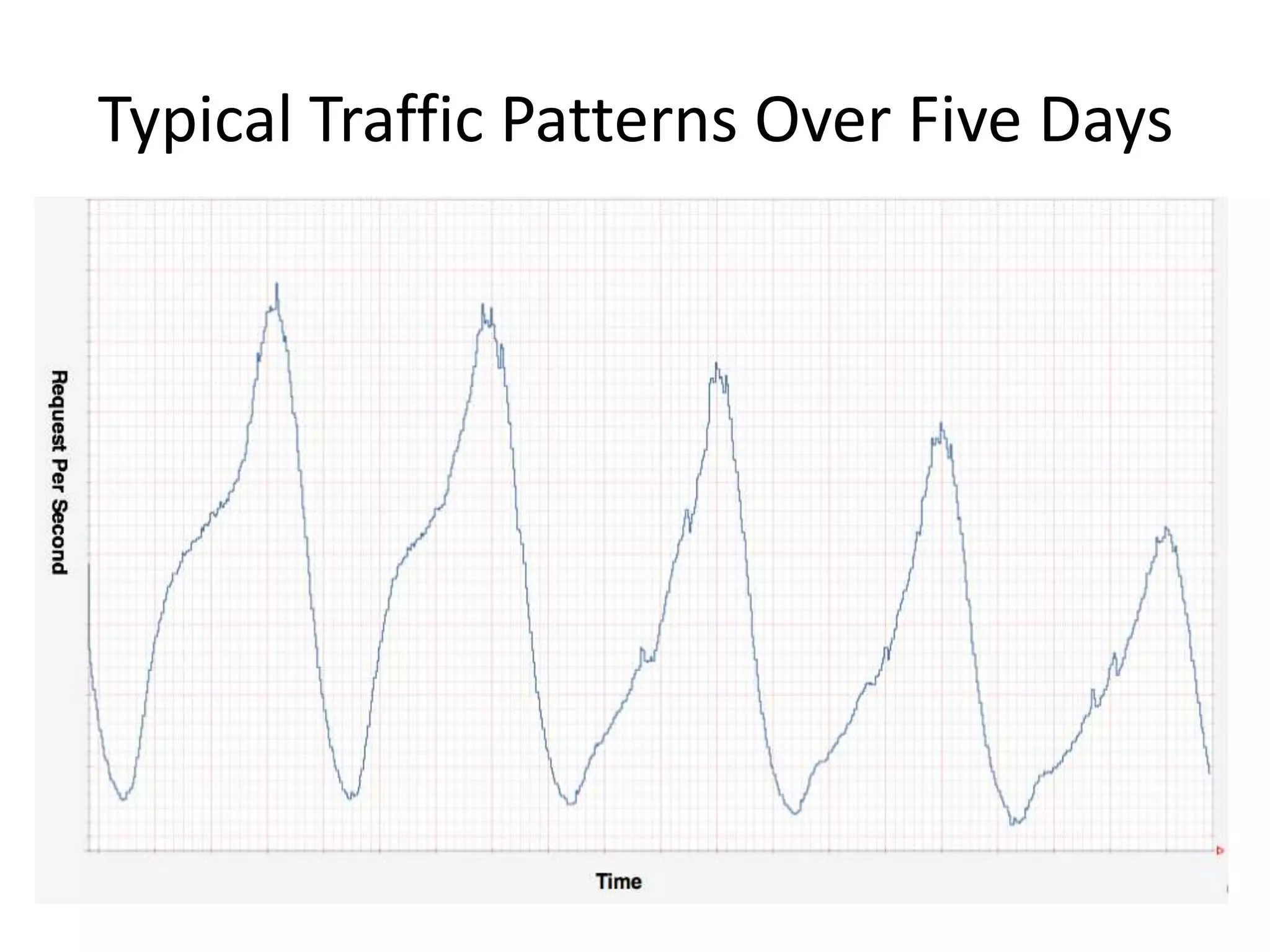
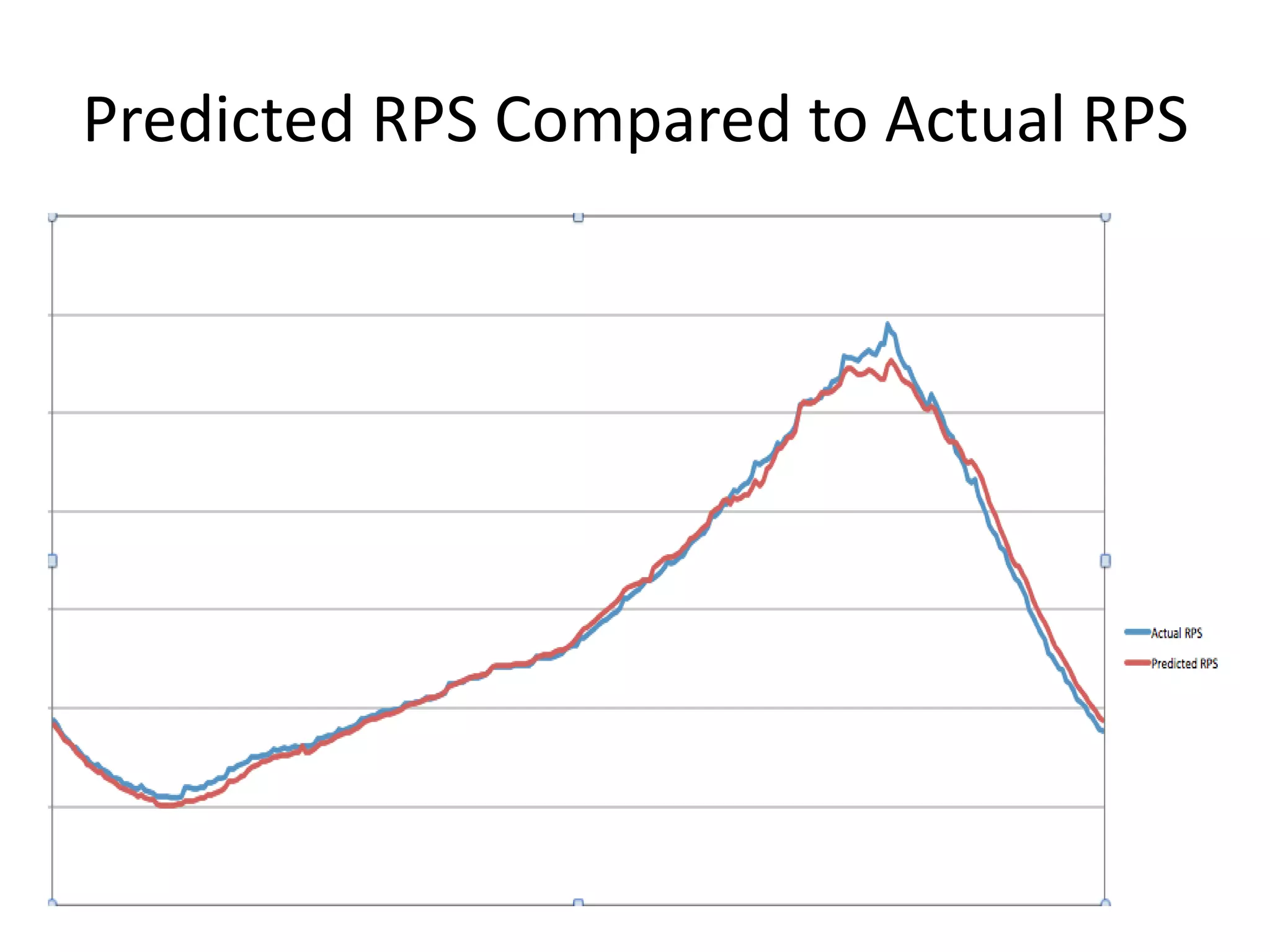
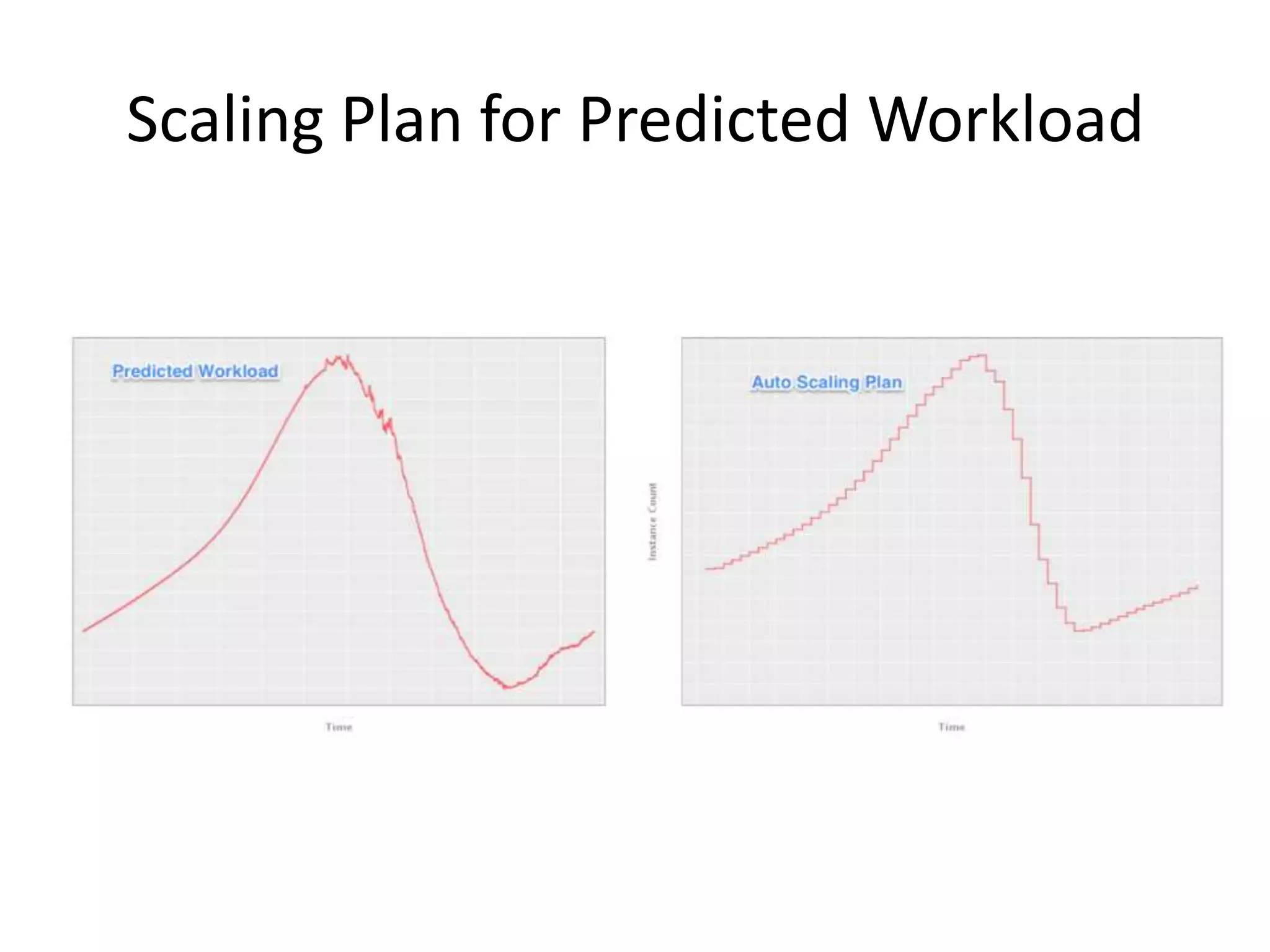


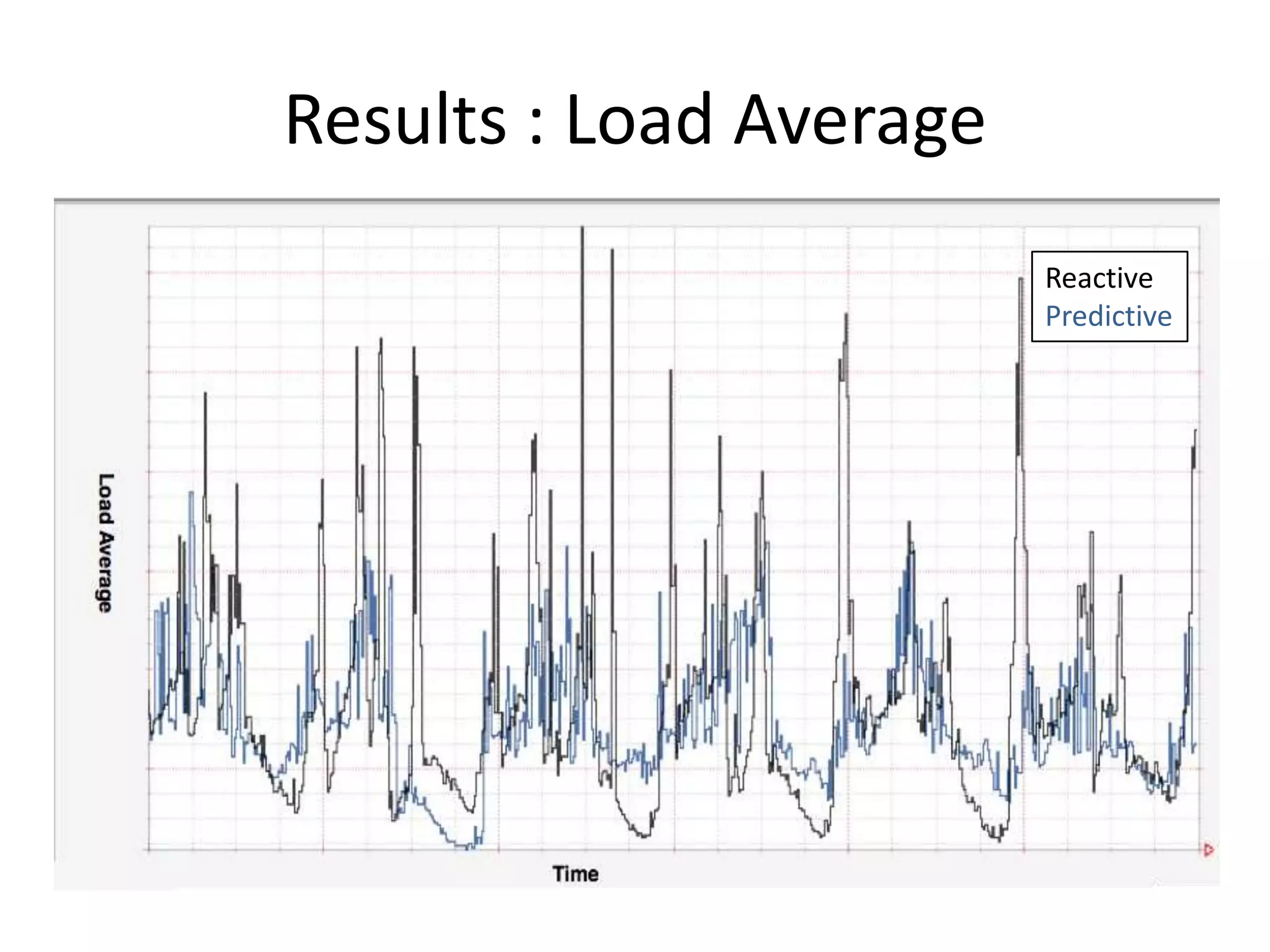
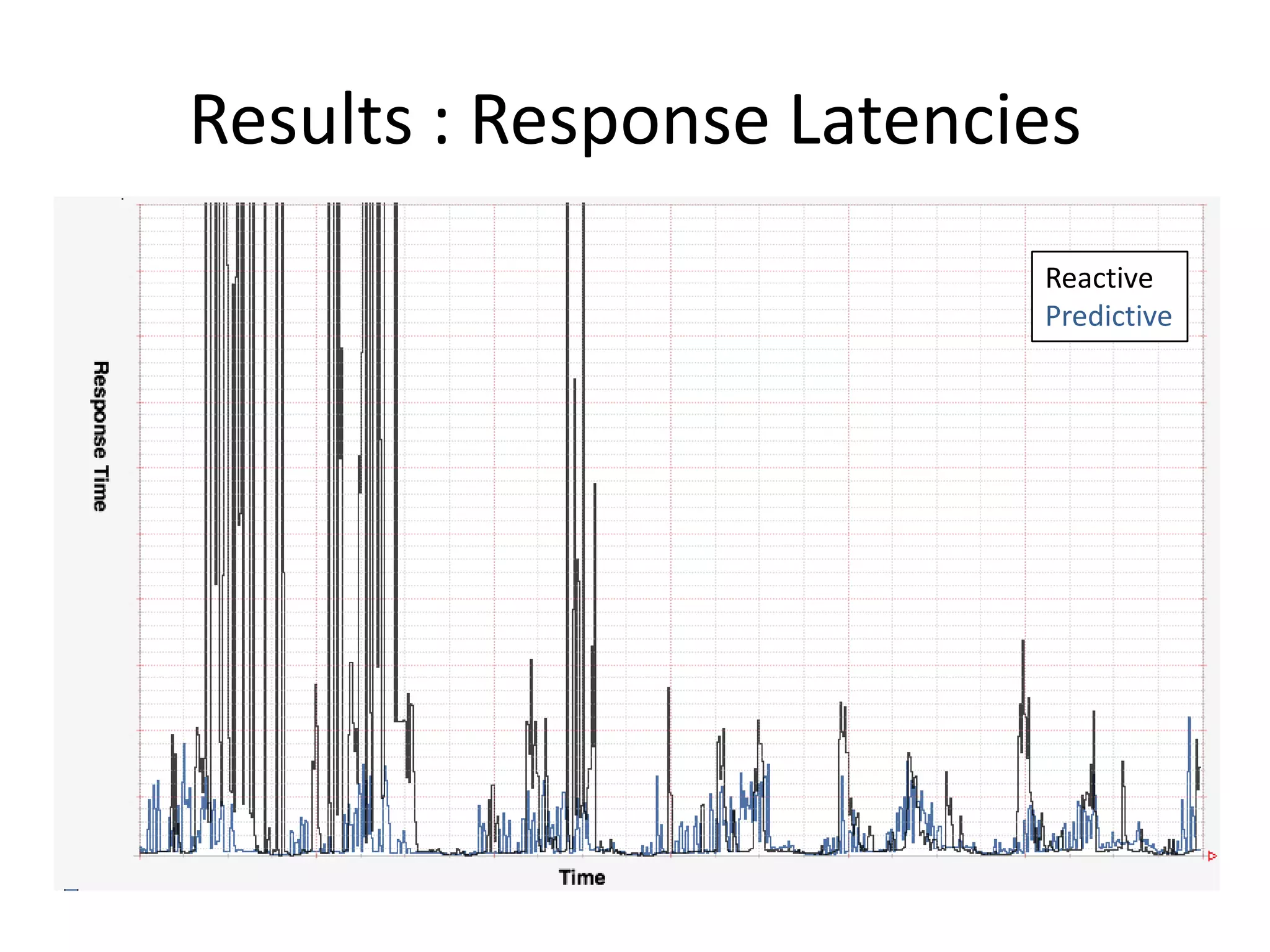
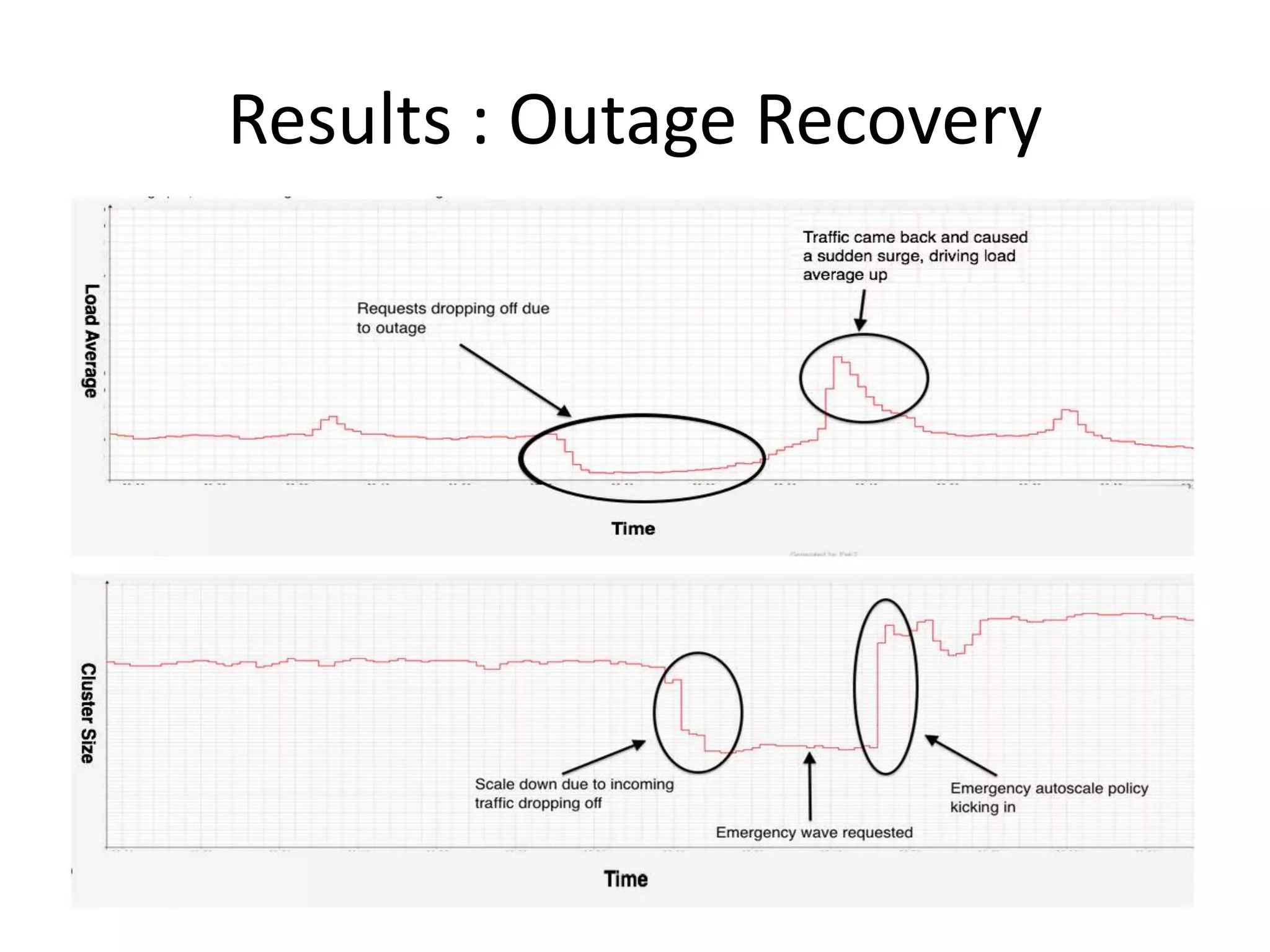
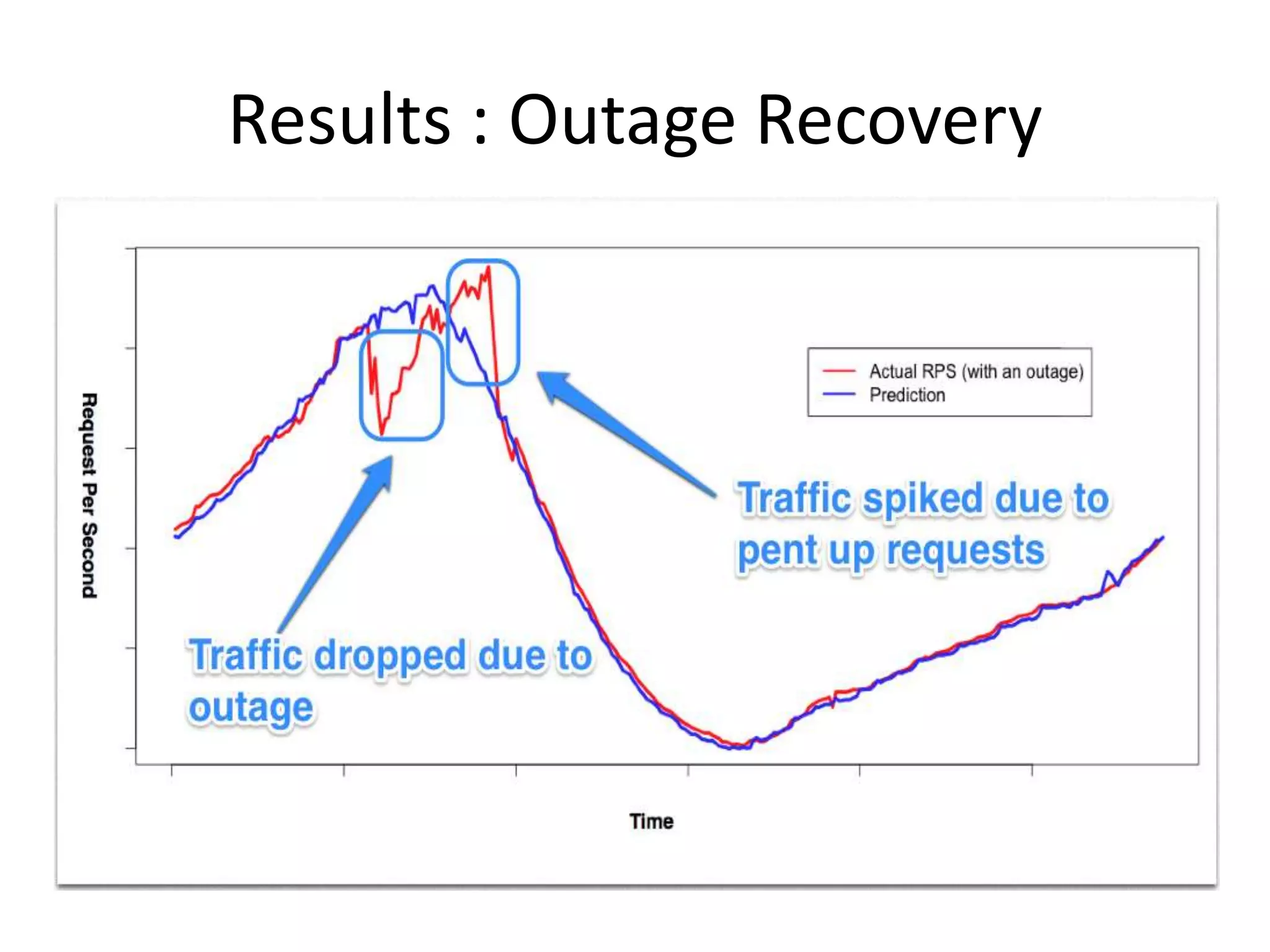
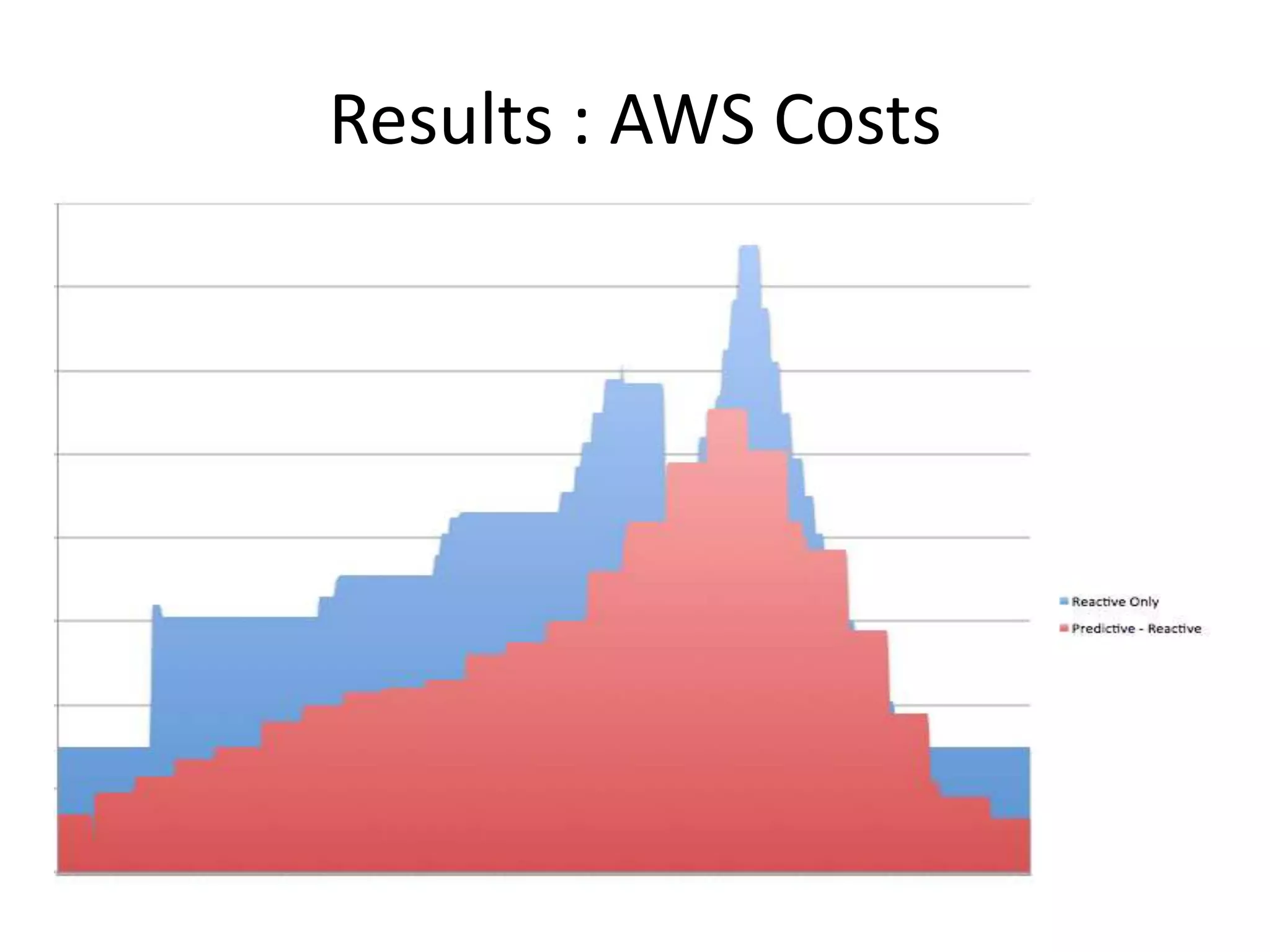

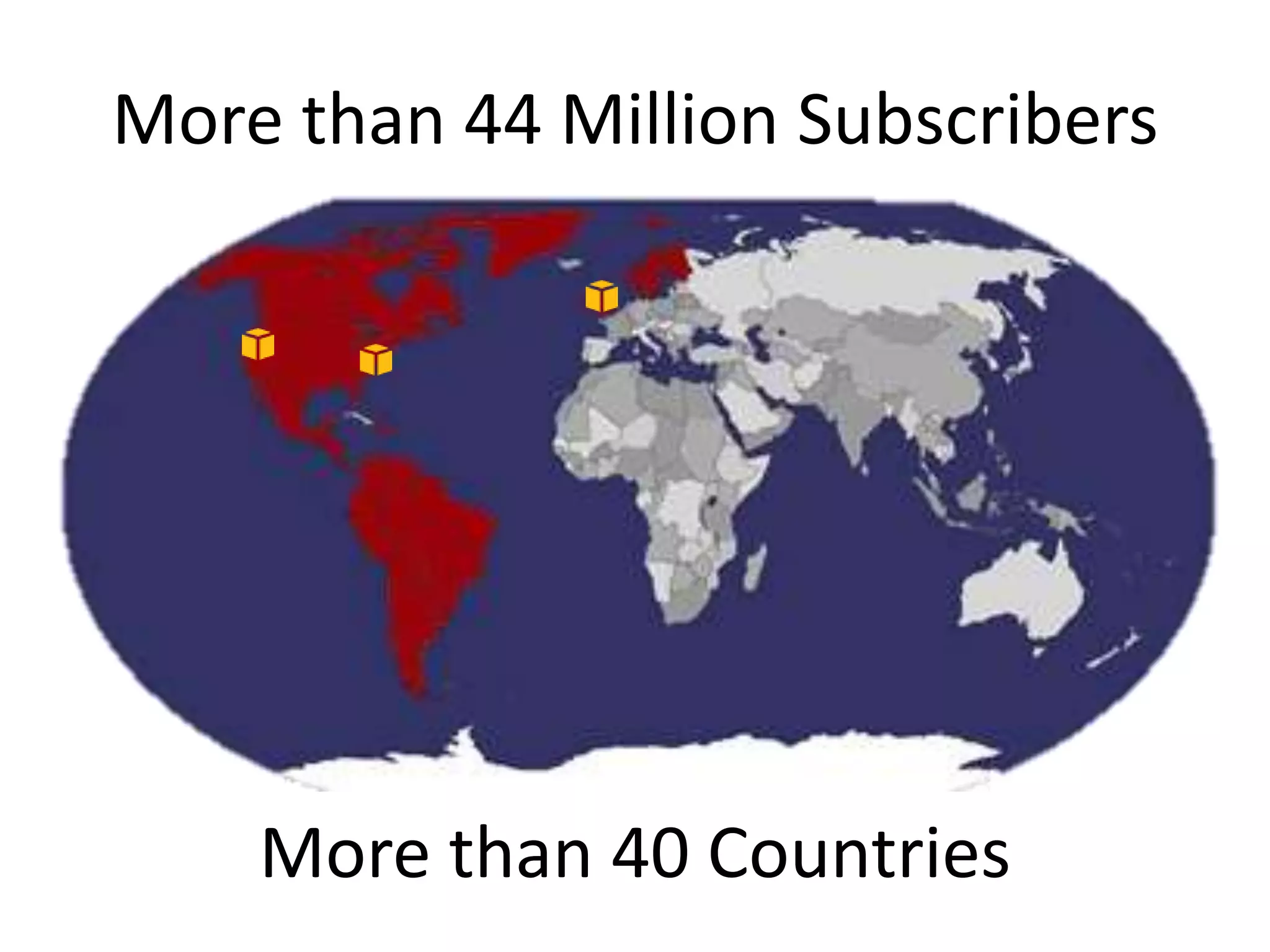
















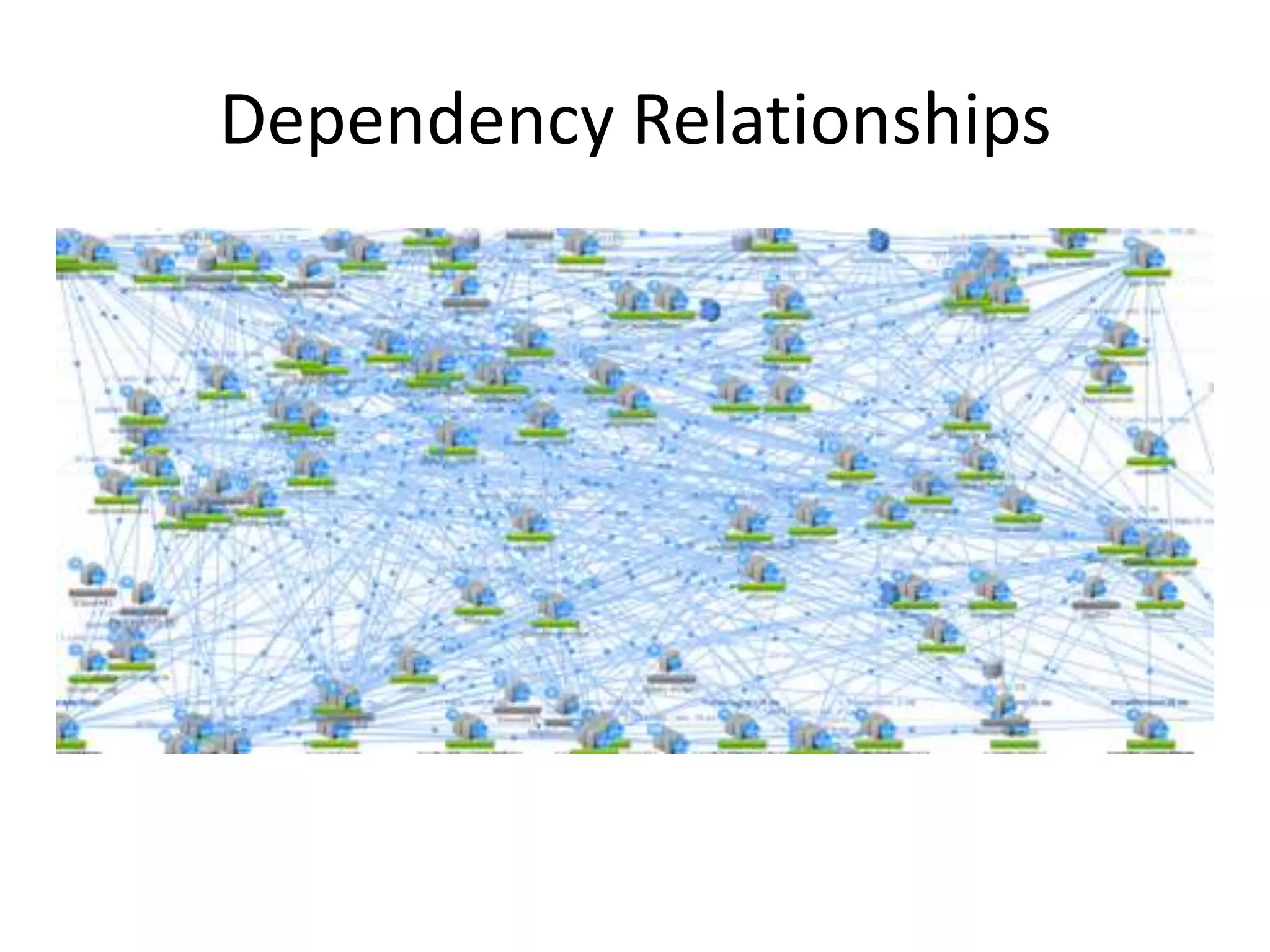


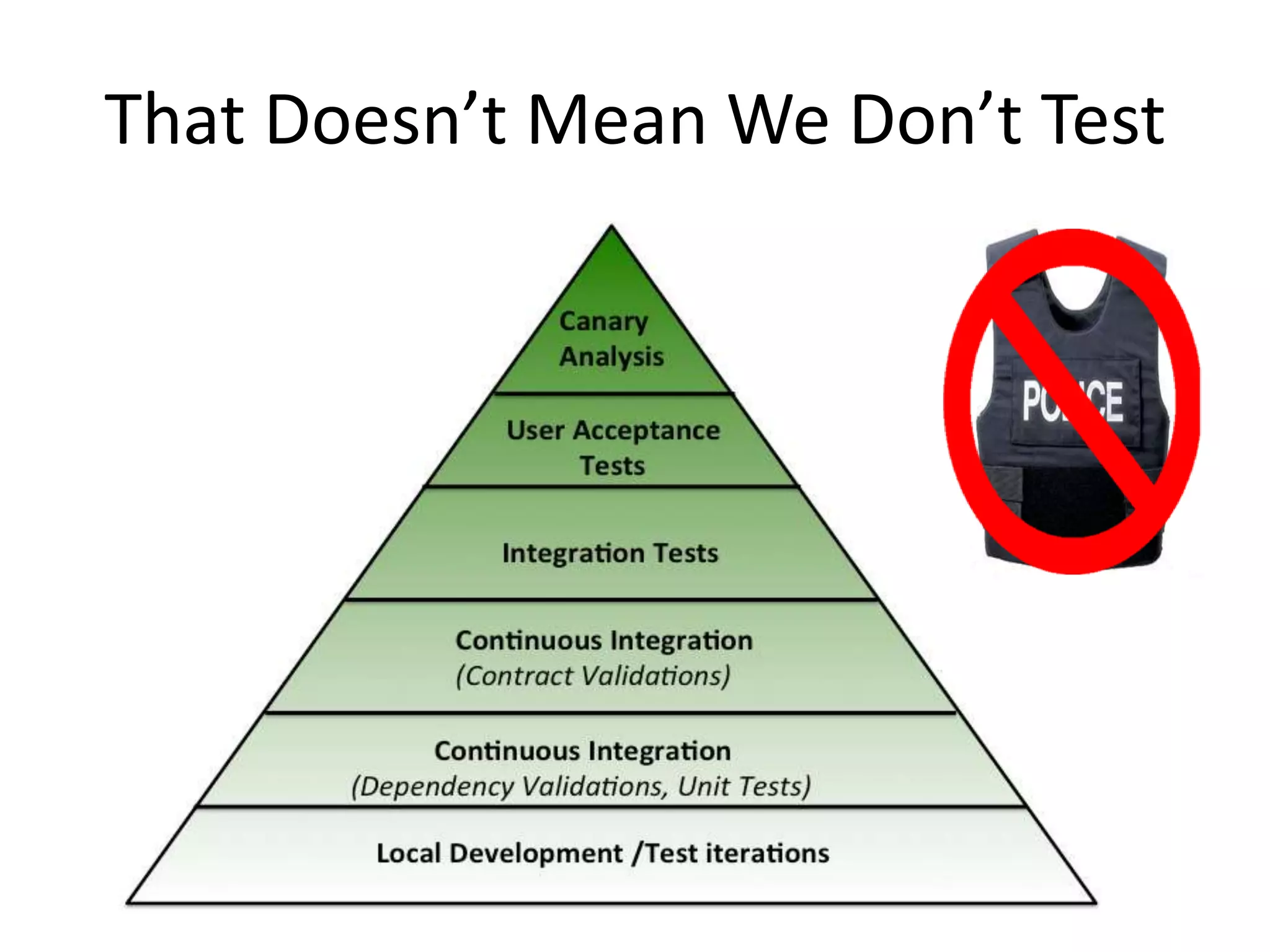
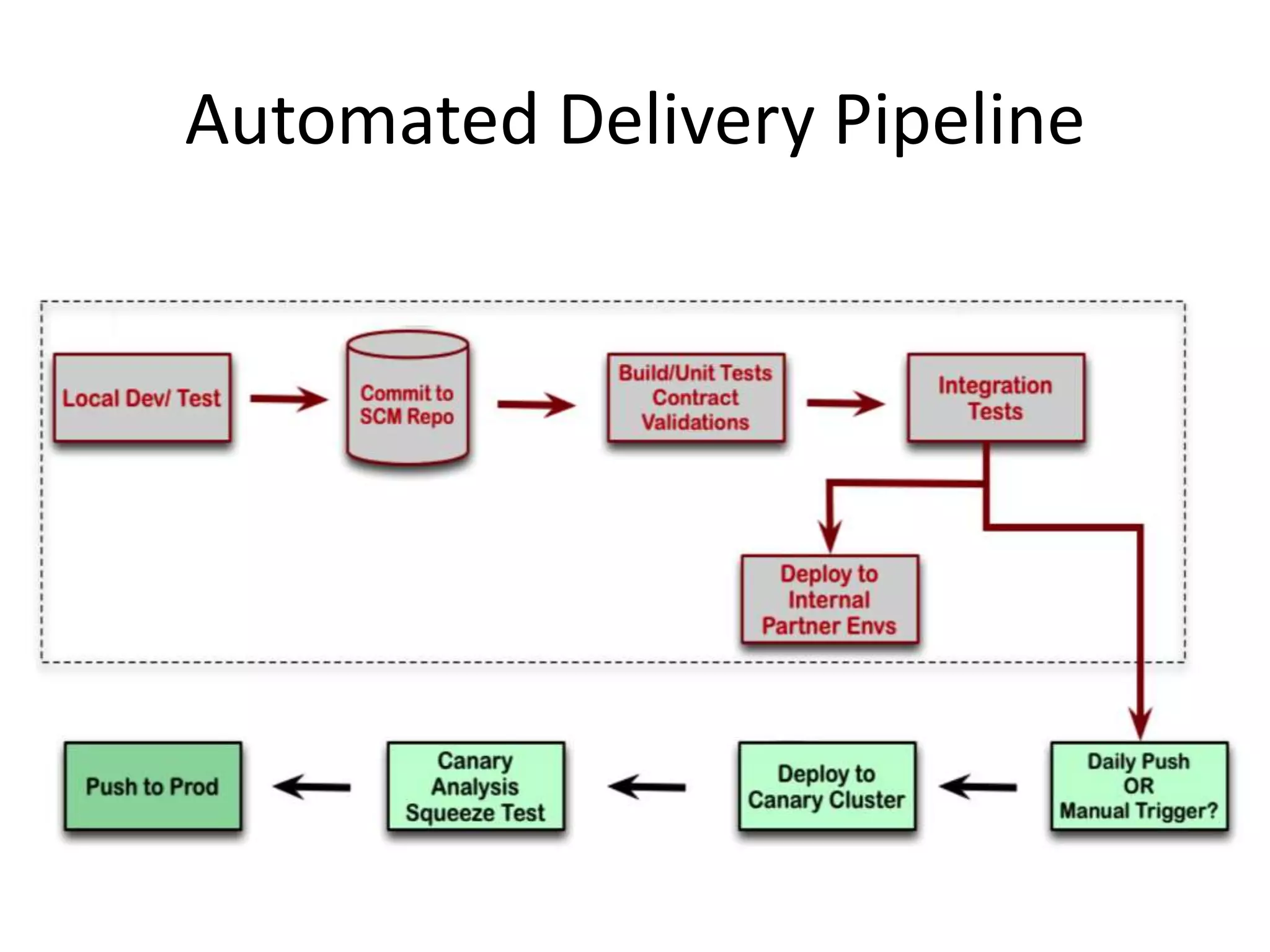

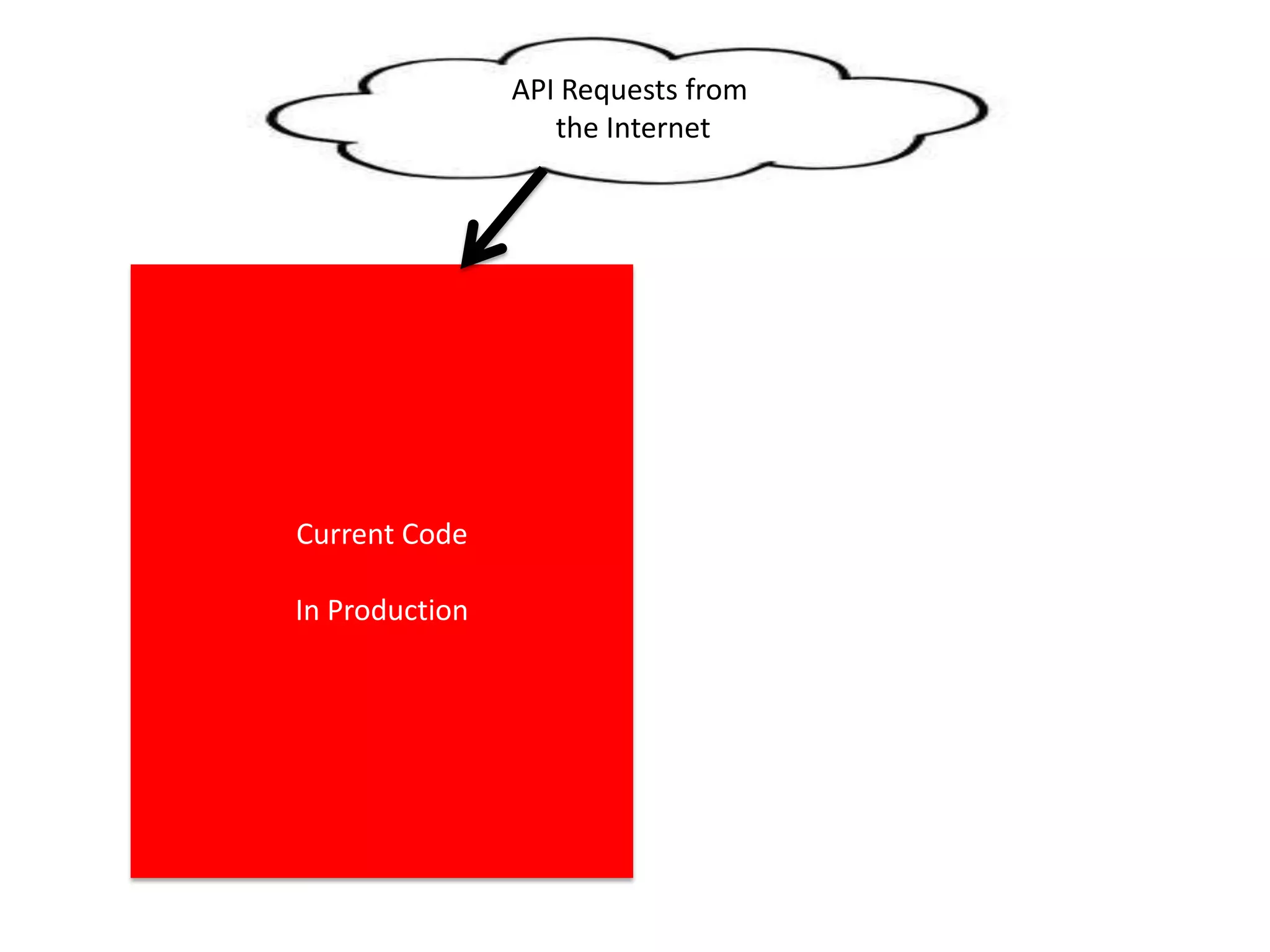
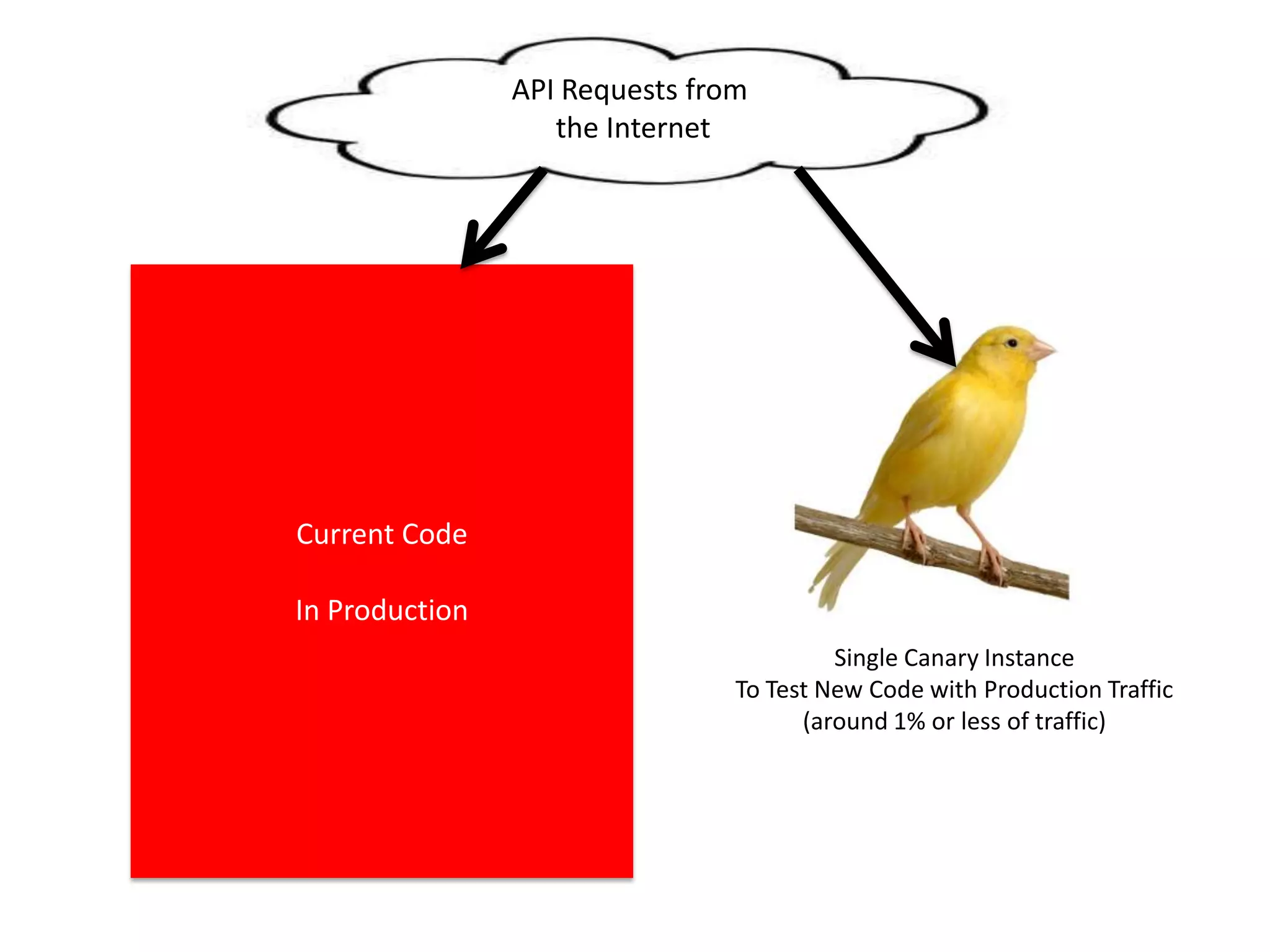
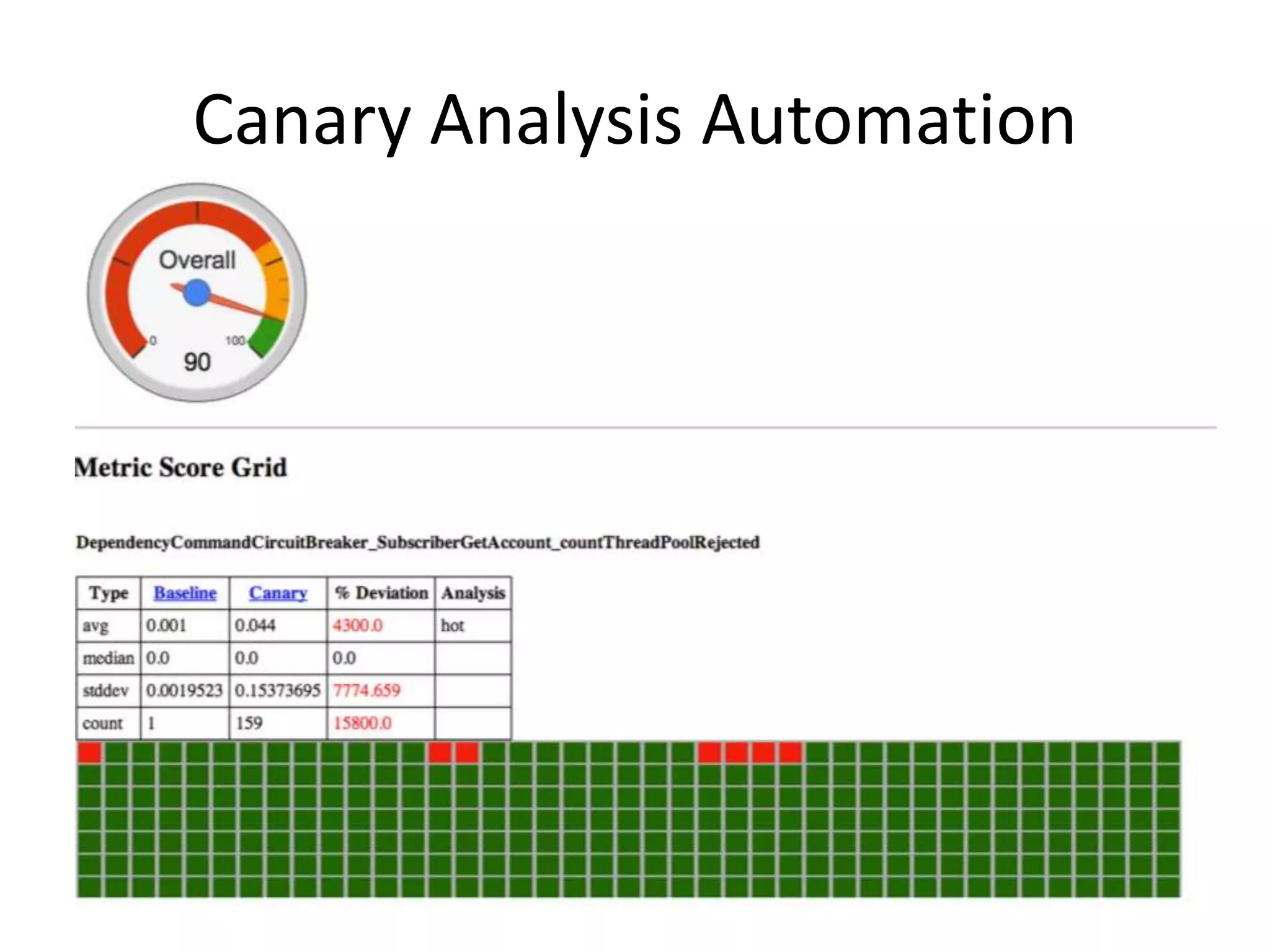
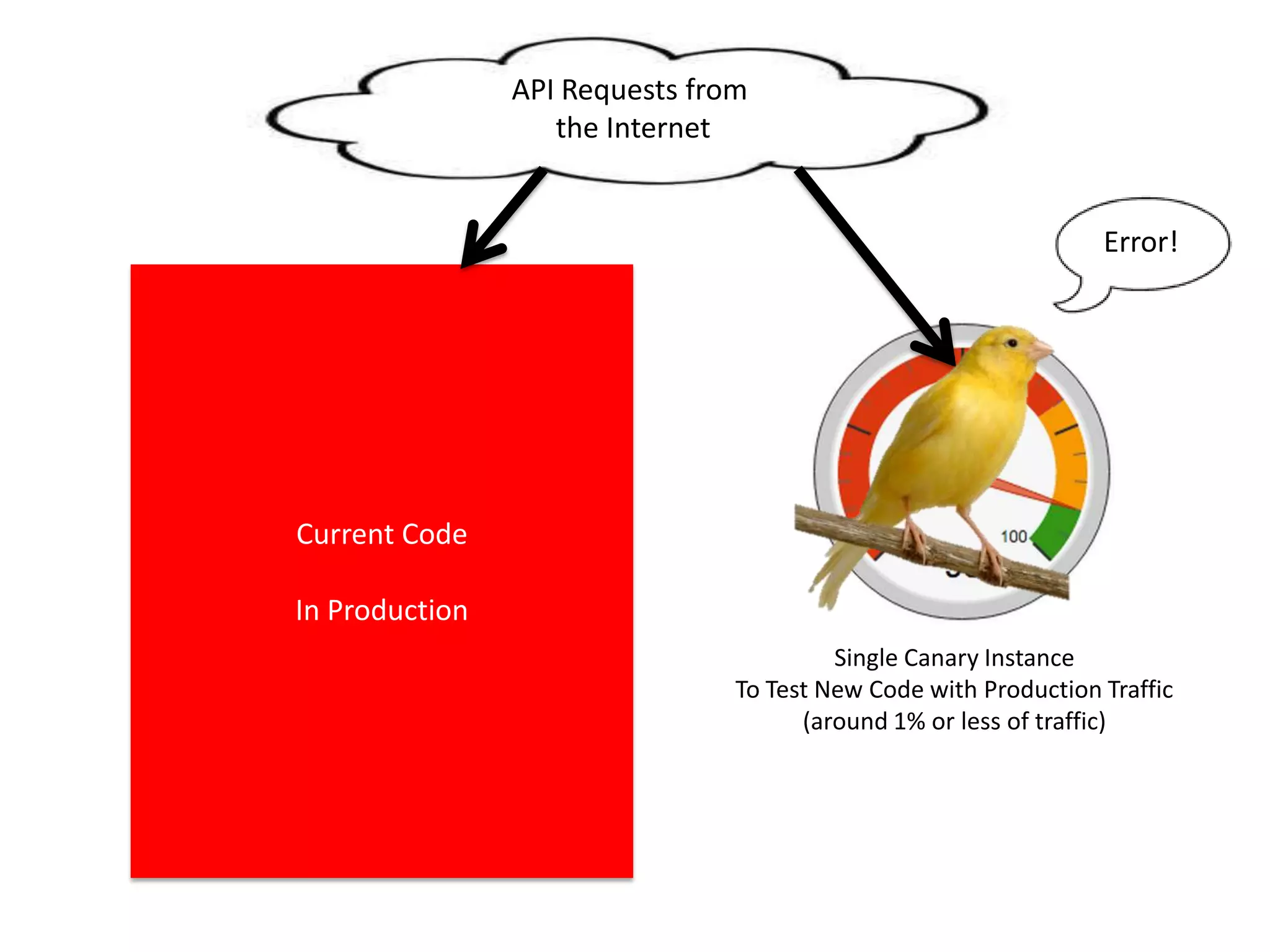
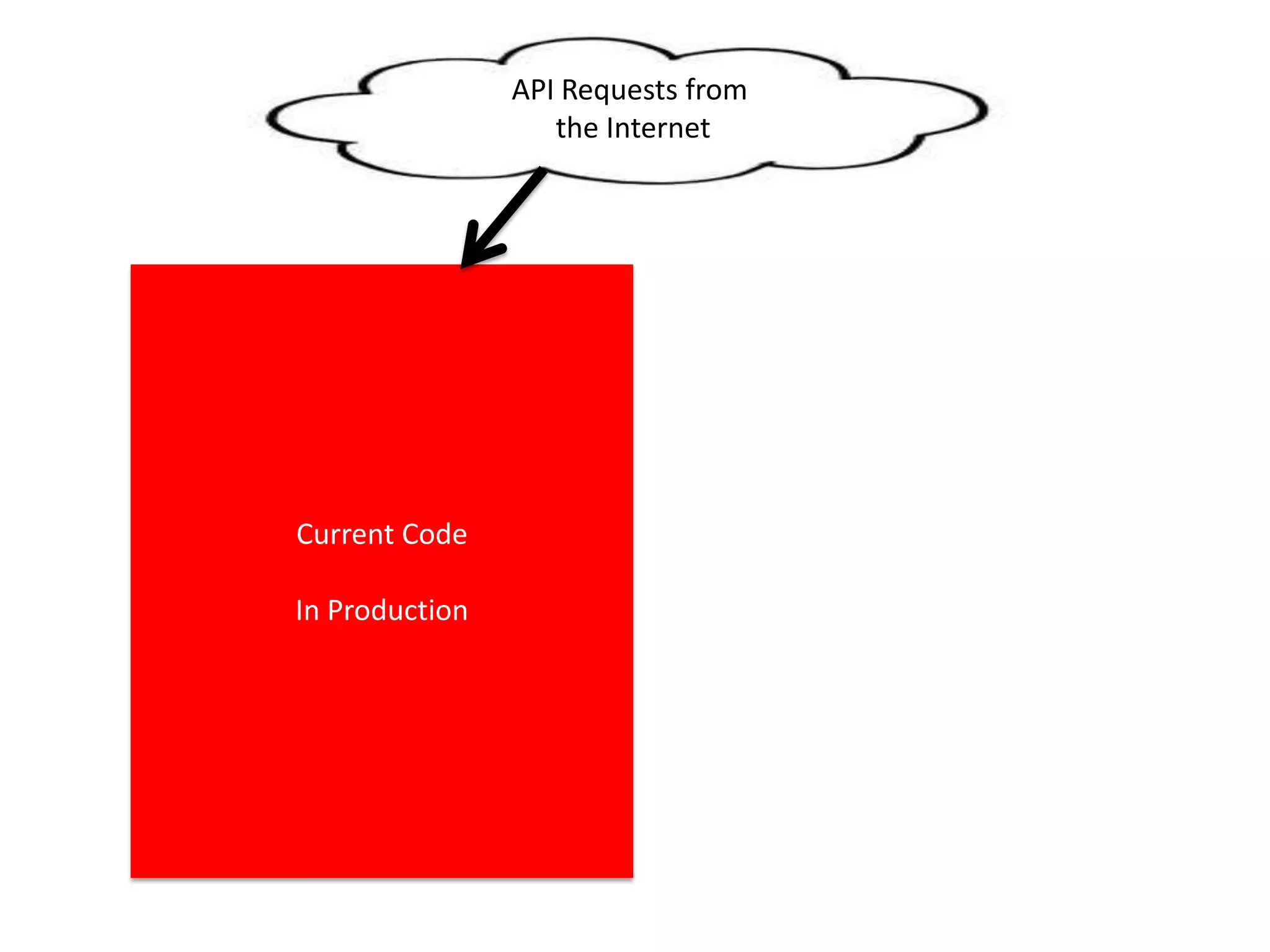
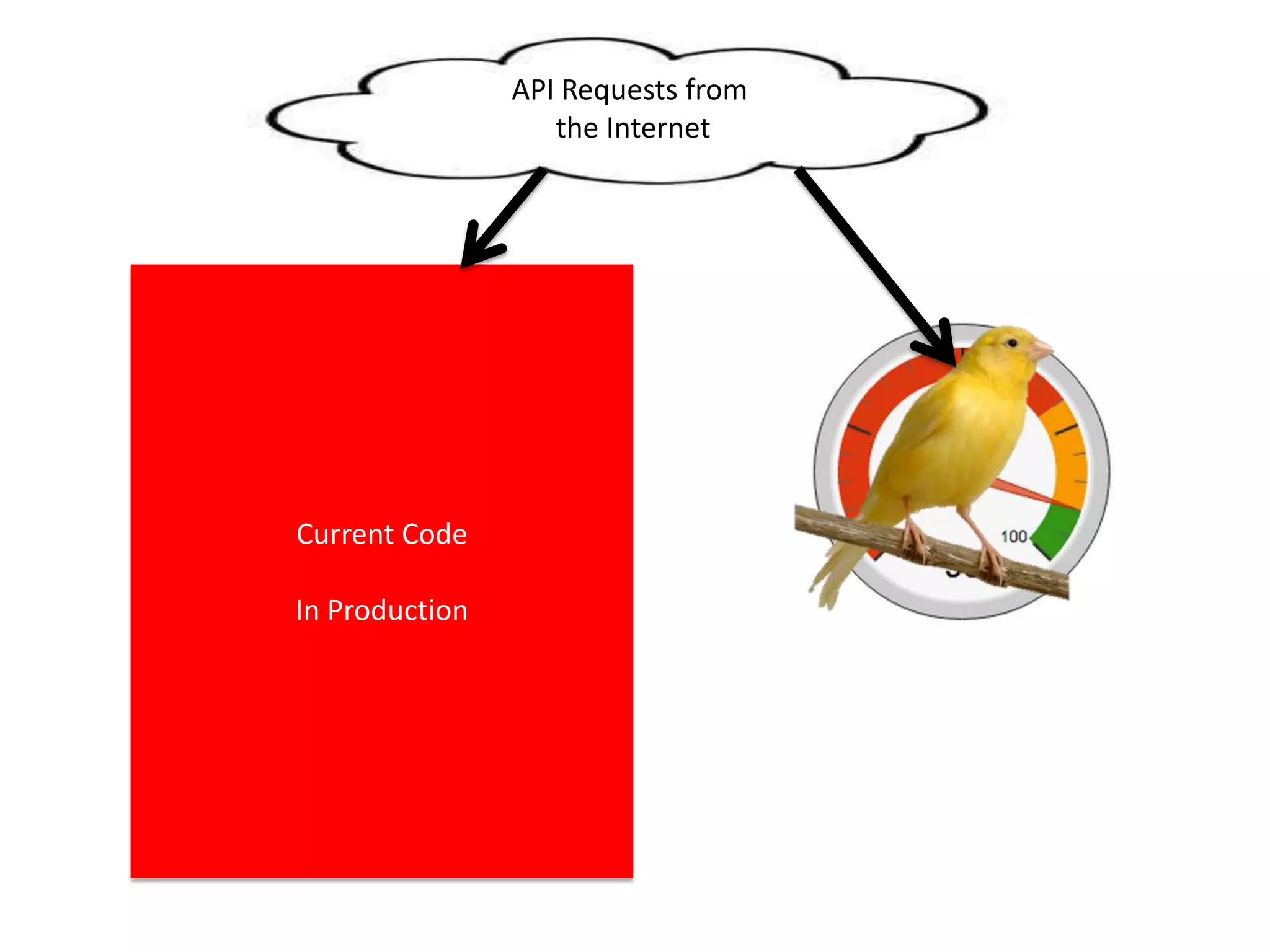
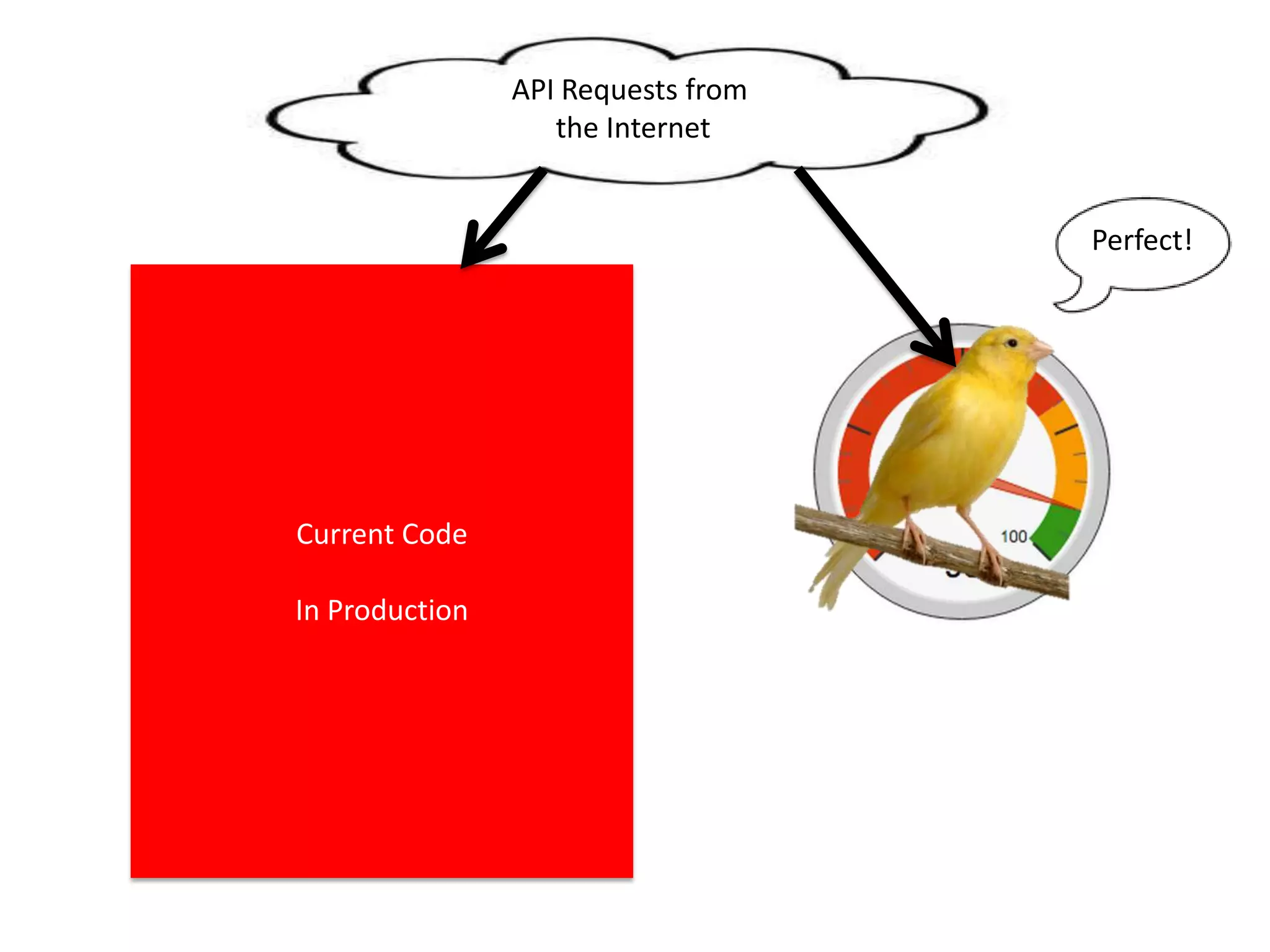

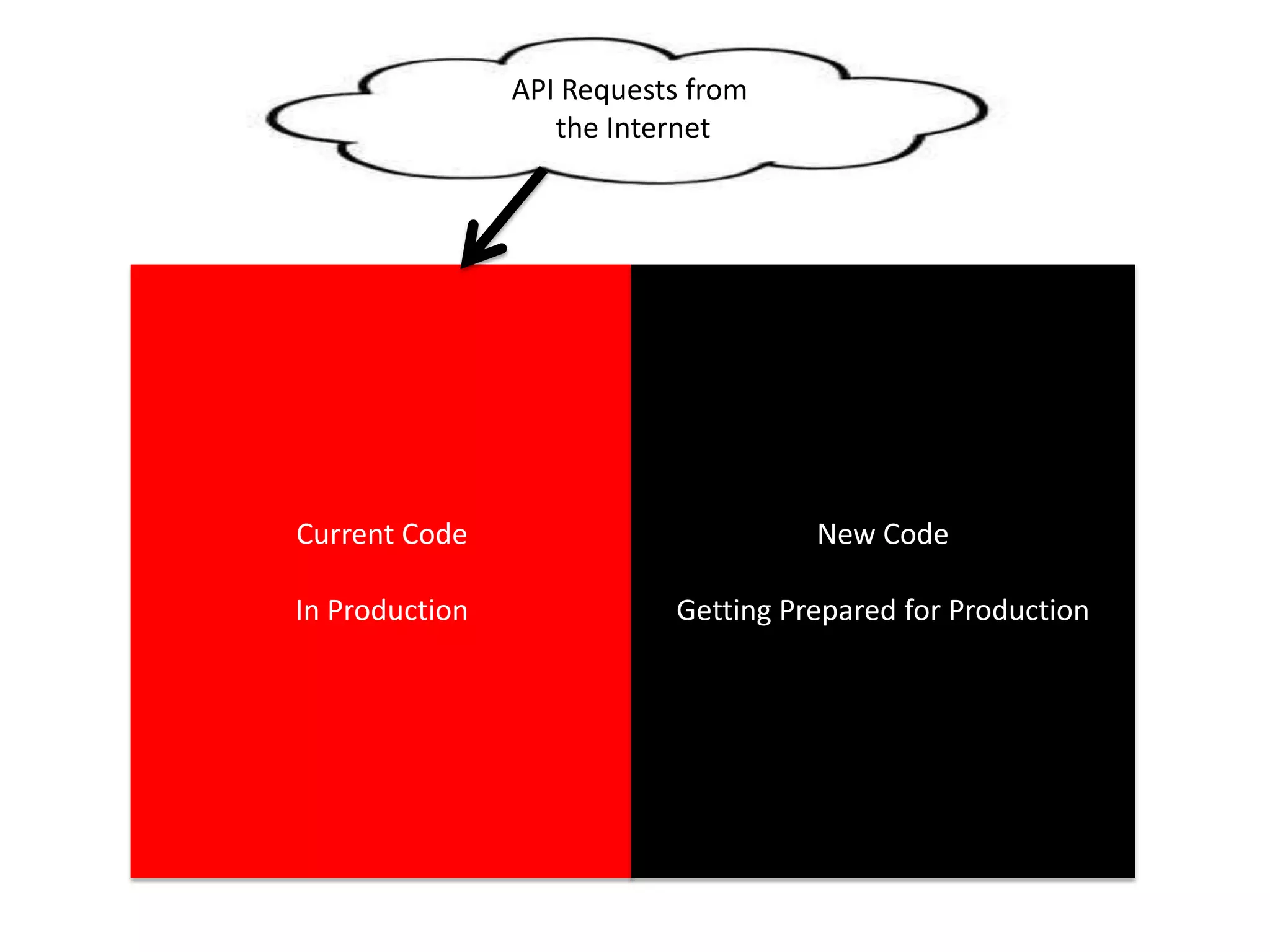
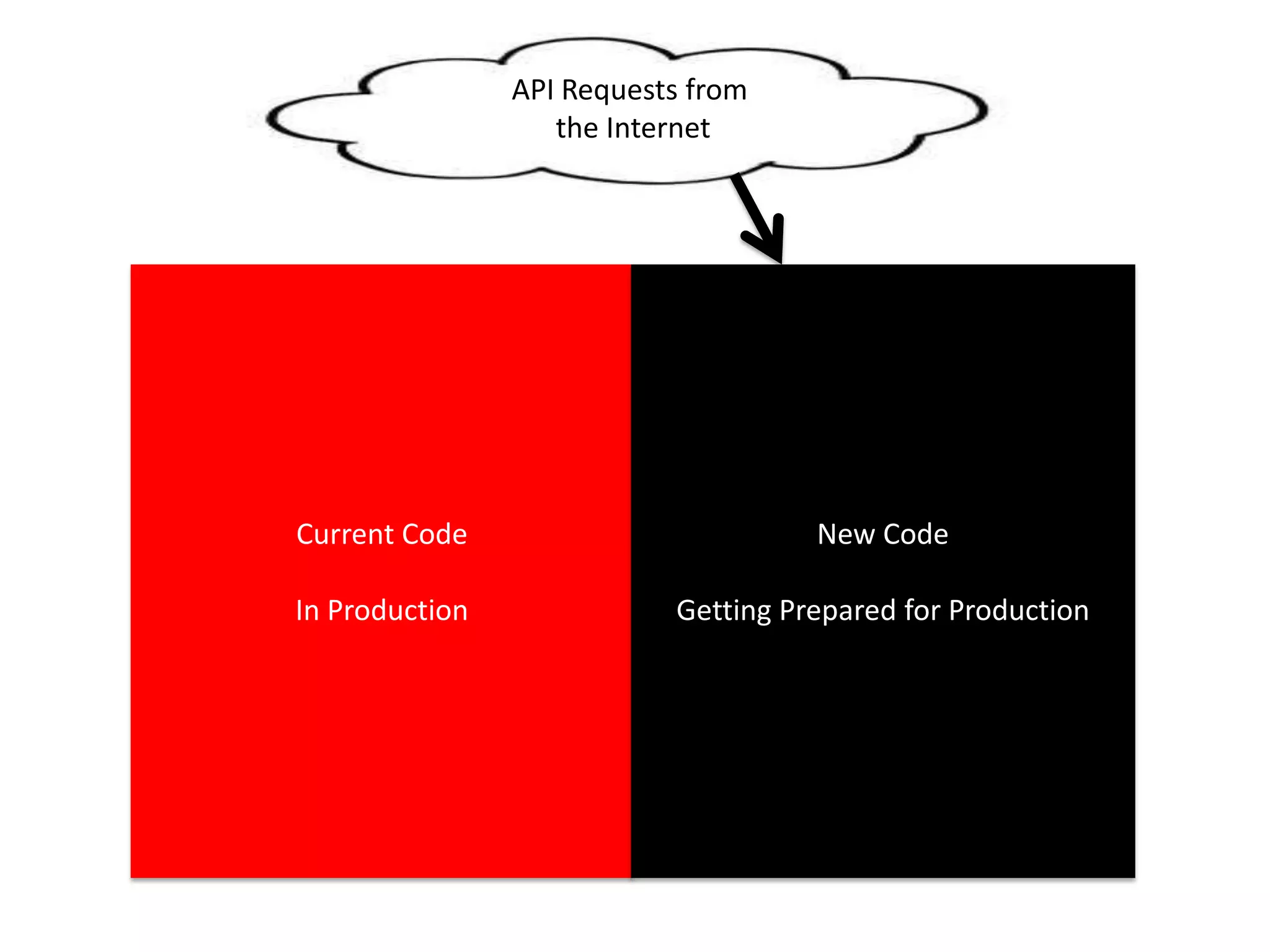
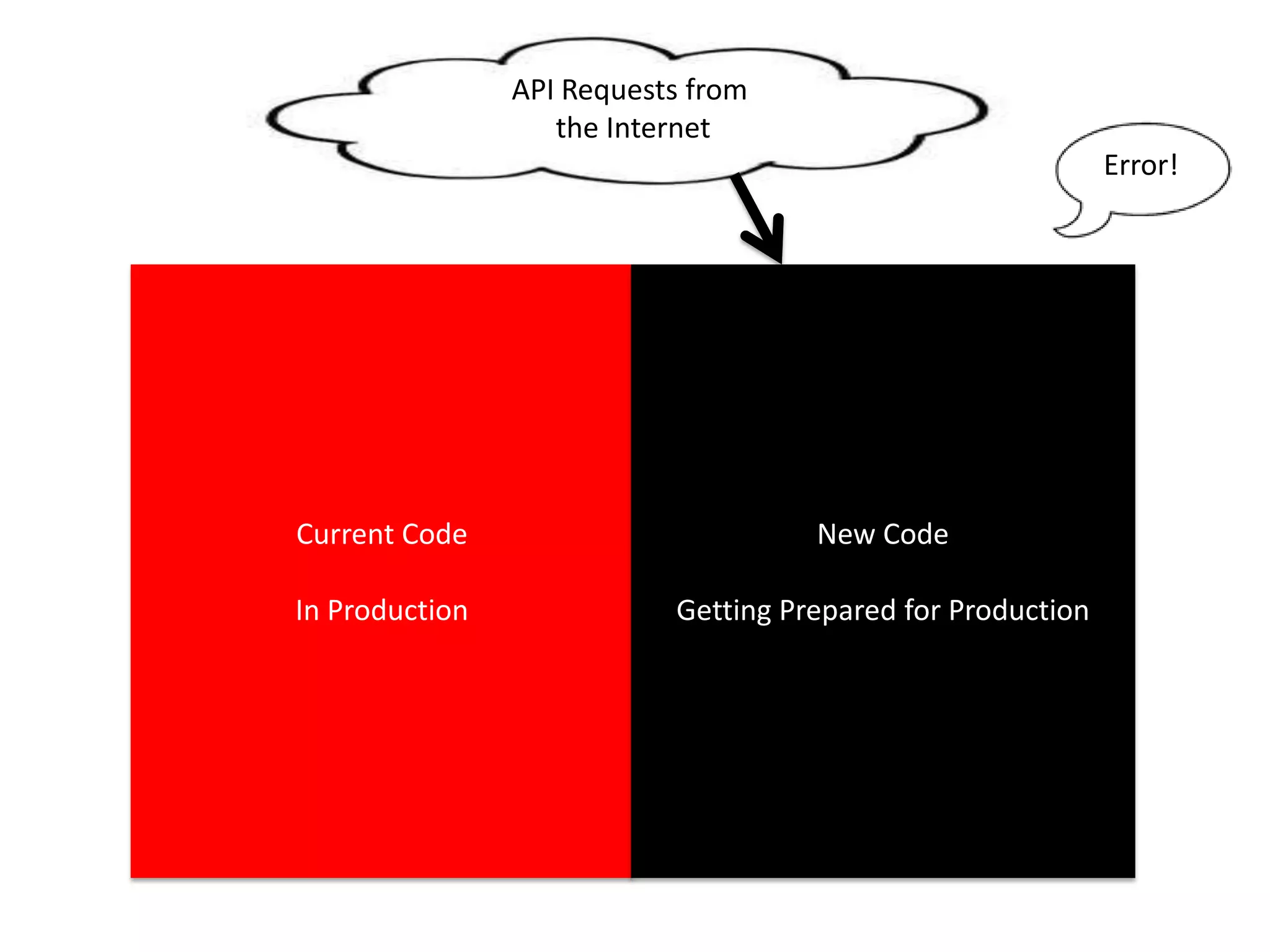
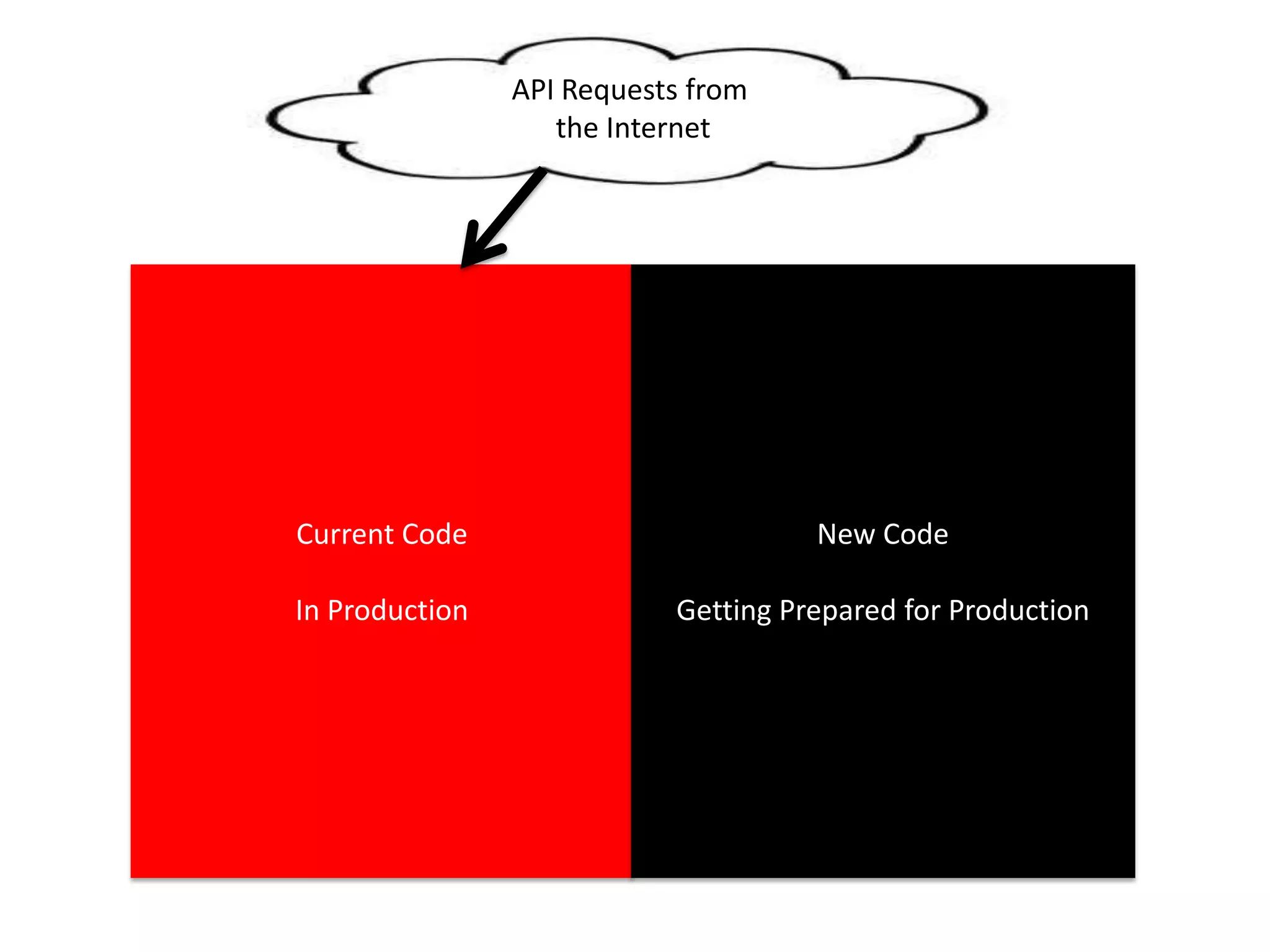
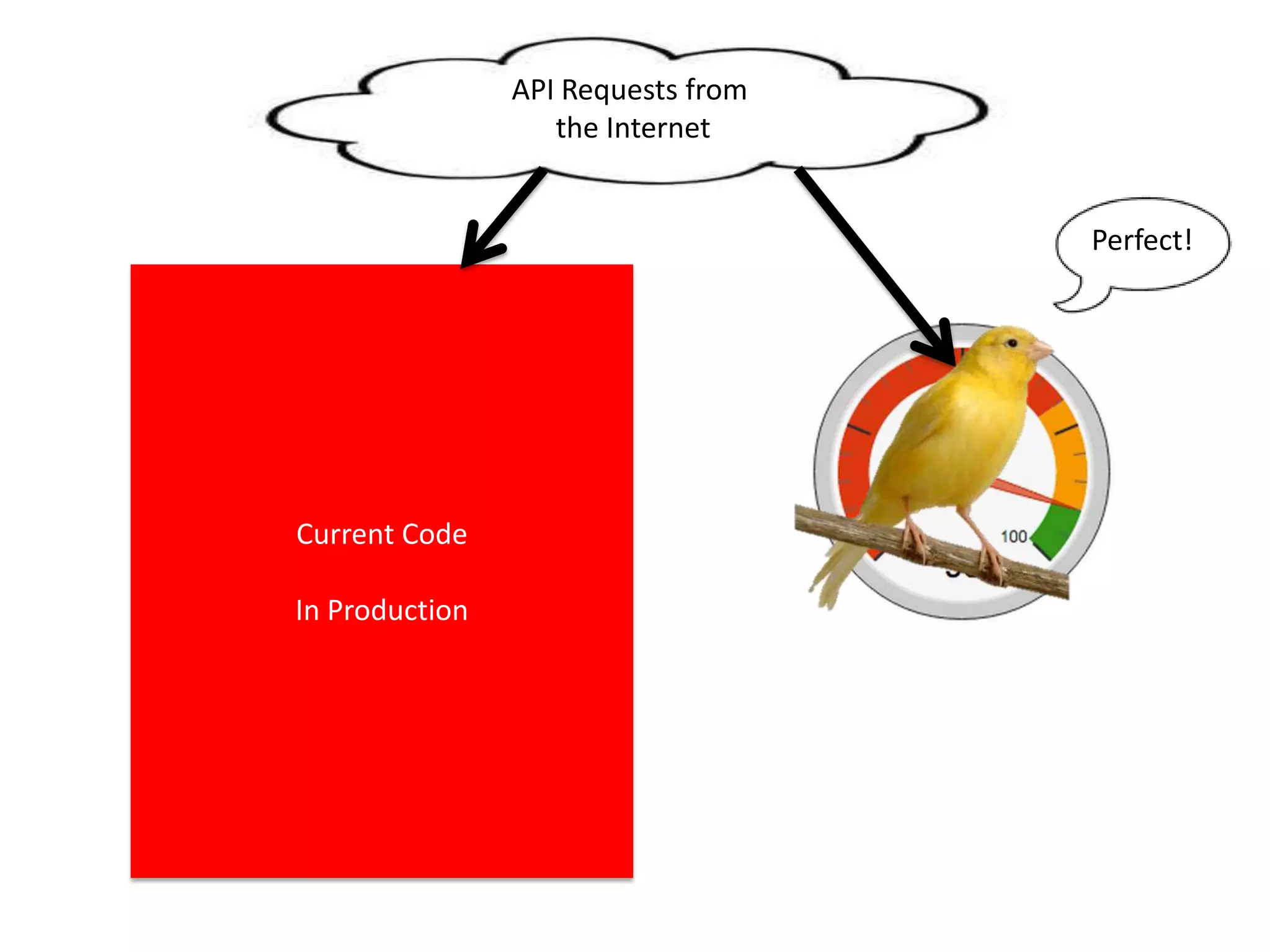

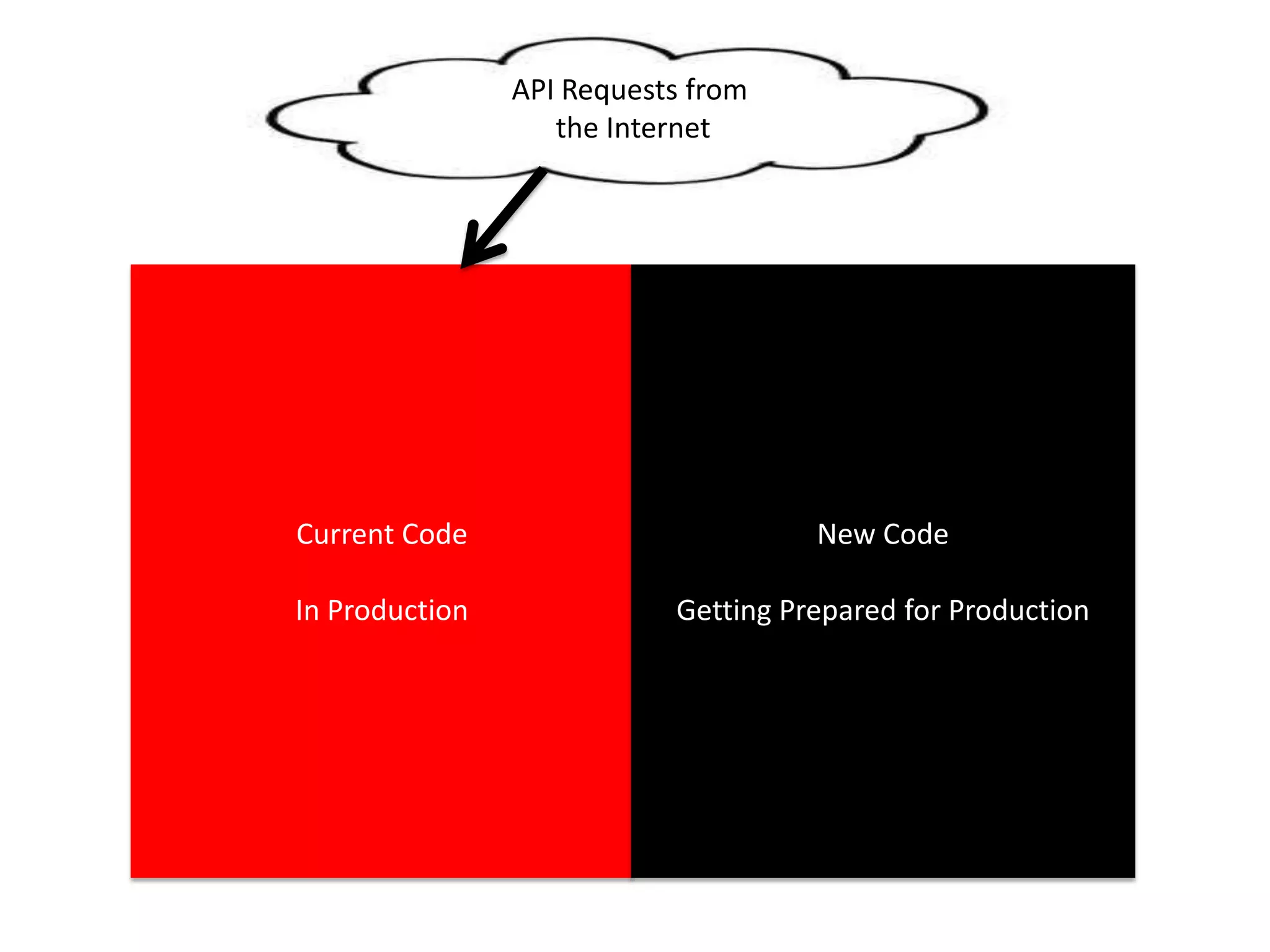
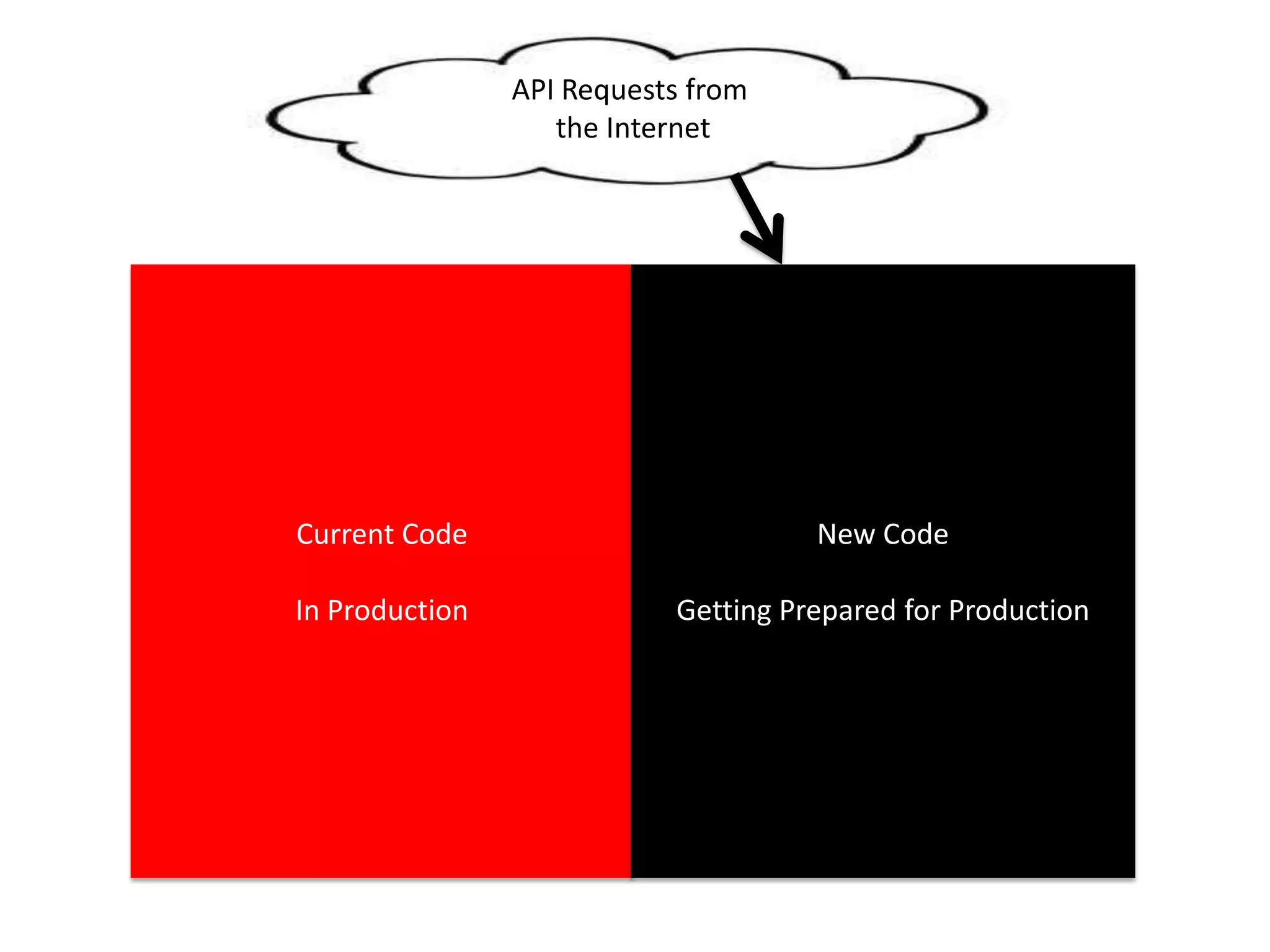
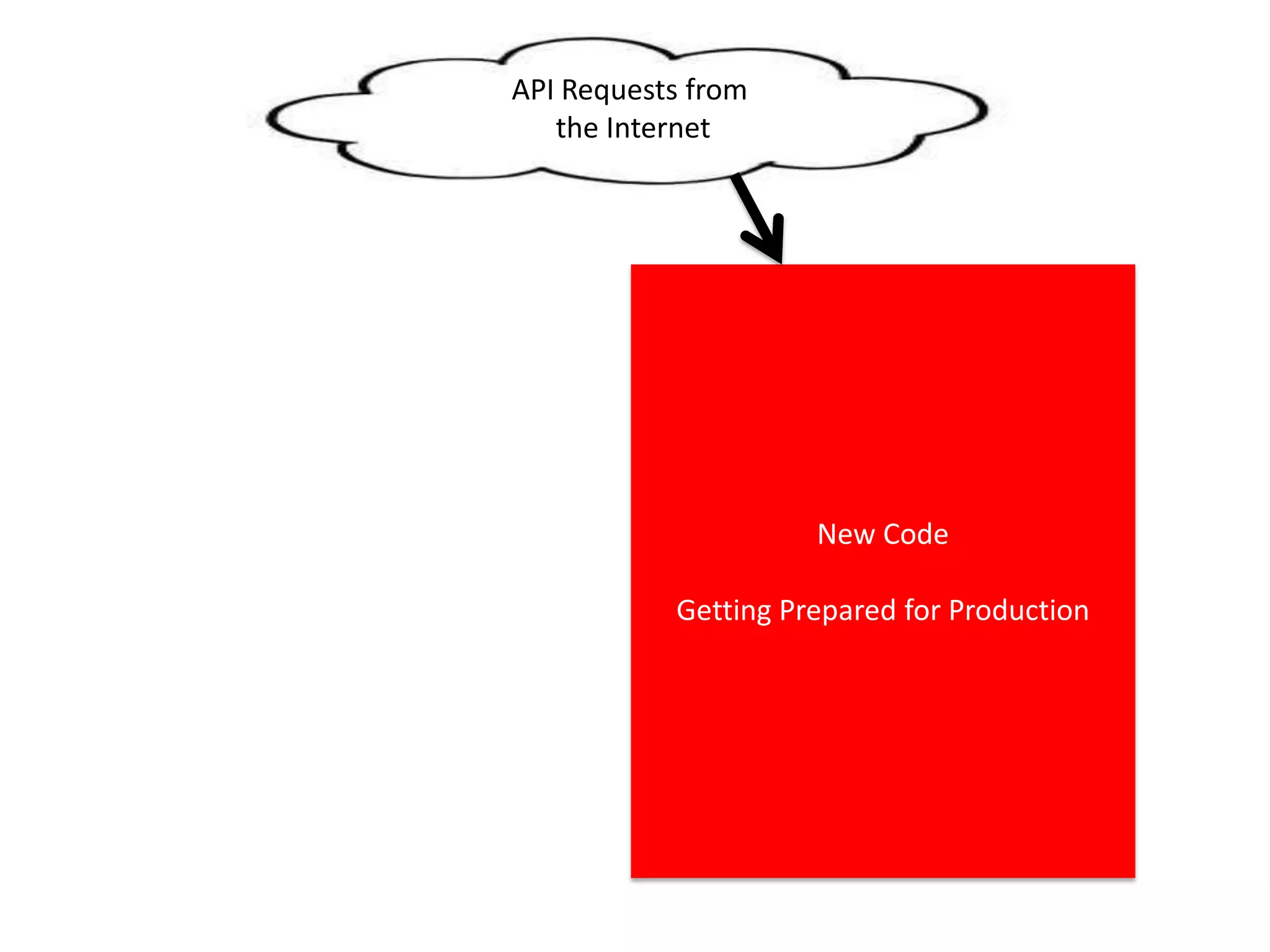






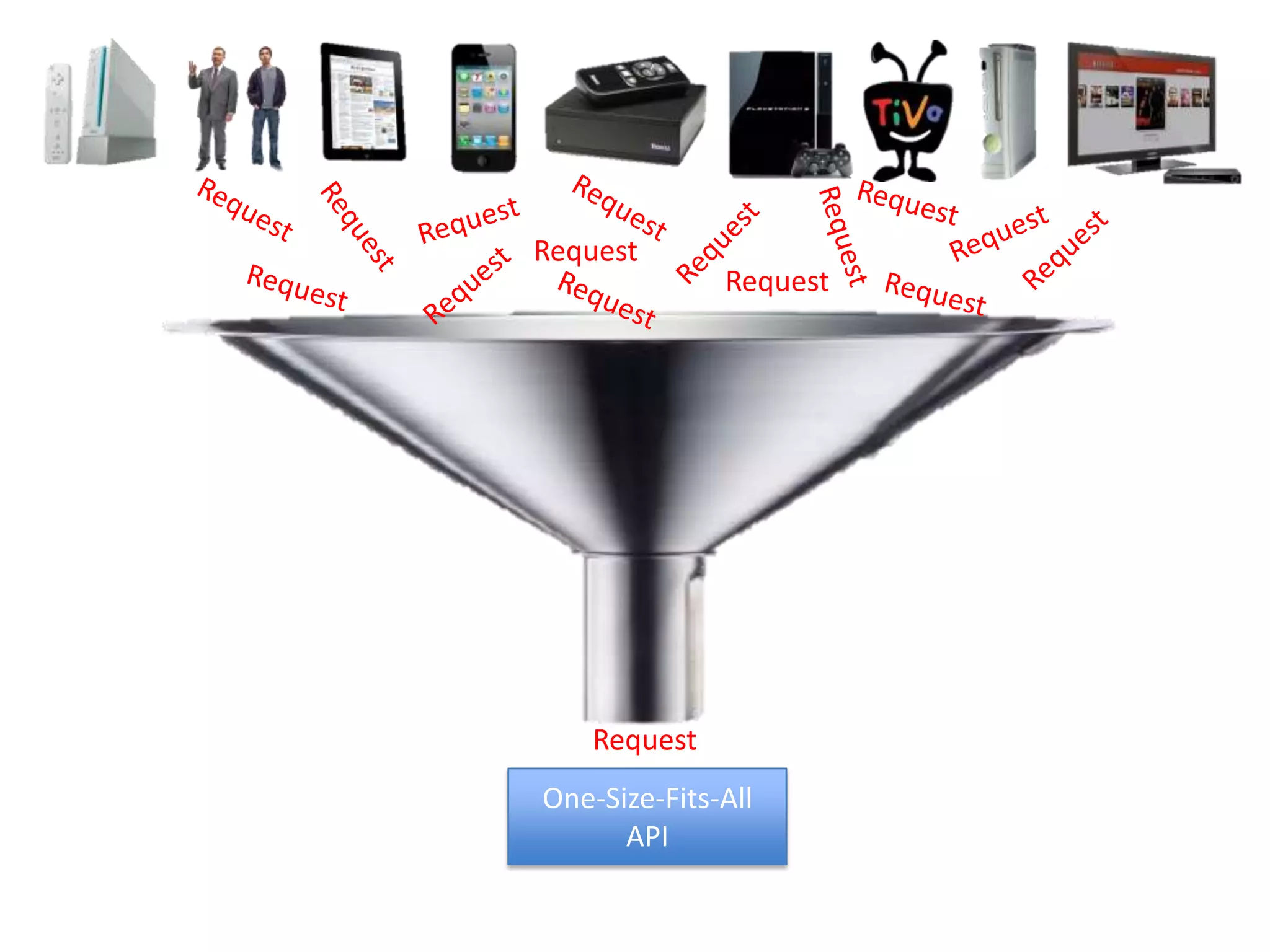




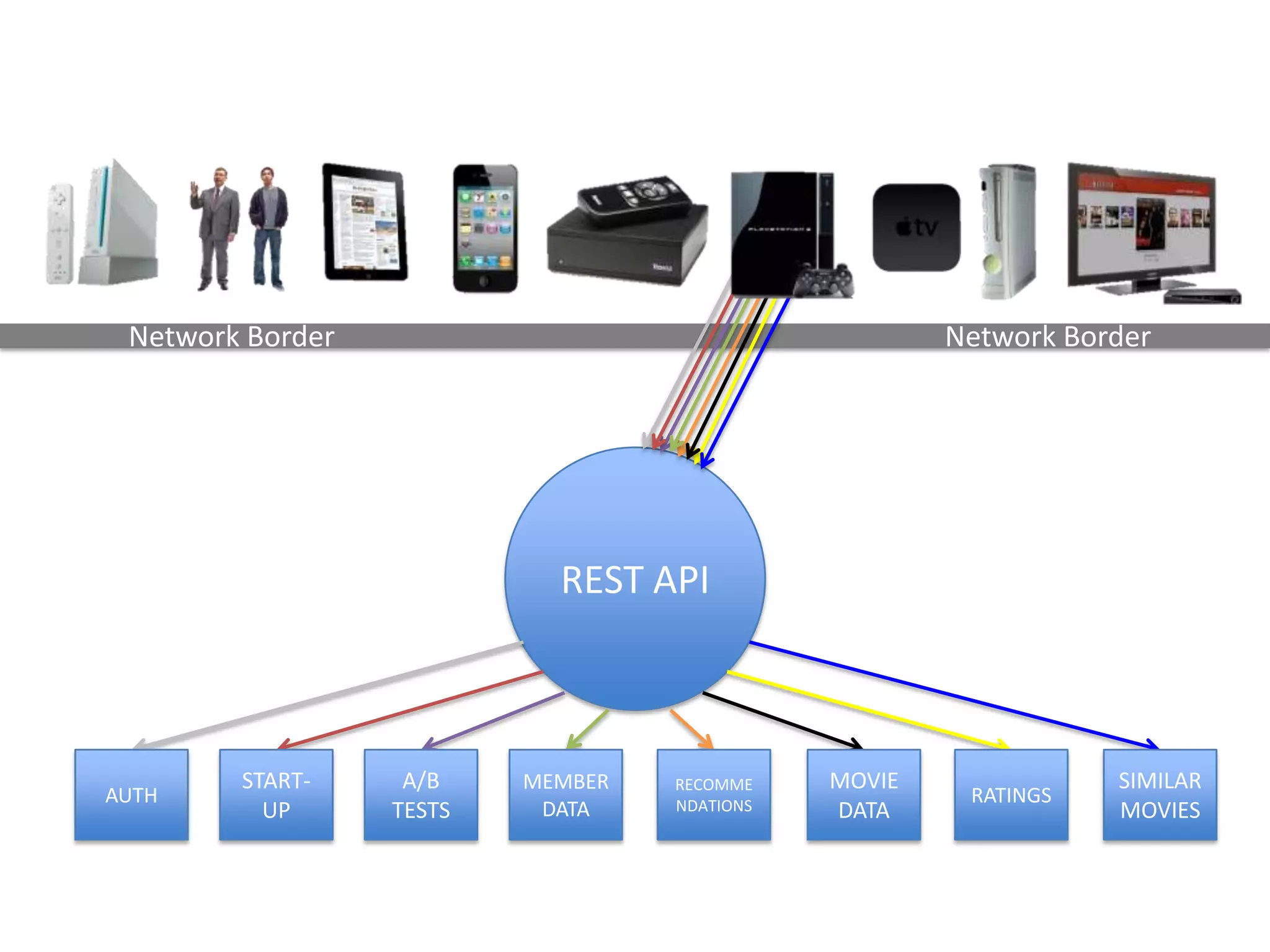
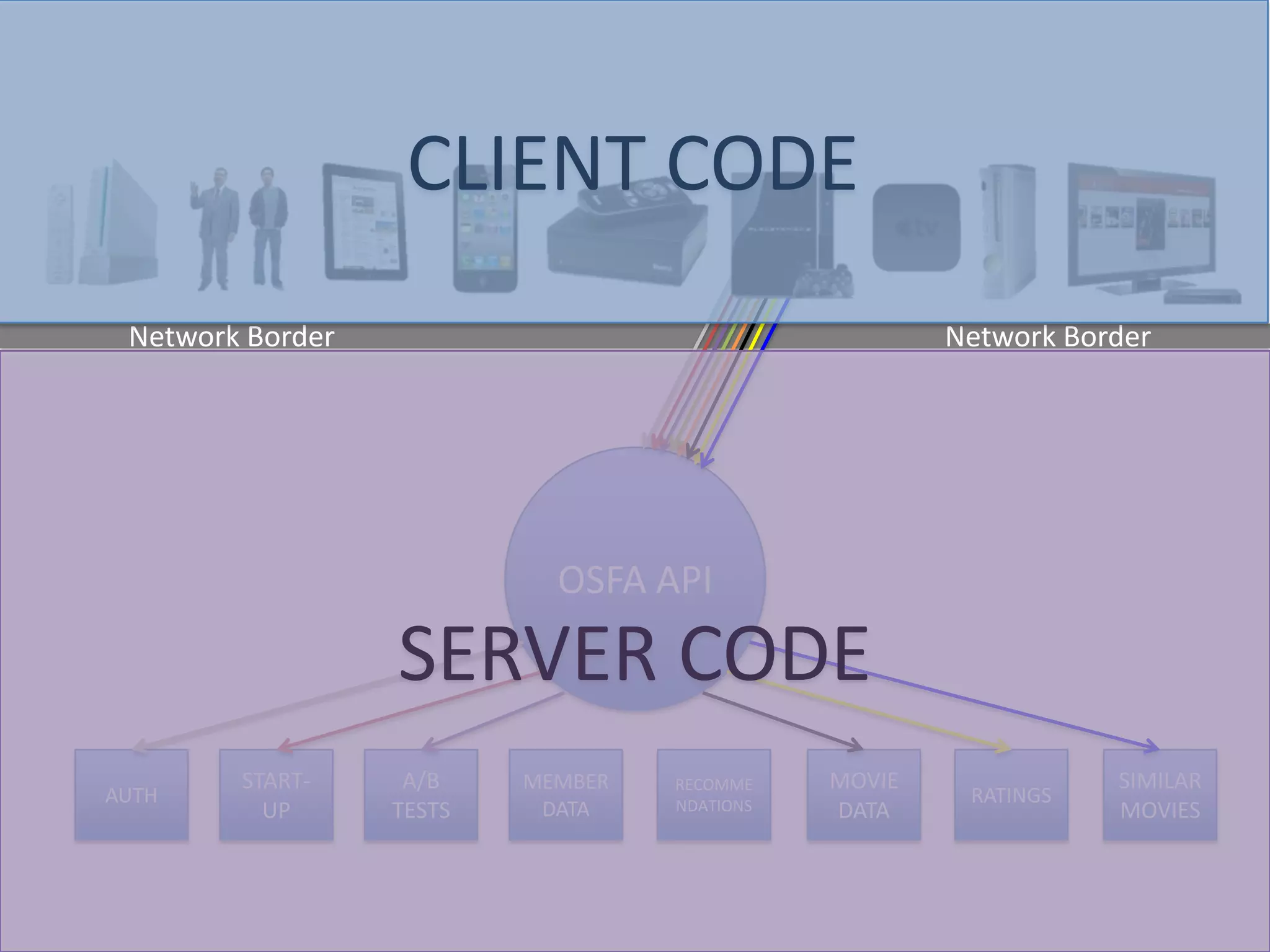
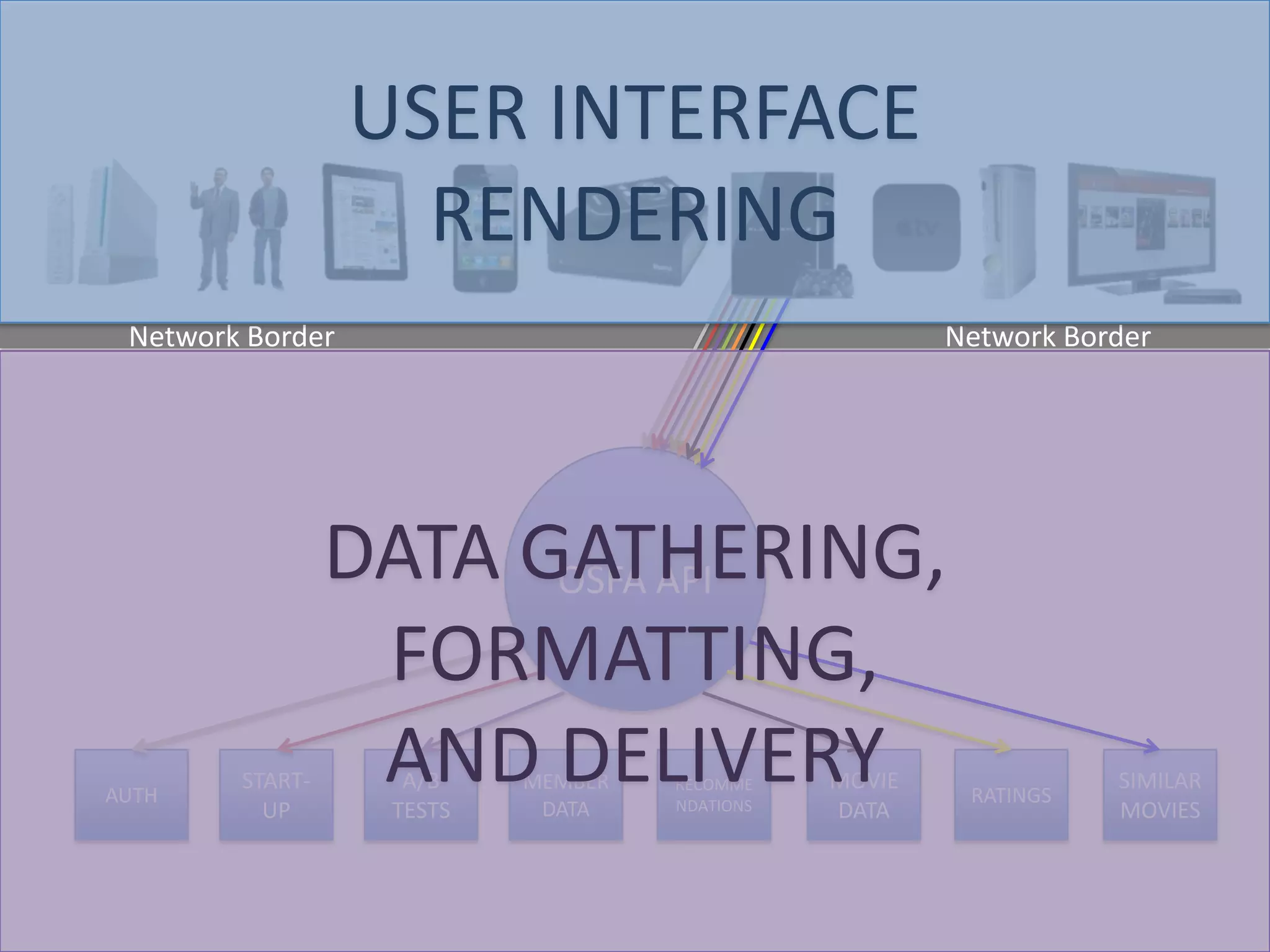
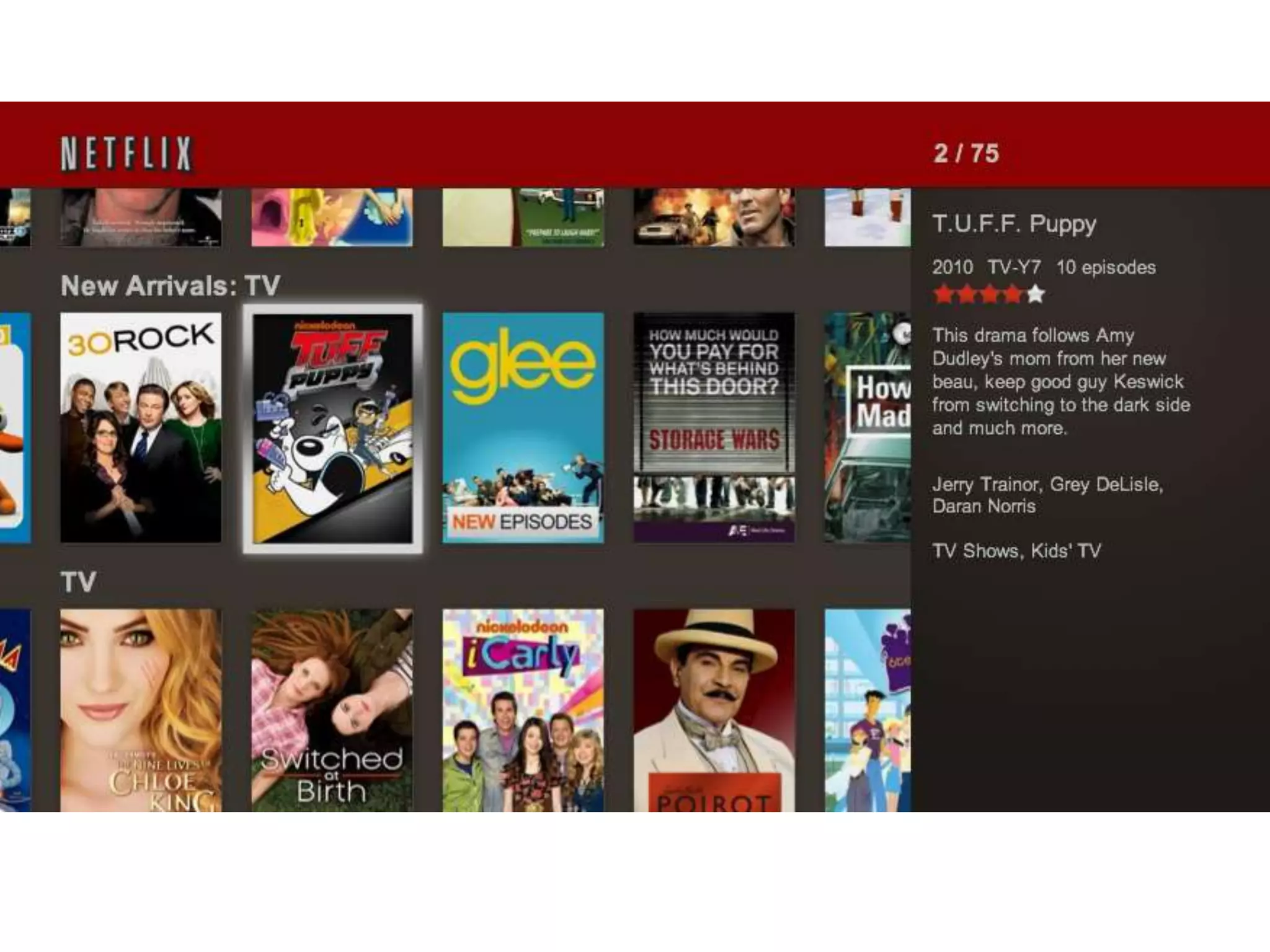


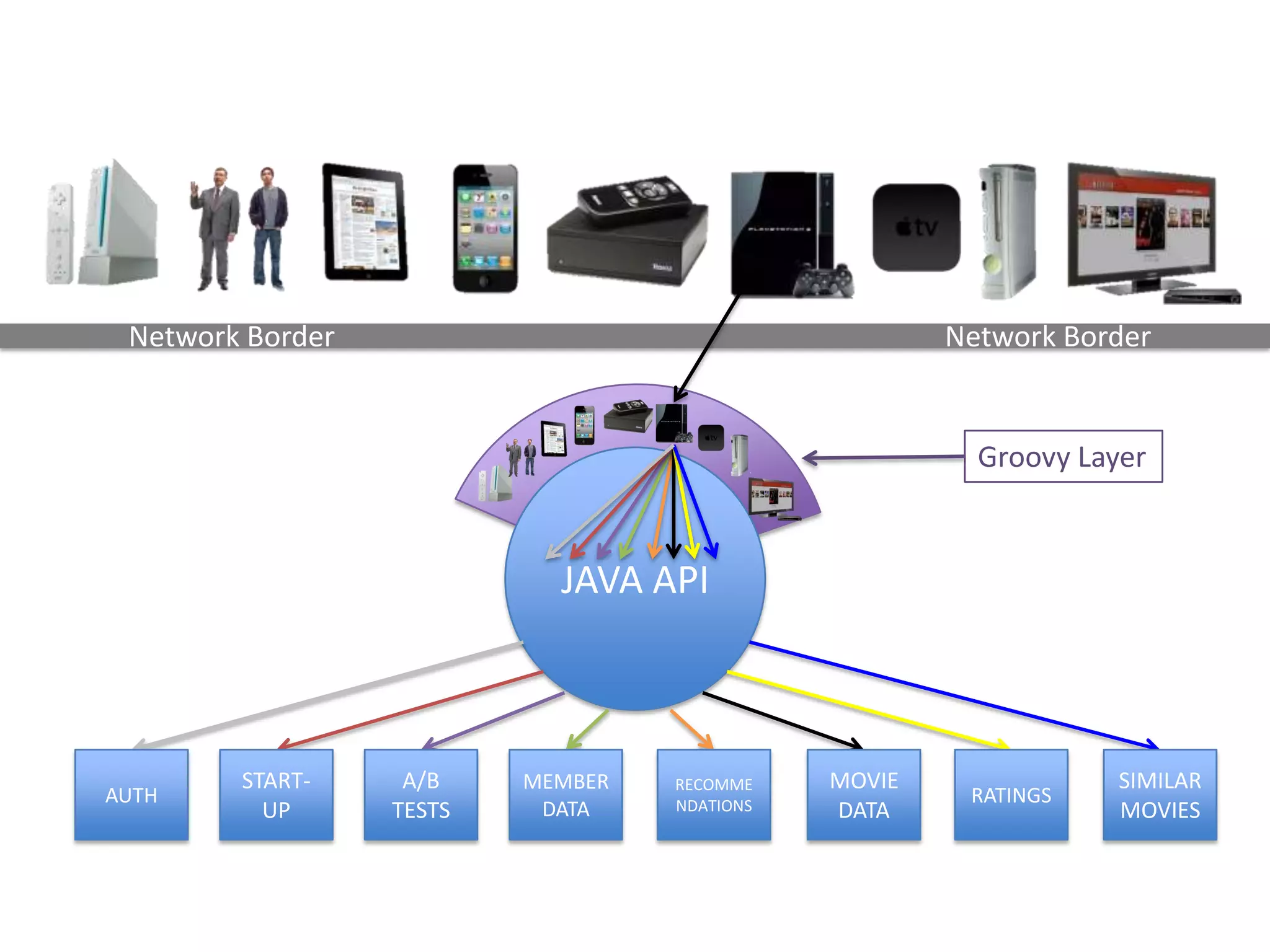

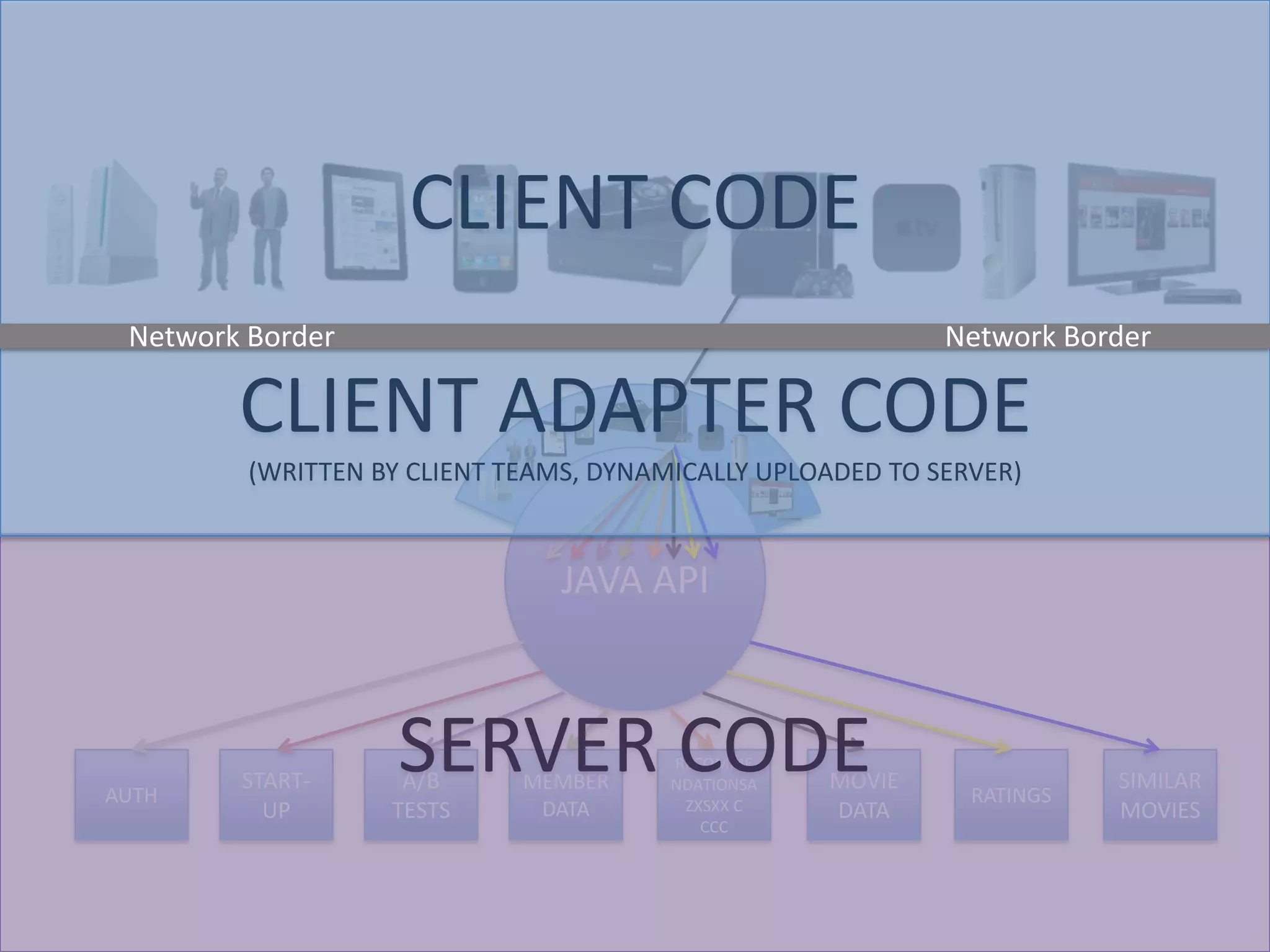
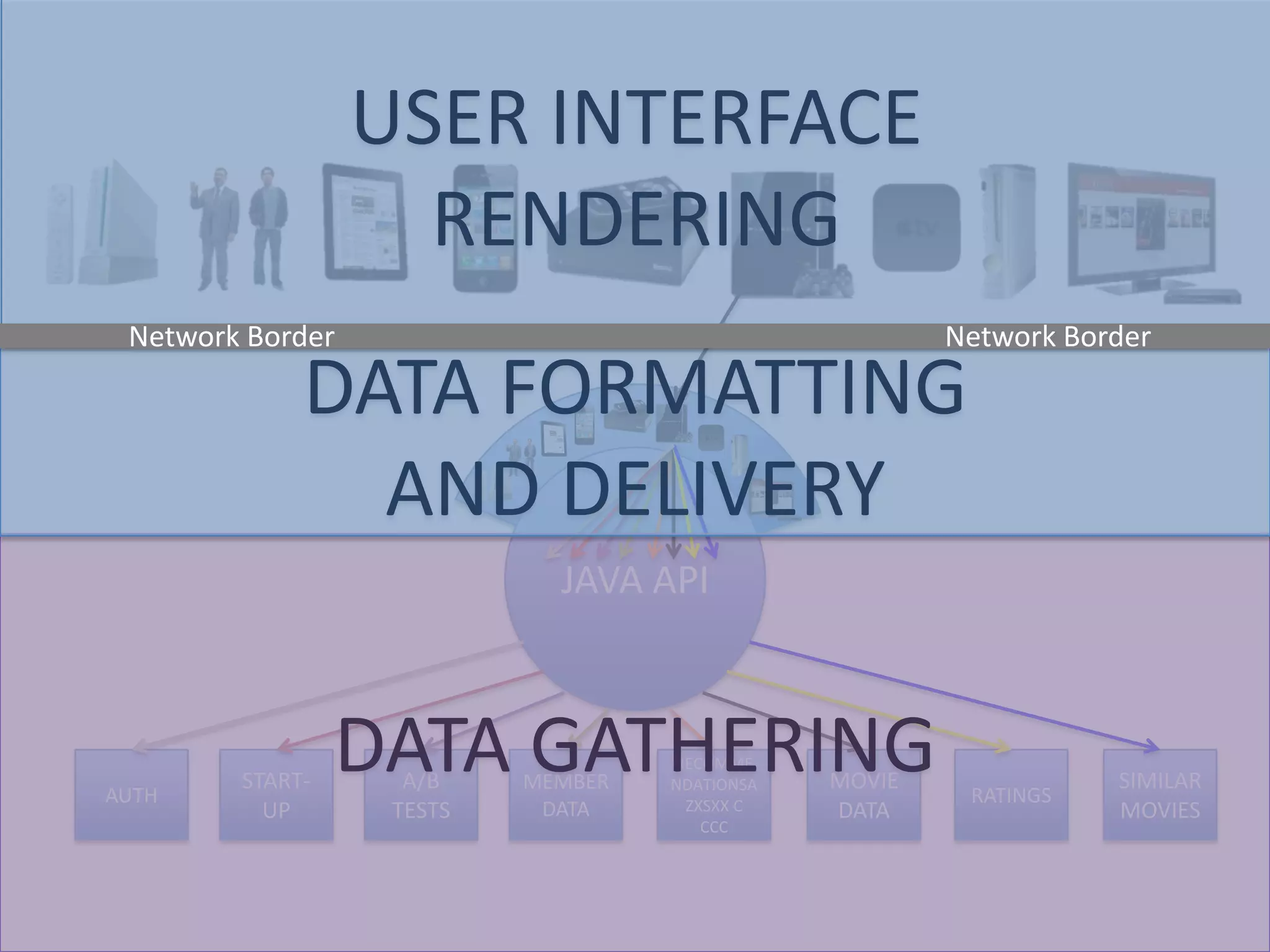





The presentation by Daniel Jacobson details the architecture and operational strategies of Netflix's global streaming service, which serves over 44 million subscribers across more than 40 countries. Key points include the challenges of maintaining a resilient API, scaling the system, and implementing predictive auto-scaling with tools like 'Scryer' and chaos testing methodologies to ensure reliability. Additionally, it emphasizes the importance of data brokering and personalized content delivery across over 1,000 device types.




![[C33] 24時間365日「本当に」止まらないデータベースシステムの導入 ~AlwaysOn+Qシステムで完全無停止運用~ by Nobuyuki Sa...](https://cdn.slidesharecdn.com/ss_thumbnails/c33sqlserversasaki-131128193643-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)









