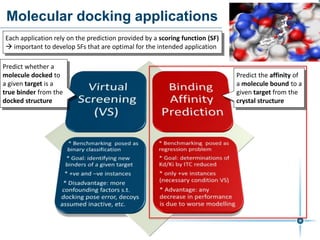
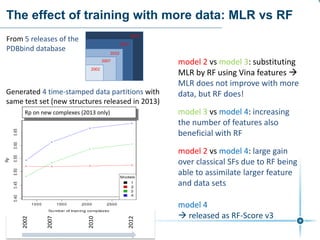
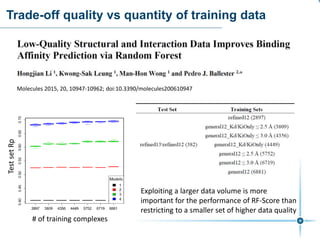
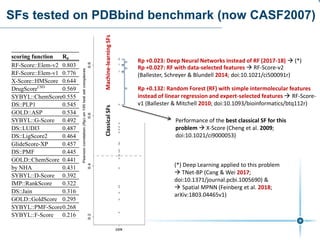
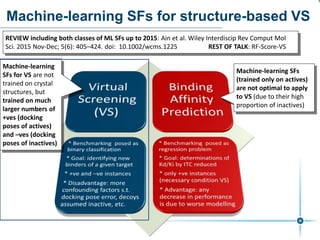
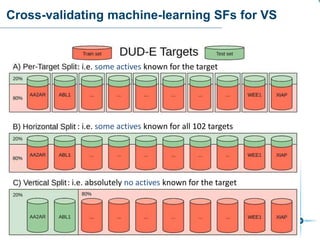
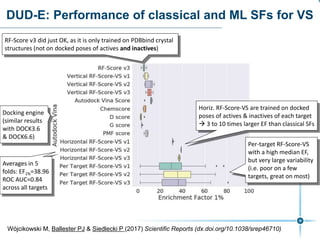
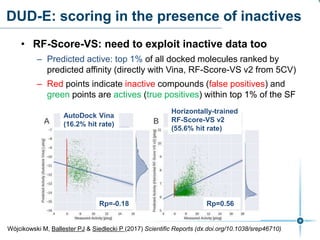
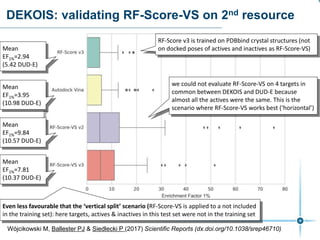
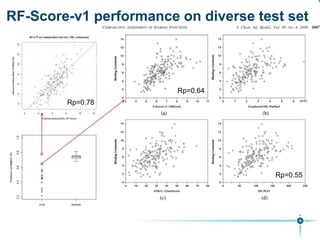
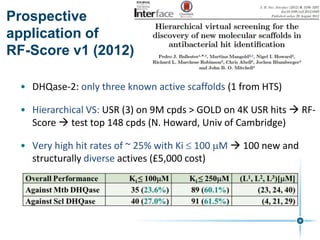
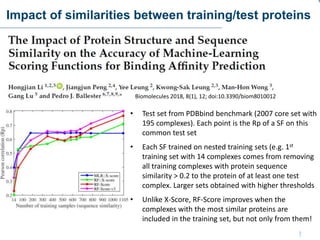
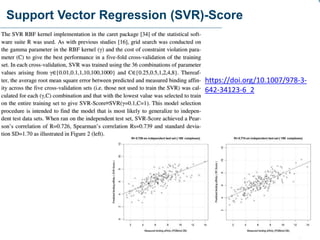
This document discusses the development and performance of machine-learning scoring functions (ML SFS) for predicting binding affinities in molecular docking, particularly focusing on the rf-score series. The findings highlight that ML SFS outperforms traditional scoring functions, especially with larger training sets and data-driven feature selection. It emphasizes the challenges and future directions in optimizing these scoring functions for diverse protein-ligand complexes.




































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)












