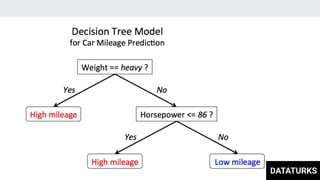
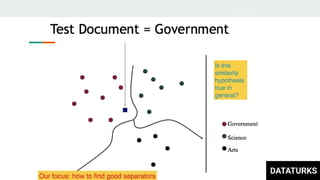
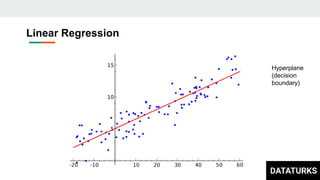
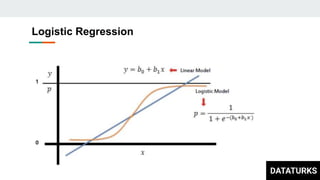
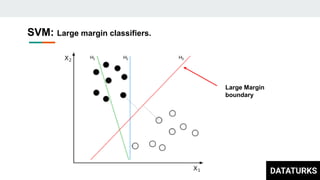
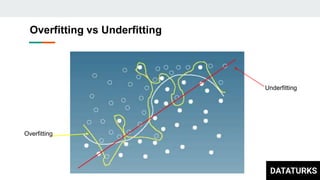
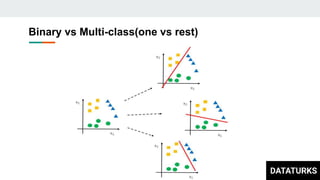
This document discusses text classification, which involves assigning categories or classes to text documents. It describes common applications like spam filtering and news categorization. Several machine learning models for text classification are covered, including naive bayes, decision trees, document vector models, K-nearest neighbors (KNN), support vector machines (SVM), logistic regression, and fastText. The concepts of overfitting and underfitting are also briefly discussed.