Downloaded 15 times


![© Hee-Meng Foo, 2020
What this talk is about
● Essentially the “Cliff Notes” of this paper (37 page long):
“Machine Learning Testing: Survey, Landscapes and Horizons”, Jie M. Zhang,
Mark Harman, Lei Ma, Yan Liu, arXiv:1906.10742v2 [cs.LG], 21 Dec 2019
● Please don’t shoot the messenger
● There are ~ 300 citations, I have not read most of them
● “[XX]” (eg. [23]) in slides refer to a citation from the paper
● Slides will reference sections of paper eg. “3. Machine Learning Testing”](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-2-320.jpg)





![© Hee-Meng Foo, 2020
Preliminaries
● The Oracle Problem
○ Testing involves examining the behavior of a system in order to discover potential faults. Given an input for a
system, the challenge of distinguishing the corresponding desired, correct behavior from potentially incorrect
behavior is called the “test oracle problem”.
○ See https://www.youtube.com/watch?v=cquyBmIh0e4
● Metamorphic Testing
○ TSP example
● Differential Testing
○ Compare the result from > 2 other systems eg. compilers. DeepXplore [1]
● Adversarial Testing
○ Use perturbed data to test robustness
● MC/DC coverage
○ What is minimum combinations of a set of predicates to cover all possible meaningful combinations
○ Eg. A ^ B ^ C v D (truth table is 2^4)
○ See https://www.youtube.com/watch?v=HzmnCVaICQ4
Source:
http://algorist.com/problems/Traveling_Salesman_Problem.html
A
X](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-12-320.jpg)


![© Hee-Meng Foo, 2020
ML Testing Properties (Non-Functional)
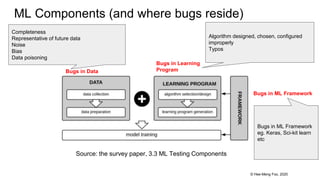
● Robustness
○ Ie. how resilient is ML system’s correctness in presence of perturbations
○ Local vs Global robustness ie. robustness wrt 1 test input vs all test inputs
● Security
○ ML system’s resilience against potential harm, danger or loss via manipulating or illegally accessing
ML components eg. adversarial attacks, data poisoning
● Data Privacy
○ Current research focuses on how to present privacy-preserving ML, not detecting privacy violations
● Efficiency
○ ie. training or prediction speed. Also small footprint for mobile
● Fairness
○ Various sources of bias. Protected characteristics vs protected attributes vs sensitive attributes
● Interpretability
○ 2 aspects: transparency (how model works), post hoc explanations (other info derived fr model)
○ Good e-book on ML Interpretability [70]
See survey paper, 3.4 ML Testing Properties](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-19-320.jpg)

![© Hee-Meng Foo, 2020
Studies of ML Bugs
● Thung et al [159]
○ Looked at bug reports from Apache Mahout, Lucene, OpenNLP
○ 22.6% bugs due to incorrect implementation
○ 15.6% bugs were non-functional
○ 5.6% data bugs
● Zhang et al [160]
○ Looked at 175 Tensorflow bugs
○ 18.9% Tensorflow API misuse
○ 13.7% unaligned tensor
○ 21.7% incorrect model parameter or structure
● Banerjee et al [161]
○ Looked at bugs in AV systems
○ ML and decision control accounted for 64% of disengagements
See survey paper, 5.5 Bug Report Analysis](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-21-320.jpg)

![© Hee-Meng Foo, 2020
Test Input Generation
● 5.1.1 Domain Specific Test Input Synthesis
○ 2 categories: adversarial (perturbed data, robustness test) & natural (test application scenario)
○ DeepXplore [1] generates “real world” test data for neuron coverage
○ DeepTest [76] - realistic image transforms for testing AV
■ Detected > 1000 erroneous behaviors in CNNs/RNNs [77]
○ GANs [79] - driving scene based test generation with different weather conditions
○ DeepBillboard [81] - generate real-world adversarial billboards for testing AV systems
○ Audio based DNN [82] - transformations tailored to audio inputs for testing
○ Image classification [83] - generates images and uses metamorphic relations for testing
○ Machine translation [86] - uses mutation of words to generate test inputs](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-23-320.jpg)
![© Hee-Meng Foo, 2020
Test Input Generation
● 5.1.2 Fuzz and Search based Test Input Generation
○ What is Fuzzing [9] - see https://www.youtube.com/watch?v=pcEy-4eZF6g
○ Search based test generation - uses metaheuristic search to guide fuzz process [17][87][88]
○ TensorFuzz [89] - hill-climbing approach to explore valid input space for Tensorflow graphs
○ DLFuzz [90] - based on ideas from DeepXplore (neuron coverage) to gen. adversarial examples
○ DeepHunter [91] - metamorphic transformation based coverage guided fuzzing technique
○ Feature guided test generation [93] - Using Scale-Invariant Feature Transform (SIFT) to identify
features that represent an image with a Gaussian mixture model, then transforms problem of
finding adversarial examples into a 2-player stochastic game
○ Evaluation of reinforcement learning with adversarial example generation [94]
○ Fuzzing and metamorphic testing to test LiDAR obstacle detection [95]
○ [97] test input for text classification + fuzzing that considers grammar
○ [98][99] - mutated sentences in Natural Language Inference (NLI) to generate test inputs for
robustness testing
○ [101] - test input generation to highlight discriminatory nature of of model
○ [102] - framework for testing AV systems that utilizing fuzz based test gen + search based test
gen](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-24-320.jpg)
![© Hee-Meng Foo, 2020
Test Input Generation
● 5.1.3 Symbolic Execution based Test Input Generation
○ What is symbolic execution [105] - see https://youtu.be/FlzroEd4pnw
○ Concolic testing (or DSE, also see video) - auto-gen test inputs to achieve high coverage
○ However for ML, we need to test combination of code + data
○ [7] - symbolic analysis and statistic approach to generate effective tests
○ [108] outlines 3 challenges applying symbolic execution to ML:
■ No explicit branching, highly non-linear, scalability issues due to complexity of ML models
○ DeepCheck [108] - create 1-pixel, 2-pixel attacks to fail image classification
○ DeepConcolic [111] - DSE for DNNs adopting MC/DC criteria for coverage
● 5.1.4 Synthetic Data to Test Learning Program
○ [112] - generated data with repeating/missing values or categorical data
○ [45] - synthetic training data that adhere to schema constraints to trigger hidden assumptions
○ [54] - synthetic data with known distributions to test overfitting
○ [113] - generating datasets with predictable characteristics to be used as pseudo oracles](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-25-320.jpg)
![© Hee-Meng Foo, 2020
Test Oracles
● 5.2.1 Metamorphic Relations as Test Oracles
○ Widely studied. Many metamorphic relations based on transformations of data that are
expected to yield unchanged or certain expected changes in predicted output
○ Coarse Grained Data Transformations
■ [115] - describes 6 transformations: additive, multiplicative, permutative, invertive, inclusive, exclusive
■ [116] - proposes 11 metamorphic relations for image classification
■ [117] - function level metamorphic relations (evaluation of 9 ML applications)
○ Fine Grained Data Transformations
■ [118] - proposed 5 types of metamorphic relations specific to certain models for supervised classifiers
■ [120] - discusses the differences in the metamorphic relations between SVM and DNNs
■ [54] - proposed Perturbed Model Validation (PMV) that combines metamorphic relations and data
mutation to detect overfitting
■ [123] - studied metamorphic relations of Naive Bayes, KNN
■ METTLE [125] - 6 types of metamorphic relations for unsupervised learners
■ [113][126] - discussed possibility of using different grained metamorphic relations to find problems in
SVM and DNNs](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-26-320.jpg)
![© Hee-Meng Foo, 2020
Test Oracles
● 5.2.1 Metamorphic Relations as Test Oracles
○ Metamorphic Relations Between Datasets
■ [127] [45] - studied metamorphic relations between training and new data
■ [45] - studied metamorphic relations among different datasets close in time
○ Frameworks to Apply Metamorphic Relations
■ Amsterdam [128] - framework to automate process of using metamorphic relations to detect ML bugs
■ Corduroy [117] - extends Java Modelling Language to let developers specify metamorphic properties
and generate test cases for ML testing](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-27-320.jpg)
![© Hee-Meng Foo, 2020
Test Oracles
● 5.2.2 Cross-Referencing as Test Oracles
○ Differential testing and N-version Programming
■ [133] 5 - 27% of test oracles for DNN libraries use differential testing
■ N-version Programming ie. generate multiple functionally equivalent programs to compare against
○ [135] used differential testing to discover 16 faults from 7 Naive Bayes implementations & 13
faults from 19 KNN implementations
○ CRADLE [48] - an approach to finding and localizing bugs in DNN frameworks (CNTK,
Tensorflow, Theano), 11 datasets (eg. ImageNet, MNIST), 30 pre-trained models
○ DeepXplore [1], DLFuzz [90] - used differential testing to find effective test inputs
○ [136] uses “mirror” programs instead of different implementations for diff testing
● 5.2.3 Measurement Metrics for Designing Test Oracles
○ [137] - robustness metric
○ [138] [139] [140] - fairness metric
○ [65] [141] - interpretability metric](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-28-320.jpg)
![© Hee-Meng Foo, 2020
Test Adequacy
● 5.3.1 Test Coverage
○ Unlike traditional software where decision logic is in the code, code coverage is not as
demanding a criteria for ML testing since decision logic is derived from training
○ Other proposed coverage techniques:
■ Neuron coverage
● DeepXplore [1] and [92]
■ MC/DC coverage variants
● [145] MC/DC inspired DNN test coverage
■ Layer level coverage
● [92] [148] [149] [147]
■ State level coverage
● For RNNs [82]
○ Limitations of coverage criteria research
■ Most focus on DNNs
■ [147] [150] talks about limitations of these approaches](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-29-320.jpg)
![© Hee-Meng Foo, 2020
Test Adequacy
● 5.3.2 Mutation Testing (or rather Mutation Score)
○ Mutation testing ie. fault injection
○ Mutation score = ratio of detected faults against all injected faults
○ DeepMutation [152] - mutate DNNs at source or model level
○ [153] propose 5 mutation operators for DNNs
● 5.3.3 Surprise Adequacy
○ See [127] for thorough explanation
○ ie. test data should be “sufficiently but not overly surprising” compared with training data
○ “Surprise” - measured using (a) KDE or (b) distance btw neuron activation vectors
● 5.3.4 Rule Based Checking of Test Adequacy
○ [154] 28 test aspects to consider + scoring system used by Google. 4 types: (a) tests for
Model, (b) tests for ML infrastructure, (c) tests for ML data and (d) tests if ML system works
well over time](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-30-320.jpg)
![© Hee-Meng Foo, 2020
Test Prioritization and Reduction
● 5.4 Test Prioritization and Reduction
○ [155] used DNN metrics eg. cross-entropy, surprisal and Baysian uncertainty to prioritize test
inputs
○ [156] adversarial test input prioritization
○ [157] used sampling technique guided by neurons of last hidden layer of DNN
○ [158] test selection metrics based on “model confidence”](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-31-320.jpg)
![© Hee-Meng Foo, 2020
Debug & Repair
● Debugging Approaches (From 5.6 Debug and Repair)
○ Data Resampling
■ Generated test data as training data for re-training - DeepXplore [1] 3% imp, DeepTest [76] 46% imp
■ “Faulty neurons” [162] - identified neurons responsible for misclassification
○ Debugging Frameworks
■ Storm [163] - program transformation framework to generate smaller programs that can support
debugging
■ tfdbg [164] - a debugger for ML models built on Tensorflow with 3 components:
● Analyzer, NodeStepper, RunStepper
■ MISTIQUE [165] - system to capture, store and query model intermediaries for debugging
■ PALM [166] - tool that explains complex model as 2-part surrogate model
● Repair Approaches
○ Fix Understanding
■ [167] - human-in-the-loop approach to simulate potential fixes
○ Program Repair
■ [168] - distribution guided inductive synthesis approach to repair decision making programs](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-32-320.jpg)
![© Hee-Meng Foo, 2020
General Testing Framework & Tools
● 5.7 General Testing Framework and Tools
○ [169] - framework to generate and validate test inputs for security testing
○ [170] - CNN testing framework
○ [171] - tool to help developers test and debug fairness bugs
○ [172] - testing framework including different evaluation aspects eg. availability, achieveability,
robustness, avoidability, improvability
○ [173] - framework for designing ML algorithms that simplifies the regulation of undesired
behaviors](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-33-320.jpg)
![© Hee-Meng Foo, 2020
ML Properties To Be Tested
● 6.1 Correctness
○ Classical approaches: cross-validation & bootstrapping
○ Classical measures: accuracy, precision, recall, AUC etc
○ [177] - studied variability of training/test data when assessing correctness of ML classifier
○ [178] - studied diff statistical methods when comparing AUC
○ [136] - “mirror” program as correctness oracle
○ [160] - survey of 175 Tensorflow bugs, 40 concern correctness
○ [179][180][181] - detecting data bugs
○ [116][120][121][123][130][154][162] - test input/test oracle design
○ [165][167][182] - test tool design](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-34-320.jpg)
![© Hee-Meng Foo, 2020
ML Properties To Be Tested
● 6.2 Model Relevance
○ Model relevance evaluation detects mismatches between model and data
○ Poor model relevance is usually associated with over or under-fitting
○ [183] When a model is too complex for the data, even noise in training data is fitted by model
○ [184][185][186] Overfitting can easily happen esp when data is insufficient
○ [54] PMV injects noise into training data, re-trains model, and uses training accuracy decrease
to detect over/under-fitting. PMV has better performance than 10 fold cross-validation
○ [42] overfitting detection by generating adversarial examples from test data
○ [187] repeated re-use of same test data will result in overfitting
○ [51] talks about training efficiency
○ [162] tries to address overfitting by re-sampling the training data](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-35-320.jpg)
![© Hee-Meng Foo, 2020
ML Properties To Be Tested
● 6.3 Robustness & Security
○ Robustness Measurement
■ [137] correctness of system with the existence of noise
■ DeepFool [188] computes perturbations to “fool” DNNs and quantify robustness
■ [189] 3 metrics: (a) pointwise (b) adversarial frequency (c) adversarial severity
■ [190] set of attacks to set upper bound for robustness
■ [191] upper and lower bounds based on test data
■ DeepSafe [192] data-driven approach to assessing DNN robustness
■ [193] - probabilistic robustness
■ [194] Bayesian Deep Learning to model propagation of errors
○ Perturbation Targeting Test Data
■ [190] adversarial example generation using distance metrics to measure similarity
■ [196][197] library to standardize adversarial example construction
○ Perturbation Targeting Whole System
■ AVFI [198] software fault injection to approx h/w errors for AV systems
■ Kayotee [199] systematically injects faults into s/w & h/w systems for AV systems
■ DriveFI [96] - mines situations and faults that maximally impact AV safety
■ [102] closed loop behavior of whole system to support adversarial example generation (also AV)](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-36-320.jpg)
![© Hee-Meng Foo, 2020
ML Properties To Be Tested
● 6.4 Efficiency
○ Already covered elsewhere
● 6.6 Interpretability
○ Manual Assessment of Interpretability
■ [65] taxonomy of evaluation approaches for interpretability
■ [215] local and global interpretability
■ [215] Decision Trees and Logistic regression more locally interpretable than DNNs
○ Automatic Assessment of Interpretability
■ [46] metric to understand the behaviors of an ML model
■ [70] measure interpretability based on category of ML model
■ [216] Metamorphic Relation Patterns (MRP) to help users understand how ML system works
○ Evaluation of Interpretability Improvement Methods
■ [217] investigated several interpretability improving methods
● 6.7 Privacy
○ [218] treat programs as grey boxes and detect differential privacy violations via statistical tests
○ [219] proposed to estimate the ∊ parameter in differential privacy](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-37-320.jpg)
![© Hee-Meng Foo, 2020
ML Properties To Be Tested
● 6.5 Fairness
○ Causes of Unfairness
■ [201] 5 causes: skewed sample, tainted examples, limited features, sample size disparity, proxies
■ [171] fairness bugs can offend and harm users, cause embarrassment, mistrust, rev loss, legal action
○ Fairness Definitions and Measurement Metrics
■ [202][203][204][205] several definitions of fairness but no firm consensus
■ Fairness Through Unawareness (FTU)
● Algorithm is fair so long as protected attributes not explicitly used in decision making
● [206][202][207]
■ Group Fairness
● Demographic parity [208], Equalized odds, Equal opportunity [139]
■ Counter-factual Fairness
● [206] a model satisfies this if the output is same when protected attribute is flipped
■ Individual Fairness
● [138] task specific similarity metric to desc pairs of individuals that shd be regarded as similar
■ Analysis and Comparison of Fairness Metrics [202][203][62][204]
■ Support for Fairness Improvement
● RobinHood [209][211] - multiple user defined fairness definitions
● [75] fairness aware programming, [212] fairness classification, [168] distributed guided inductive
synthesis](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-38-320.jpg)
![© Hee-Meng Foo, 2020
ML Properties To Be Tested
● 6.5 Fairness
○ Test Generation Techniques for Fairness Testing
■ Themis [5][213] generates tests randomly for group fairness
■ Aequitas [101] test generation to uncover discriminatory inputs
■ [109] symbolic execution together with local explainability to generate test inputs
■ [171] easily interpretable bug reports
■ [122] checking whether algorithm under test is sensitive to training data changes](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-39-320.jpg)
![© Hee-Meng Foo, 2020
ML Testing Components
● 7.1 Bug Detection in Data
○ Importance of Bug Detection in Data
■ [45] important to detect data bugs early as output of ML systems often used as input data downstream
■ [220] [8] data testing is challenging
○ Bug Detection in Training Data
■ Rule-Based Approach
● [179] data linter - (a) miscoded data, (b) outliers and scaling (c) packaging errors eg. dupes, empty examples
● [46] metrics to evaluate whether training data covered all scenarios
■ Performance Based Data Bug Detection
● MODE [162] identifies “faulty” neurons
○ Bug Detection in Test Data
■ [221] augment DNNs with small sub-network to detect adversarial perturbations
■ [222] DNN model mutation to expose adversarial examples
■ [224] compared 10 approaches to detect adversarial examples
○ Skew Detection in Training and Test Data
■ [127] using KDE and distance metric to detect skew
■ [45] studied skew in training and test data](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-40-320.jpg)
![© Hee-Meng Foo, 2020
ML Testing Components
● 7.1 Bug Detection in Data
○ Frameworks in Detecting Data Bugs
■ [45] data validation system using constraints to find bugs in data (used as part of TFX)
■ ActiveClean [225][226] - iterative data cleaning
■ BoostClean [180] - to detect domain value violations
■ [181] automatic “unit testing” of large scale data sets
■ AlphaClean [228] - greedy tree search to auto tune parameters for data cleaning
■ [182] ML platform that includes data cleansing
■ [229] adopting traditional database/data warehousing data cleaning approaches](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-41-320.jpg)
![© Hee-Meng Foo, 2020
ML Testing Components
● 7.2 Bug Detection in Learning Programs
○ Unit Tests for ML Learning Program
■ [230] unit testing for Tensorflow
■ [231] collection of unit tests for stochastic optimization
○ Algorithm Configuration Examination
■ [232][233] identified OS, language and h/w compatibility issues
■ [232] focused on sklearn, Paddle, Caffe
■ [233] focused on Tensorflow, Theano, Torch
■ [160] - most common learning program bug due to change of Tensorflow API
■ [234] - testing algorithm parameters in DNN testing problems
○ Algorithm Selection Examination
■ [235] compared DNN with classical ML
○ Mutant Simulations of Learning Program Faults
■ [117][128] used mutations to simulate program-code errors
■ [237] static analysis of tensors in Tensorflow](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-42-320.jpg)
![© Hee-Meng Foo, 2020
ML Testing Components
● 7.3 Bug Detection in Framework
○ Study of Framework Bugs
■ [238] studied bugs from Tensorflow, Caffe, Torch. Common issues: crash, non-term, out of mem
■ [233] studied Tensorflow, Theano, Torch - cmp runtime efficiency, training accuracy, robustness etc
■ [232] 10% of framework bugs are efficiency bugs
○ Implementation Testing of Frameworks
■ Challenges in Implementation Bug Detection
● [159] 22% of 500 bugs studies due to incorrect algorithm implementation
● [240] injected implementation bugs into classic ML code in Weka
■ Solutions for Implementation Bug Detection
● [135][48] used differential testing to identify faults (10 in Naive Bayes impl and 20 in KNN impl)
● [10][115] first to discuss possibility of using metamorphic relations in testing ML
● [118] - metamorphic relations to test supervised learning classifiers
● [121] - applied metamorphic relations to finding bugs in image classification
○ Study of Framework Test Oracles
■ [133] studied approximated oracles for Tensorflow, Theano, Pytorch, Keras](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-43-320.jpg)

![© Hee-Meng Foo, 2020
Challenges in ML Testing
● Challenges in Test Input Generation
○ (SBST) Search based Software Test generation [87]
■ Good fit for ML as it searches large input spaces
○ Adversarial Inputs for robustness
■ Criticisms that test data not natural
○ Test inputs as natural as possible
■ DeepTest [76], DeepHunter [92], DeepRoad [79] (AV) - however still amount of “unnaturalness”
● Challenges in Test Assessment Criteria
○ [290] lack of systematic evaluation of how diff assessment metrics correlate with bug revealing
success
● Challenges relating to Oracle Problem
○ Metamorphic relations require human ingenuity to discover/design
○ [128] flaky tests arise in metamorphic testing
○ Pseudo oracles may also lead to many false positives
● Challenges in Testing Cost Reduction
○ ML component testing requires retraining
○ Low footprint devices eg. mobile devices, IoT](https://image.slidesharecdn.com/machinelearningtestingsurveylandscapesandhorizons1-200424033521/85/Machine-learning-testing-survey-landscapes-and-horizons-the-Cliff-Notes-45-320.jpg)



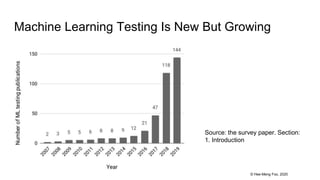
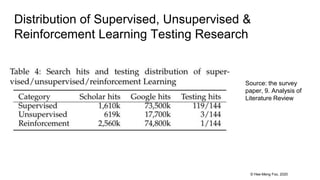
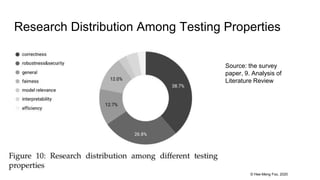
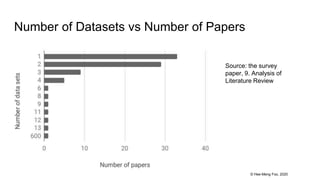
This document provides an overview and summary of a 37-page paper on machine learning testing. It discusses the main sections and findings of the paper, including how ML testing is a growing field but also challenging due to its data-driven nature. Several approaches to ML testing are covered such as test input generation, test oracles, test adequacy, and debugging. Charts from the paper show trends in ML testing research over time.








































































