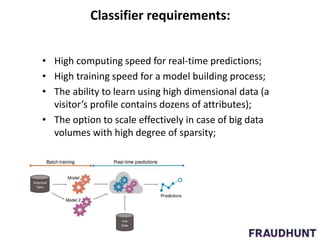
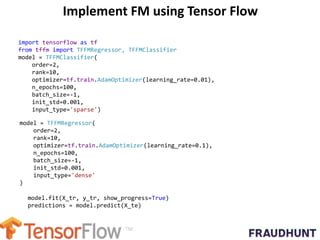
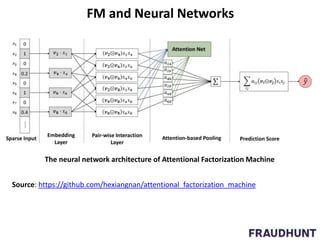
The document discusses digital marketing fraud, detailing its types, prevention principles, and the role of machine learning in real-time fraud detection. It highlights specific algorithms such as factorization machines and outlines their advantages in handling high-dimensional and sparse data for effective fraud prediction. The conclusion emphasizes the need for continuous improvement in predictive modeling accuracy to combat evolving fraud strategies.













![What are the significant advantages of the FM?
1. Allows you to effectively evaluate the options in case of
highly sparse, high dimensional data.
2. Has a linear learning complexity, providing a polynomial
effect.
3. It is a generalization of recommending models with
matrix factorizations.
4. Combines advantages of SVM and factorization models.
Reduce complexity from O(N2)
to O(kN):
Credit from [5]](https://image.slidesharecdn.com/machinelearningtechniquesinfraudprevention-180209093728/85/Machine-learning-techniques-in-fraud-prevention-18-320.jpg)

![FM model main learning points
1. SGD [Rendle] is used for learning
argmin
𝜔
𝑖
𝑙 𝜑 𝜔, 𝑥 , 𝑦 + 𝜆 × 𝜔 2
𝑙 𝜔 = − ln σ 𝜑 𝜔, 𝑥 ∙ 𝑦 σ 𝛼 =
1
1 + 𝑒−𝛼
The function of losses of a binary classification:
where
2. The rating model quality through auROC, Log-Loss.
3. A threshold post processing for predicted score](https://image.slidesharecdn.com/machinelearningtechniquesinfraudprevention-180209093728/85/Machine-learning-techniques-in-fraud-prevention-20-320.jpg)


![PYTHON PROJECT[1] Online Fraud Fraud Detection Cybersecurity Anomaly Detec...](https://cdn.slidesharecdn.com/ss_thumbnails/pythonproject1-250421141954-bd5cebfc-thumbnail.jpg?width=640&height=640&fit=bounds)