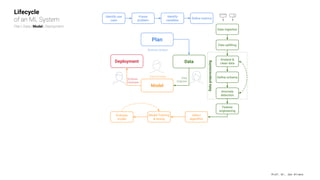
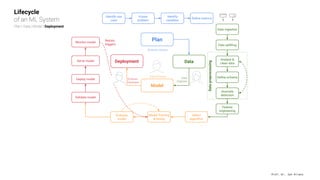
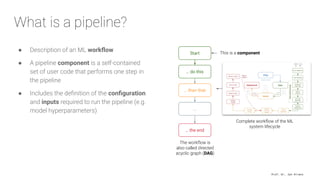
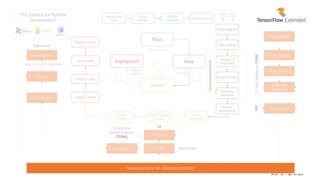
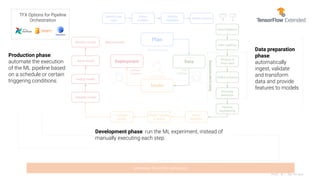
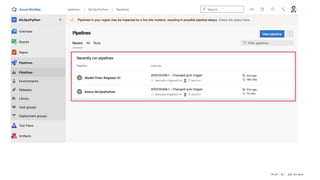
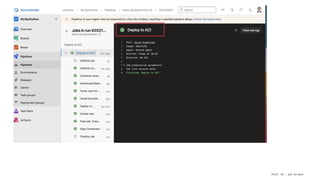
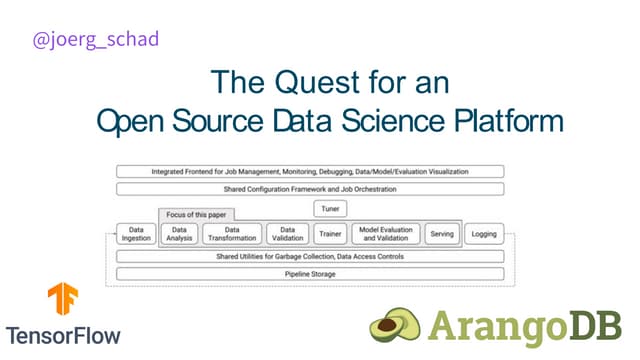
The document presents an overview of machine learning operations (MLOps) and the usage of pipelines in the ML lifecycle, emphasizing the importance of tools like TensorFlow Extended (TFX) and Kubeflow for automating and orchestrating ML processes. It highlights common challenges in scaling AI projects and provides insights into a structured approach to the ML workflow, from data ingestion to model deployment. A key takeaway is the necessity of standardization and automation to bridge the gap from proof of concept to production in AI initiatives.














































































![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)











