Download as PDF, PPTX




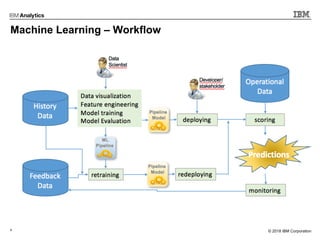
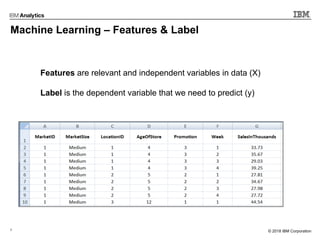
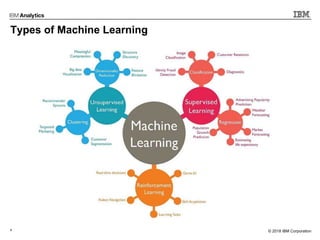

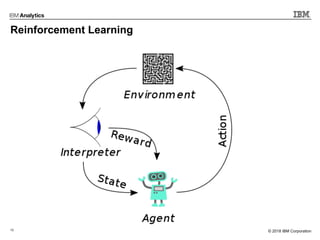

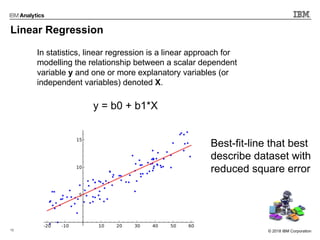
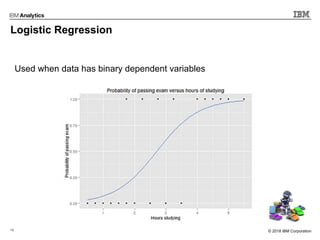
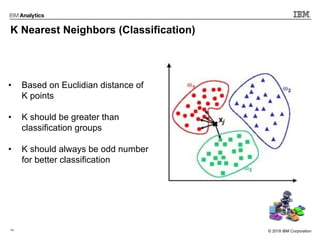
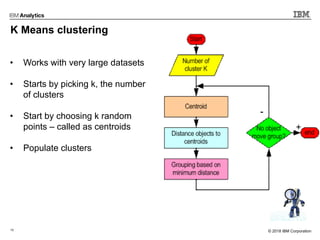
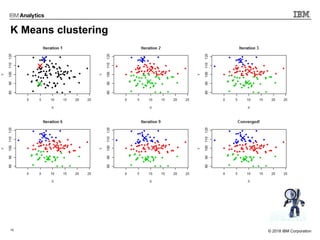

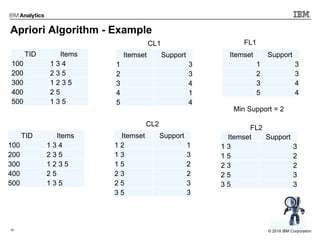


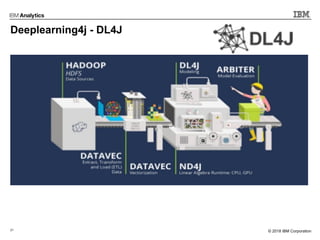





This document outlines an agenda for a machine learning workshop for Java developers. The agenda includes introductions to machine learning algorithms like linear regression, logistic regression, K-nearest neighbors, and K-means clustering. It also discusses machine learning frameworks for Java like Weka, Deeplearning4j, and how to use Jupyter notebooks with Java. The workshop will demonstrate examples using these tools and frameworks.
























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










