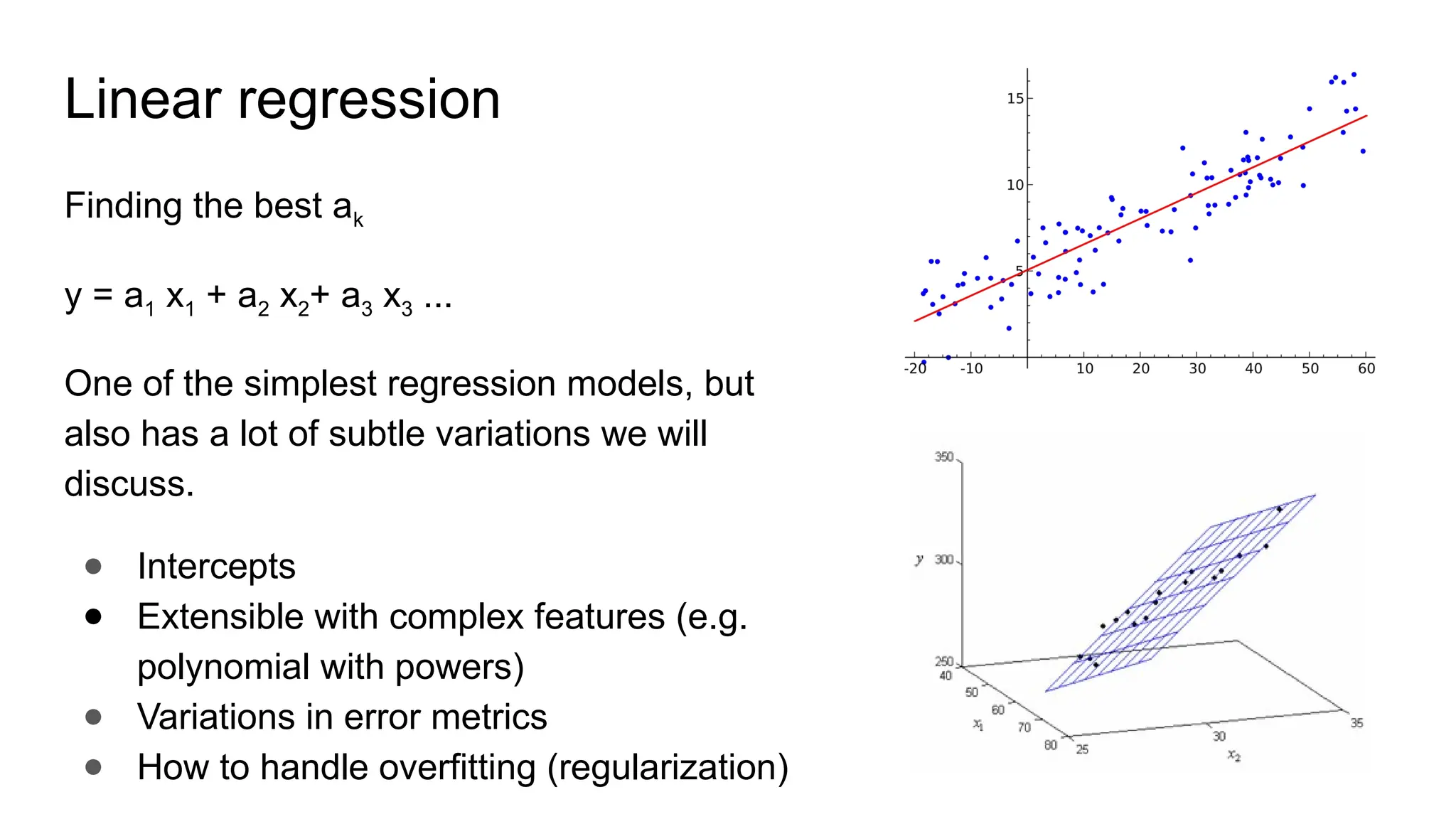
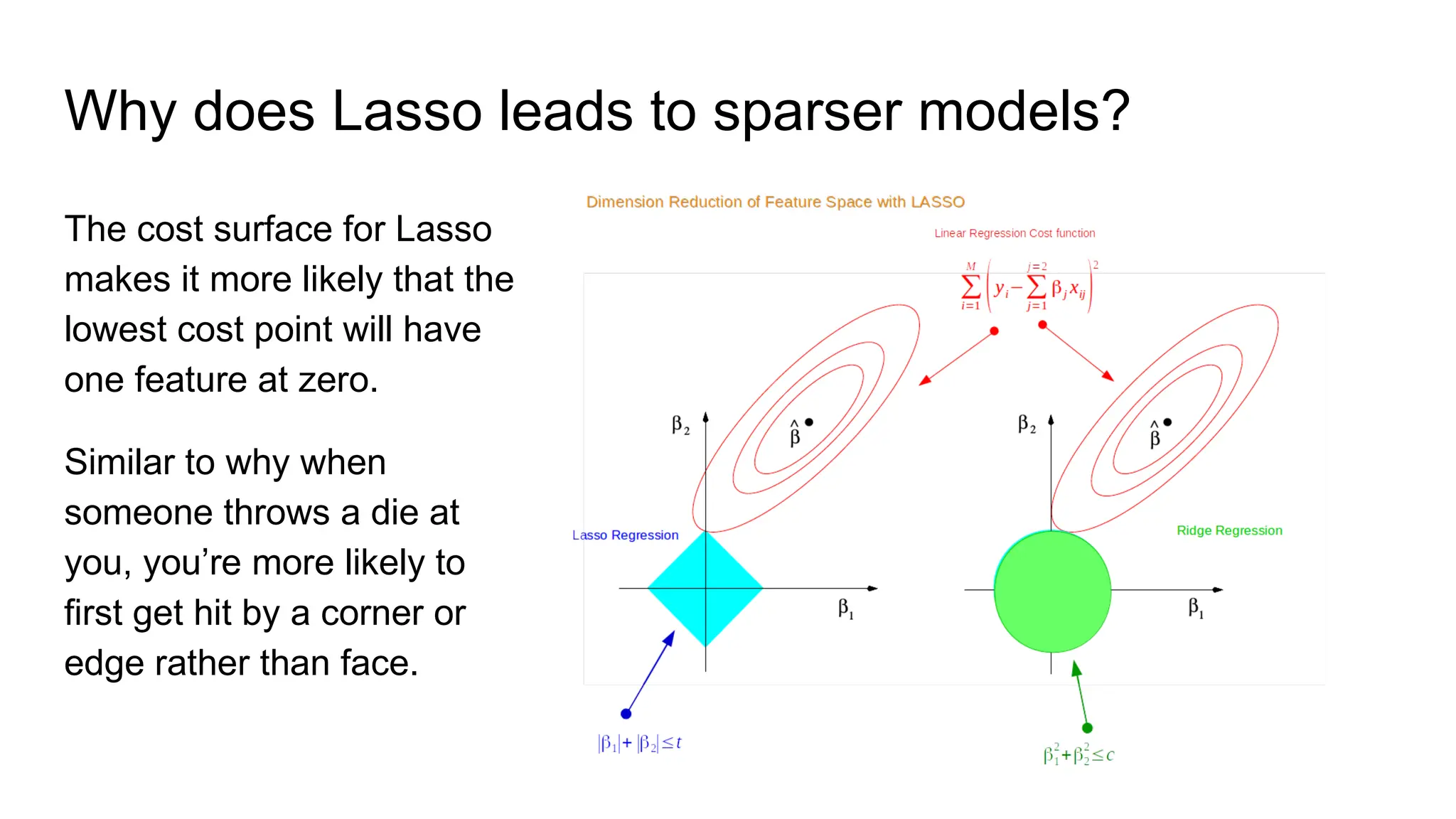
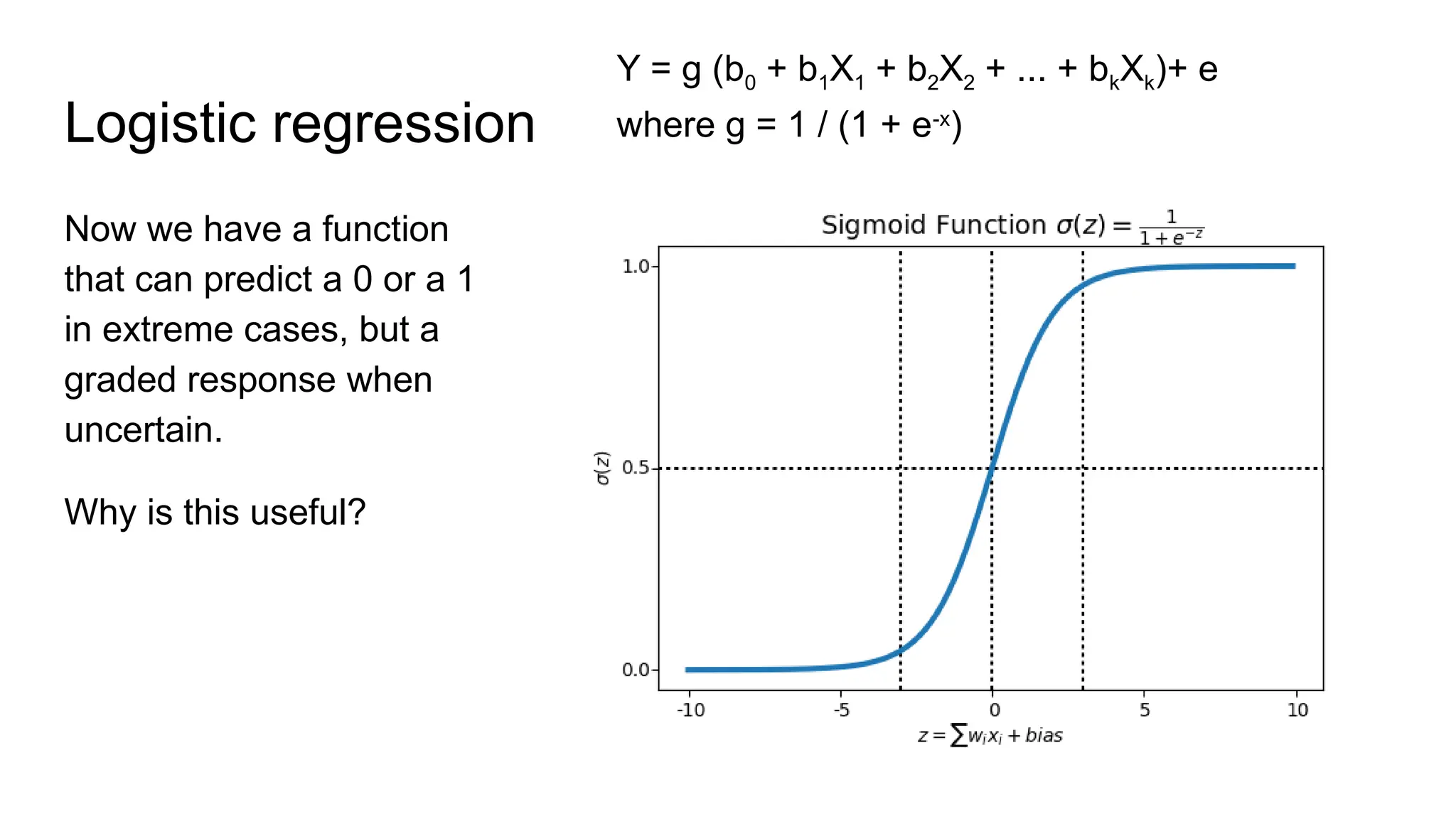
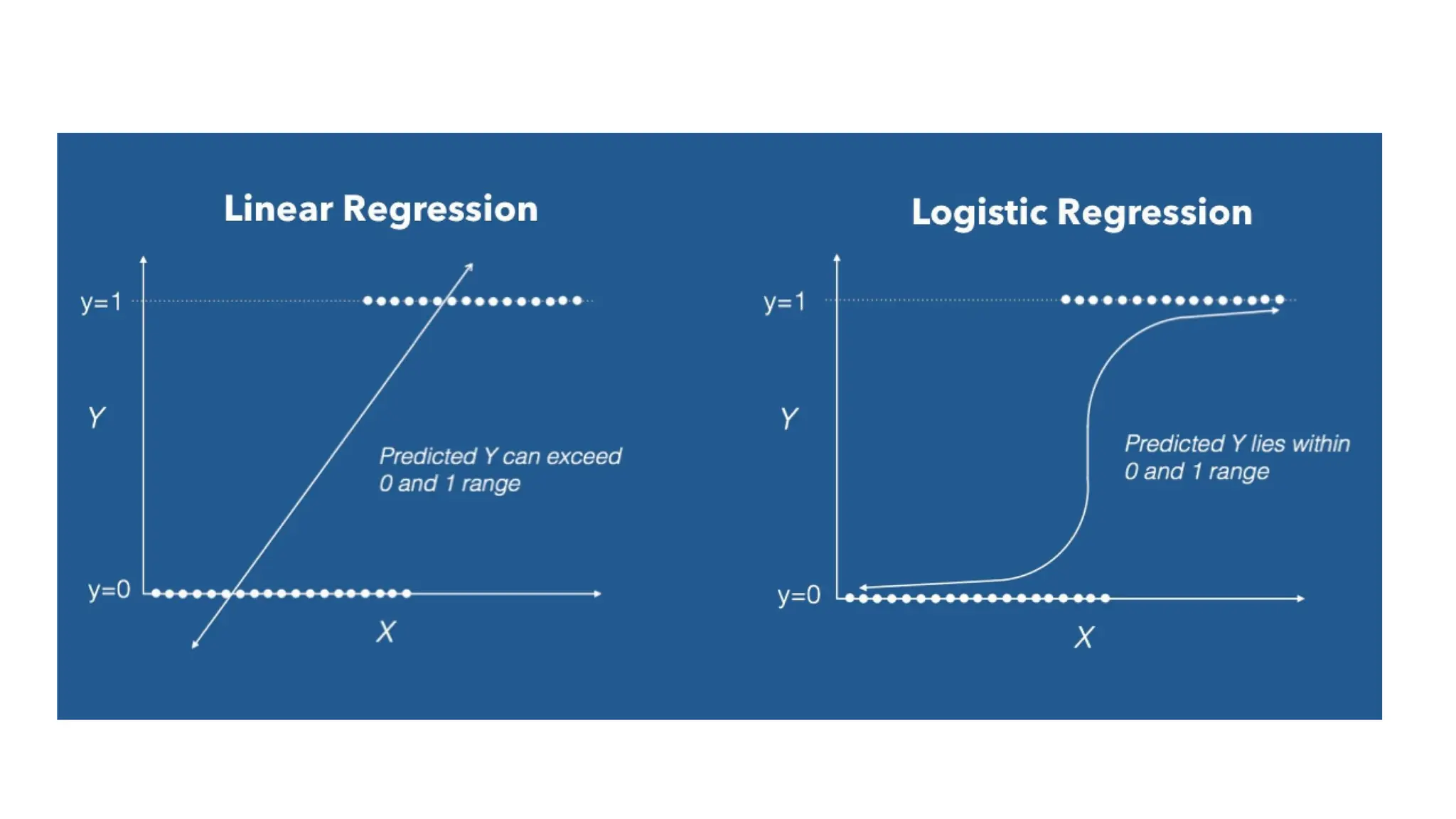
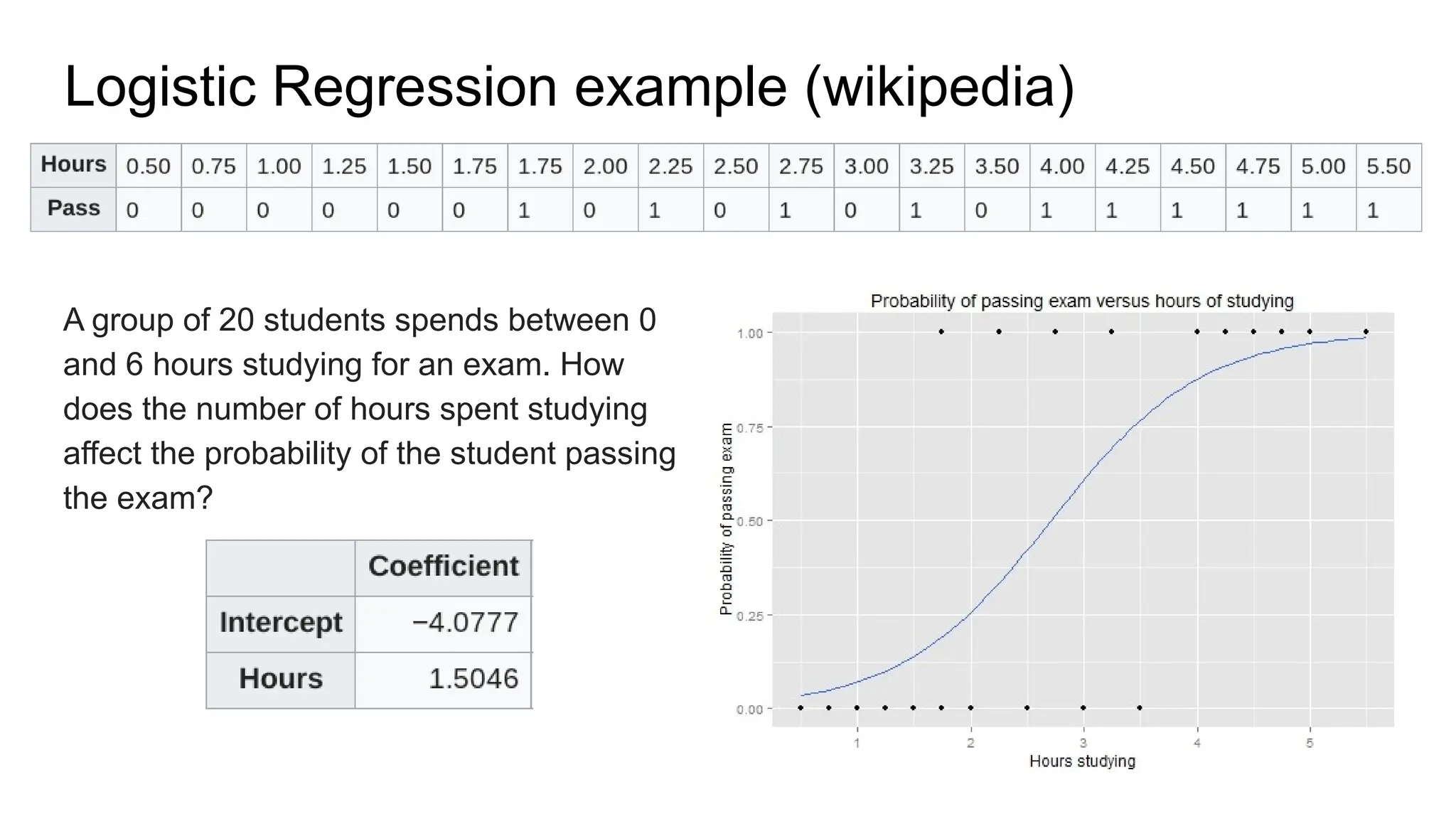
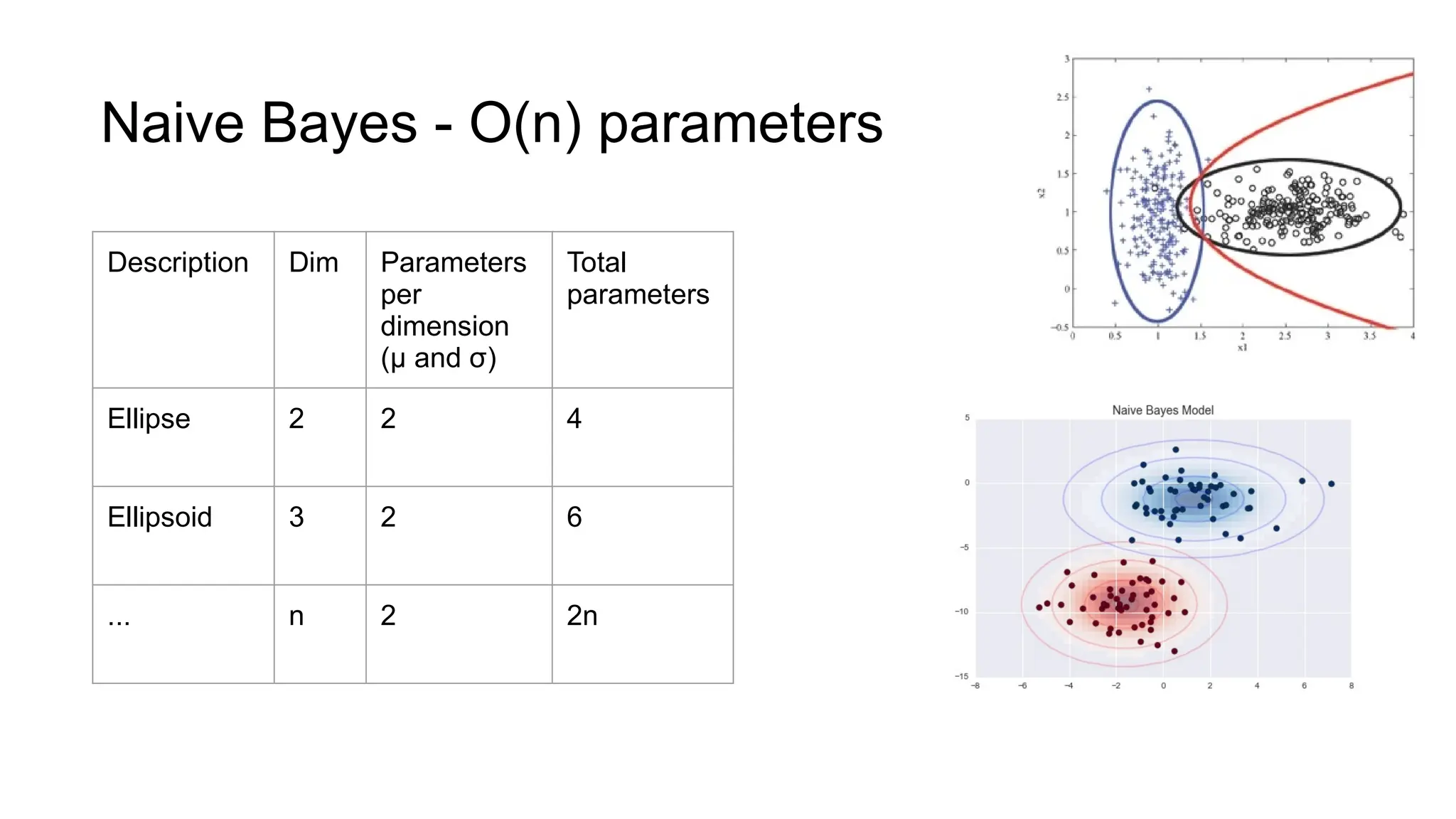
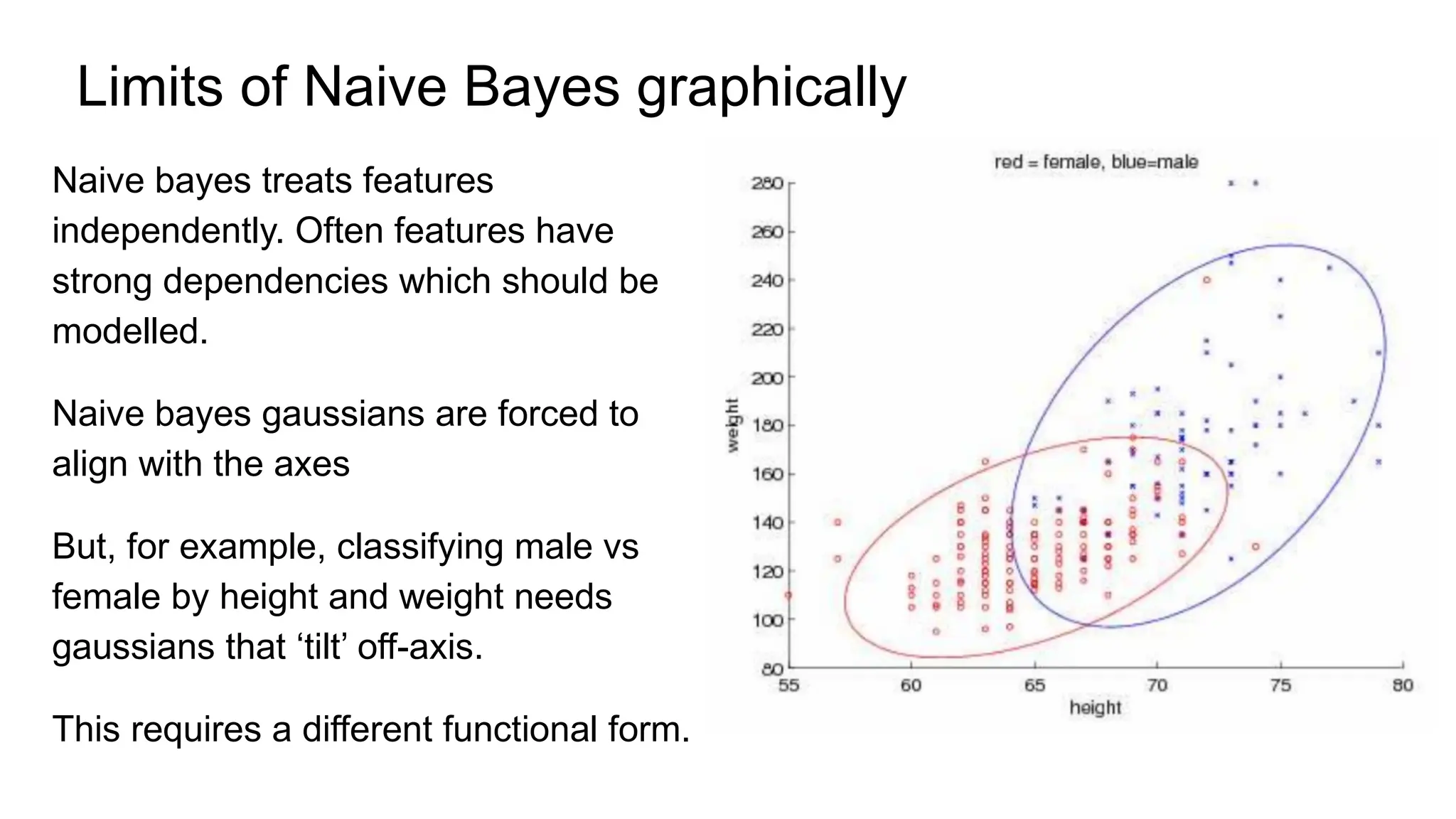
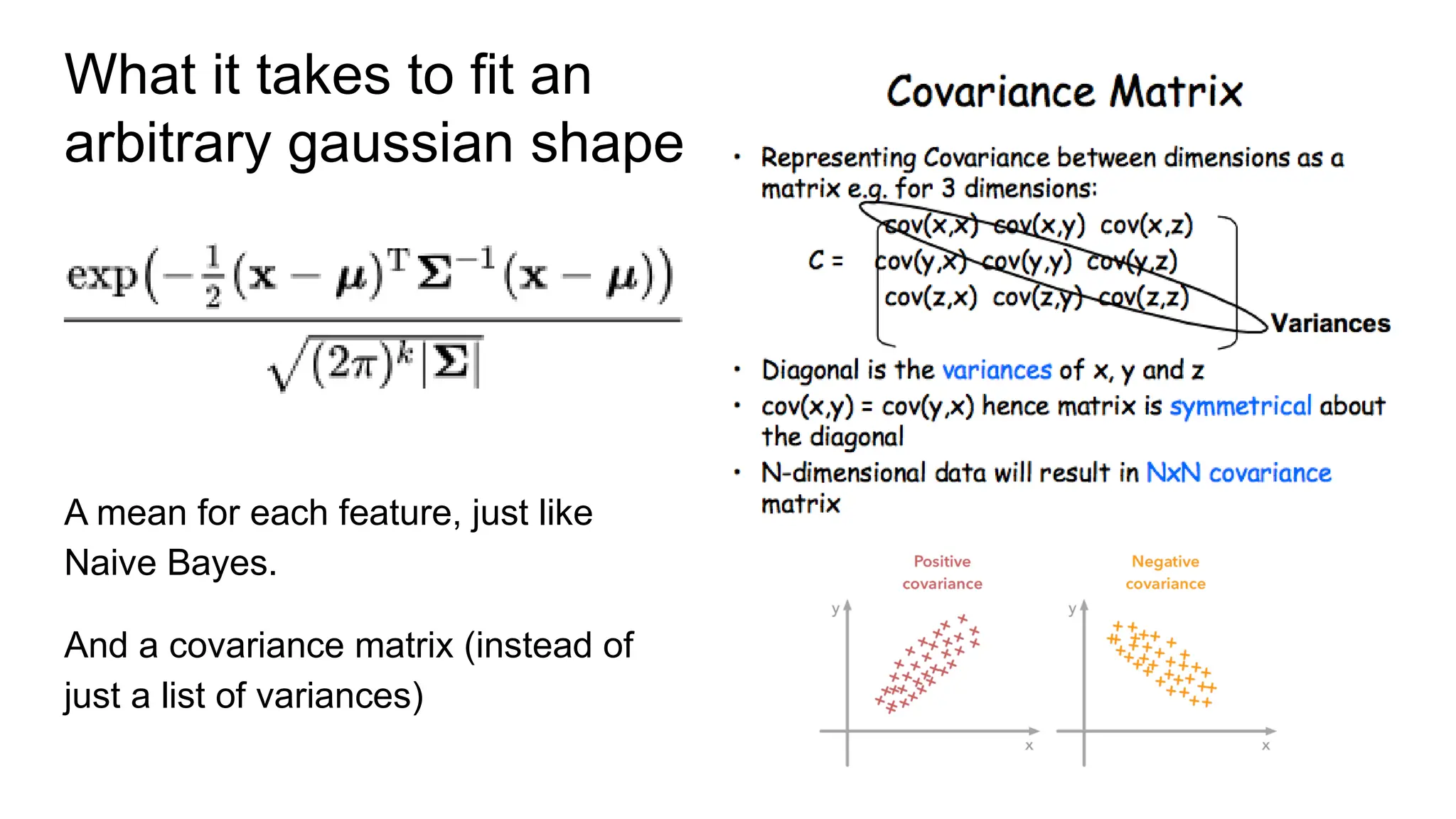
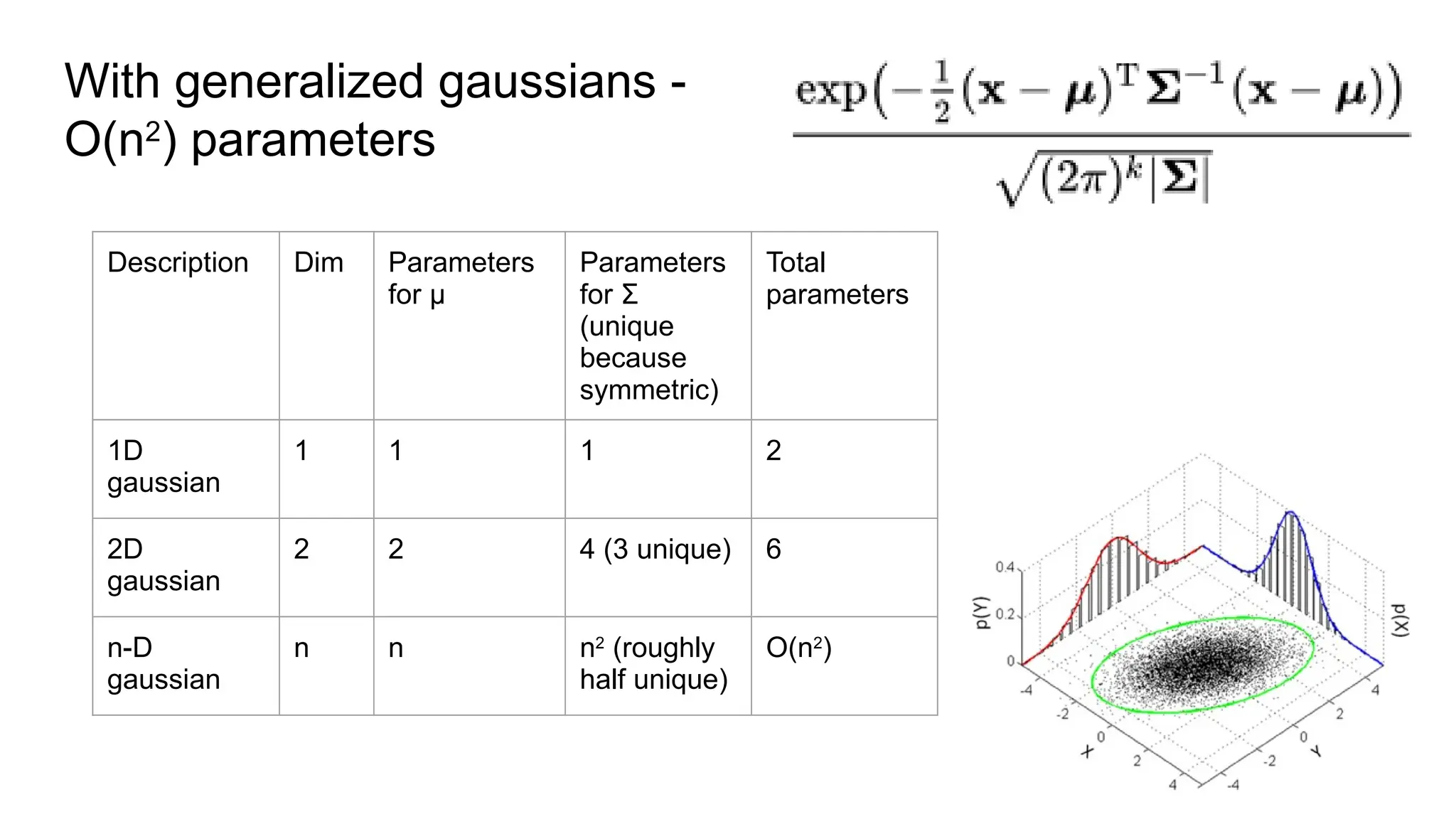
The document discusses various supervised machine learning techniques including k-nearest neighbors, naive Bayes, linear regression, and logistic regression, highlighting their functions, advantages, and applications in predictive modeling. It further elaborates on regularized regression methods such as ridge and lasso, emphasizing their utility in feature selection and handling overfitting. Additionally, the document presents the significance of generalized linear models and the implications of dimensionality in relation to the number of parameters needed for effective learning.