Download to read offline











![References
[1]
I. Anderouysopoulos, J. Koutsias, K.V. Chandrianos, G. Paliouras, C. SpyrpolousAn evaluation of naïve
Bayesian anti-spam filtering
Proceeding of 11th Euro Conference on Match Learn (2000)
[2]
I. Anderouysopoulos, J. Koutsias, K.V. Chandrianos, G. Paliouras, C. SpyrpolousAn experimental comparison of
naïve Bayesian and keyword-based anti-spam filtering with personal e-mail messages
Proceeding of the an International ACM SIGIR Conference on Res and Devel in Inform Retrieval (2000)
[3]
A. Asuncion, D. NewmanUCI Machine Learning Repository
(2007)
http://www.ics.uci.edu/mlearn/MLRRepository.html
[4]
E. Blanzieri, A. BrylA Survey of Learning-based Techniques of Email Spam Filtering Tech. Rep
DIT-06-056
University of Trento, Information Engineering and Computer Science Department (2008)
[5]
J. Clark, I. Koprinska, J. PoonA neural network-based approach to automated email classification
Proceeding of the IEEE/WIC International Conference on Web Intelligence (2003)
[6]
S.J. Delany, D. BridgeTextual case-based reasoning for spam filtering: a comparison of feature-based and
feature-free approaches
Artif. Intell. Rev., 26 (1–2) (2006), pp. 75-87
CrossRefView Record in Scopus
[7]
F. Fdez Riverola, E. Iglesias, F. Diaz, J.R. Mendez, J.M. ChorchodoSpam hunting: an instance-based reasoning
system for spam labeling anf filtering
Decis. Support Syst., 43 (3) (2007), pp. 722-736
ArticlePDF (492KB)View Record in Scopus
[8]
A. SeewaldAn evaluation of Naïve Bayes variants in content-based learning for spam filtering
Intell. Data Anal. (2009)
[9]
Ahmed KhorsiAn overview of content-based spam filtering techniques
Informatica, 31 (3) (October 2007), pp. 269-277
View Record in Scopus](https://image.slidesharecdn.com/machinelearning-180111174216/85/Machine-learning-15-320.jpg)

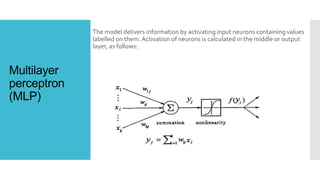
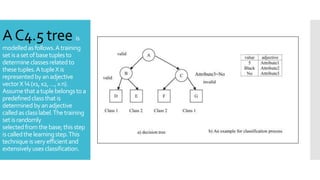
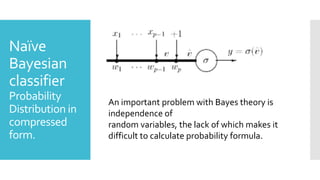
The document proposes an efficient algorithm using machine learning techniques to filter electronic spam, which poses significant challenges for major companies due to its economic impact and resource consumption. Three machine-learning algorithms including multilayer perceptron, decision tree classifier, and naïve Bayes are discussed for their low error rates and high effectiveness in distinguishing spam from valid emails. The study evaluates the classifiers' accuracy based on factors like valid recognition rate and false positive rates, concluding that the multilayer perceptron outperforms the others in efficiency.



































































