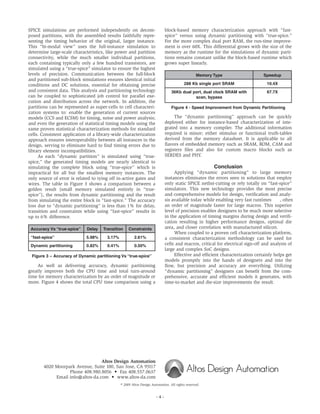
This document discusses challenges with characterizing high-performance memories and proposes a new "dynamic partitioning" approach. Existing approaches like block-based or static path characterization have accuracy issues and slow runtimes for large memories. Dynamic partitioning leverages full-instance simulation to identify critical paths and partition them for precise "true-spice" simulation, improving accuracy to <1% while speeding up runtimes over 10x. This approach provides comprehensive, precise models needed for advanced memories without slowing down characterization.