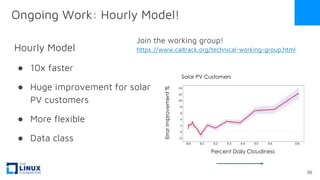
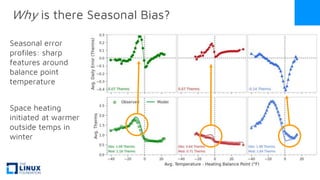
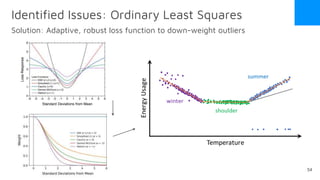
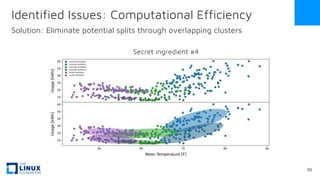
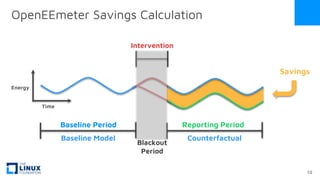
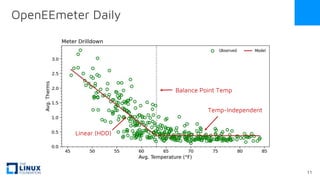
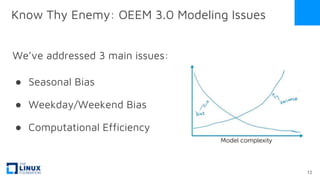
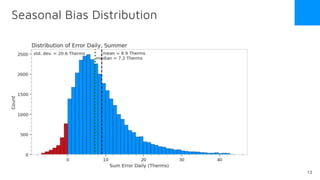
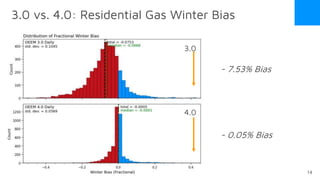
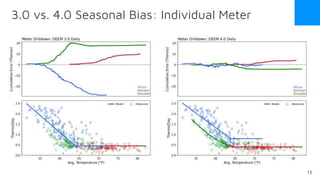
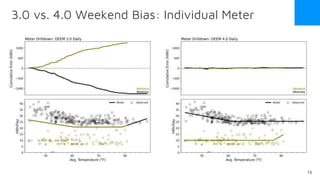
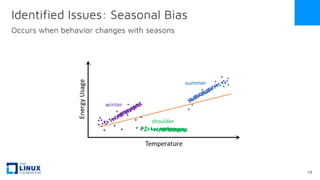
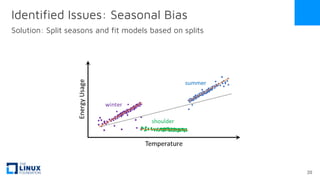
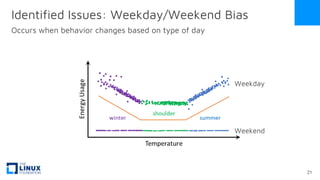
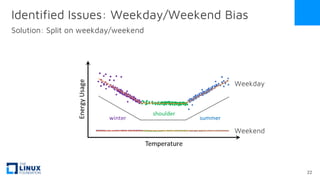
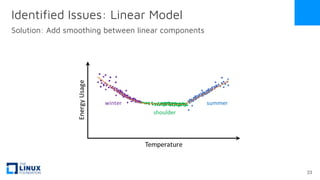
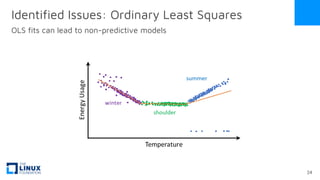
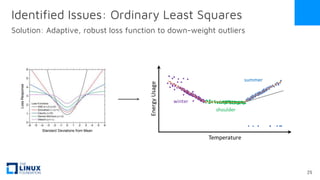
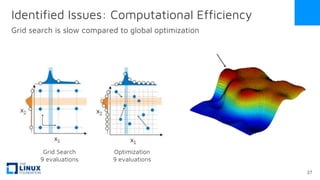
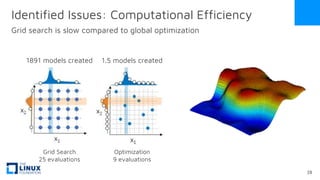
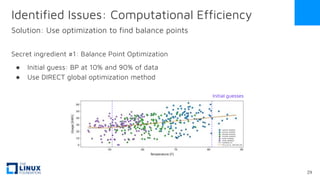
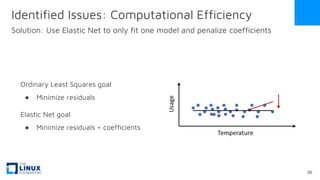
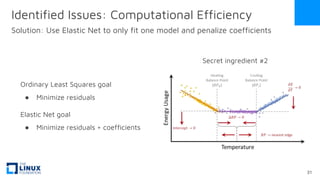
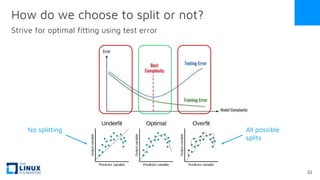
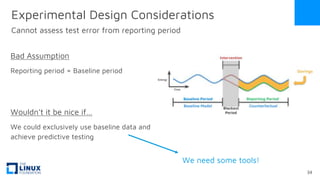
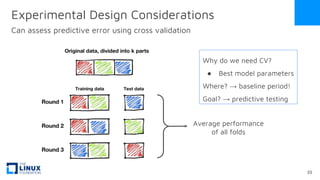
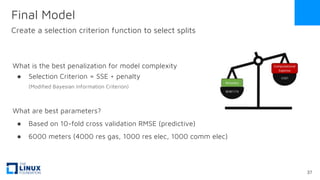
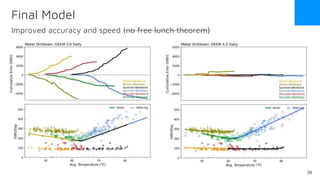
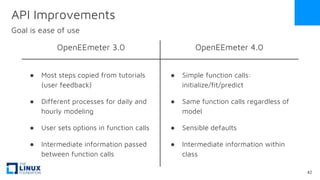
The document discusses the release of OpenEemeter 4.0, emphasizing its compliance with antitrust regulations and improvements in measurement accuracy and computational efficiency over version 3.0. Key advancements include significant reductions in seasonal and weekday/weekend biases, along with enhanced API functionality for ease of use. It also highlights the ongoing development of an hourly model and invites industry participation in the technical working group.
















![API Improvements
Inspired by Sklearn’s simplicity
● Sklearn manages many complex models with a simple interface
● We should do the same
cluster_algo = [
cluster.MiniBatchKMeans(),
cluster.AgglomerativeClustering(),
cluster.Birch(),
cluster.DBSCAN(),
]
for algo in cluster_algo:
algo.fit(X)
res = algo.predict(X_new)
regres_algo = [
linear_model.LinearRegression(),
linear_model.ElasticNet(),
linear_model.BayesianRidge(),
linear_model.RANSACRegressor(),
]
for algo in regres_algo:
algo.fit(X, y)
res = algo.predict(X_new)
Clustering API Regression API
Completely
different, but
almost same
API?
41](https://image.slidesharecdn.com/lfeoeem4webinar-240312195657-93909485/85/LF-Energy-Webinar-Unveiling-OpenEEMeter-4-0-41-320.jpg)


![Data Class
Tracks disqualification and formats data for Model class
● Track all data sufficiency
● Unique for each model type
● Must be run to pass to Model
(Can bypass in model)
● Formats data for Model class
● Violations are propagated to
Model class
baseline_data = BaselineData(baseline_df)
baseline_data.disqualification
baseline_data.warnings
Disqualification -
{
'qualified_name':
'eemeter.sufficiency_criteria.too_many_days_with_missing_data',
'description': 'Too many days in data have missing meter data or
temperature data.',
'data': {'n_valid_days': 251, 'n_days_total' : 365}}
}
Warnings -
{'qualified_name':
'eemeter.sufficiency_criteria.missing_high_frequency_meter_data',
'description': 'More than 50% of the high frequency Meter data is
missing.',
'data': [Timestamp('2020-02-29 00:00:00+0000', tz='UTC')]
}
45](https://image.slidesharecdn.com/lfeoeem4webinar-240312195657-93909485/85/LF-Energy-Webinar-Unveiling-OpenEEMeter-4-0-45-320.jpg)