Download as PDF, PPTX





















![37
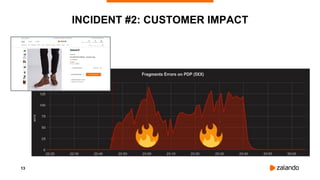
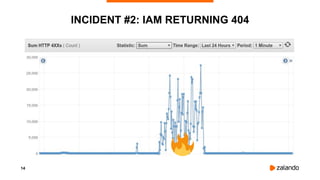
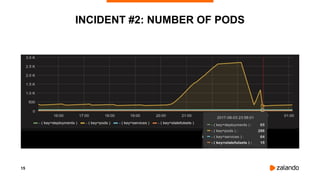
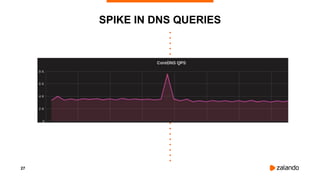
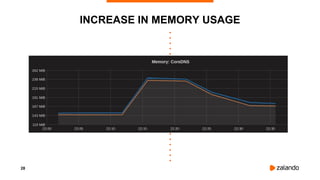
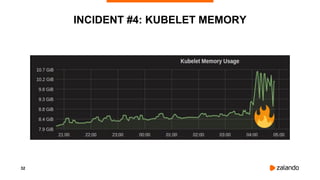
INCIDENT #5: CREDENTIALS QUEUE
17:30:07 | [pool-6-thread-1 ] | Current queue size: 7115, current number of active workers: 20
17:31:07 | [pool-6-thread-1 ] | Current queue size: 7505, current number of active workers: 20
17:32:07 | [pool-6-thread-1 ] | Current queue size: 7886, current number of active workers: 20
..
17:37:07 | [pool-6-thread-1 ] | Current queue size: 9686, current number of active workers: 20
..
17:44:07 | [pool-6-thread-1 ] | Current queue size: 11976, current number of active workers: 20
..
19:16:07 | [pool-6-thread-1 ] | Current queue size: 58381, current number of active workers: 20](https://image.slidesharecdn.com/2019-02-11kubernetesfailurestories-hamburgmeetup-190212085340/85/Let-s-talk-about-Failures-with-Kubernetes-Hamburg-Meetup-37-320.jpg)


![41
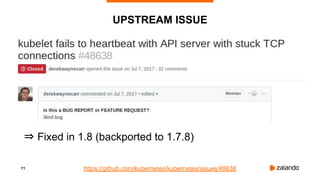
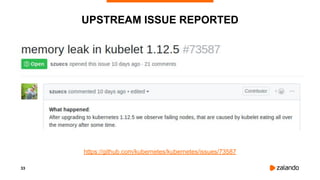
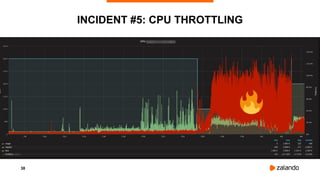
DISABLING CPU THROTTLING
[Announcement] CPU limits will be disabled
⇒ Ingress Latency Improvements
kubelet … --cpu-cfs-quota=false](https://image.slidesharecdn.com/2019-02-11kubernetesfailurestories-hamburgmeetup-190212085340/85/Let-s-talk-about-Failures-with-Kubernetes-Hamburg-Meetup-41-320.jpg)










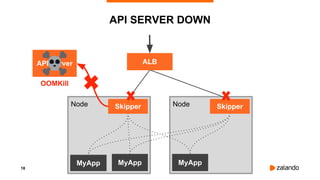
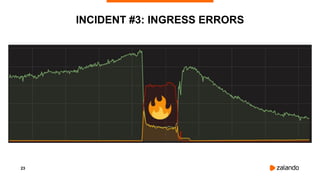
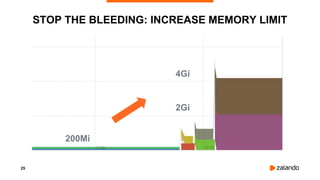
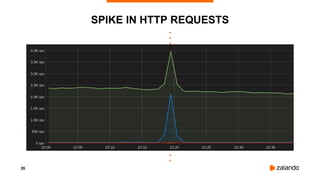
The document presents Kubernetes failure stories from Zalando, highlighting incidents involving node availability, customer impact, and resource management issues. Specific examples illustrate the causes of failures, such as misconfigured cron jobs and memory limits, as well as the steps taken to resolve these issues. It concludes by questioning the reliability of managed Kubernetes services and providing resources for production proofs in AWS EKS.








































![[k8s] Kubernetes terminology (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/k8skubernetesterminology1-230513211357-e2d31a79-thumbnail.jpg?width=640&height=640&fit=bounds)





































