Training data vsTesting data
• There are two key types of data used for machine learning
training and testing data.
• They each have a specific function to perform when building
and evaluating machine learning models.
• Machine learning algorithms are used to learn from data in
datasets.
• They discover patterns and gain knowledge, make choice
and examine those decisions.
3.
Training and TestingPhases
• Training Phase: The stage where a model learns from data
to recognize patterns.
• Testing Phase: The stage where the model's accuracy is
evaluated using new data.
• We understand this with a generalized Model.
• Lets take a small dataset to understand this concept.
5.
Training Phase
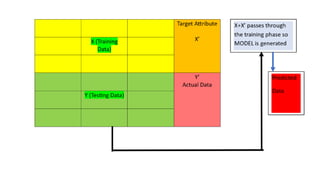
• Feedfeatures (X) and target (X’) into the model
• Model learns patterns and relationships between X and X’
• Output: A trained model capable of making predictions
• Example: A teacher teaching students by providing
examples and explanations
• To Minimize errors during training to build a reliable model
6.
Testing Phase
• Itspurpose is to evaluate model accuracy with new/unseen
data/
• Provide only features (X) to the model.
• Model generates predicted data.
• Compare predicted outputs with actual outputs (Y)
• The difference between predicted and actual values is called
Error Margin.
• A lower error margin indicates a more accurate model.
7.
Difference between Trainingdata and Testing data
Features Training Data Testing Data
Purpose The machine-learning model is trained
using training data. The more training
data a model has, the more accurate
predictions it can make.
Testing data is used to evaluate the
model's performance.
Exposure By using the training data, the model
can gain knowledge and become more
accurate in its predictions.
Until evaluation, the testing data is not
exposed to the model. This guarantees
that the model cannot learn the testing
data by heart and produce flawless
forecasts.
Distribution This training data distribution should
be similar to the distribution of actual
data that the model will use.
The distribution of the testing data and
the data from the real world differs
greatly.
Use To stop overfitting, training data is
utilized.
By making predictions on the testing
data and comparing them to the actual
labels, the performance of the model is
8.
Underfitting and Overfitting
•Machine learning models aim to perform well on both
training data and new unseen data and is considered “good”
if:
1. It learns patterns effectively from the training data.
2. It generalizes well to new, unseen data.
3. It avoids memorizing the training data (overfitting) or
failing to capture relevant patterns (underfitting).
9.
Underfitting in MachineLearning
Underfitting is the opposite of overfitting. It happens when a
model is too simple to capture what’s going on in the data.
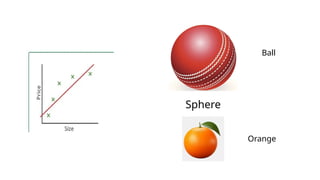
• For example, imagine drawing a straight line to fit points
that actually follow a curve. The line misses most of the
pattern.
• In this case, the model doesn’t work well on either the
training or testing data.
• Underfitting models are like students who don’t study
enough. They don’t do well in practice tests or real exams
Overfitting in MachineLearning
Overfitting happens when a model learns too much from the
training data, including details that don’t matter (like noise or
outliers).
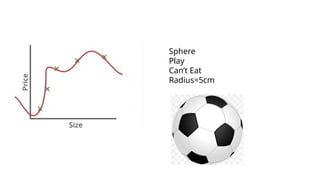
• For example, imagine fitting a very complicated curve to a set of
points. The curve will go through every point, but it won’t
represent the actual pattern.
• As a result, the model works great on training data but fails when
tested on new data.
• Overfitting models are like students who memorize answers
instead of understanding the topic. They do well in practice tests
(training) but struggle in real exams (testing).