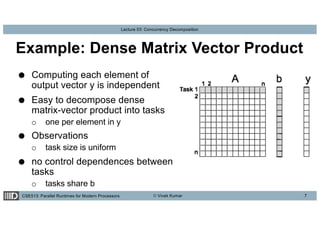
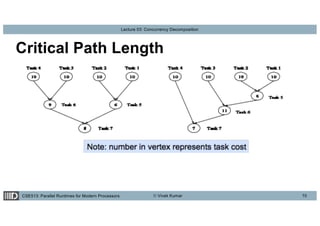
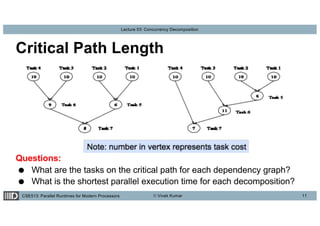
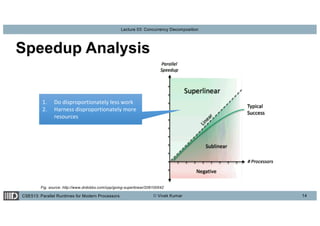
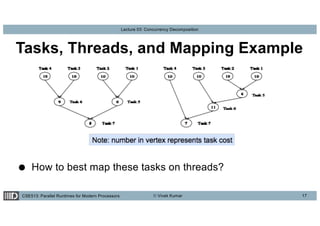
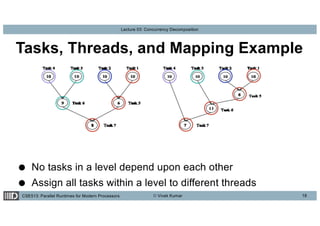
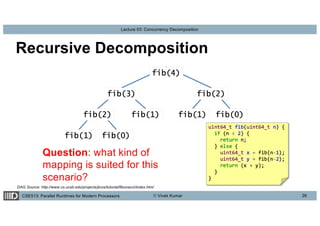
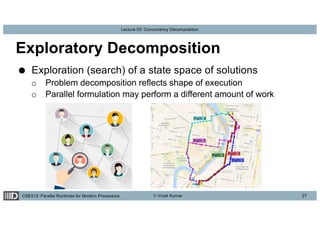
This lecture discusses concurrency decomposition in parallel programming, emphasizing the distinction between concurrency and parallelism, and the methods for decomposing sequential programs into parallel tasks. Key concepts include Amdahl's law, the mapping of tasks to threads, and various decomposition techniques such as data, recursive, exploratory, and speculative decomposition. The importance of task granularity, critical paths, and the influence of overheads on parallel performance are also highlighted.