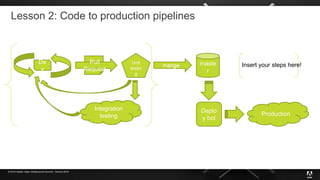
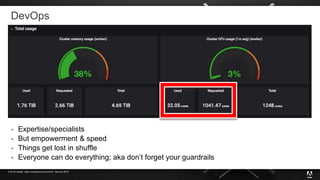
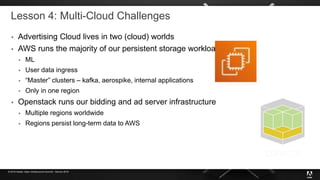
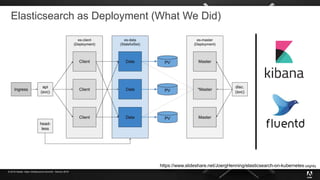
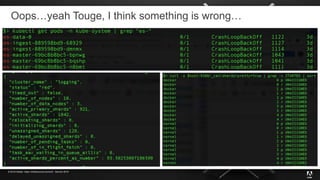
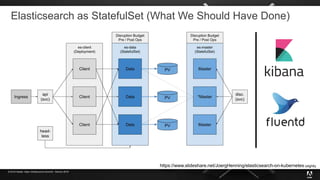
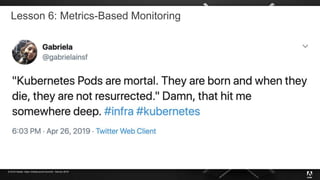
The document presents insights from Adobe's experience using Kubernetes across various data centers, highlighting seven key lessons learned. These include the importance of communication, efficient code production pipelines, understanding application needs, managing multi-cloud challenges, metrics-based monitoring, and the benefits and challenges of autoscaling. Overall, it emphasizes collaboration and continuous improvement within technology teams to enhance deployment processes and operational efficiency.























































![[Rakuten TechConf2014] [F-4] At Rakuten, The Rakuten OpenStack Platform and B...](https://cdn.slidesharecdn.com/ss_thumbnails/f4openstackrakutentechnologyconference20141025-141105211349-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







