Download to read offline


















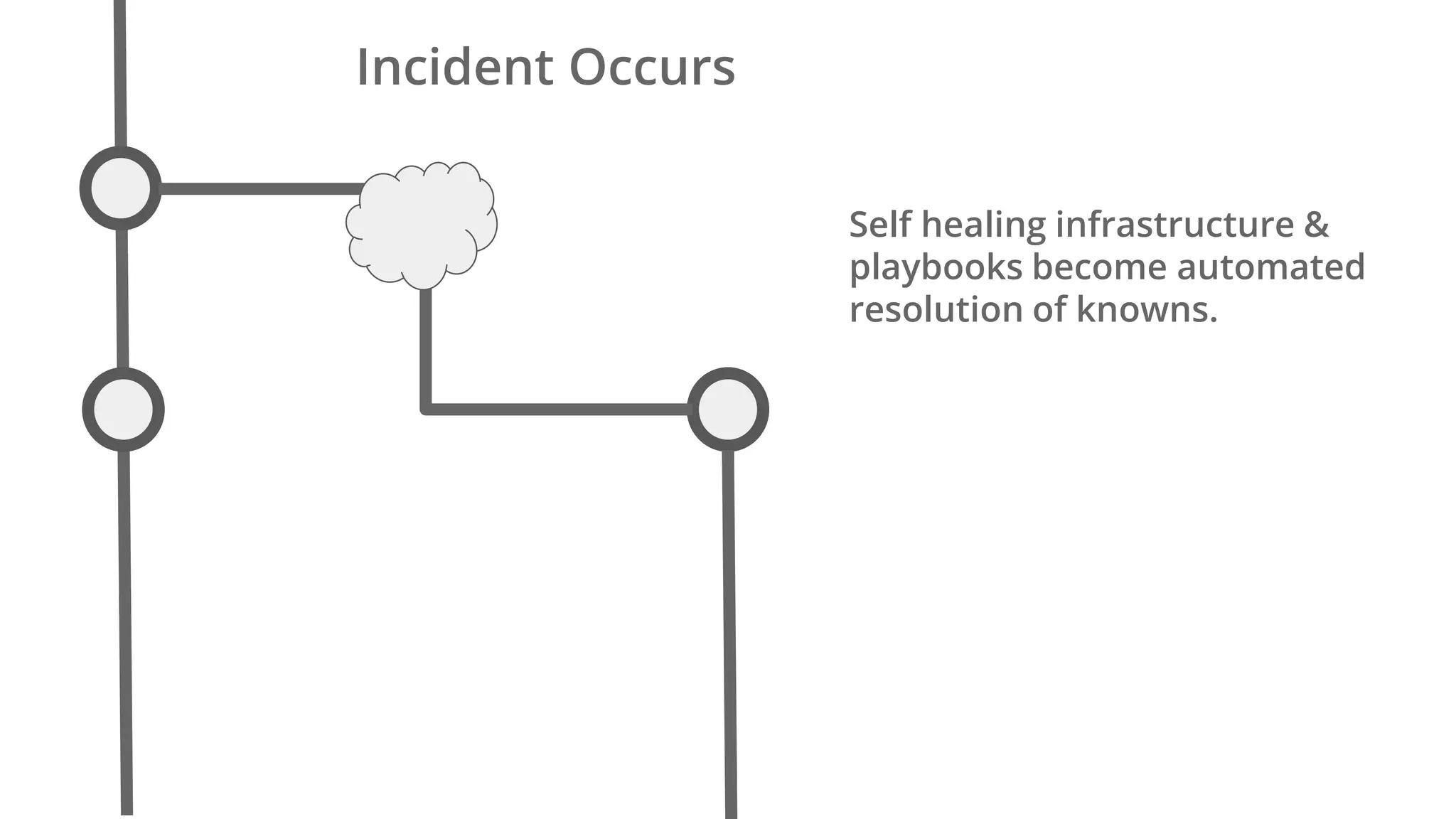

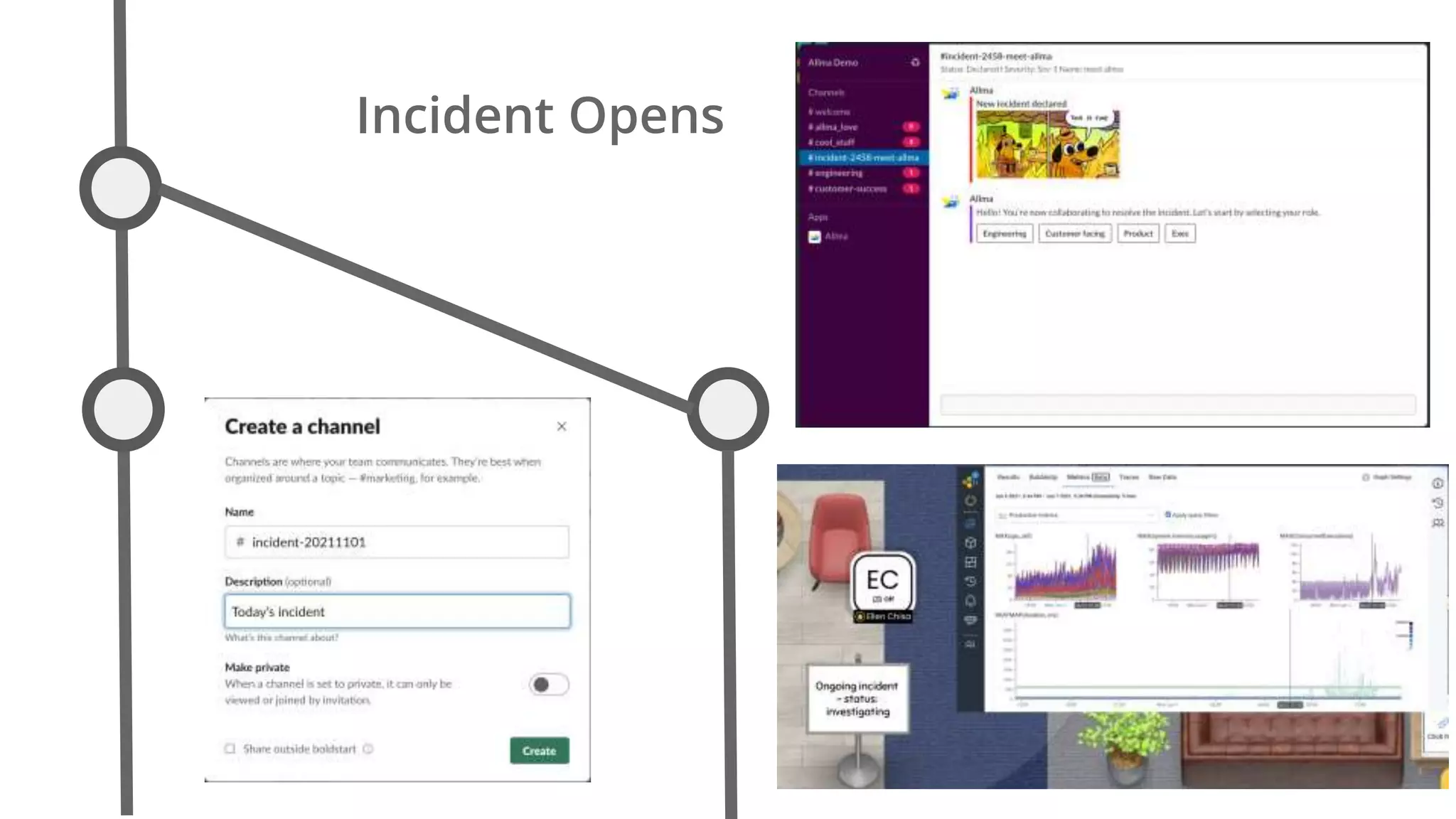
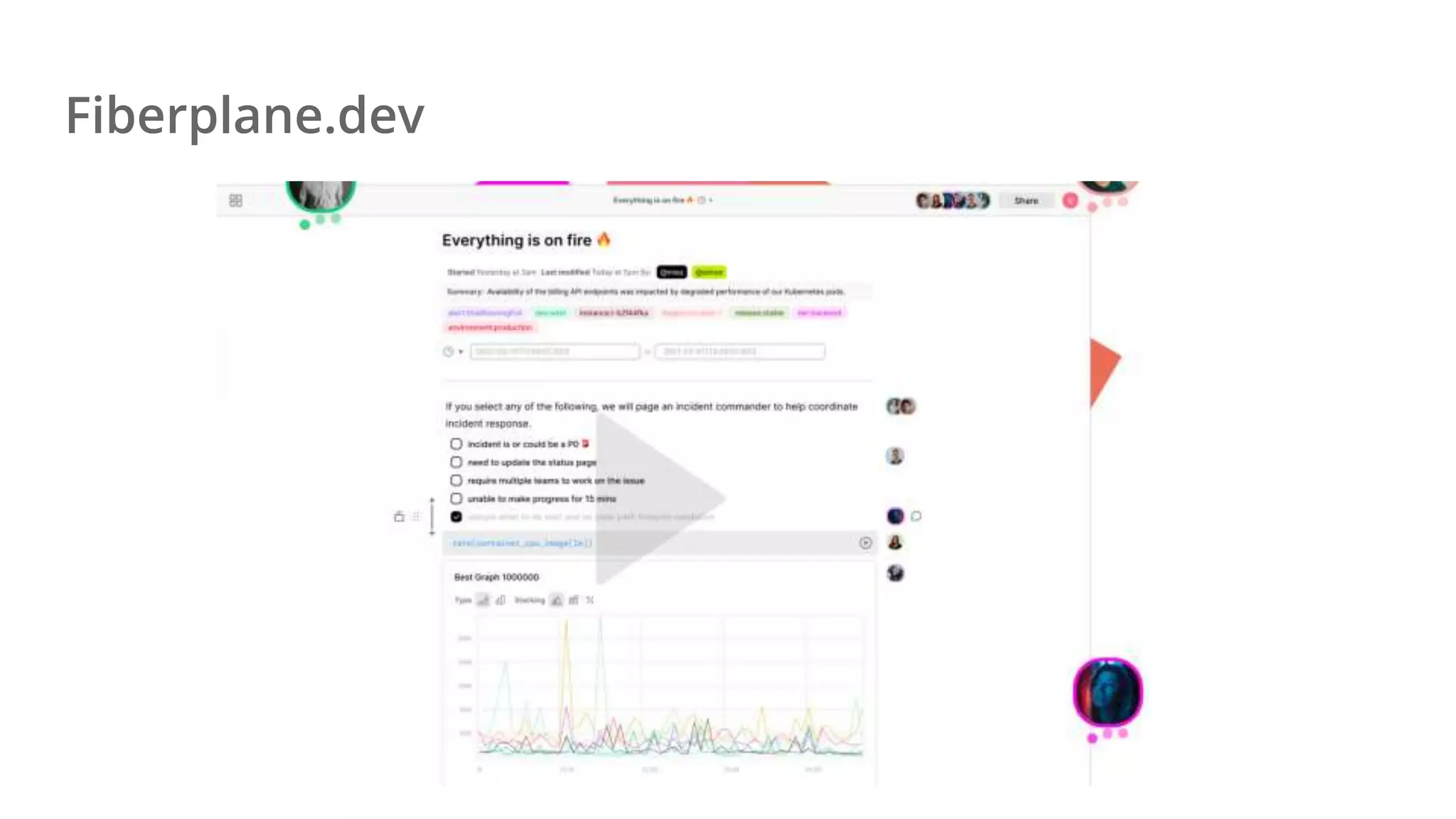
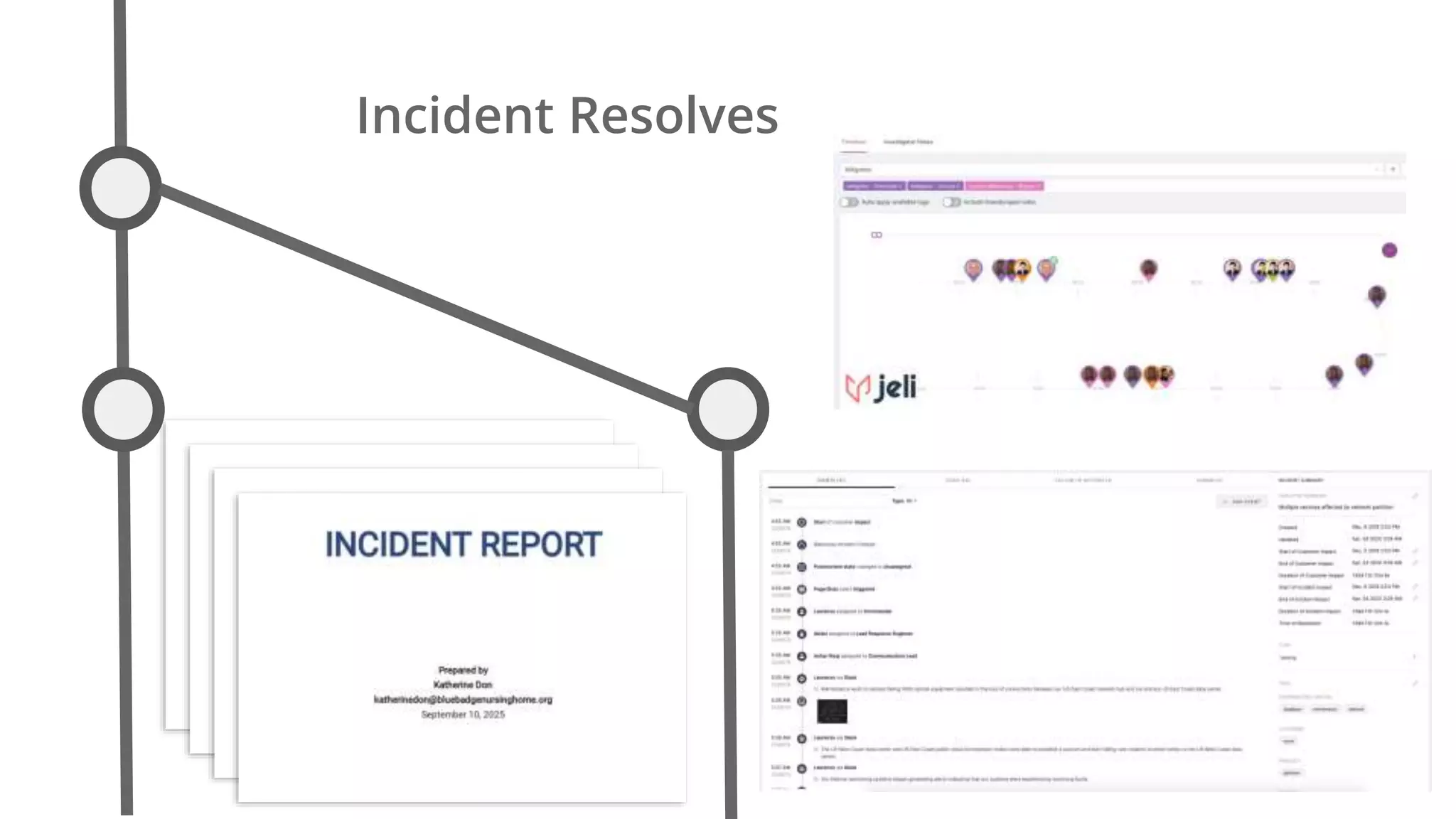


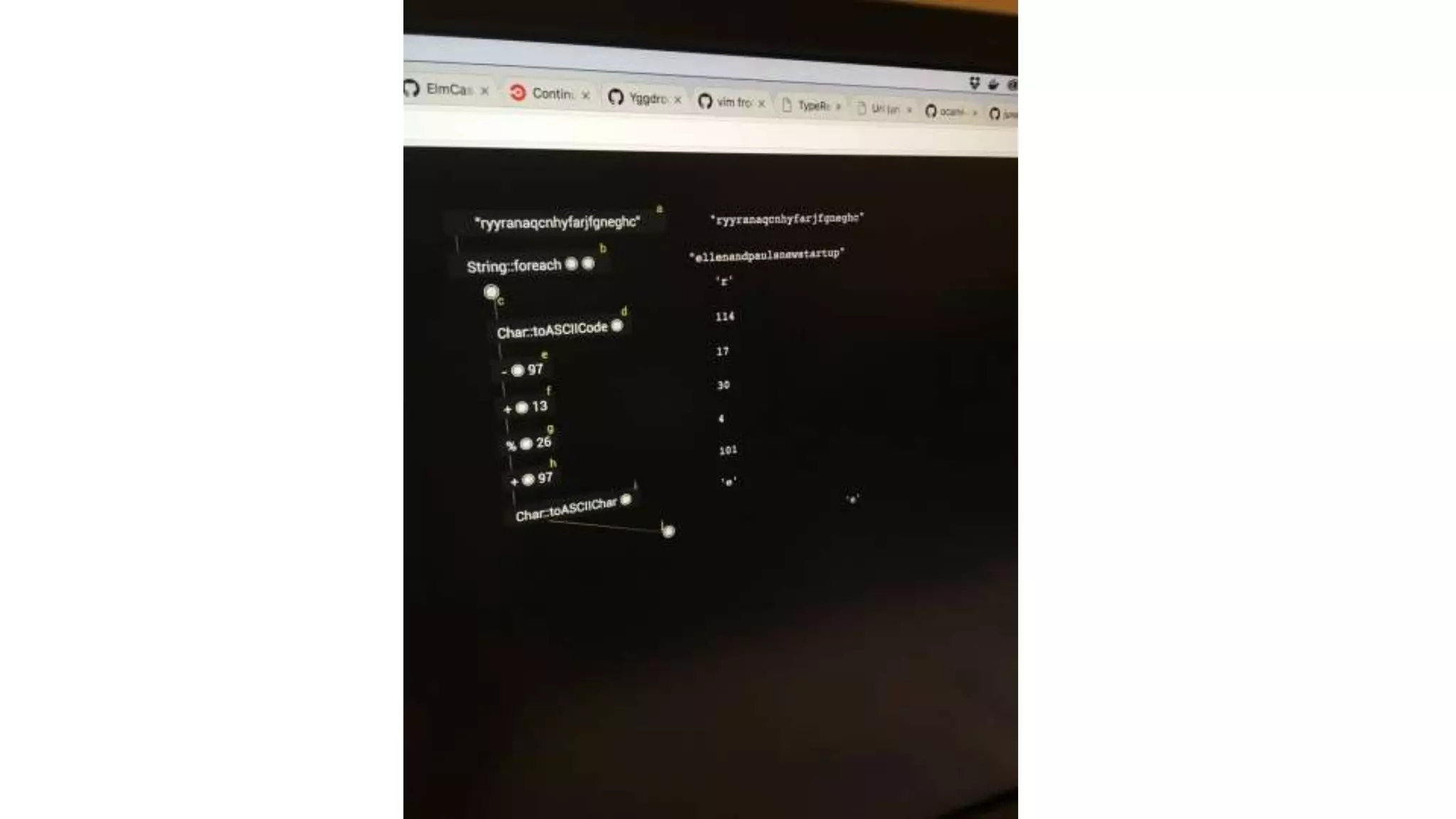
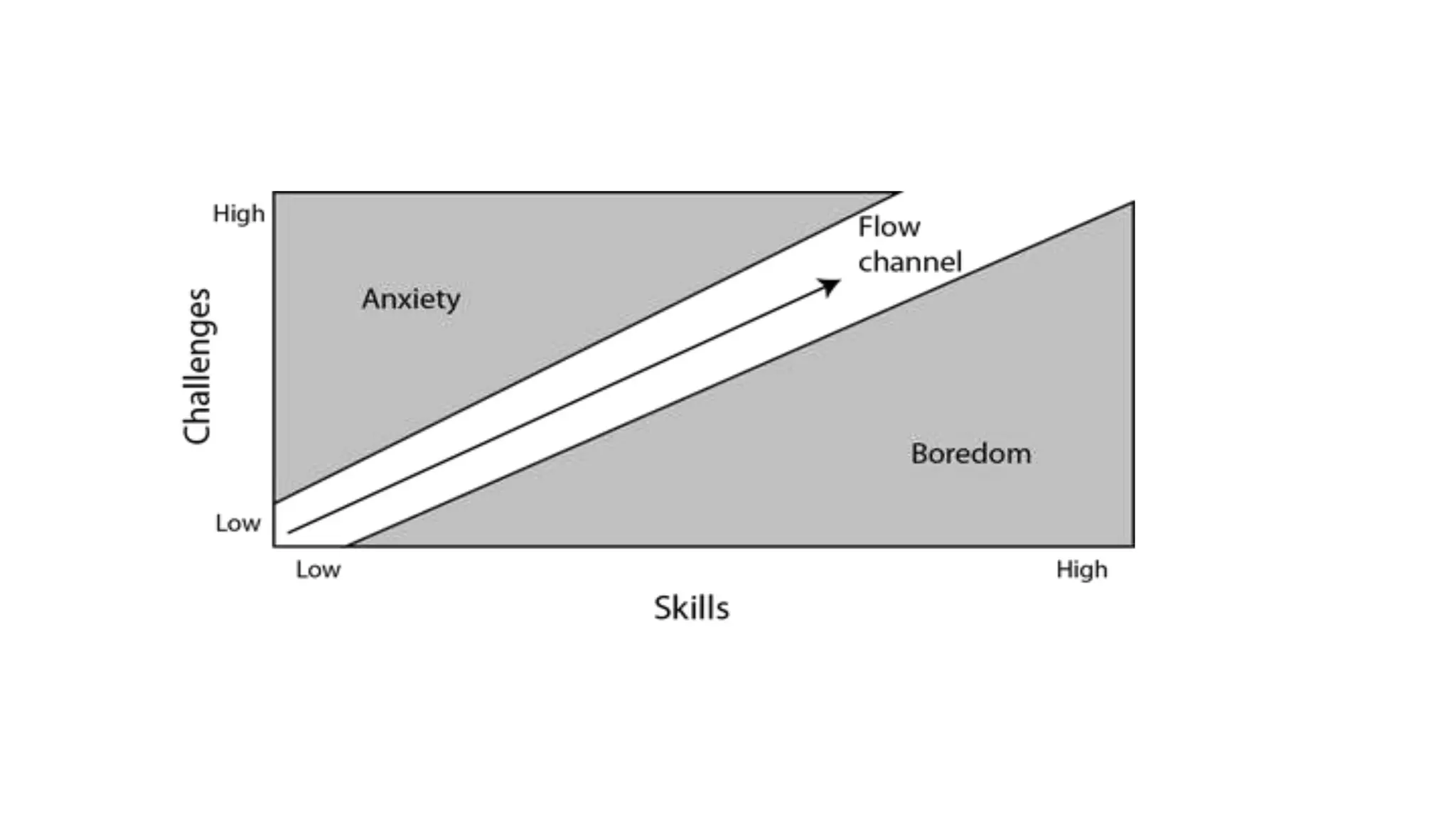

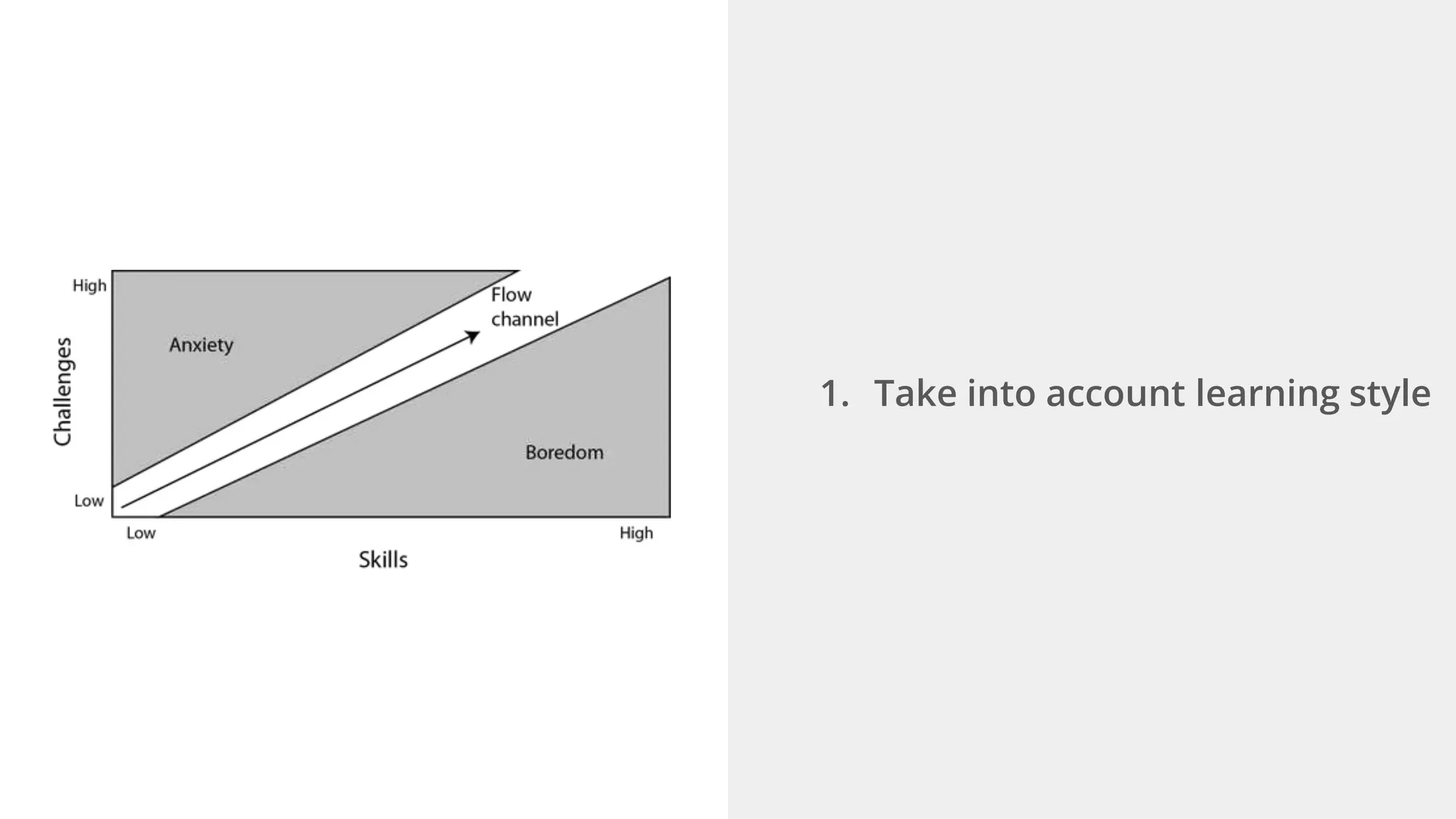
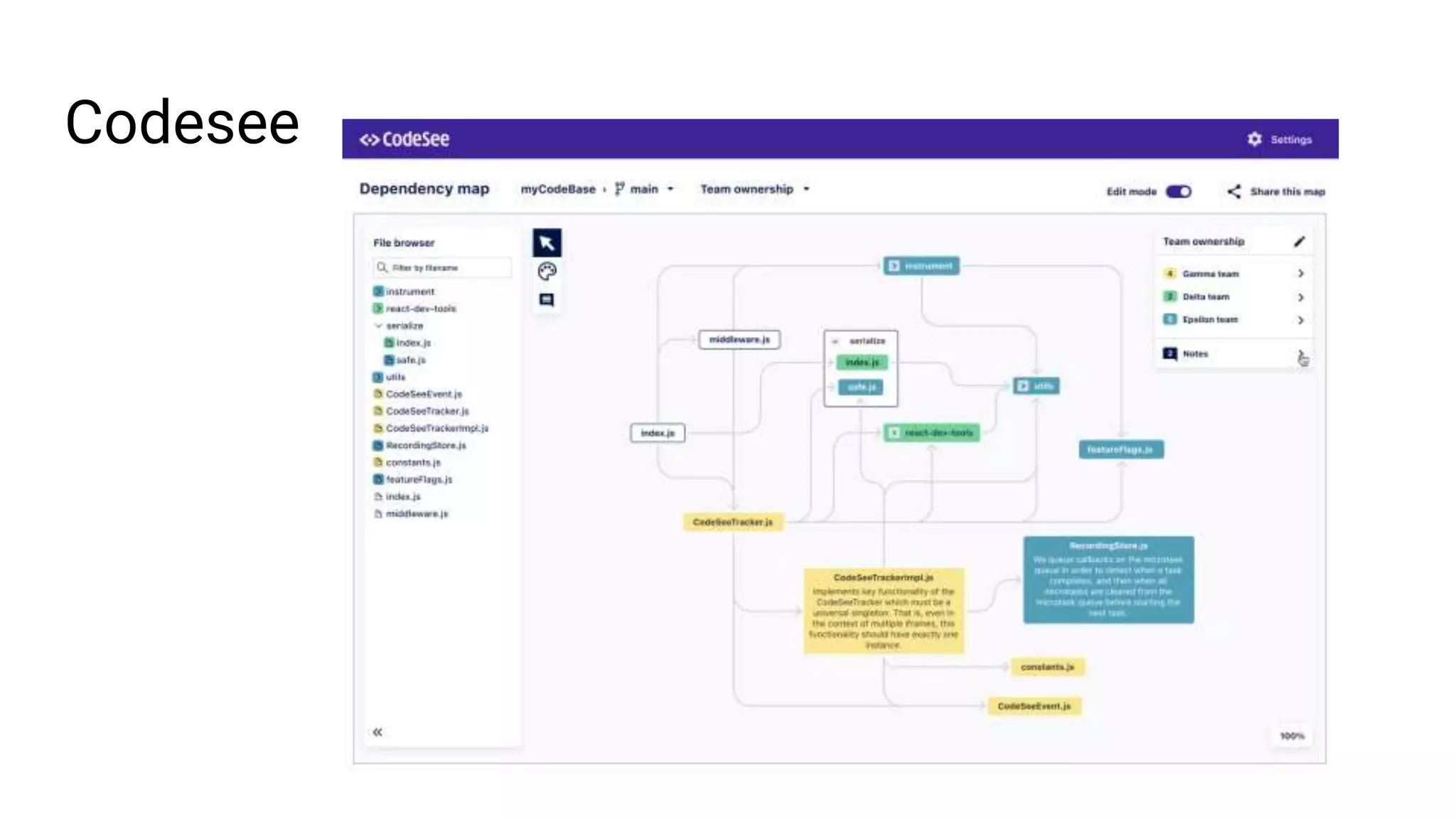
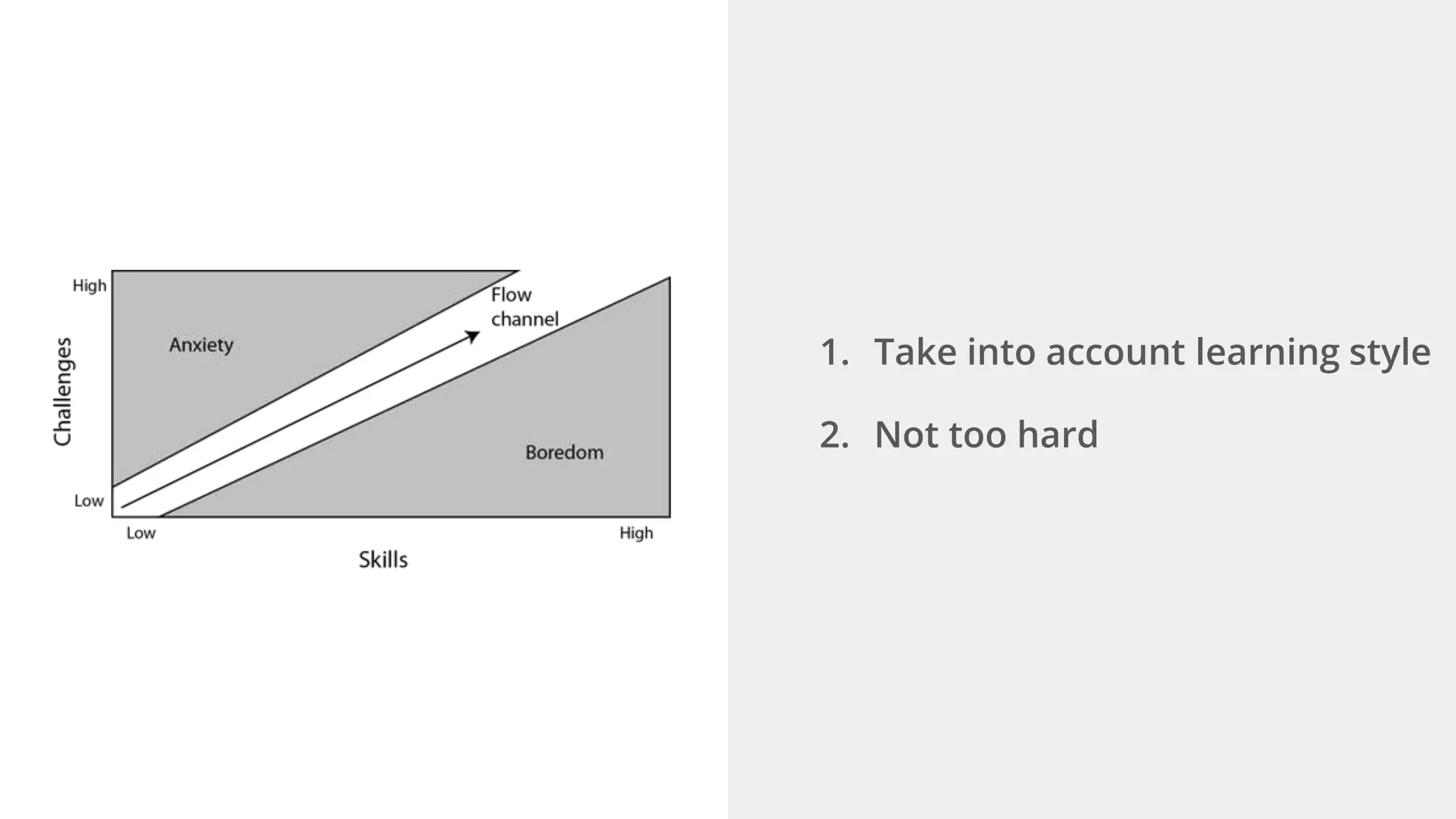
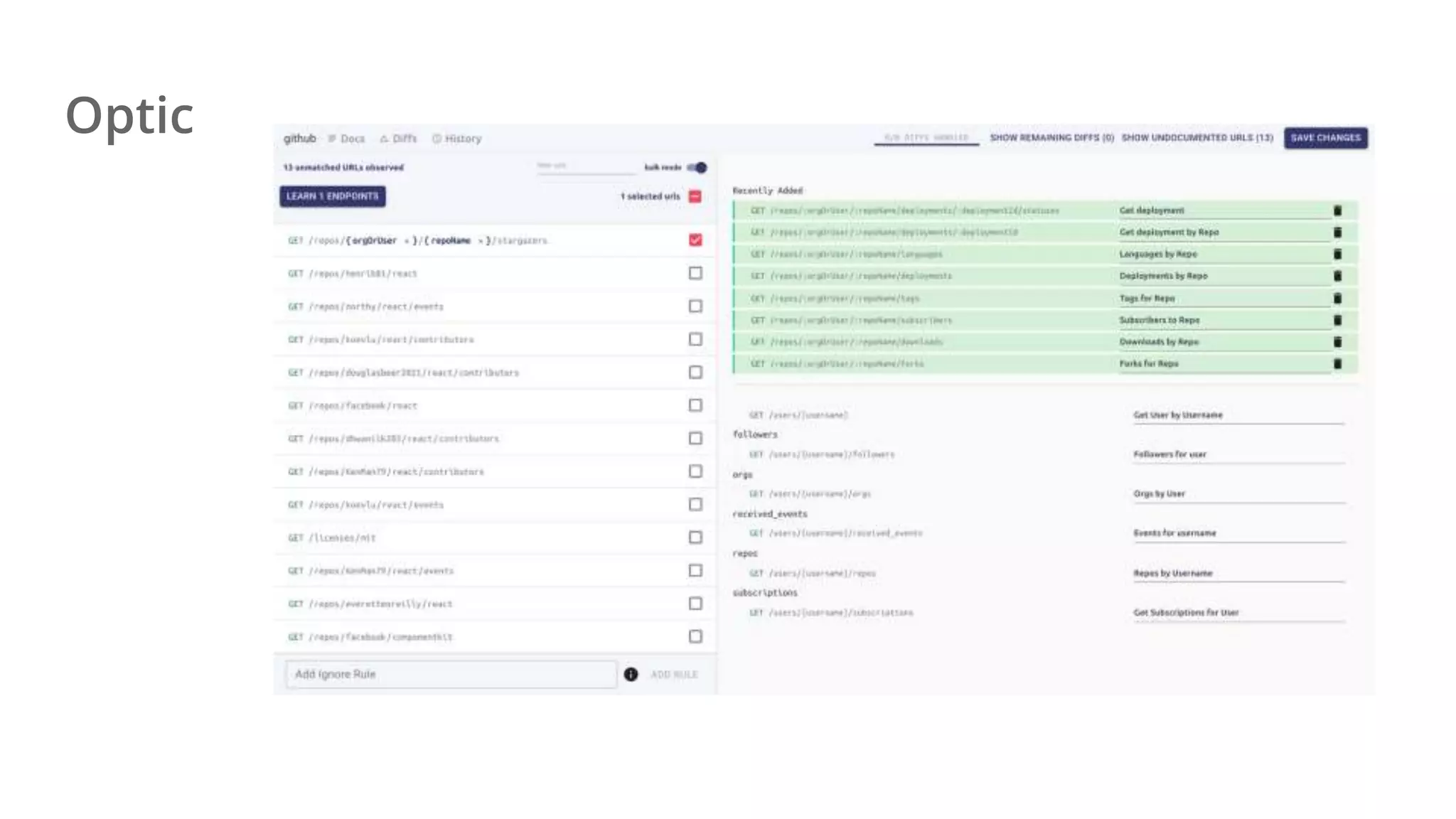
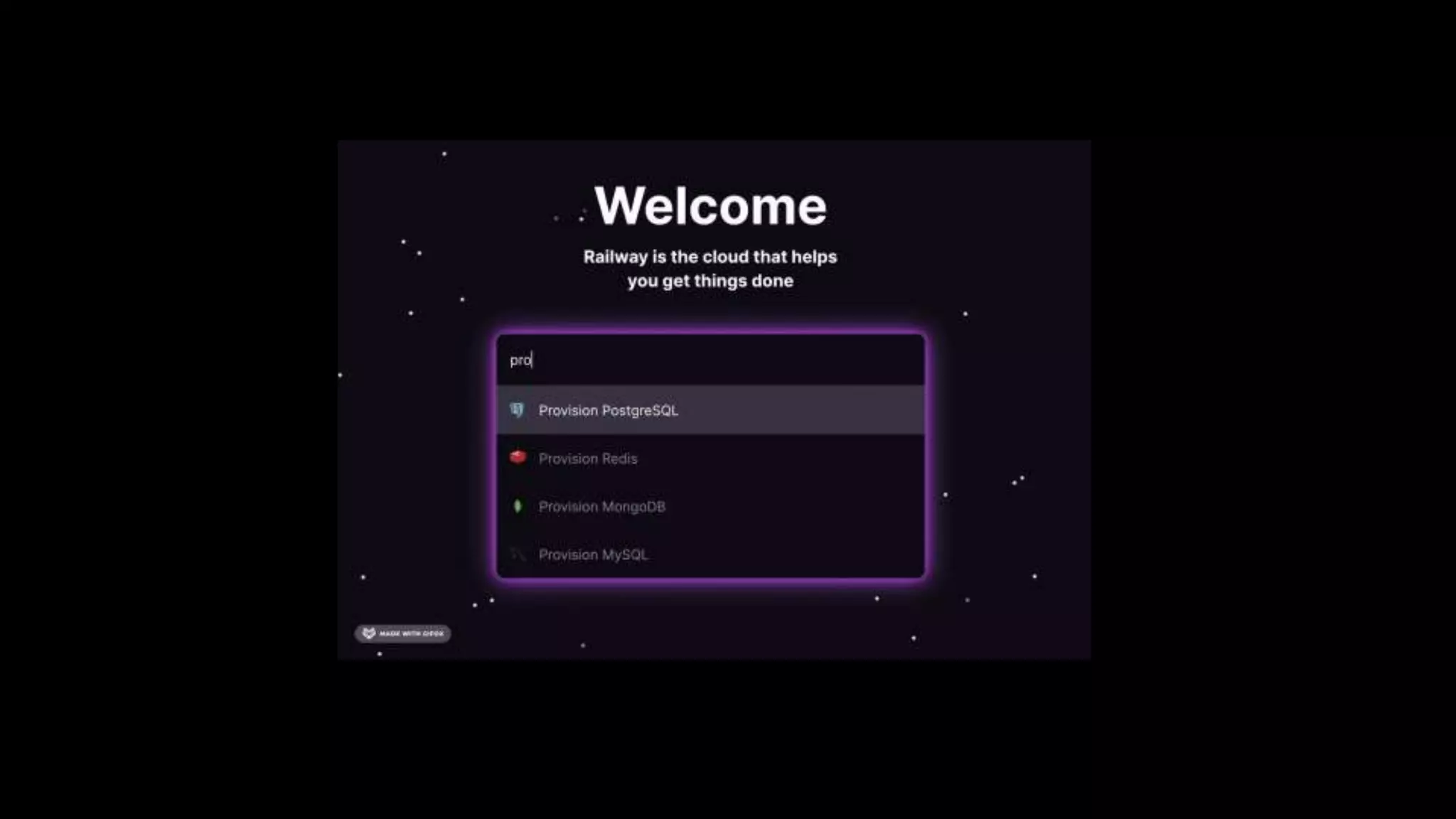
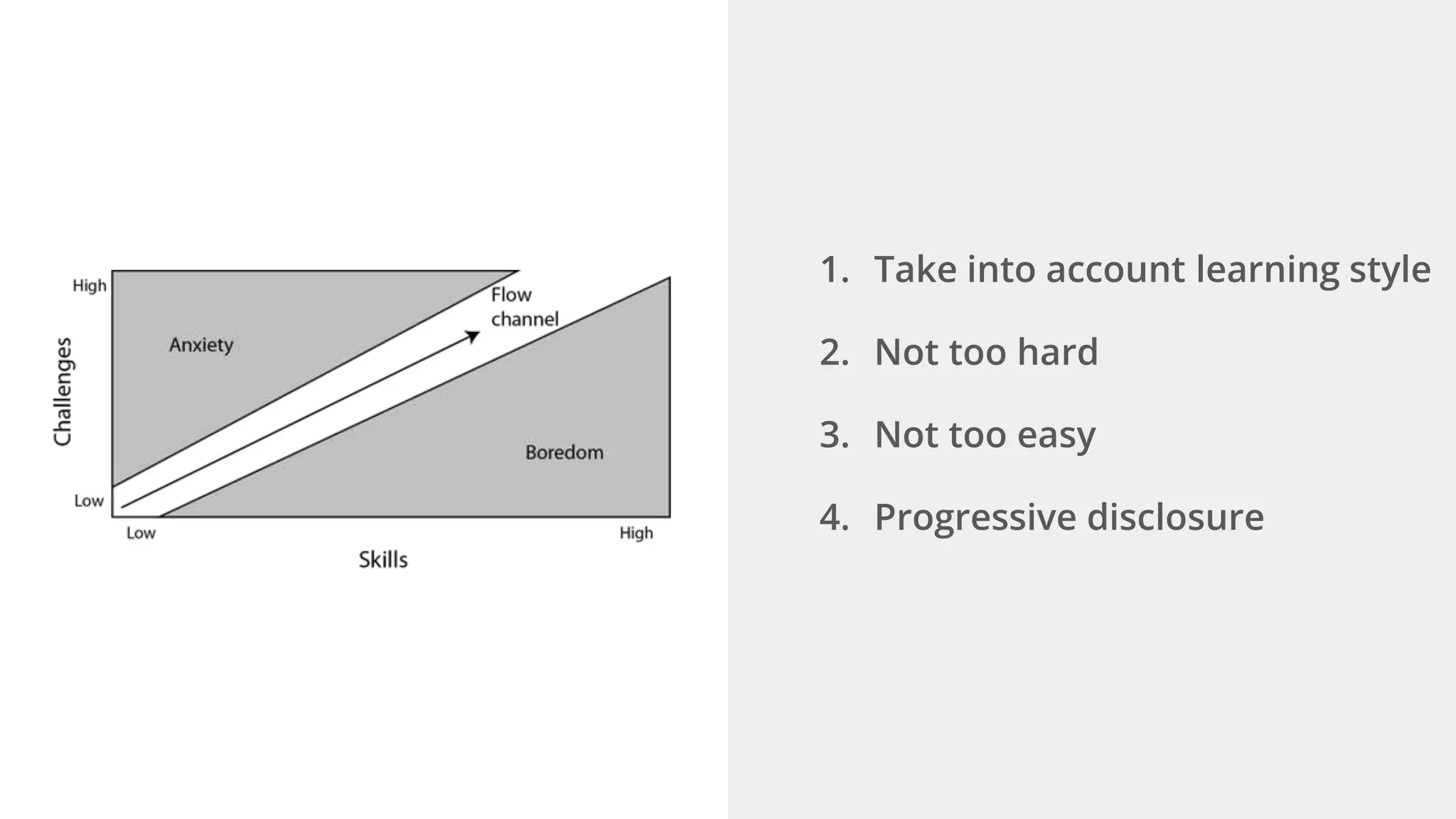

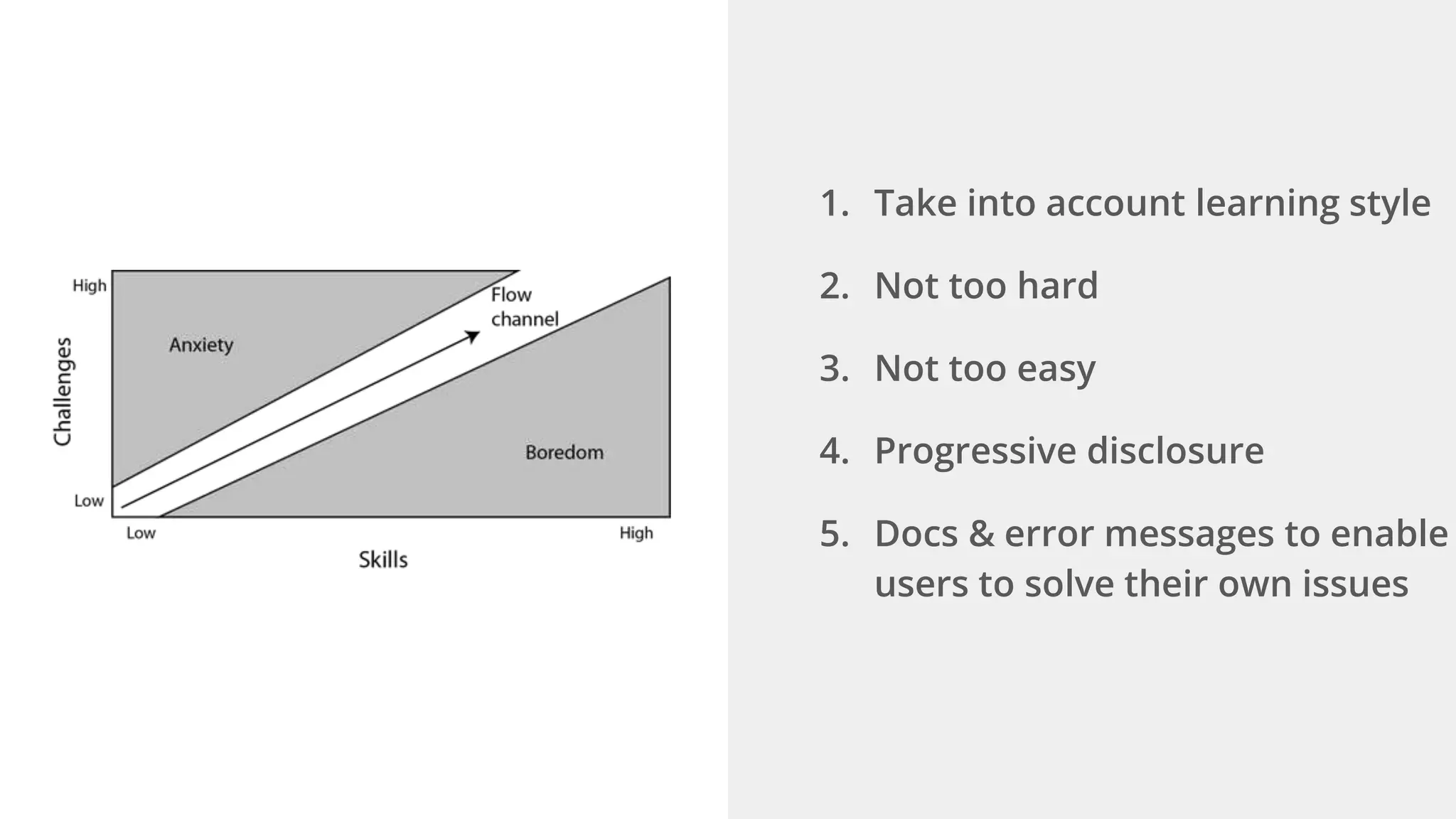

















Ellen Chisa discusses the evolution of DevOps over the next ten years, emphasizing the importance of increasing speed while reducing risk through effective practices and tools. Key strategies include real-time feedback loops, incident infrastructure automation, and an enhanced focus on developer experience. She highlights the necessity for organizational buy-in and business metrics to improve collaboration and resources, ultimately advocating for a future where software development is more efficient and enjoyable.























































































