Integrating advanced text analytics into solr - By Steve Kearns
1.
Integrating Advanced Text
Analytics into Solr
Lucene Revolution
Steve Kearns
Product Manager
www.basistech.com
2.
Agenda
• About BasisTechnology
• Why Text Analytics and Solr?
• Overview and Uses of Text Analytics
• Integration Strategies
3.
About Basis Technology
•HQ in Cambridge, MA, Offices in:
Tokyo, San Francisco, Washington DC
• Specialists in multilingual text analytics for
Web/enterprise search
Document/OSINT/media exploitation
• Rosette Linguistics Platform is widely used by
commercial enterprises and government
agencies
4.
Why Text Analyticsand Solr?
• More than Keyword Search and Result Lists
• More Metadata
New ways to visualize, navigate and explore
New knobs to tune relevance
New info to connect disparate data sources
• Solr can be the consumer, host, or broker
5.
Overview of TextAnalytics
• Document-Level
Language Identification, Categorization
• Sub-Document Level
Entity Extraction, Fact Extraction, Sentiment, Linguistics
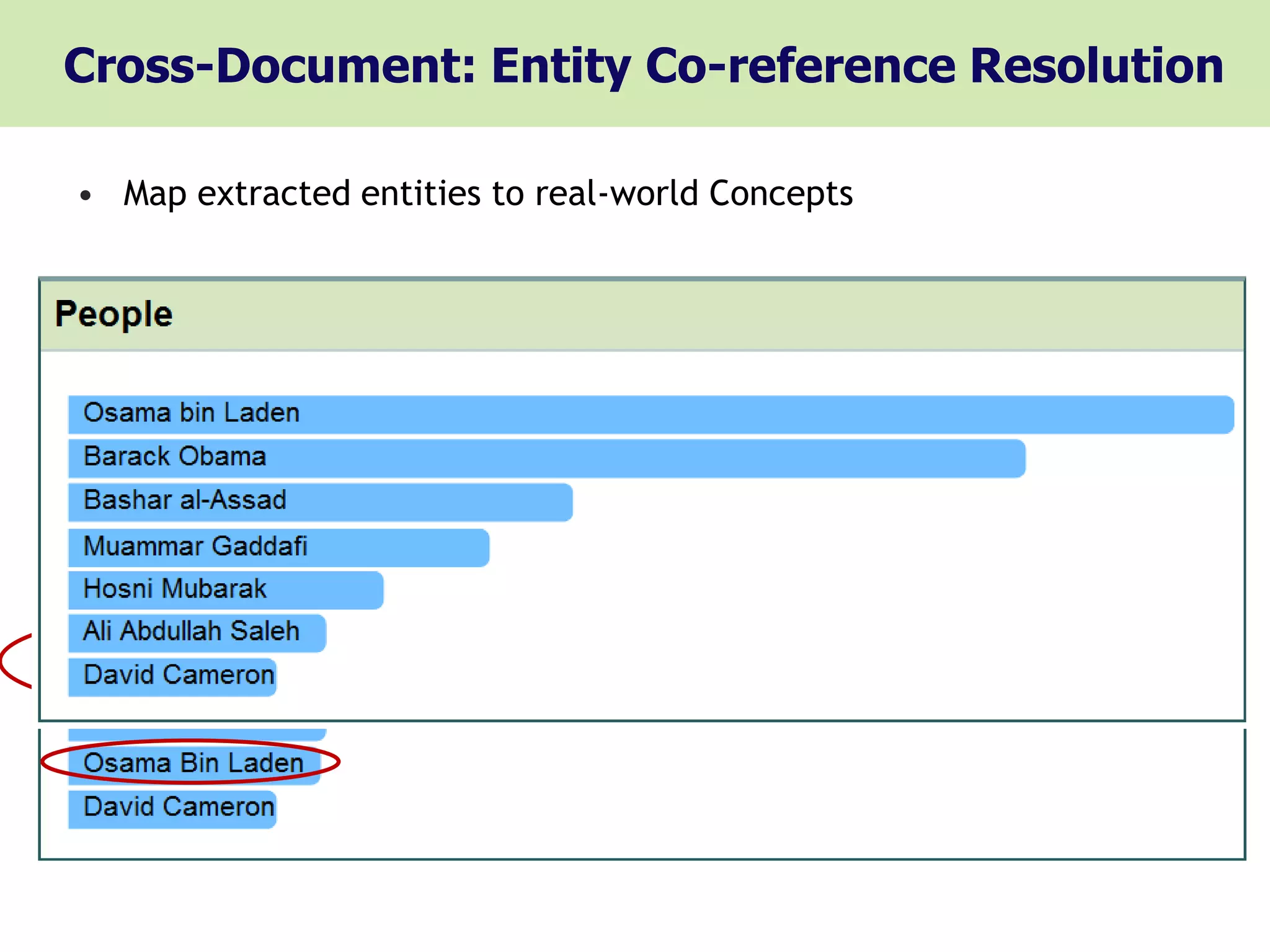
• Cross-Document
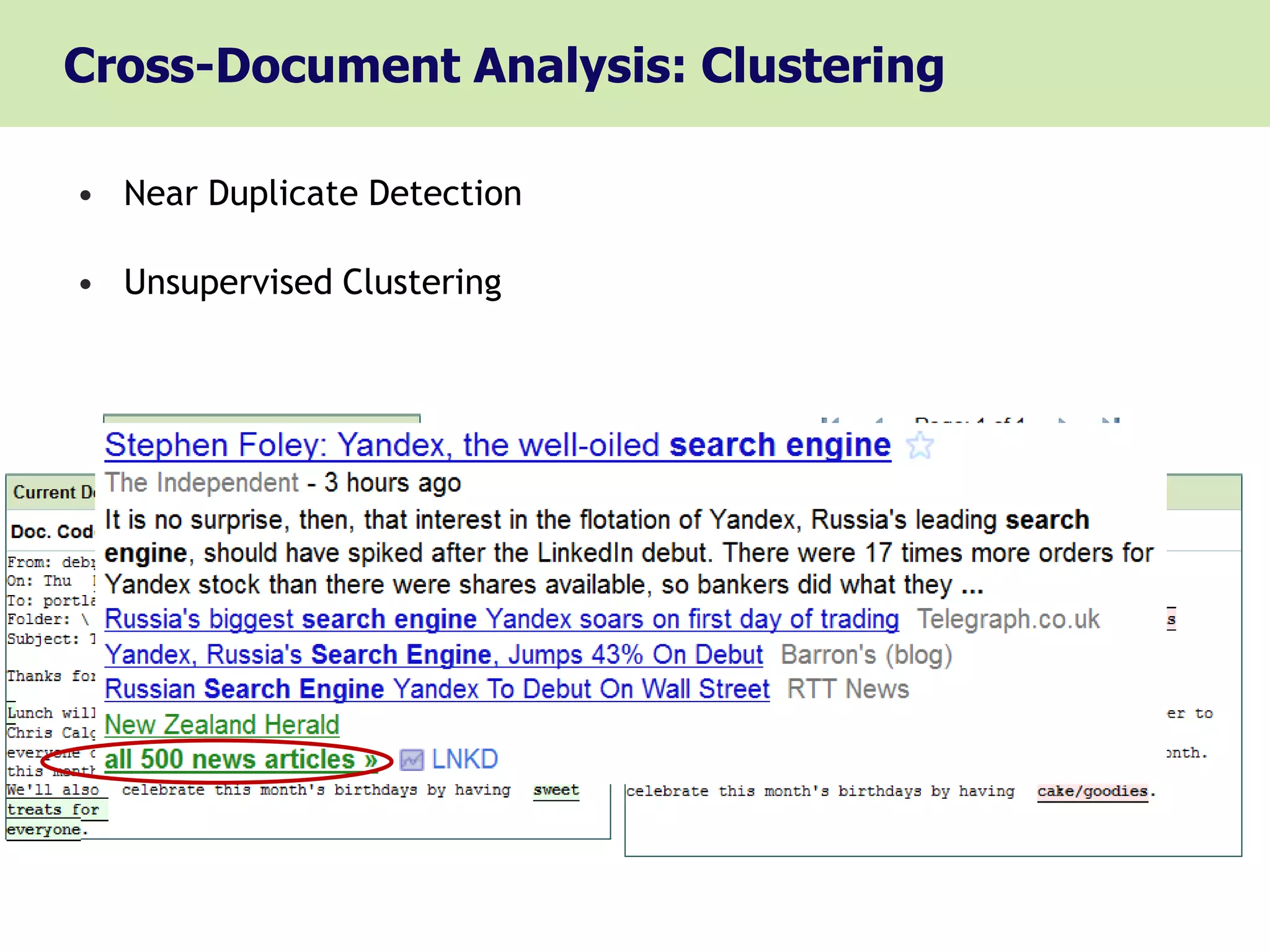
Cross-Document Entity Resolution, Near Duplicate Detection,
Unsupervised Clustering
6.
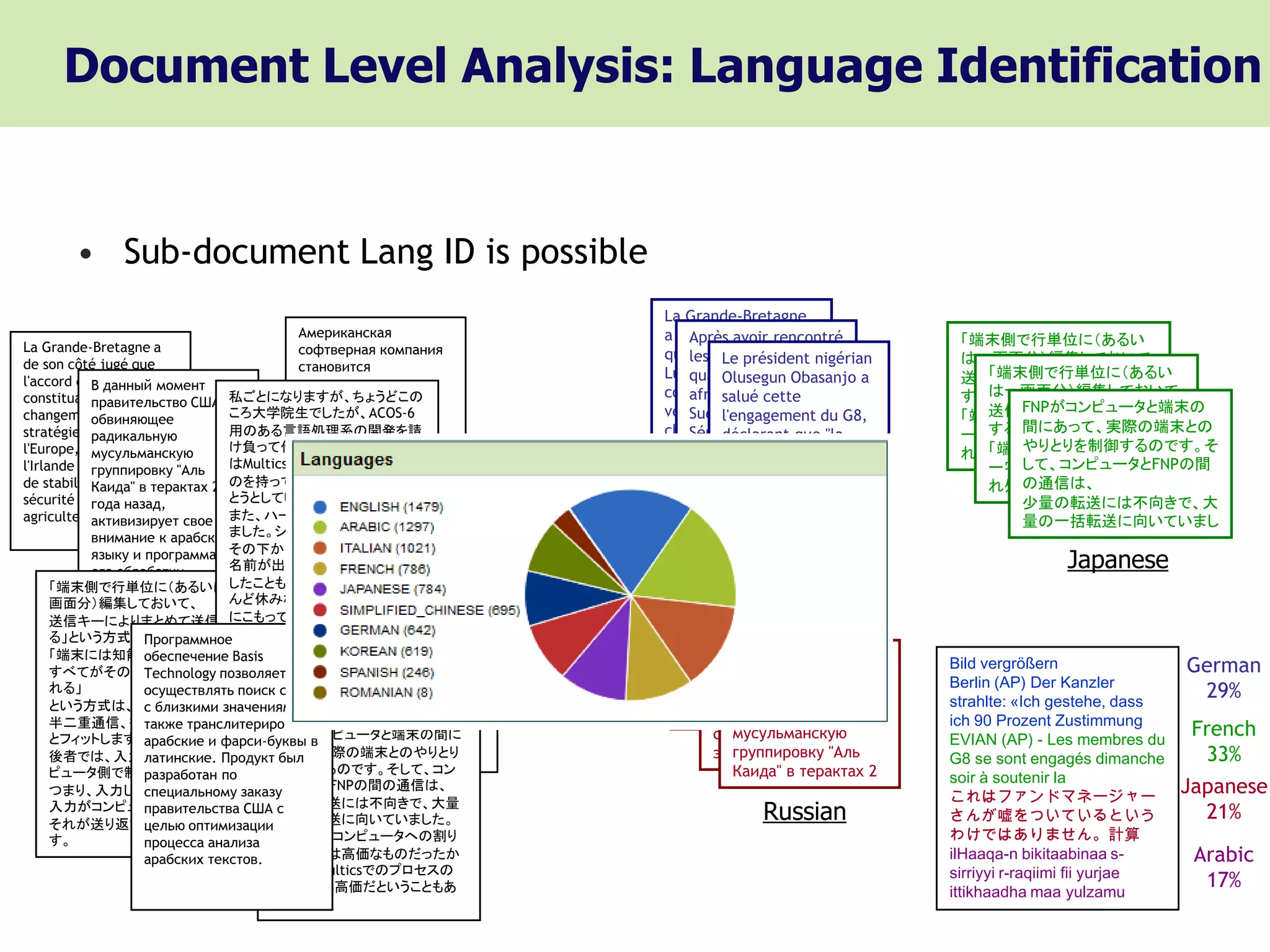
Document Level Analysis:Language Identification
• Sub-document Lang ID is possible
La Grande-Bretagne
Американская a de son côté jugé
Après avoir rencontré
La Grande-Bretagne a 「端末側で行単位に(あるい
софтверная компания queles présidents de nigérian
l'accord de
de son côté jugé que становится
Le président は一画面分)編集しておいて、
l'accord deВ данный момент
Luxembourg
Luxembourg cinq pays
quatre des
Olusegun Obasanjo a 「端末側で行単位に(あるい
送信キーによりまとめて送信
пользующимся
constituaitправительство США, 私ごとになりますが、ちょうどこの
un véritable спросом у спецслужб
constituait uncette du
africains (Afrique
salué は一画面分)編集しておいて、
する」という方式と、
changement dans la ころ大学院生でしたが、ACOS-6 véritable
Sud, l'engagement du G8,
Algérie, FNPがコンピュータと端末の
送信キーによりまとめて送信
обвиняющее США экспертом в 「端末には知能はなく、一字
stratégie agricole de 用のある言語処理系の開発を請
области лингвистики changement Nigeria) "la
Sénégal, dans la
déclarant que 間にあって、実際の端末との
する」という方式と、
радикальную 一字すべてがその都度送ら
l'Europe, tandis que
мусульманскую け負って作っていました。ACOS-6
(в частности, изучения stratégie
membres du comité
condition majeure au やりとりを制御するのです。そ
「端末には知能はなく、一字
れ処理される」
l'Irlande y a vu un gage "Аль
группировку はMulticsの概念に非常に近いも
и обработки de pilotage du して、コンピュータとFNPの間
一字すべてがその都度送ら
développement est
de stabilité et et de терактах 2 のを持っていました、あるいは持
Каида" в информации на の通信は、
れ処理される」
sécurité pour les
года назад, とうとしていました。 языке) после
арабском 少量の転送には不向きで、大
активизирует свое また、ハードウェアも大変似てい
agriculteurs. терактов 11 сентября French 量の一括転送に向いていまし
внимание к арабскому ました。シールをはがすと、
2001 Le président nigérian
г.
языку и программам その下から別のアメリカの会社の
его обработки. 名前が出てくるマシンでテスト
Olusegun Obasanjo a
salué cette Japanese
Грамматика языков したこともありました。1年間ほとdu G8,
「端末側で行単位に(あるいは一 l'engagement
画面分)編集しておいて、
данной группы んど休みなしにマシンルーム déclarant que "la Программное
送信キーによりまとめて送信す にこもっていて、ここでの議論とcondition majeure au обеспечение Basis
Американская
る」という方式と、 Программное 疑問を自分のテーマとしても développement est Technology позволяет
софтверная
「端末には知能はなく、一字一字обеспечение扱ったことがあるのです。それで、
Basis l'absence de conflit". La осуществлять поиск
компания момент
В данный
よーくわかるのです。 porte-parole de la Bild vergrößern German
すべてがその都度送られ処理さ Technology позволяет слов с правительство США,
близкими
становится Berlin (AP) Der Kanzler
れる」 осуществлять поиск слов présidence française, значениями, а также
обвиняющее
пользующимся strahlte: «Ich gestehe, dass
29%
という方式は、究極的に前者は с близкими значениями, а Catherine Colonna, a транслитерировать
радикальную
спросом у ich 90 Prozent Zustimmung
半二重通信、後者は全二重通信 также транслитерировать pour sa part qualifié la French
FNPがコンピュータと端末の間に
とフィットします。арабские и фарси-буквы в réunion мусульманскую
спецслужб США EVIAN (AP) - Les membres du
後者では、入力のエコーもコン あって、実際の端末とのやりとり
латинские. Продукт был d'"exceptionnelle". группировку "Аль
экспертом в области G8 se sont engagés dimanche 33%
ピュータ側で制御されます。 по
разработан を制御するのです。そして、コン Каида" в терактах 2 soir à soutenir la
つまり、入力した字の表示はキーспециальному заказуピュータとFNPの間の通信は、
これはファンドマネージャー
Japanese
入力がコンピュータに送られ、 США少量の転送には不向きで、大量
それが送り返されて表示されま
правительства
целью оптимизации
с
の一括転送に向いていました。 Russian さんが嘘をついているという 21%
す。 процесса анализа FNPによるコンピュータへの割り
わけではありません。計算
арабских текстов. 込み要求は高価なものだったか ilHaaqa-n bikitaabinaa s- Arabic
らです。Multicsでのプロセスの sirriyyi r-raqiimi fii yurjae
wake upも高価だということもあ ittikhaadha maa yulzamu
17%
りました。
7.
Document Level Analysis:Categorization
• Group Documents into Pre-defined categories
http://news.google.com/
http://www.bbc.co.uk/
8.
Sub-Document Analysis: Linguistics
• Segmentation of Asian language
• Lemmatization
Stemming
N-Gram
Morphological
Lemmatization
Segmentation
Sub-Document Analysis: EntityExtraction
• Identify Named Concepts in Unstructured Text
Statistical, rules, lists
http://www.twitscoop.com/
11.
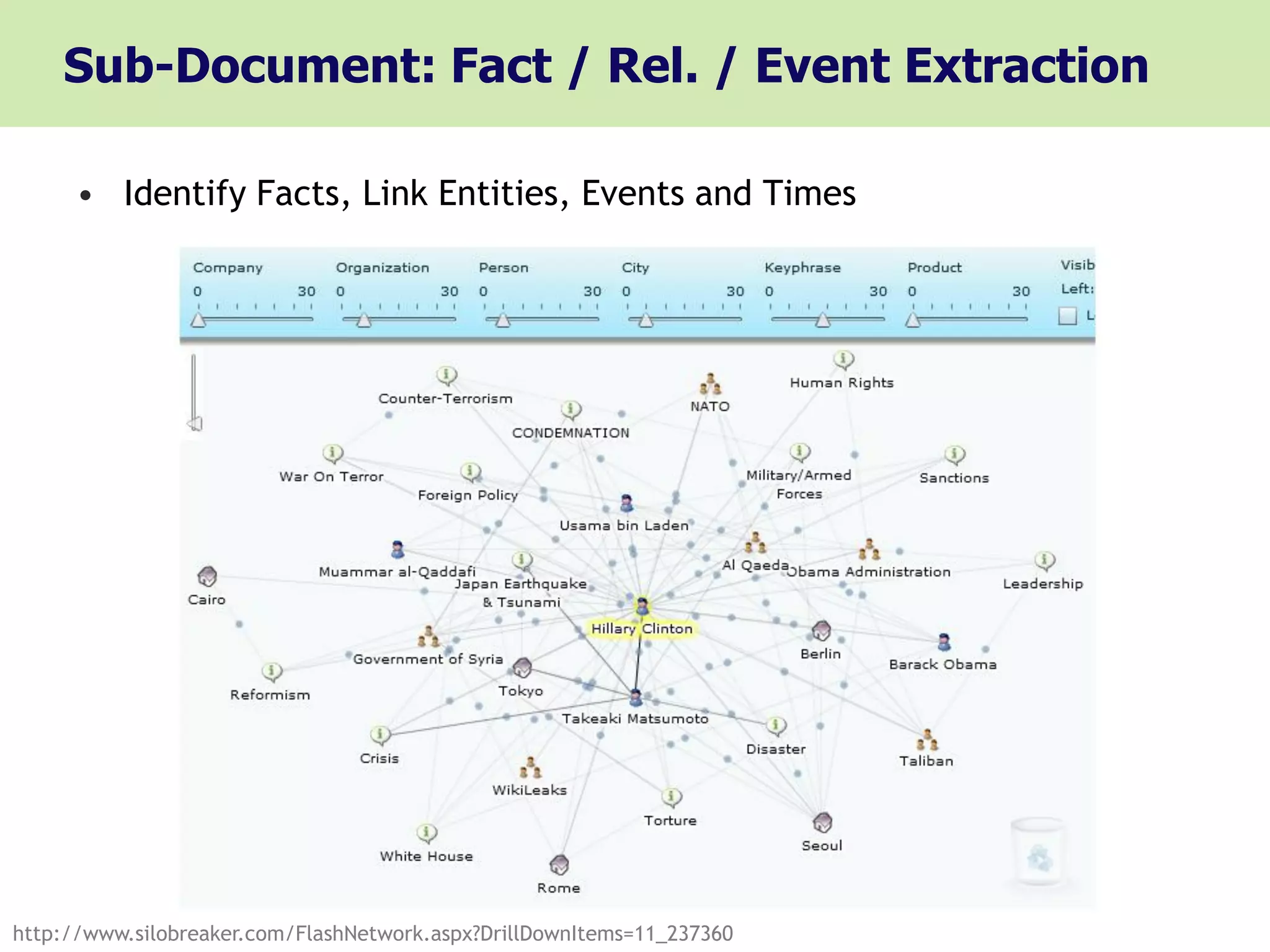
Sub-Document: Fact /Rel. / Event Extraction
• Identify Facts, Link Entities, Events and Times
http://www.silobreaker.com/FlashNetwork.aspx?DrillDownItems=11_237360
Integration Point: UpdateRequestProcessor
•Runs Before Analyzers
• Full Access to Document
• Two options:
Run the analysis directly in Solr
Call out to external analysis services
• Limitations:
Think through your indexing strategy
18.
Integration Point: UpdateRequestProcessor
•Run the analysis directly in Solr
Good for light weight analytics
Not good for cross-document analytics
• Call out to external analysis services
Web Services, UIMA, OpenPipeline, GATE, custom code
Note that these external calls are synchronous
Additional complexity / points of failure
Integration Point: Pre-Processor
•Index in Solr as Last Step of Analysis
• Good For:
Finer-grained control
Managing dependencies between components
Scalability
• Limitations:
Complexity / New points of failure
Cannot use Solr’s content acquisition features
21.
Integration Summary
• Thereare Many Options!
• Document-Level Analysis:
Generally, safe to run in UpdateRequestProcessor
• Sub-Document Analysis:
Sometimes run in UpdateRequestProcessor, sometimes external
• Cross-Document Analysis:
Run external
• Multiple-Analysis Components:
Run external document processing pipeline