Downloaded 15 times


![Related Research
Main approaches of hand tracking systems:
Data-glove-based - electromechanical gloves with sensors
Vision-based - continuous image frames from regular RGB or 3D sensors
Main machine learning techniques:
Artificial Neural Networks (ANN)
Hidden Markov Models (HMM)
Usage of HMM to recognize 47 Libras gestures types, captured with regular RGB
cameras [Souza et al. 2007].
3D hand and gesture recognition system using Microsoft Kinect sensor, for
dynamic gestures, and HD color sensor, for static gestures recognition [Caputo et
al. 2012]
A real-time system to recognize a set of Libras alphabet (only static gestures),
using MS Kinect and neural networks [Anjo et al. 2012].](https://image.slidesharecdn.com/kdmile2014apresentacaolibrasv1-141021073736-conversion-gate02/75/Using-Neural-Networks-and-3D-sensors-data-to-model-LIBRAS-gestures-recognition-KDMile-2014-3-2048.jpg)
![Case Study – Data Acquisition
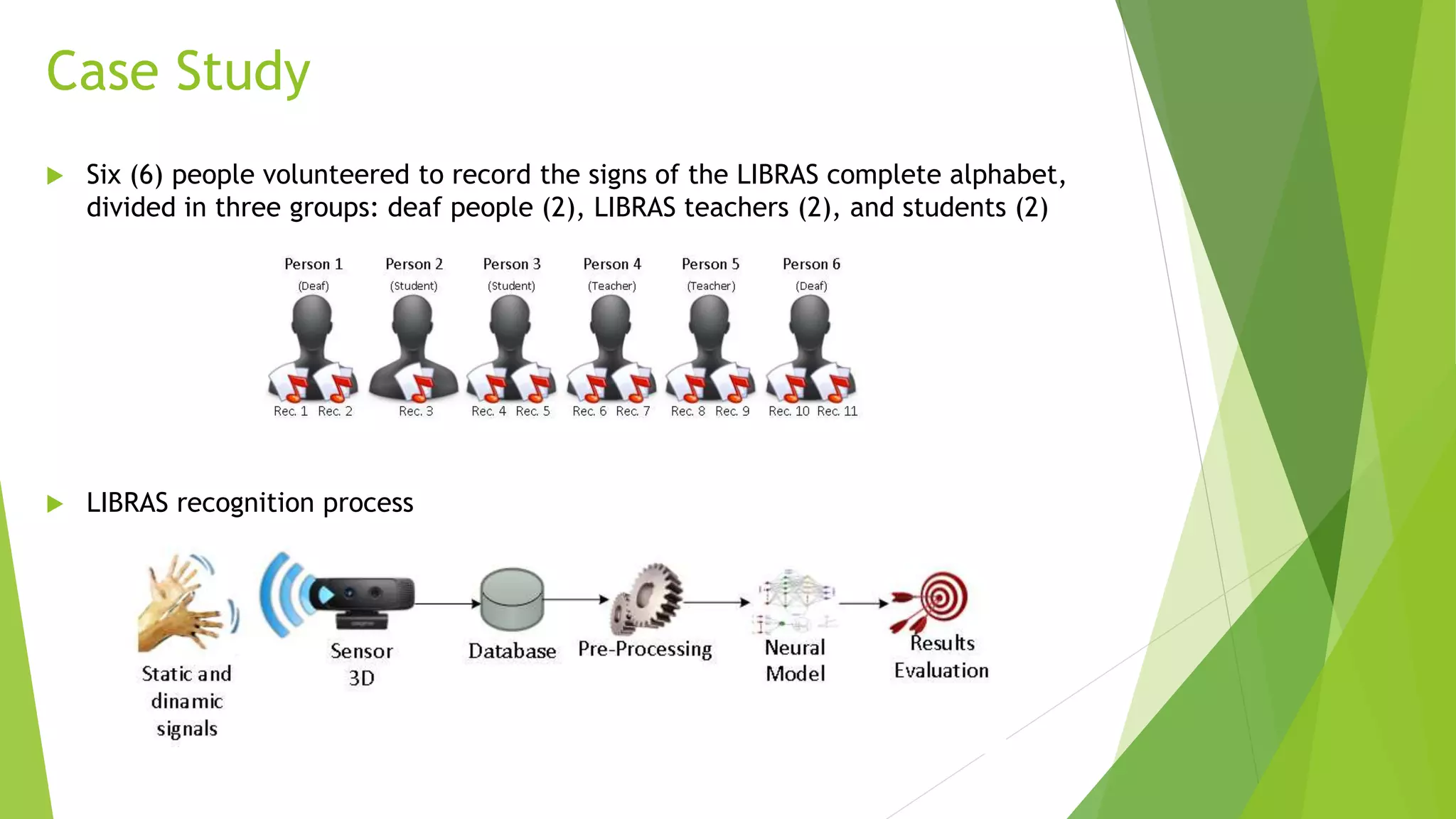
Gestures recorded using:
COTS 3D sensor Creative Senz3D GestureCam™ [Creative 2013]
Intel® Skeletal Hand Tracking Library (Experimental Release) [Intel 2013]
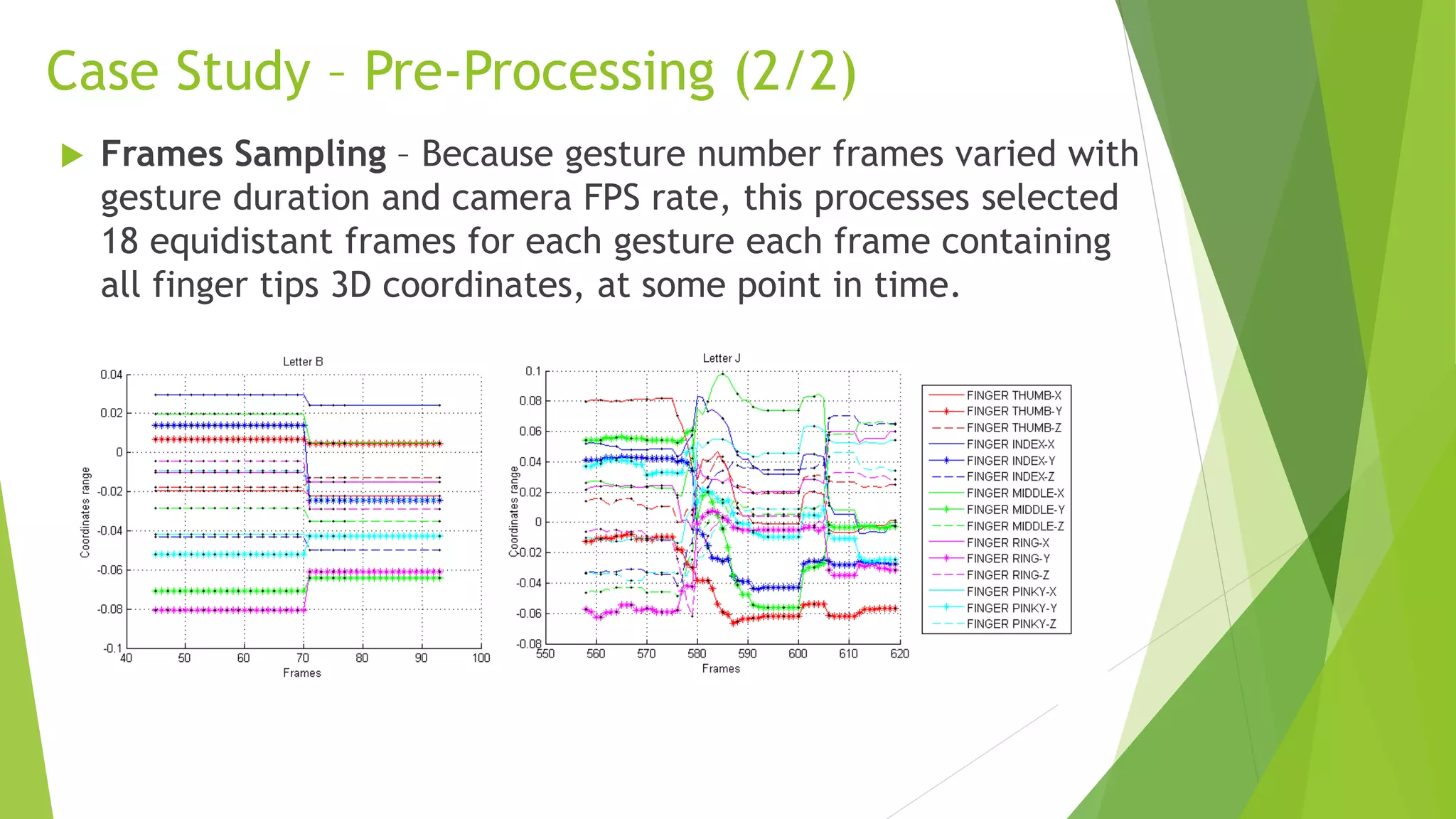
In this investigation, for each frame, it was recorded the absolute 3D coordinates (X,
Y, and Z) of 5 fingertips and the center of the hand palm, based on the sensor
distance. That resulted in 18 attributes with continuous position of hand and fingers.
Creative Senz3D GestureCam
Hand Tracking](https://image.slidesharecdn.com/kdmile2014apresentacaolibrasv1-141021073736-conversion-gate02/75/Using-Neural-Networks-and-3D-sensors-data-to-model-LIBRAS-gestures-recognition-KDMile-2014-6-2048.jpg)

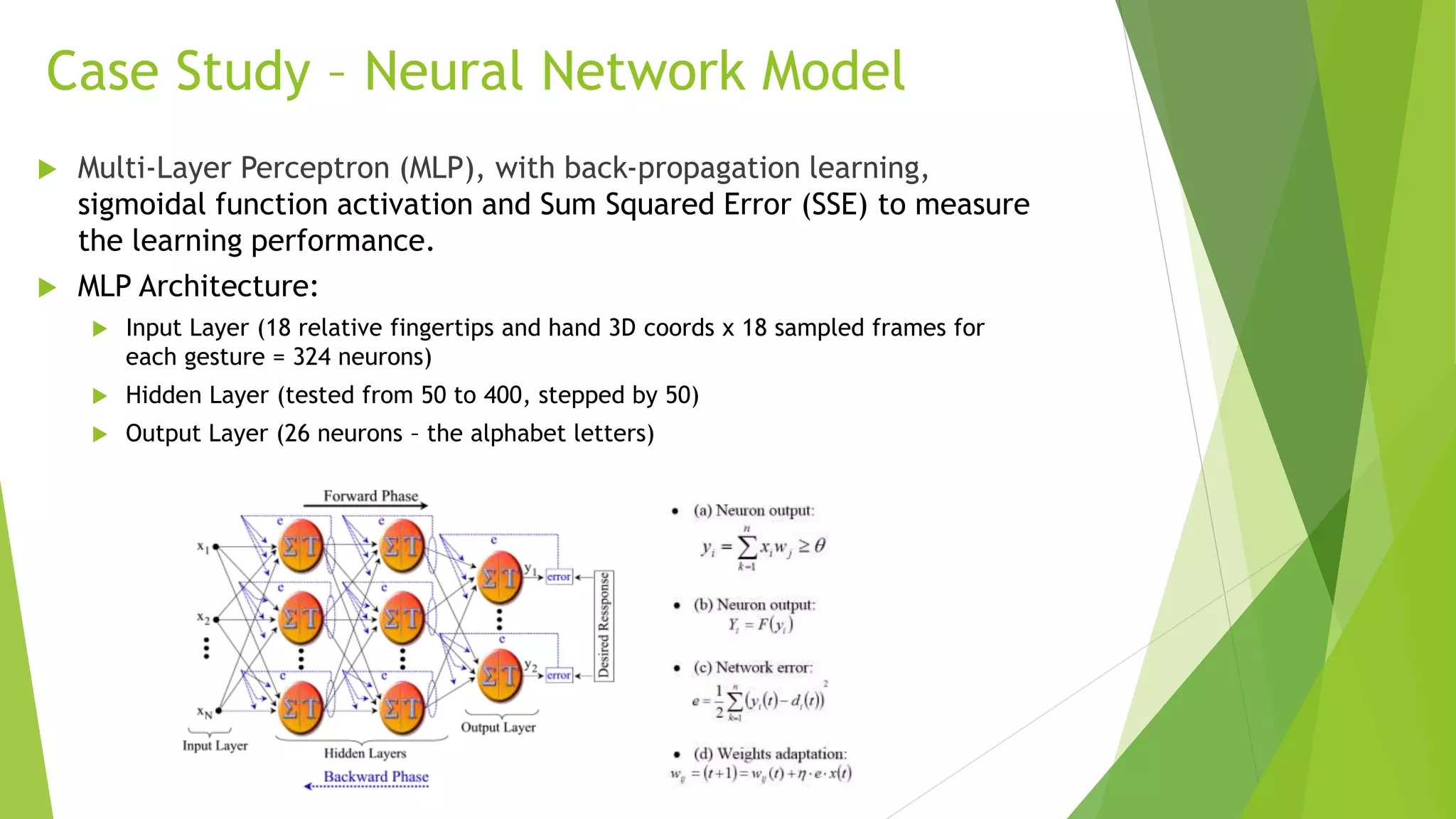






This research explores the recognition of Brazilian Sign Language (Libras) gestures using 3D sensor data and neural networks, addressing the needs of the deaf community in Brazil. It includes a case study with six participants recording various gestures, employing a multi-layer perceptron model that achieved a classification accuracy of 61.54% on unseen data. Challenges were faced in gathering accurate gesture samples and technical limitations of the chosen 3D sensor, with recommendations for future improvements and exploration of alternative models.










































![[Phd Thesis Defense] CHAMELEON: A Deep Learning Meta-Architecture for News Re...](https://cdn.slidesharecdn.com/ss_thumbnails/chameleondefesadoutorado1-191209202516-thumbnail.jpg?width=640&height=640&fit=bounds)

































