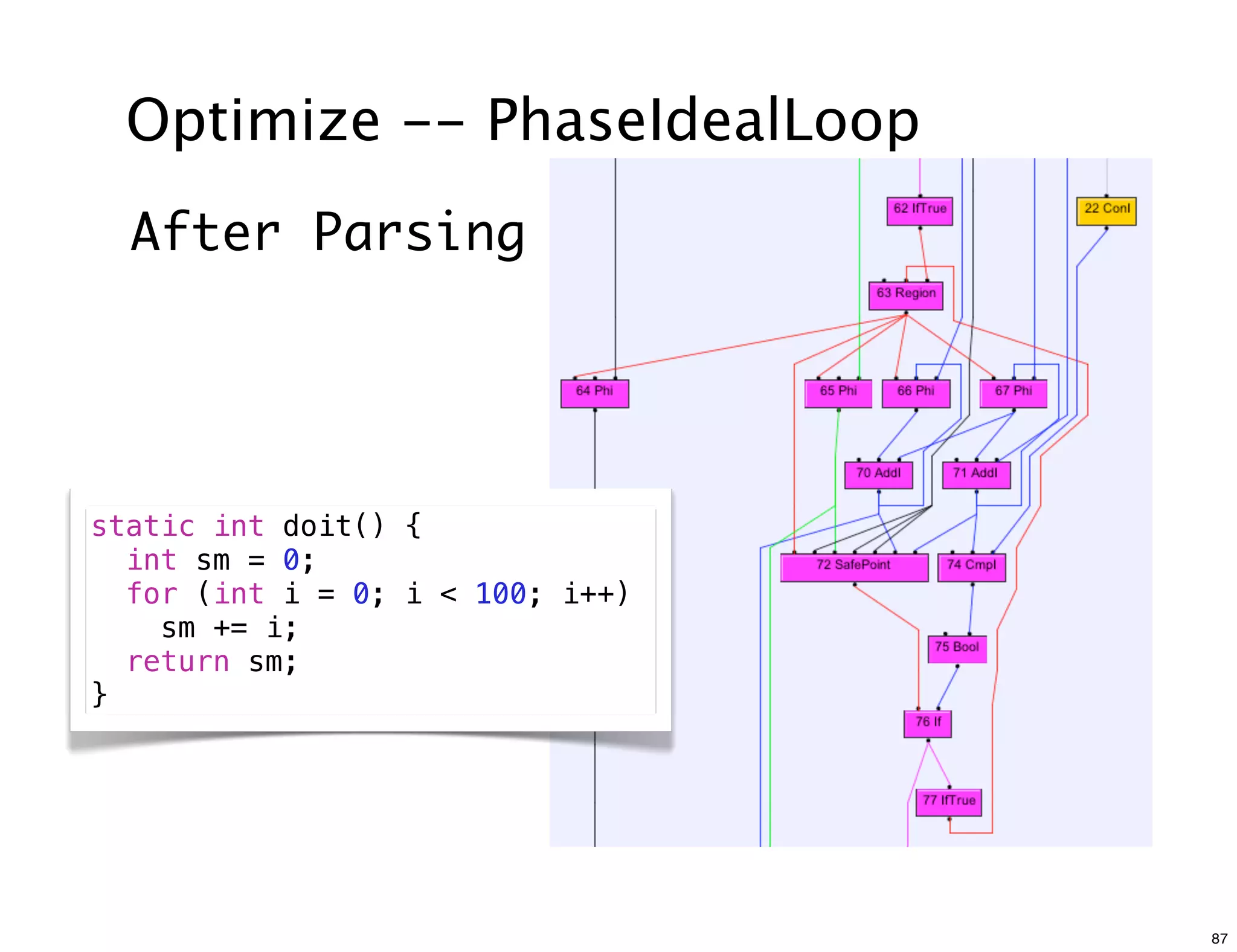
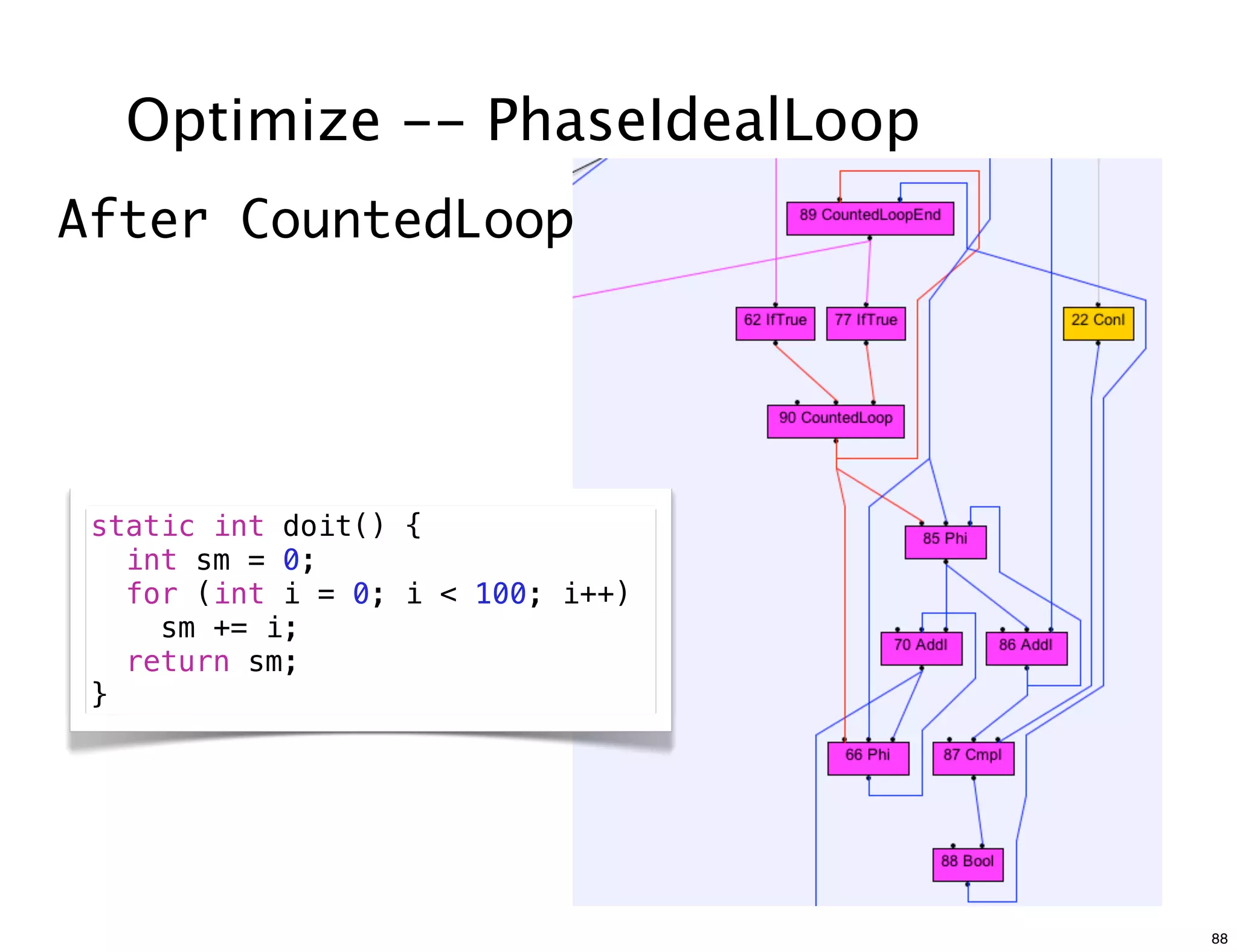
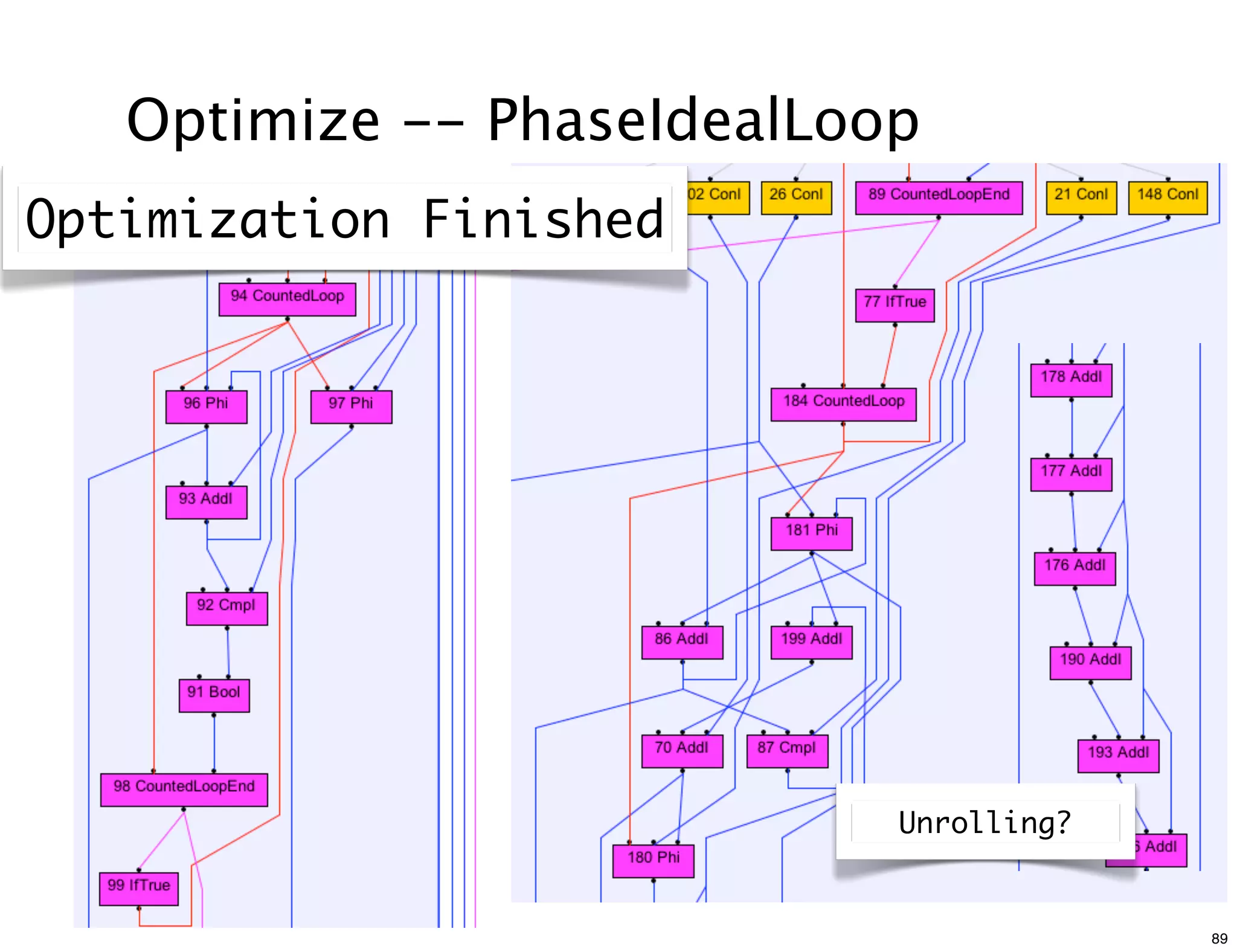
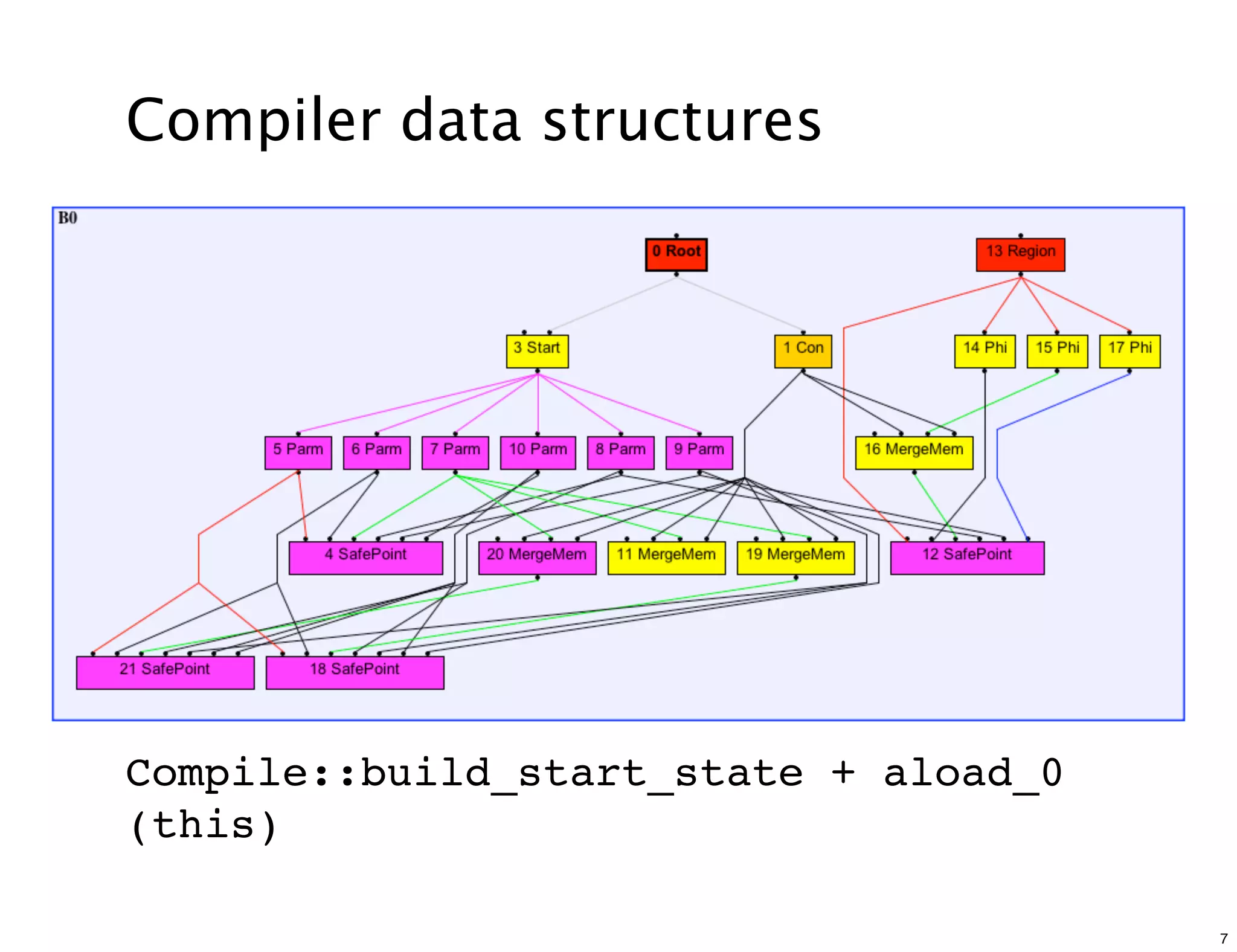
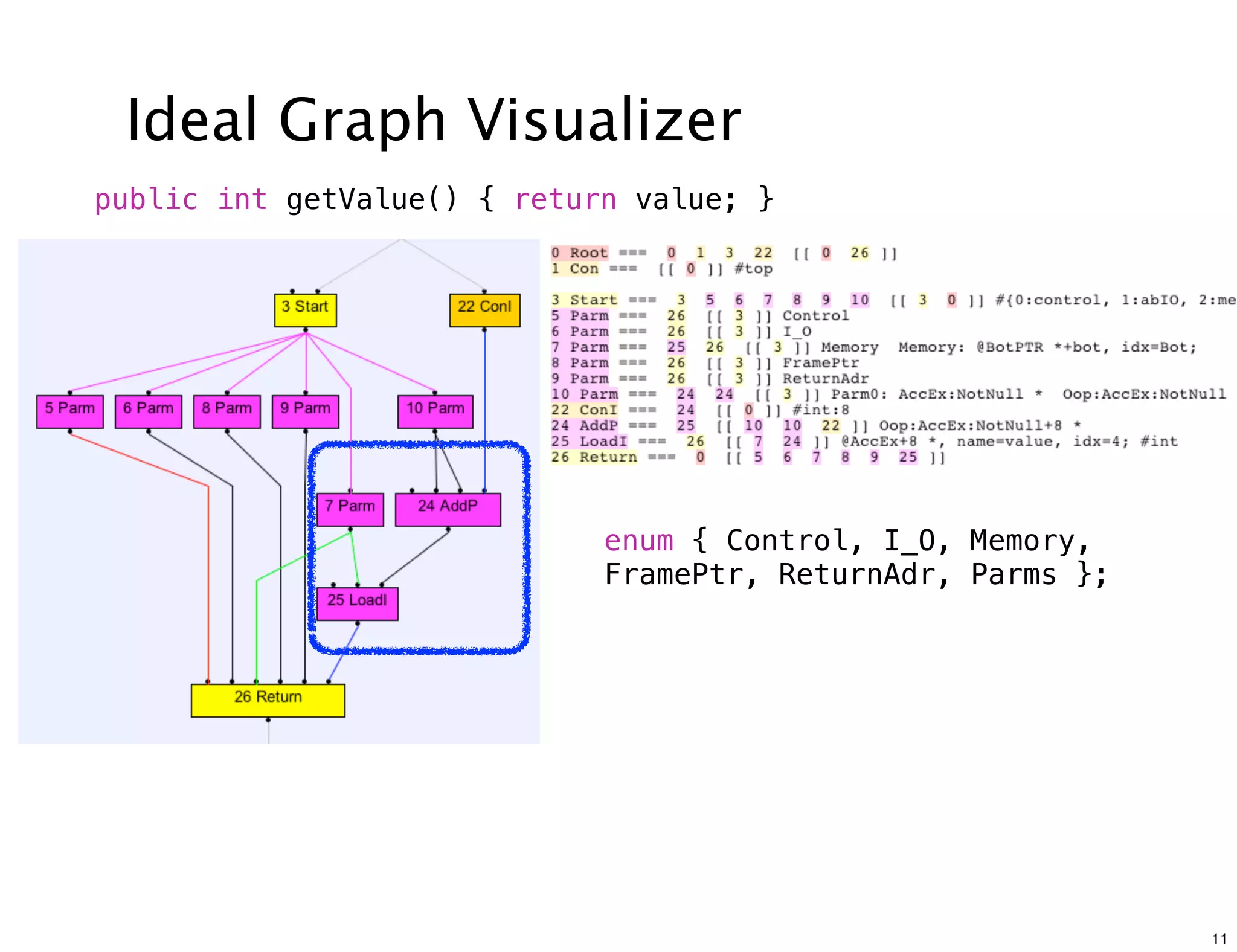
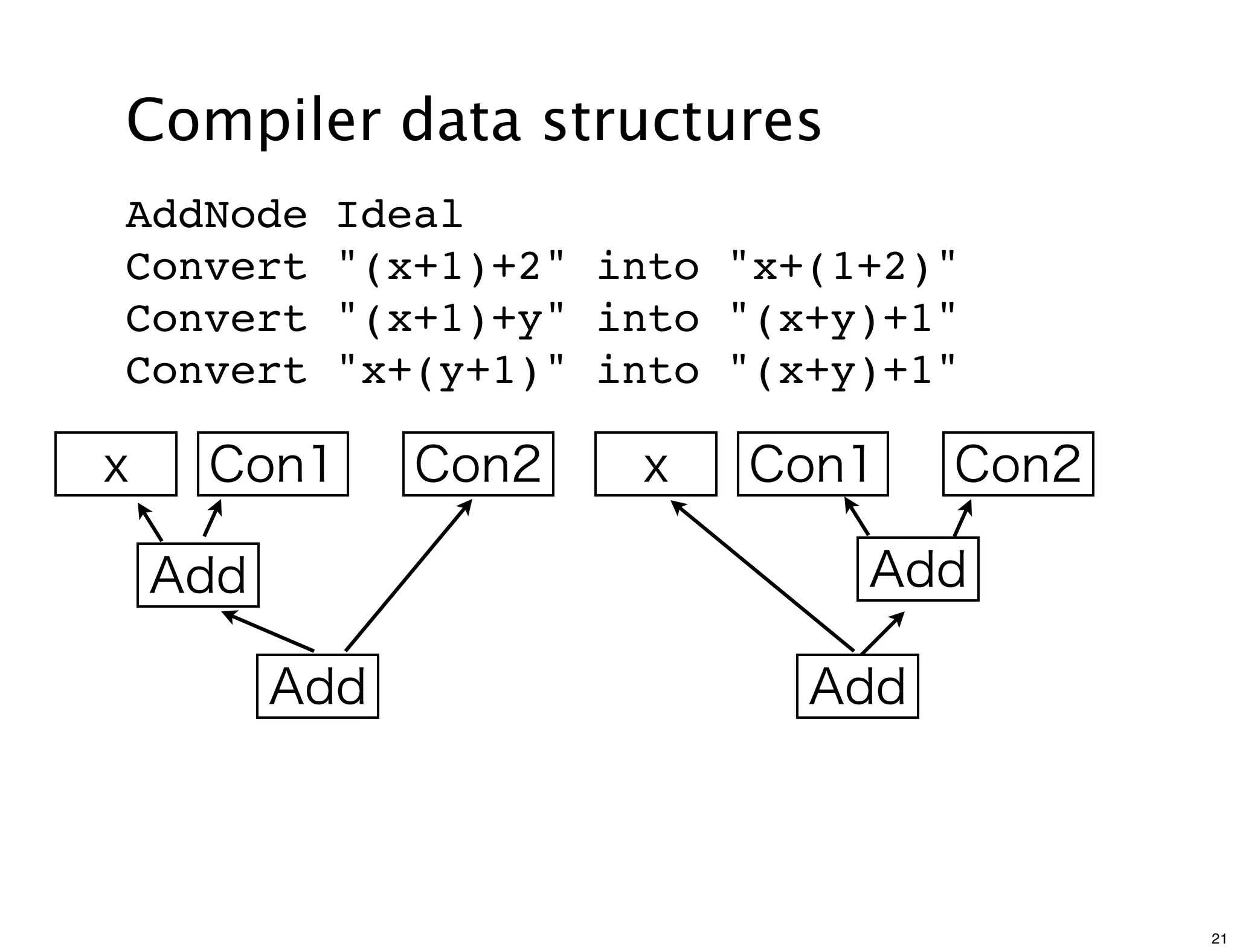
The document discusses various compiler data structure nodes used in the Java HotSpot VM compiler such as Node, RegionNode, PhiNode, and LoopNode. It describes how nodes are connected and how methods like Ideal, Value, and Identity are used to optimize nodes. The nodes represent an intermediate representation of the code during compilation and are manipulated throughout the various phases of compilation.







![Compiler data structures
$ ~/jdk1.7.0-b147/fastdebug/bin/java -XX:+PrintCompilation -XX:+PrintIdeal
-XX:CICompilerCount=1 sum
214 1 sum::doit (22 bytes)
VM option '+PrintIdeal' ...
21" ConI" === 0 [[ 180 ]] #int:0
180" Phi" === 184 21 70 [[ 179 ]] #int !orig=[159],[139],[66] !
jvms: sum::doit @ bci:10
179" AddI" === _ 180 181 [[ 178 ]] !orig=[154],[137],70,[145] !jvms:
sum::doit @ bci:12
178" AddI" === _ 179 181 [[ 177 ]] !orig=[153],[146],[135],86,[71] !
jvms: sum::doit @ bci:14
177" AddI" === _ 178 181 [[ 176 ]] !orig=[165],[152],86,[71] !jvms:
sum::doit @ bci:14
148" ConI" === 0 [[ 87 ]] #int:97
176" AddI" === _ 177 181 [[ 190 ]] !orig=[168],[152],86,[71] !jvms:
sum::doit @ bci:14
// <idx> <node type> === <in[]> [[out[]]] <additional desc>
// jvms = JVMState, root()->dump(9999) would dump IR as above;
Real example: https://gist.github.com/1369656
9](https://image.slidesharecdn.com/jvm-code-reading-c2-111118121955-phpapp01/75/JVM-code-reading-C2-9-2048.jpg)

![Compiler data structures
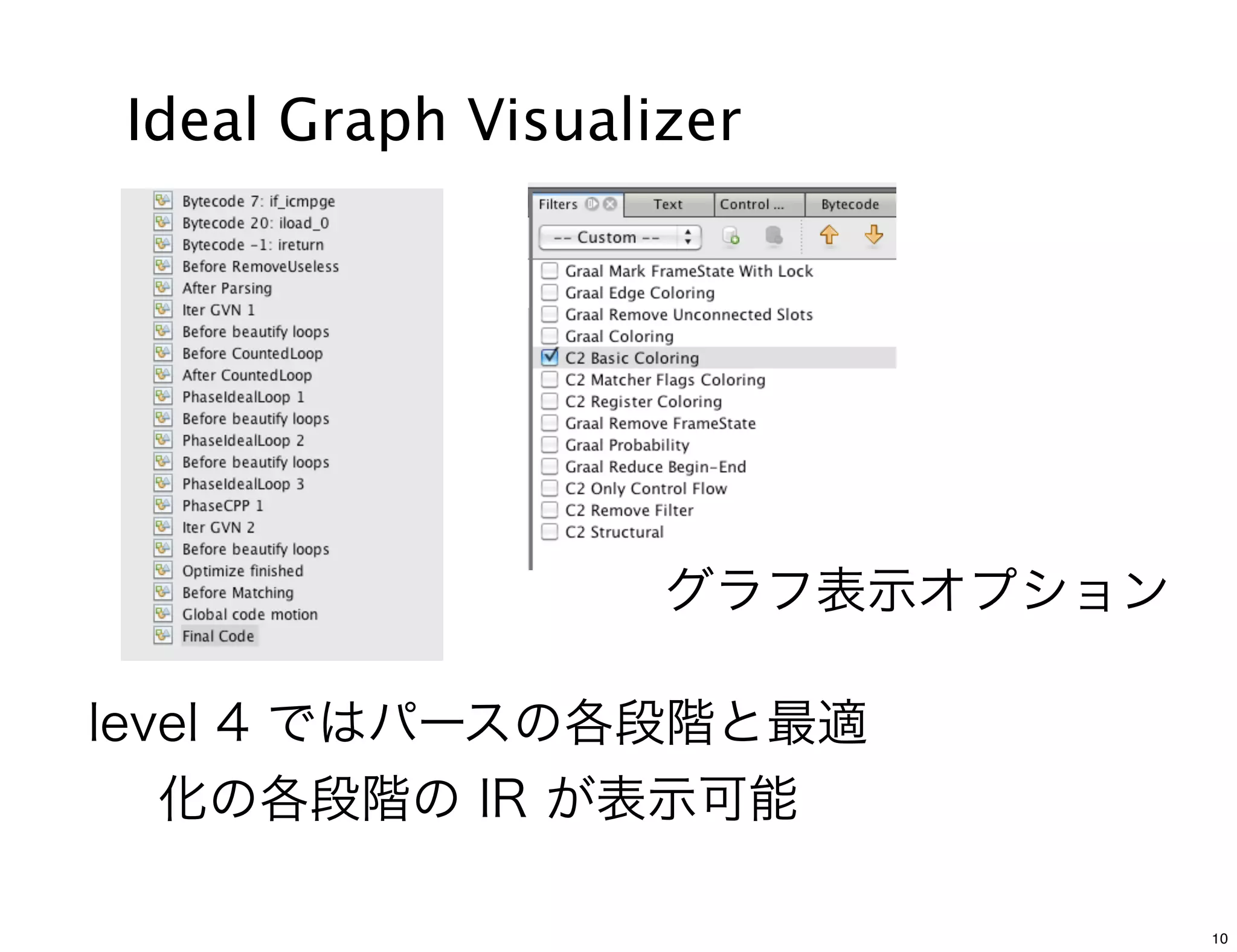
Options to generate data for Ideal
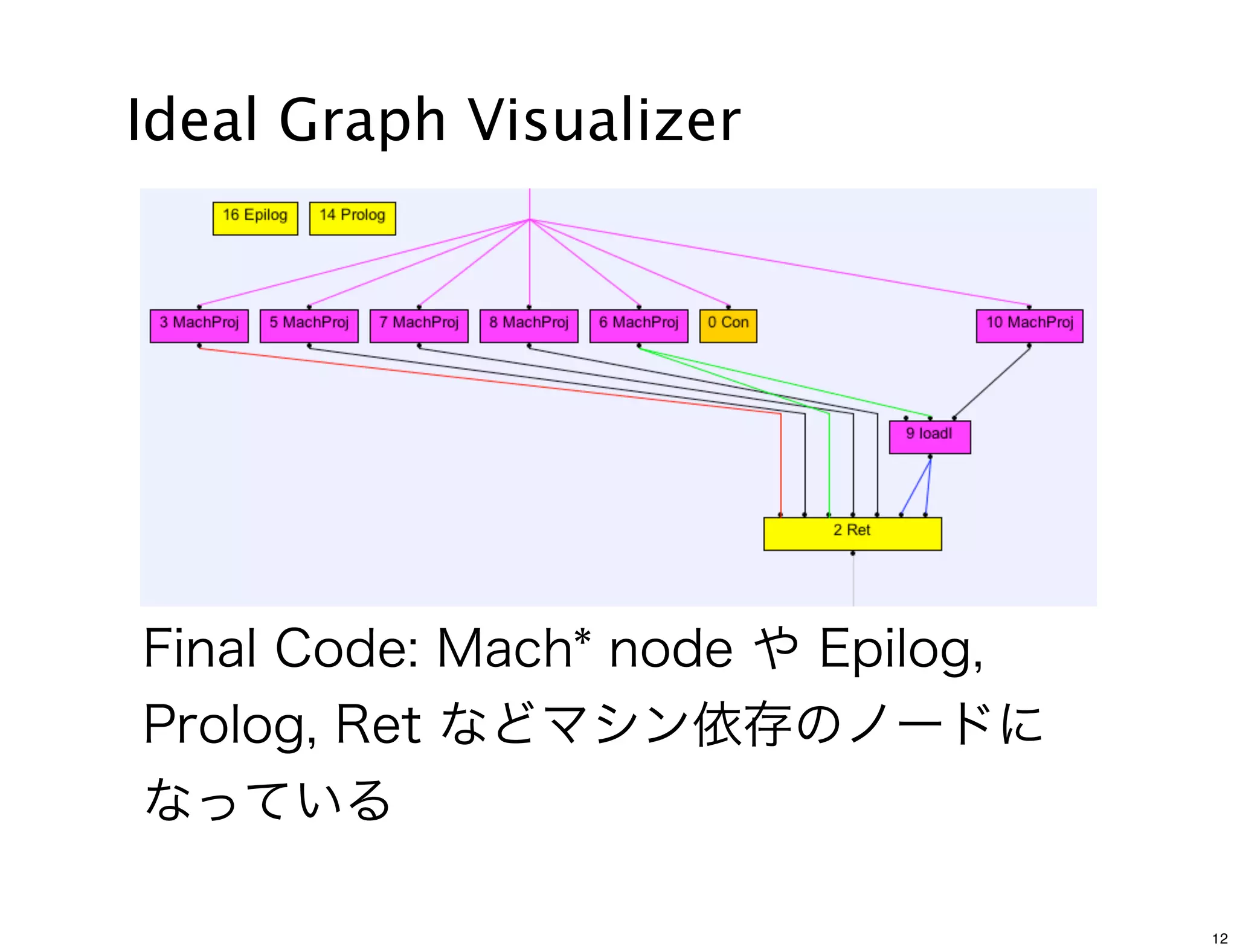
Graph Visualizer
-XX:PrintIdealGraphLevel=0 [0:None, 4: most verbose]
-XX:PrintIdealGraphPort=4444
-XX:PrintIdealGraphAddress=”127.0.0.1”
-XX:PrintIdealGraphFile=<path to IR xml file>
IdealGraphVisualizer listens to port 4444 by default.
14](https://image.slidesharecdn.com/jvm-code-reading-c2-111118121955-phpapp01/75/JVM-code-reading-C2-14-2048.jpg)


![Compiler data structures
// Insert a new required input at the end
void Node::ins_req( uint idx, Node *n ) {
assert( is_not_dead(n), "can not use dead node");
add_req(NULL); // Make space
...
_in[idx] = n; // Stuff over old required edge
if (n != NULL) n->add_out((Node *)this); // Add
reciprocal def-use edge
}
void add_out( Node *n ) {
if (is_top()) return;
if( _outcnt == _outmax ) out_grow(_outcnt);
_out[_outcnt++] = n;
}
17](https://image.slidesharecdn.com/jvm-code-reading-c2-111118121955-phpapp01/75/JVM-code-reading-C2-17-2048.jpg)


























![Compiler data structures
class PhaseTransform : public Phase {
protected:
Arena* _arena;
Node_Array _nodes;
Type_Array _types;
ConINode* _icons[...];
ConLNode* _lcons[...];
ConNode* _zcons[...];
:
}
45](https://image.slidesharecdn.com/jvm-code-reading-c2-111118121955-phpapp01/75/JVM-code-reading-C2-45-2048.jpg)


























![Parse do_one_bytecode
getClass はインライン展開され、
LoadKlass -> メモリアクセスに。
hashCode は static に
public class Call {
public static void main(String[] args) {
Call c = new Call();
for (int i = 0; i < 100000; i++) {
c.doit();
}
}
int doit() {
return getClass().hashCode();
}
}
72](https://image.slidesharecdn.com/jvm-code-reading-c2-111118121955-phpapp01/75/JVM-code-reading-C2-72-2048.jpg)