









![# M D B l o c a l
@ S i g N a r v a e z
Documents are Rich Data Structures{
first_name: ‘Paul’,
surname: ‘Miller’,
cell: 447557505611,
city: ‘London’,
location: { type: Point,
coordinates: [45.123,47.232]},
Profession: [‘banking’, ‘finance’, ‘trader’],
cars: [
{ model: ‘Bentley’,
year: 1973,
value: 100000, … },
{ model: ‘Rolls Royce’,
year: 1965,
value: 330000, … }
]
}
Fields can contain an array of sub-
documents
Typed field values
Fields can contain arrays
Fields
ORM not needed
Index/Query at any level](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-11-320.jpg)



![# M D B l o c a l
@ S i g N a r v a e z
{
sku: ‘PAINTZXC123’,
product_name: ‘Metallic Paint’,
colors: [‘Red’, ‘Green’],
size_gallons: [5, 10]
}
{
sku: ‘TSHRTASD43546’,
product_name: ‘T-shirt’,
size: [‘S’, ‘M’, ‘L’, ‘XL’],
colors: [‘Heather Gray’ … ],
material: ‘100% cotton’,
wash: ‘cold’,
dry: ‘tumble dry low’
}
{
sku: ‘WHEELBVCX6543’,
product_name: ’19” 5-spoke’,
material: ‘aluminum alloy’,
color: ‘silver’,
frame_material: ‘aluminum’,
package_height: ’20.5x32.9x55’,
weight_lbs: 5.15,
wheel_size_in: 19
}
Different Documents in the same ProductsCatalog collection in MongoDB
Polymorphic Schema – Aligns with OOP principles
Car Paint products Car T-Shirt products Car Wheels products
Documents are FLEXIBLE](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-15-320.jpg)








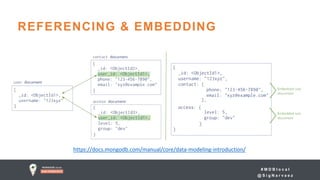


![# M D B l o c a l
@ S i g N a r v a e z
1-M
{
_id: 2,
first: “Joe”,
last: “Patient”,
addr: { …},
procedures: [
{
id: 12345,
date: 2015-02-15,
type: “Cat scan”,
…},
{
id: 12346,
date: 2015-02-15,
type: “blood test”,
…}]
}
Patients
Embed
Modeled in 2 possible ways
{
_id: 2,
first: “Joe”,
last: “Patient”,
addr: { …},
procedures: [12345, 12346]}
{
_id: 12345,
date: 2015-02-15,
type: “Cat scan”,
…}
{
_id: 12346,
date: 2015-02-15,
type: “blood test”,
…}
Patients
Reference
Procedures](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-27-320.jpg)
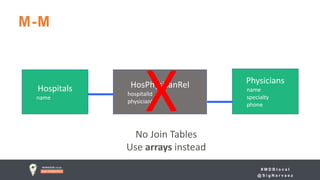
![# M D B l o c a l
@ S i g N a r v a e z
M-M
{
_id: 1,
name: “Oak Valley Hospital”,
city: “New York”,
beds: 131,
physicians: [
{
id: 12345,
name: “Joe Doctor”,
address: {…},
…},
{
id: 12346,
name: “Mary Well”,
address: {…},
…}]
}
Embedding Physicians in Hospitals collection
{
_id: 2,
name: “Plainmont Hospital”,
city: “Omaha”,
beds: 85,
physicians: [
{
id: 63633,
name: “Harold Green”,
address: {…},
…},
{
id: 12345,
name: “Joe Doctor”,
address: {…},
…}]
}
Data Duplication
…
is ok!](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-29-320.jpg)
![# M D B l o c a l
@ S i g N a r v a e z
M-M
{
_id: 1,
name: “Oak Valley Hospital”,
city: “New York”,
beds: 131,
physicians: [12345, 12346]
}
Referencing
{
id: 63633,
name: “Harold Green”,
hospitals: [1,2],
…}
Hospitals
{
_id: 2,
name: “Plainmont Hospital”,
city: “Omaha”,
beds: 85,
physicians: [63633, 12345]
}
Physicians
{
id: 12345,
name: “Joe Doctor”,
hospitals: [1],
…}
{
id: 12346,
name: “Mary Well”,
hospitals: [1,2],
…}](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-30-320.jpg)


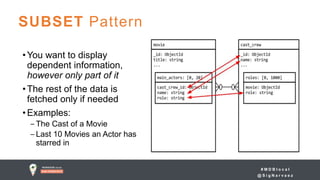







![# M D B l o c a l
@ S i g N a r v a e z
Data Modeling for Time Series
http://www.switchdoc.com/wp-content/uploads/2015/01/41-tvY-gqZL.jpg
{
sensor_id : 520124,
measurements : [
{
date : ISODate(“2017-02-25T17:13:00.000Z”),
temperature : 9,
humidity : 60
},
{
date : ISODate(“2017-02-25T17:13:05.000Z”),
temperature : 15,
humidity : 55
}, … ],
Bucketing](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-41-320.jpg)

![# M D B l o c a l
@ S i g N a r v a e z
Data Modeling for Time Series
http://www.switchdoc.com/wp-content/uploads/2015/01/41-tvY-gqZL.jpg
{
sensor_id : 520124,
measurements : [
{
date : ISODate(“2017-02-25T17:13:00.000Z”),
temperature : 9,
humidity : 60
},
{
date : ISODate(“2017-02-25T17:13:05.000Z”),
temperature : 15,
humidity : 55
}, … ],
txCount : 100,
Bucketing by
transactions](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-43-320.jpg)

![# M D B l o c a l
@ S i g N a r v a e z
Data Modeling for Time Series
http://www.switchdoc.com/wp-content/uploads/2015/01/41-tvY-gqZL.jpg
{
sensor_id : 520124,
start_date : ISODate(“2017-02-25T17:00:00.000Z”),
end_date : ISODate(“2017-02-25T18:00:00.000Z”),
measurements : [
{
date : ISODate(“2017-02-25T17:13:00.000Z”),
temperature : 9,
humidity : 60
},
{
date : ISODate(“2017-02-25T17:13:05.000Z”),
temperature : 15,
humidity : 55
}, … ],
txCount : 100,
Bucketing by time
and transactions](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-45-320.jpg)

![# M D B l o c a l
@ S i g N a r v a e z
Data Modeling for Time Series
http://www.switchdoc.com/wp-content/uploads/2015/01/41-tvY-gqZL.jpg
{
sensor_id : 520124,
start_date : ISODate(“2017-02-25T17:00:00.000Z”),
end_date : ISODate(“2017-02-25T18:00:00.000Z”),
measurements : [
{
date : ISODate(“2017-02-25T17:13:00.000Z”),
temperature : 9,
humidity : 60
},
{
date : ISODate(“2017-02-25T17:13:05.000Z”),
temperature : 15,
humidity : 55
}, … ],
txCount : 100,
avg_temperature : 10,
avg_humidity : 53
}
Bucketing by time &
transactions with
pre-aggregation](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-47-320.jpg)


![# M D B l o c a l
@ S i g N a r v a e z
MGenerateJS
{
"first_name" : { "$string" : { "length" : 30 }},
"last_name" : { "$string" : { "length" : 30 }},
"cell" : "$number",
"city" : { "$string" : { "length" : 30 }},
"location" : [ "$number", "$number"],
"professions" : { "$array" : [ {
"$choose" : [ "banking", "finance", "trader" ] },
{ "$number": [1, 3] }
] },
"physicians" : { "$array" : [
{
"name" : { "$string" : { "length" : 30 }},
"last_visit" : { "$string" : { "length" : 30 }},
"last_visit_dt" : "$datetime"
},
{ "$number" : [1, 5]}
] }
}
• Model schema using JSON
• Generate K’s to M’s of docs
• Try out queries
• Measure performance
• Iterate!!](https://image.slidesharecdn.com/0800-0845-jumpstart-schema-d-41bf84c7-2921-4858-9a6d-ab75bcff284a-709579575-171018133101/85/Jumpstart-Introduction-to-Schema-Design-50-320.jpg)




The document discusses schema design in MongoDB, emphasizing the differences from relational databases, the importance of optimized designs for performance, and patterns for various use cases. It covers the document model, data structures, indexing, querying techniques, and specific examples from various fields like healthcare and weather data. Key takeaways include the necessity of understanding access patterns and the flexibility of MongoDB's document-based architecture.






















![[MongoDB.local Bengaluru 2018] Jumpstart: Introduction to Schema Design](https://cdn.slidesharecdn.com/ss_thumbnails/0800-jumpstartschemadesign-saurabh-180425155648-thumbnail.jpg?width=640&height=640&fit=bounds)












![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











