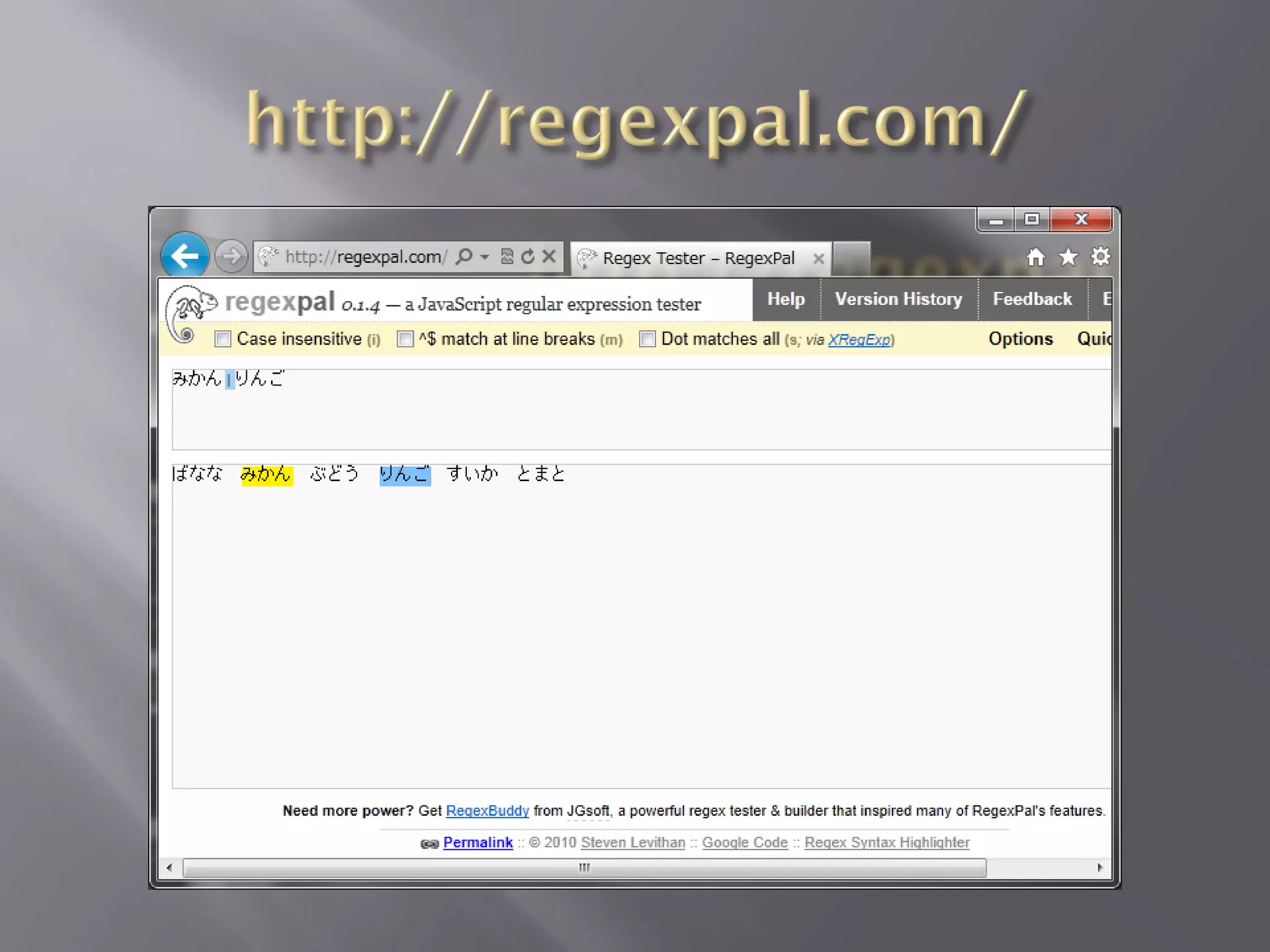
本の例題
var parse_url =/^(?:([A-Za-z]+):)?(¥/{0,3})([0-9.¥-A-Za-
z]+)(?::(¥d+))?(?:¥/([^?#]*))?(?:¥?([^#]*))?(?:#(.*))?$/;
var url = "http://www.ora.com:80/goodparts?q#fragment";var result =
parse_url.exec(url);
var names = ['url', 'scheme', 'slash', 'host', 'port', 'path', 'query', 'hash'];
var blanks = ' ';
var i;
for (i = 0; i < names.length; i += 1) {
document.writeln(names[i] + ':' +
blanks.substring(names[i].length), result[i]);
}




![ 「|」を使うと複数キーワードで検索できる
ように、下記の特殊文字には役割がある。
¥ / [ ] - ( ) ? + * | . ^ $
正規表現では「メタ文字」と呼んでいる。
メタ文字自身を検索対象とする場合、¥を付ける
例 ¥¥ ,¥[ , ¥+
※メタ(meta-)とは、「高次な-」「超-」「-間の」「-を含んだ」
「-の後ろの」等の意味の接頭辞。ギリシャ語から](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-5-2048.jpg)






![ 「[ ]」 …指定内の任意表現 呼び名:ブラケット
正規表現 今日の天気は[晴曇雨]です
対象文字 今日の天気は晴です
今日の天気は曇です
今日の天気は雨です
今日の天気は雪です
「[^ ]」 …指定内の任意以外表現
正規表現 今日の天気は[^晴曇雨]です (^が先頭)
対象文字 今日の天気は雪です
※[ ]の中で ^ が使用された場合は、行の先頭を表す
^(ハット) とは意味が異なります。](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-12-2048.jpg)
![[ ] と ( | ) の使い方を間違えた場合
例 [りんご|みかん]
「り」「ん」「ご」「 | 」「み」「か」「ん」
のどれか一文字という意味になる。](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-13-2048.jpg)
![ 「[A - Z]」 … 英大文字AからZまで のどれか
「[a-z]」 … 英小文字aからzまで のどれか
「[0-9]」 … 数字0から9まで のどれか
「[A - Za-z0-9]」 … 上記を連続して書ける
「[あ-お]」 … あぃいぅうぇえぉお のどれか
「[か-こ]」 … かがきぎくぐけげこ のどれか
「[.*]」 … .か * のいずれかの文字。
[ ]の中ではメタ文字は普通の文字として認識
される文字もメタ文字ではない。
(但し、先頭の^や ] や範囲指定の‐は例外)](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-14-2048.jpg)
![ ¥w 英字、数字、アンダースコア。
[a-zA-Z0-9_] に同じ。
¥W 英字、数字、アンダースコア以外の文字。
[^a-zA-Z0-9_] に同じ。
¥d 数字。[0-9] に同じ
¥D 数字以外の文字。[^0-9] に同じ。
¥n 改行
¥s スペース。
¥S スペース以外の文字。](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-15-2048.jpg)
![ 日付を検索する
正規表現 ¥d{4}¥/¥d{1,2}¥/¥d{1,2}
対象文字 2011/08/20 2011/8/2
郵便番号を検索する(厳密ではない)
正規表現 ¥d{3}-¥d{4}
対象文字 012-1234
メールアドレスを検索する (厳密ではない)
正規表現 ^[¥w_-]+@[¥w¥.-]+¥.¥w{2,}$
対象文字 microsoft@e-mail.microsoft.com](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-16-2048.jpg)

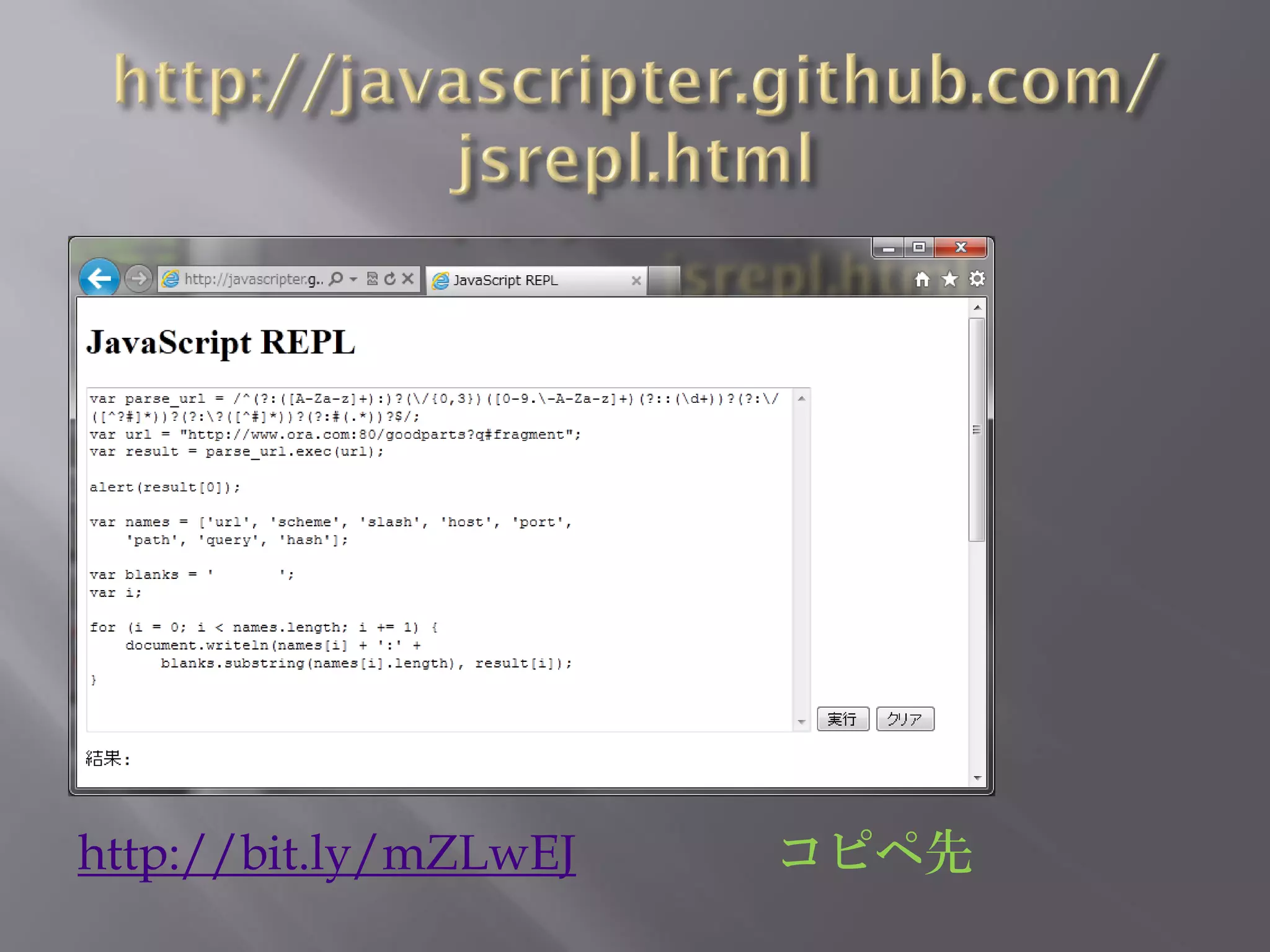
![本の例題
var parse_url = /^(?:([A-Za-z]+):)?(¥/{0,3})([0-9.¥-A-Za-
z]+)(?::(¥d+))?(?:¥/([^?#]*))?(?:¥?([^#]*))?(?:#(.*))?$/;
var url = "http://www.ora.com:80/goodparts?q#fragment";var result =
parse_url.exec(url);
var names = ['url', 'scheme', 'slash', 'host', 'port', 'path', 'query', 'hash'];
var blanks = ' ';
var i;
for (i = 0; i < names.length; i += 1) {
document.writeln(names[i] + ':' +
blanks.substring(names[i].length), result[i]);
}](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-18-2048.jpg)
![ url: http://www.ora.com:80/goodparts?q#fragment
scheme: http
slash: //
host: www.ora.com
port: 80
path: goodparts
query: q
hash: fragment
result[0] には、対象文字列のURLがセット](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-20-2048.jpg)
![ scheme: http
正規表現 ^(?:([A-Za-z]+):)?
結果 http
「(?:)」… 非キャプチャグループ
(…) で囲まれるとキャプチャグループに入る
マッチした文字列をコピーし結果の配列に格納
非キャプチャグループはグループ化だけを行う
正規表現 ^(([A-Za-z]+):)? ?:を外す
結果 http: 「:」 が入る](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-21-2048.jpg)
![str = "http://www.ora.com:80/goodparts?q#fragment";
ret = str.match(/^(?:([A-Za-z]+):)?/)
alert("1番目:" + ret[0] + "¥n" +
"2番目:" + ret[1] + "¥n");](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-22-2048.jpg)
![ slash: //
正規表現 (¥/{0,3})
結果 //
host: www.ora.com
正規表現 ([0-9.¥-A-Za-z]+)
結果 www.ora.com
port: 80
正規表現 (?::(¥d+))?
結果 80](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-23-2048.jpg)
![ path: goodparts
正規表現 (?:¥/([^?#]*))?
結果 goodparts
query: q
正規表現 (?:¥?([^#]*))?
結果 q
hash: fragment
正規表現 (?:#(.*))?
結果 fragment](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-24-2048.jpg)

![ [^ABC]*? … 文字1つ1つ を除外
正規表現 JR[^静岡]*?駅
結果 JR静岡駅 JR浜松駅 JR三島駅 JR岡山駅
これだとJR岡山駅があると対象外となる
((?!ABC).)*? … 文字列 を除外 (?!ABC).*?変更
正規表現 JR((?!静岡).)*?駅
結果 JR静岡駅 JR浜松駅 JR三島駅 JR岡山駅
これだとJR東静岡駅があると対象外となる](https://image.slidesharecdn.com/regularexpression-120930100316-phpapp02/75/JavaScript-26-2048.jpg)































































