모바일 게임 서버 런칭 과정 중 겪었던 경험들을 공유합니다.
Docker, Amazon ElasticBeanstalk, Kinesis, Elastic Stack, Elasticsearch, 부하테스트에 대한 내용을 담았습니다.
Github : https://github.com/YonghoChoi
Blog : http://yongho1037.tistory.com
발표자 소개
● 열혈강호제작 중
● 하이브 with Naver Webtoon
● 화이트데이
● 클럽 엠스타 온라인
● 와리가리 삼총사 for Kakao
● 어스토니시아VS for Kakao
● 다함께 차차차
● 어스토니시아 온라인
● 열혈강호2 온라인
참여 프로젝트
● 자바카페 커뮤니티 운영진
○ 매주 운영진 스터디
○ 매월 운영진 회의 및 세미나
○ 분기별 공개 강의 및 스터디
○ 공감 세미나 및 KCD 참여
○ 상/하반기 운영진 워크샵
○ 페이스북 / 기술 블로그 운영
활동
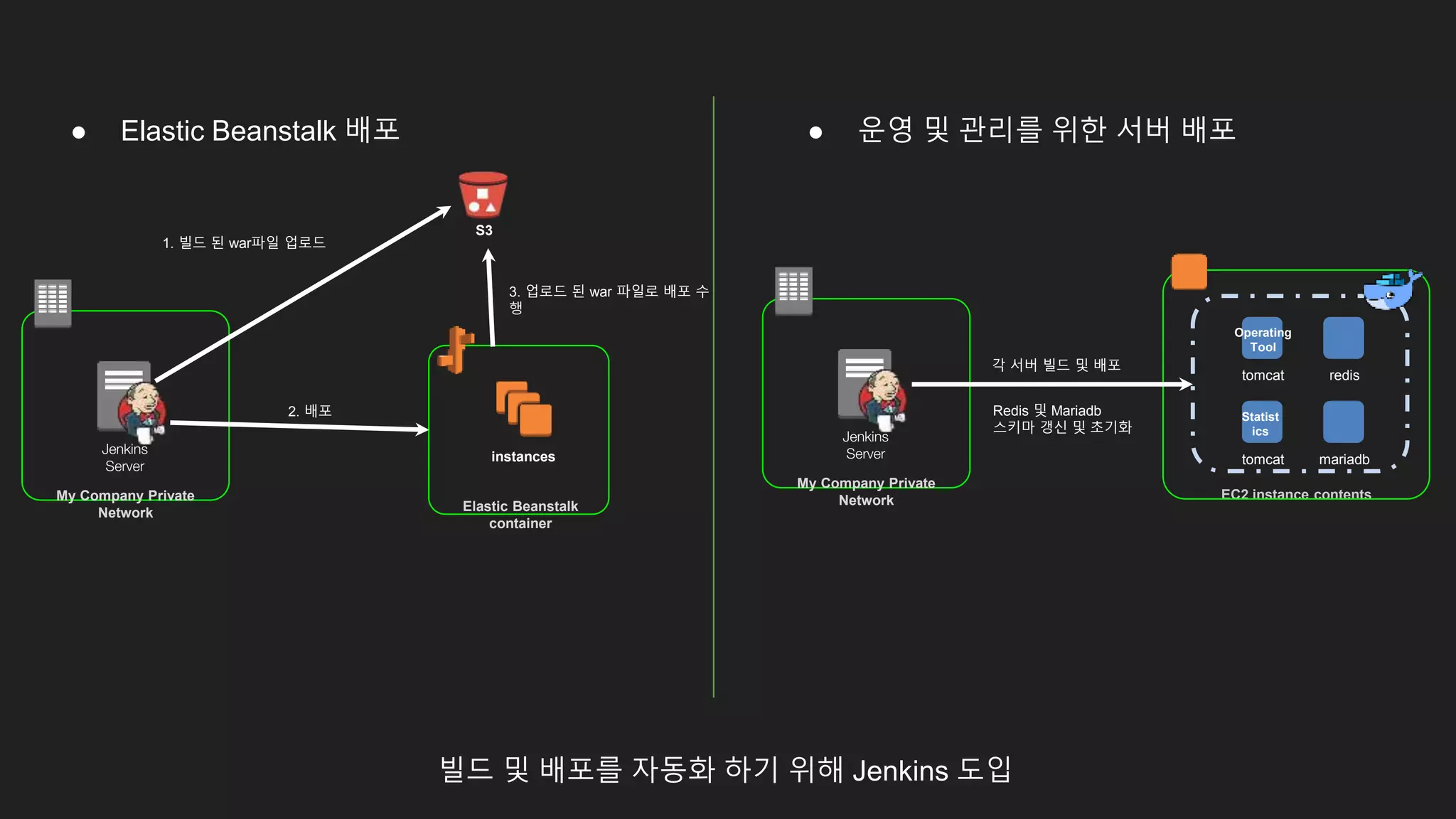
빌드 및 배포를자동화 하기 위해 Jenkins 도입
My Company Private
Network
Jenkins
Server
S3
Elastic Beanstalk
container
instances
1. 빌드 된 war파일 업로드
2. 배포
3. 업로드 된 war 파일로 배포 수
행
My Company Private
Network
Jenkins
Server
EC2 instance contents
tomcat
tomcat mariadb
redis
Operating
Tool
Statist
ics
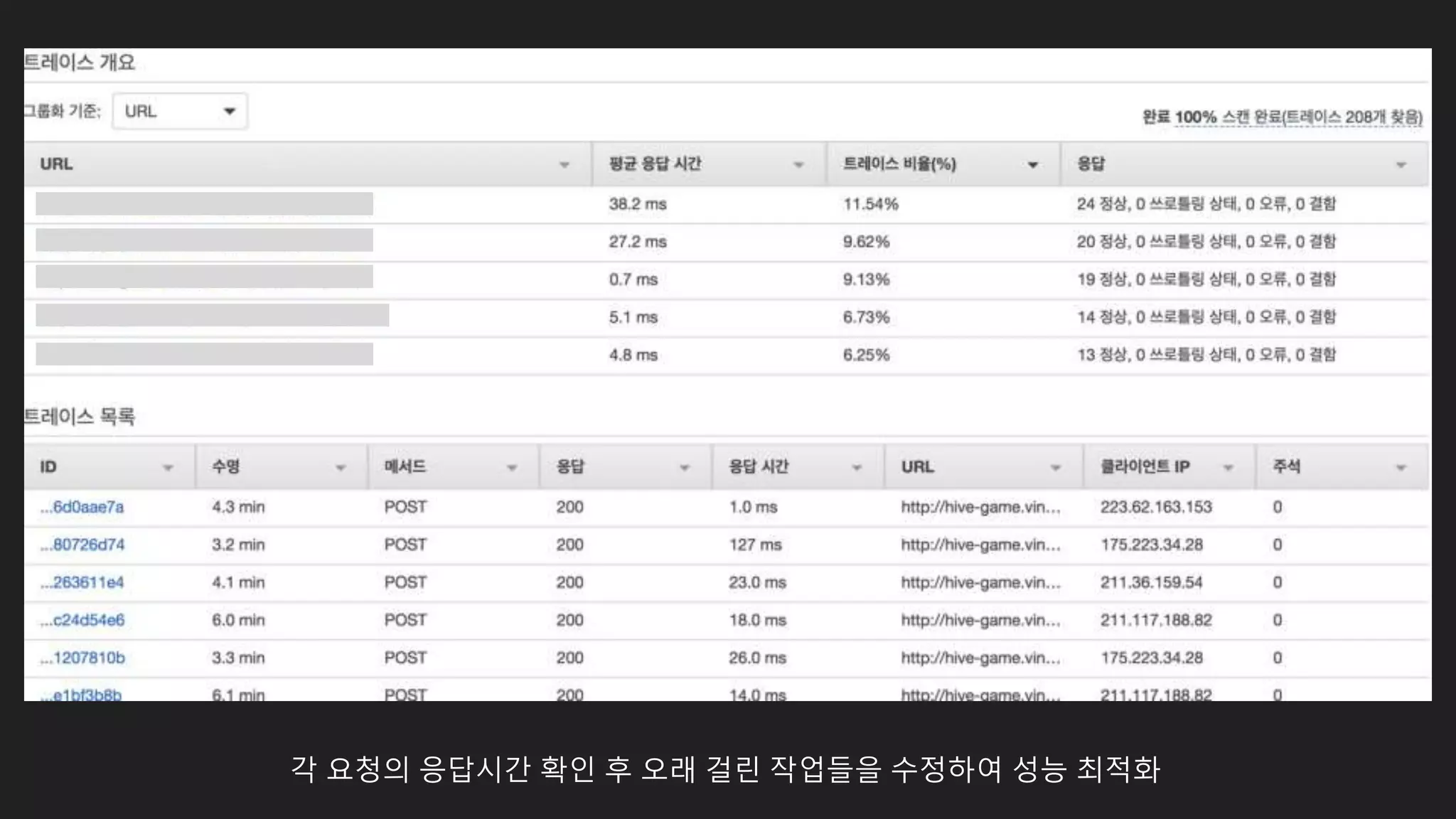
각 서버 빌드 및 배포
Redis 및 Mariadb
스키마 갱신 및 초기화
● Elastic Beanstalk 배포 ● 운영 및 관리를 위한 서버 배포
14.
docker-compose를 활용하여 10분내로 사내 환경 구성
tomcat
mariadb redis
Logstash elasticse
arch
kibanahttpd
Client
Pinpoint-
hbase
Pinpoint-
collector
Pinpoint-
web
Docker-
compose
Docker-
compos
e
Docker-
compose
Amazon
ECR
Jenkin
s
Kibana와 Pinpoint를 통해 서버 상태 확인
Docker Image들은 ECR을 사용하여 버
전 관리
사내 서버들의 빌드 및 배포는
Jenkins를 통해 자동화
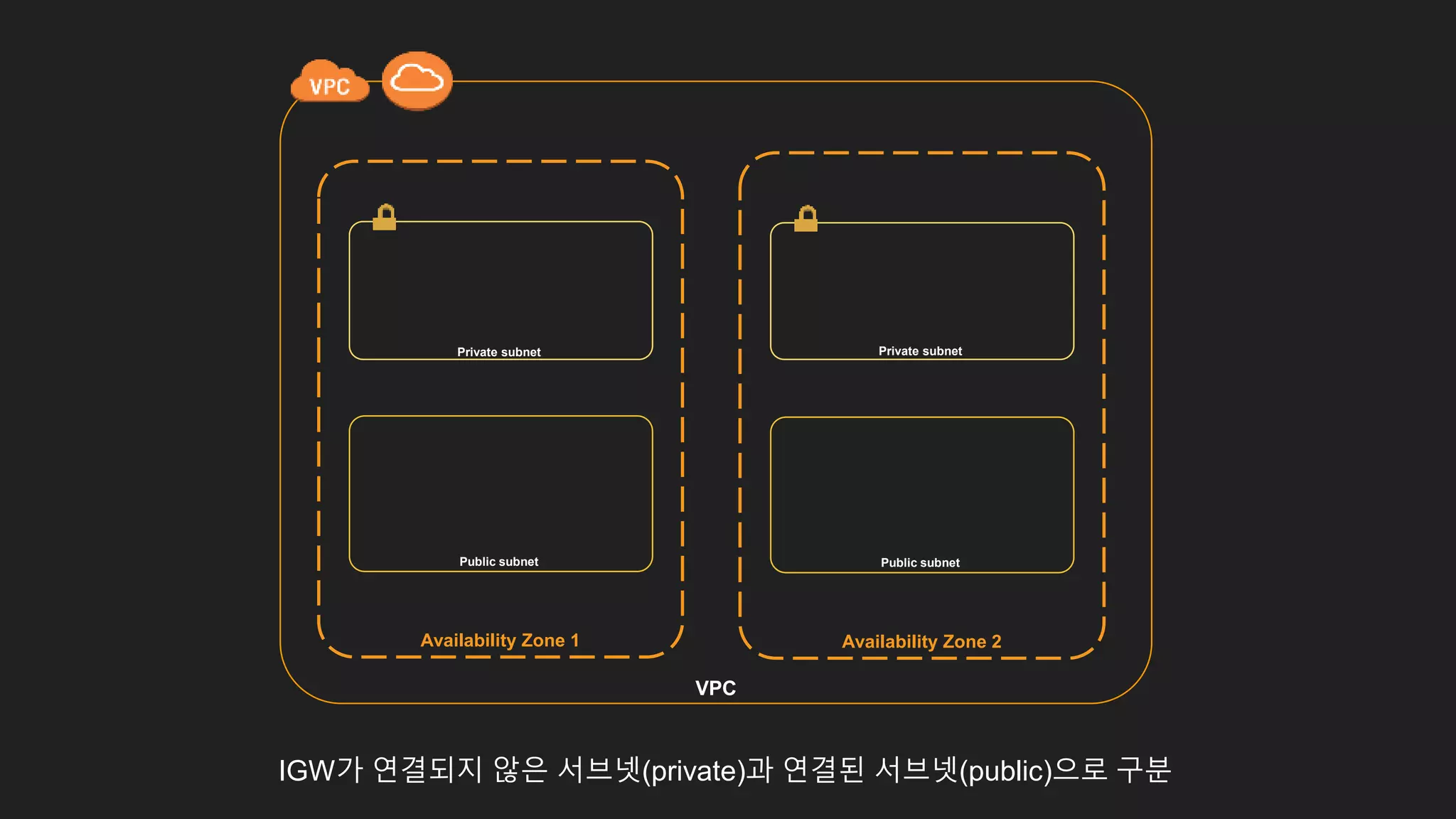
Availability Zone 1
Privatesubnet
Public subnet
Availability Zone 2
Private subnet
Public subnet
VPC
IGW가 연결되지 않은 서브넷(private)과 연결된 서브넷(public)으로 구분
23.
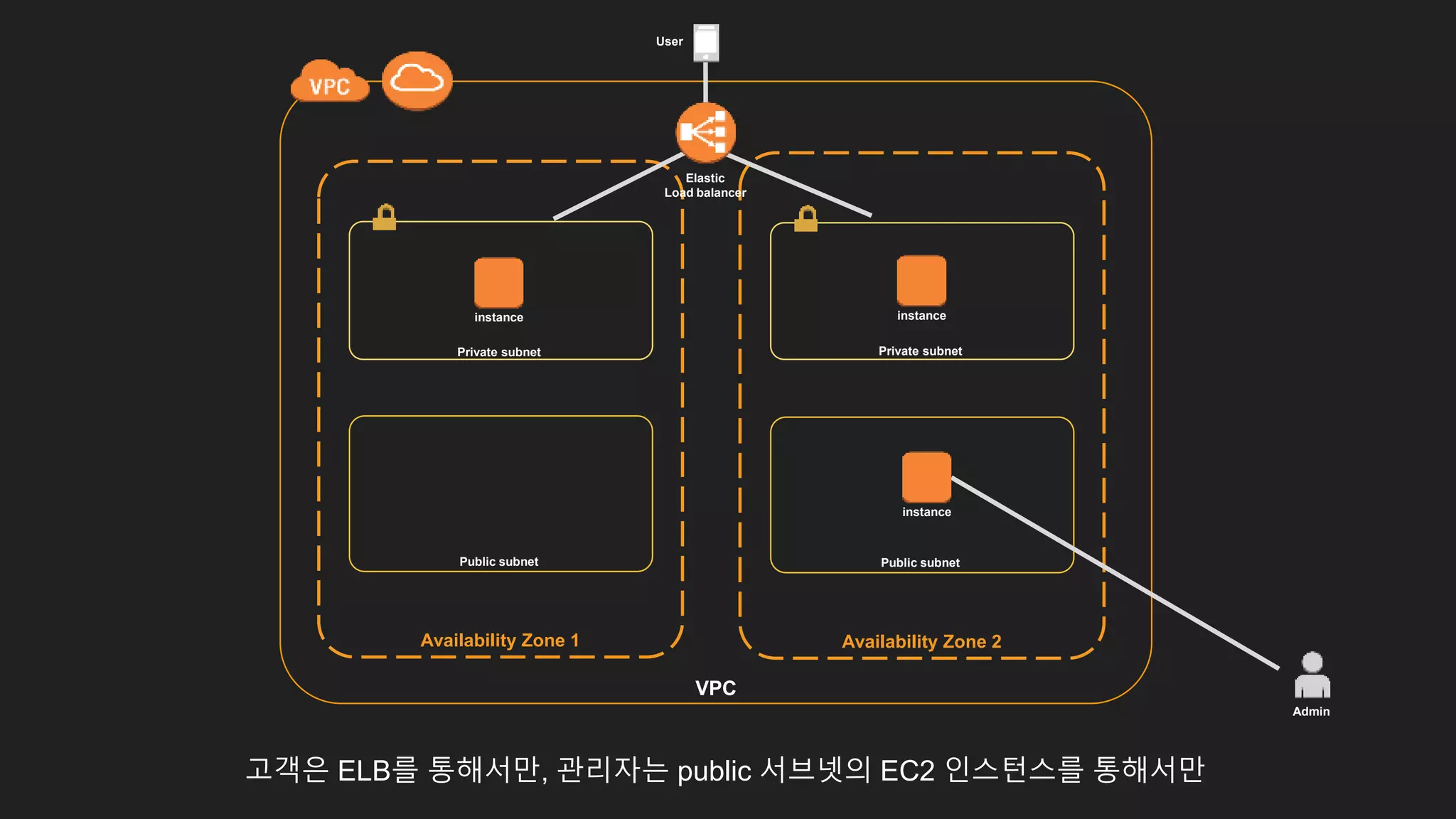
Availability Zone 1
Privatesubnet
Public subnet
Availability Zone 2
Private subnet
Public subnet
VPC
고객은 ELB를 통해서만, 관리자는 public 서브넷의 EC2 인스턴스를 통해서만
Elastic
Load balancer
User
Admin
instance
instance instance
24.
AWS 네트워크 신규기능업데이트 - 강동환 솔루션즈 아키텍트
https://youtu.be/FDFmI0nU4Wg
천만 사용자를 위한 AWS 아키텍처 보안 확장 모범 사례 - 윤석찬, 테크에반젤리스트
https://youtu.be/wn_-FtheGDY
가상 데이터 센터 만들기 - VPC 기본 및 연결 옵션 - 양승도 솔루션즈 아키텍트
https://youtu.be/R1UWYQYTPKo
미리 scale을 넉넉히걸어두고 한 머신에 구동될 수 있는 컨테이너를 제한하는 편법 사용
docker service create --name test-tomcat --publish 8080:8080 --reserve-cpu 1 tomcat
docker service scale test-tomcat=100
34.
해 놓고 보니scale 명령으로 유연한 컨테이너 구동의 장점이 사라짐
결국 우리 서비스에서 docker를 활용하는 것은 욕심이라 판단.
docker service create --name test-tomcat --publish 8080:8080 --reserve-cpu 1 tomcat
docker service scale test-tomcat=100
AWS와 Docker Swarm을이용한 쉽고 빠른 컨테이너 오케스트레이션 -
김충섭 개발자(퍼플웍스)
https://youtu.be/16LNWMqphOA
[AWS] EC2 인스턴스에서 docker swarm 서비스를 통해 웹서버 구동 및 확장
http://yongho1037.tistory.com/729
Java 기반이고 익숙한IDE에서 자유롭게 개발 후
jar파일을 배포하여 사용할 수 있기 때문에 선택
47.
머신만 확장하면 무제한의유저를 유입시킬 수 있는 구조가 목표
instances
instance
instance
instance
Classic
Load
Balancer
JMeter
JMeter
JMeter
48.
스팟 인스턴스, ssm,jmeter를 활용하여 부하테스트
instance
Spot
Instance
ssm
bucket
Output Log
Run Command
instances
부하 전달
Loadtest
Server
Spot
Instance
Spot
Instance
스팟 인스턴스를 생성하고,
생성된 인스턴스들에 대한 상태 확인과
명령을 내리기 위한 서버
Classic
Load
Balancer
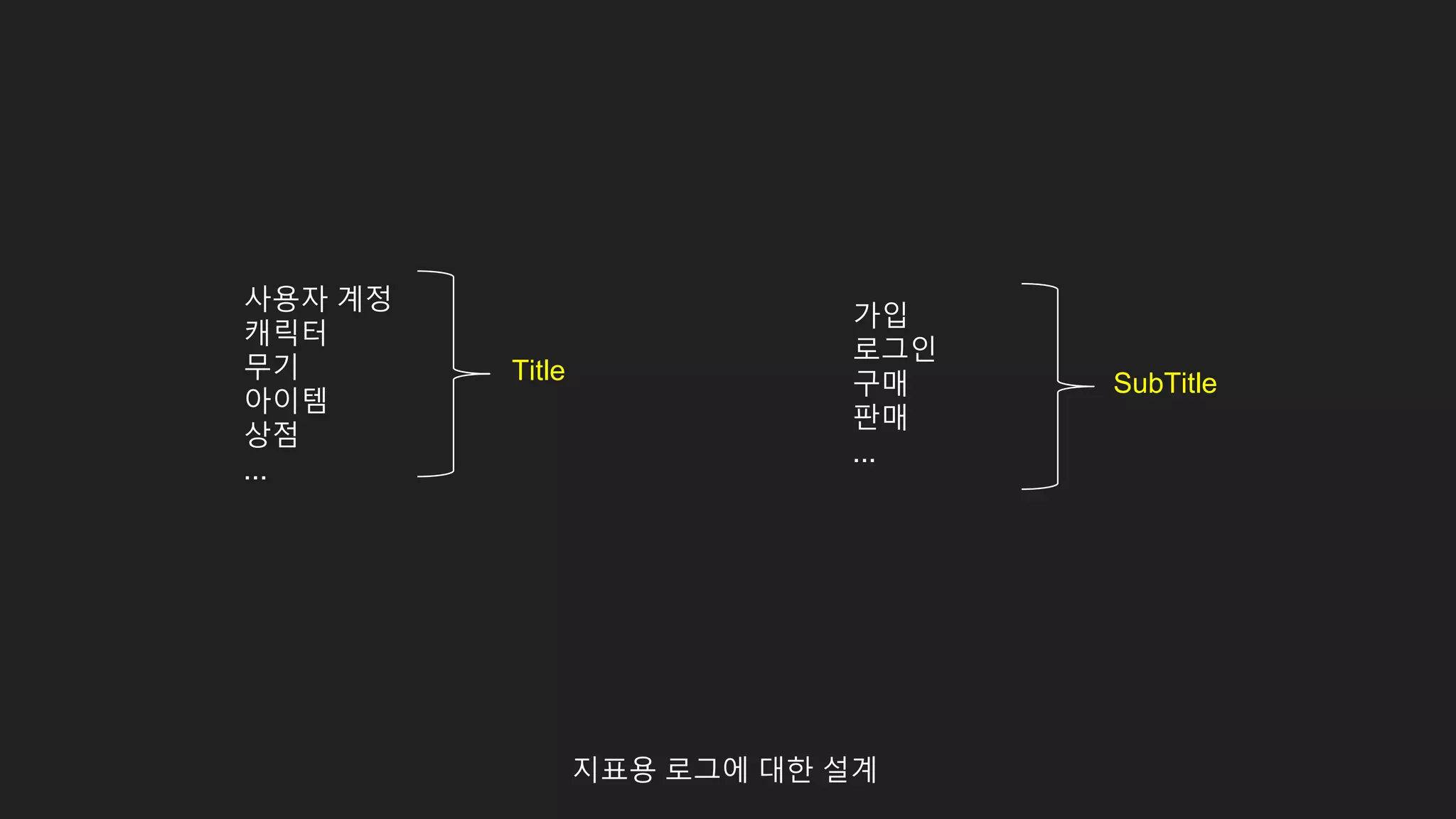
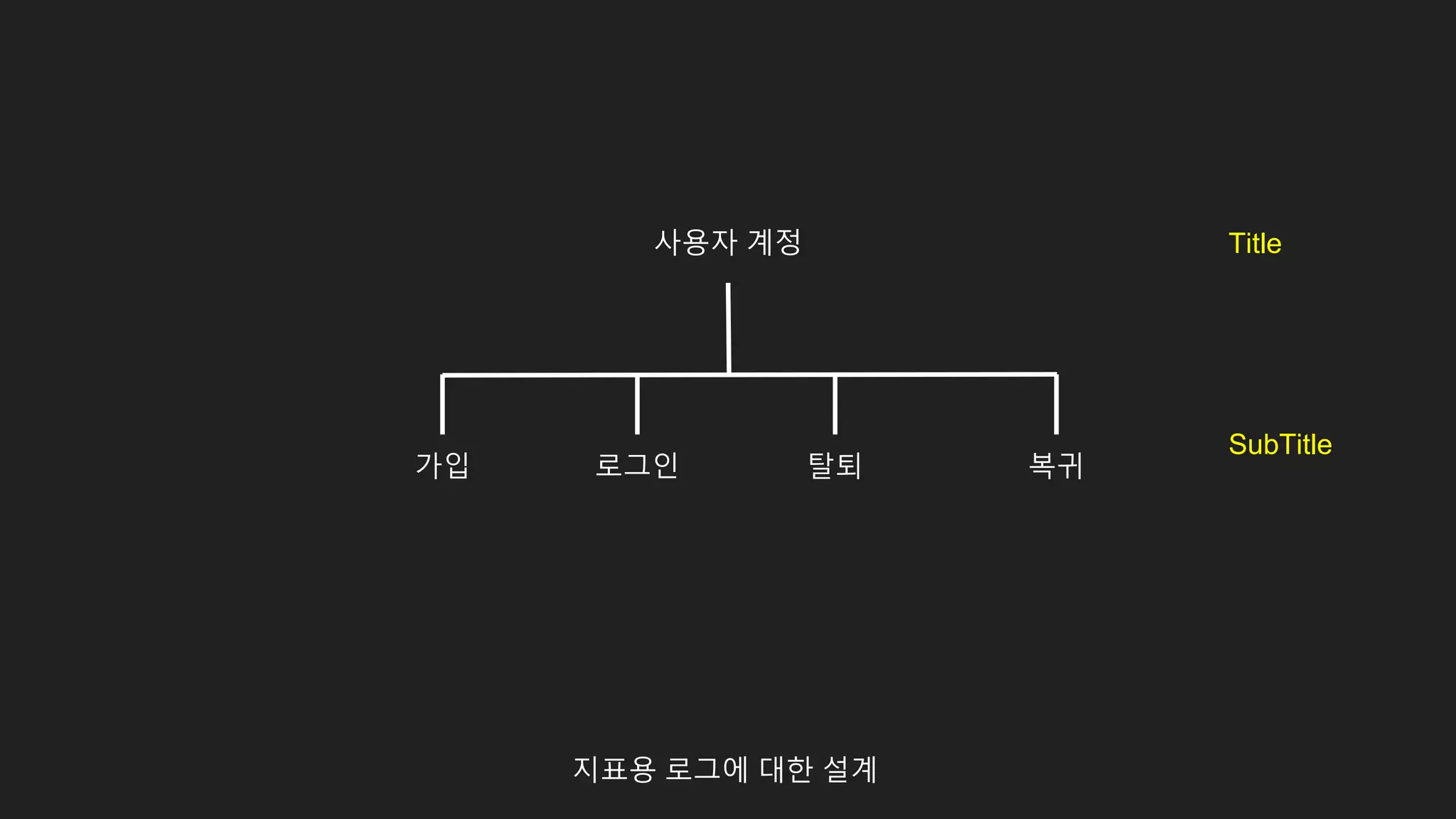
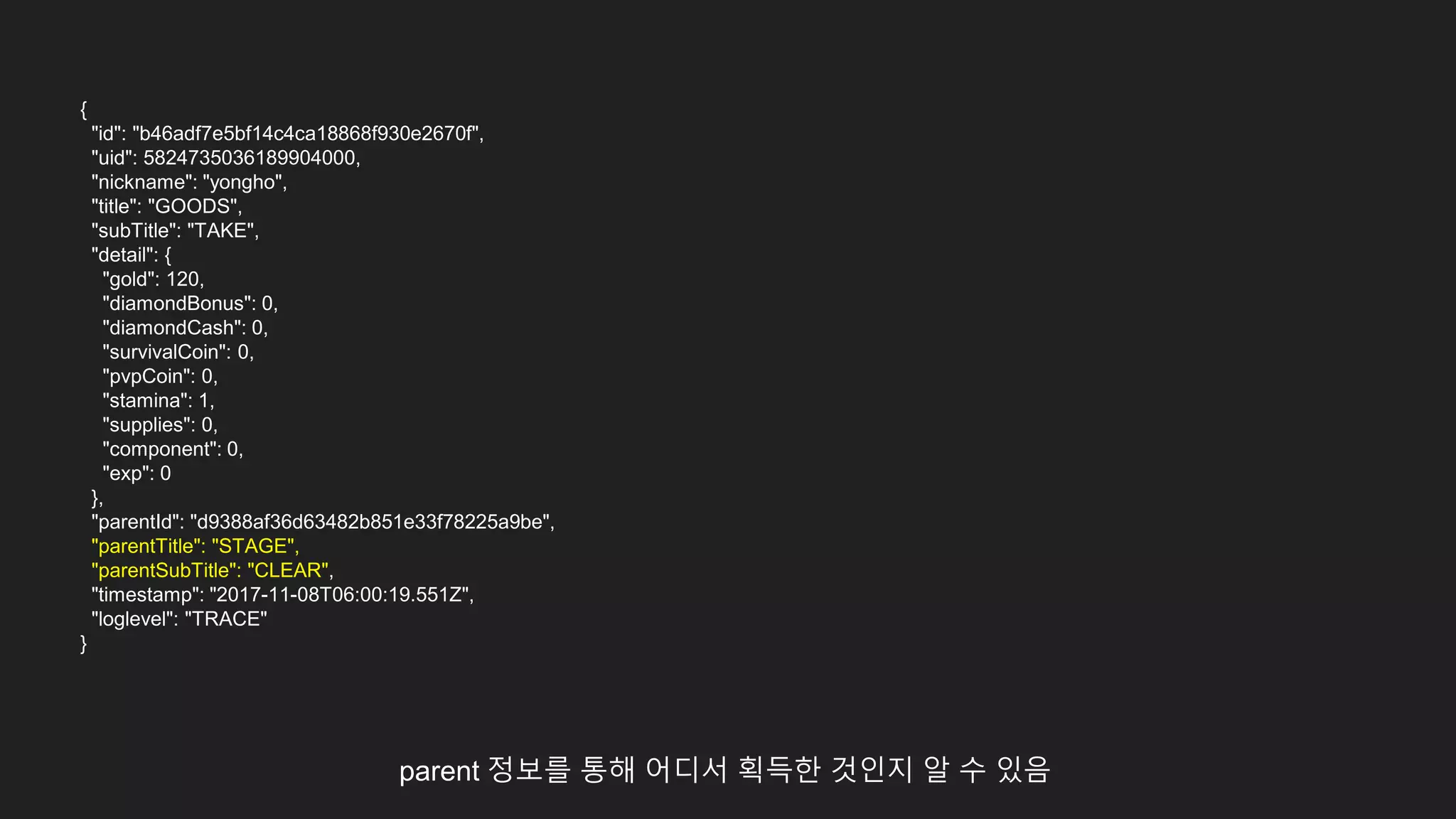
id값을 통해 사용자행위에 연관된 데이터 탐색
스테이지 클리어
재화 획득
아이템 획득
캐릭터 획득
경험치 획득
퀘스트 달성
...
ID : 10000
ID : 10001, parentID : 10000
ID : 10002, parentID : 10000
ID : 10003, parentID : 10000
ID : 10004, parentID : 10000
ID : 10005, parentID : 10000
내가 만든 UUID로_id를 사용했다가 균등하게 분배가 안되면 어쩌지?
_id % ShardSize
68.
final int SHARD_SIZE= 5;
int[] shards = new int[SHARD_SIZE];
for(int i = 0; i < 100000; i++) {
int hash =
Math.abs(Murmur3HashFunction.hash(String.valueOf(i)));
int shardId = hash % SHARD_SIZE;
shards[shardId]++;
Thread.sleep(1);
}
for(int i = 0; i < SHARD_SIZE; i++) {
System.out.println(String.format("shardId : %d,
count : %d", i, shards[i]));
}
엘라스틱서치에서 샤드 분배하는 로직을 가져다 테스트
69.
final int SHARD_SIZE= 5;
int[] shards = new int[SHARD_SIZE];
for(int i = 0; i < 100000; i++) {
int hash =
Math.abs(Murmur3HashFunction.hash(String.valueOf(i)));
int shardId = hash % SHARD_SIZE;
shards[shardId]++;
Thread.sleep(1);
}
for(int i = 0; i < SHARD_SIZE; i++) {
System.out.println(String.format("shardId : %d,
count : %d", i, shards[i]));
}
// 결과
shardId : 0, count : 19740
shardId : 1, count : 20016
shardId : 2, count : 19905
shardId : 3, count : 20032
shardId : 4, count : 20307
거의 균등하게 document가 분배됨
70.
final int SHARD_SIZE= 5;
int[] shards = new int[SHARD_SIZE];
for(int i = 0; i < 100000; i++) {
int hash =
Math.abs(Murmur3HashFunction.hash(String.valueOf(i)));
int shardId = hash % SHARD_SIZE;
shards[shardId]++;
Thread.sleep(1);
}
for(int i = 0; i < SHARD_SIZE; i++) {
System.out.println(String.format("shardId : %d,
count : %d", i, shards[i]));
}
// 결과
shardId : 0, count : 19740
shardId : 1, count : 20016
shardId : 2, count : 19905
shardId : 3, count : 20032
shardId : 4, count : 20307
id 필드를 따로 만들지 않고 샤드 분배 걱정 없이
_id를 직접 할당해서 사용하는 것이 더 효율적일 듯
71.
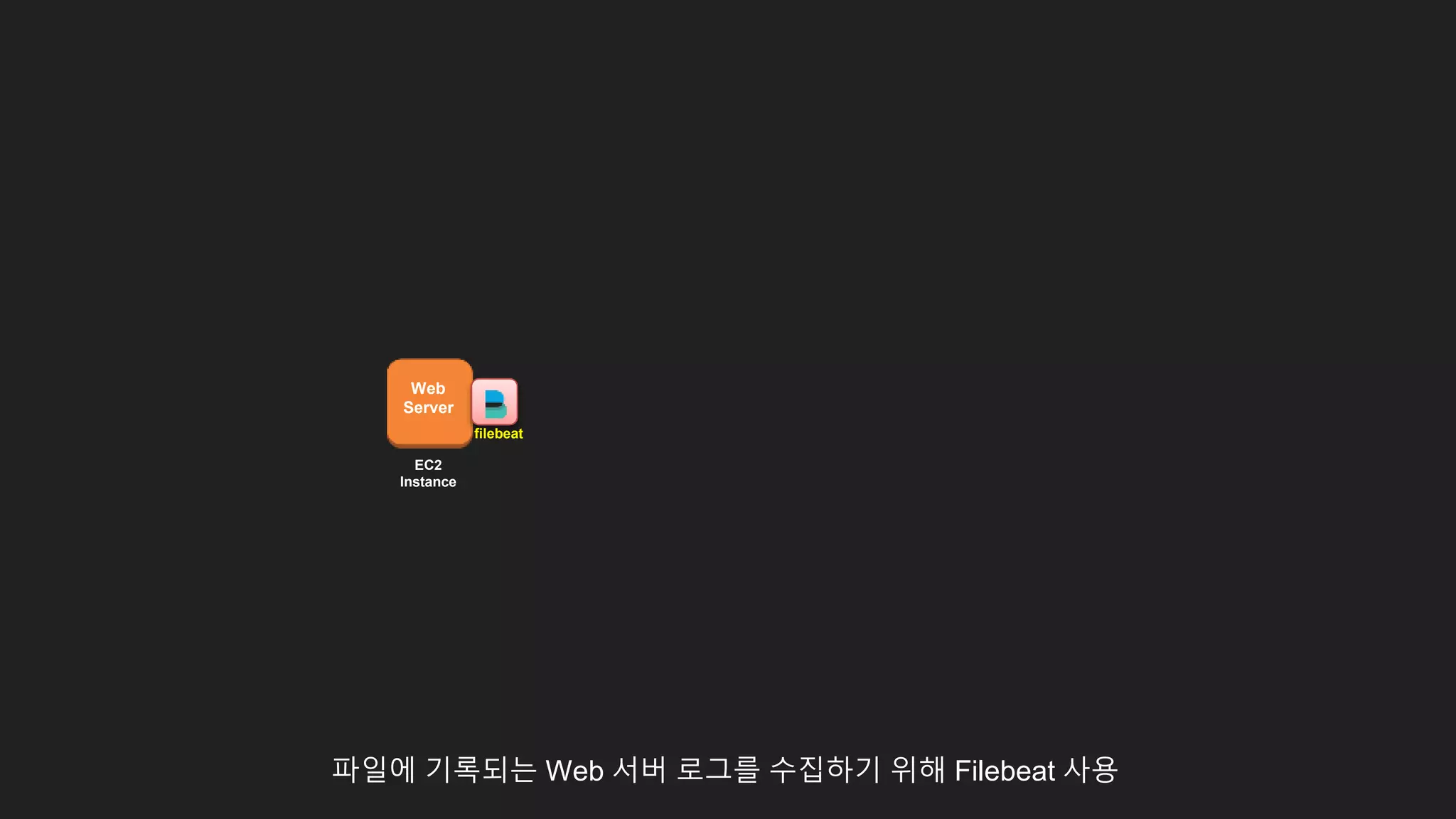
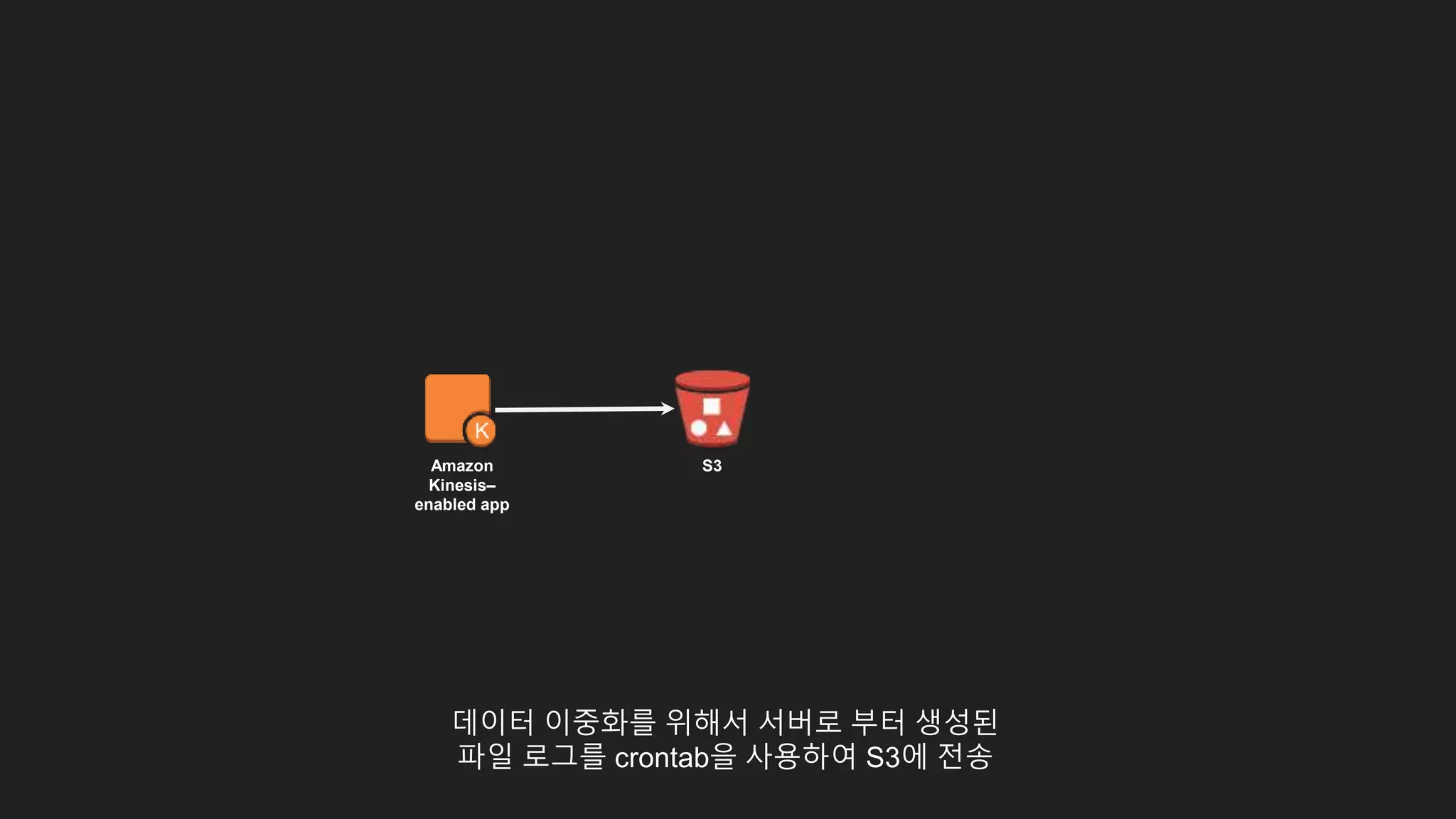
파일에 기록되는 Web서버 로그를 수집하기 위해 Filebeat 사용
Web
Server
EC2
Instance
filebeat
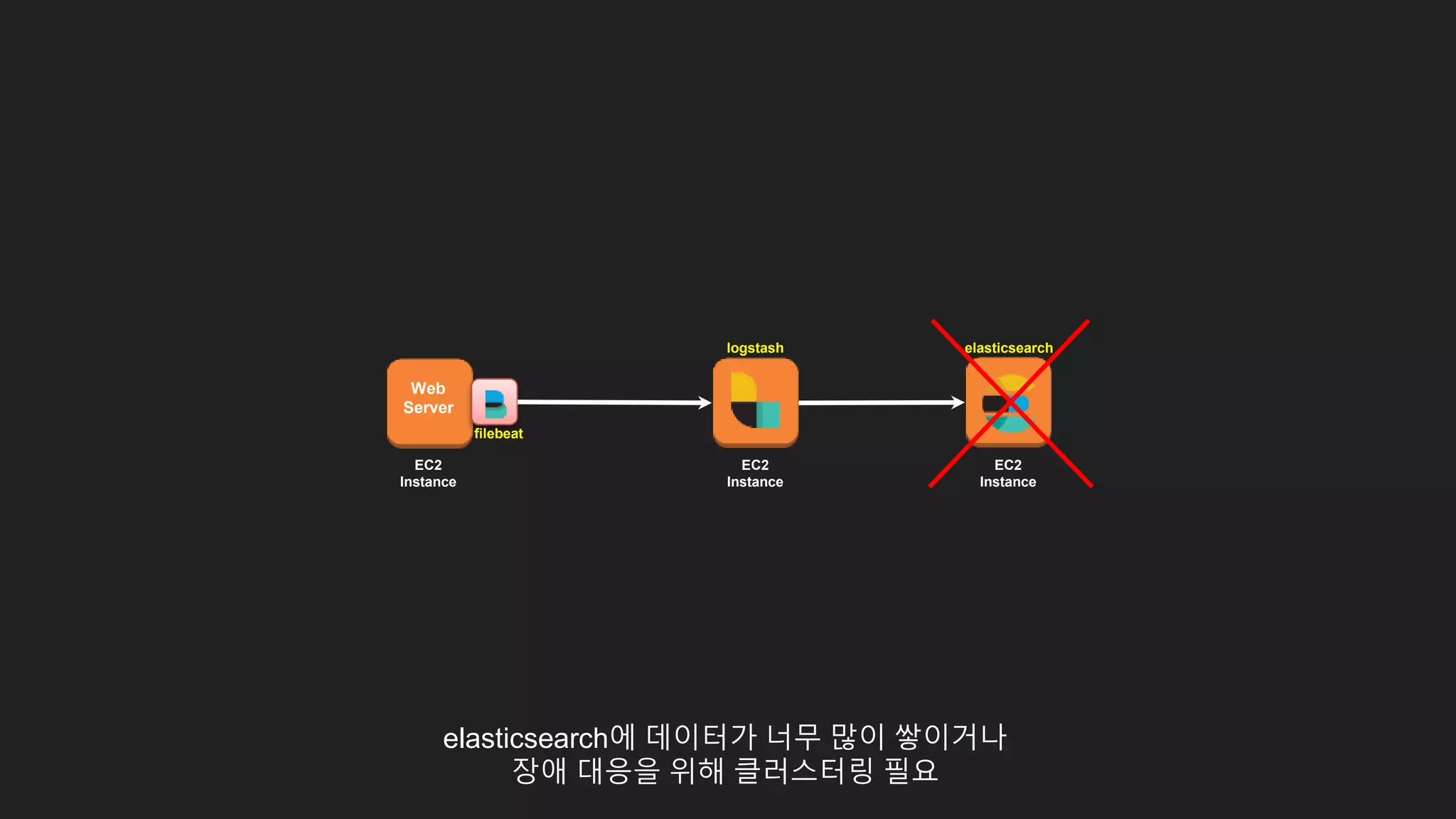
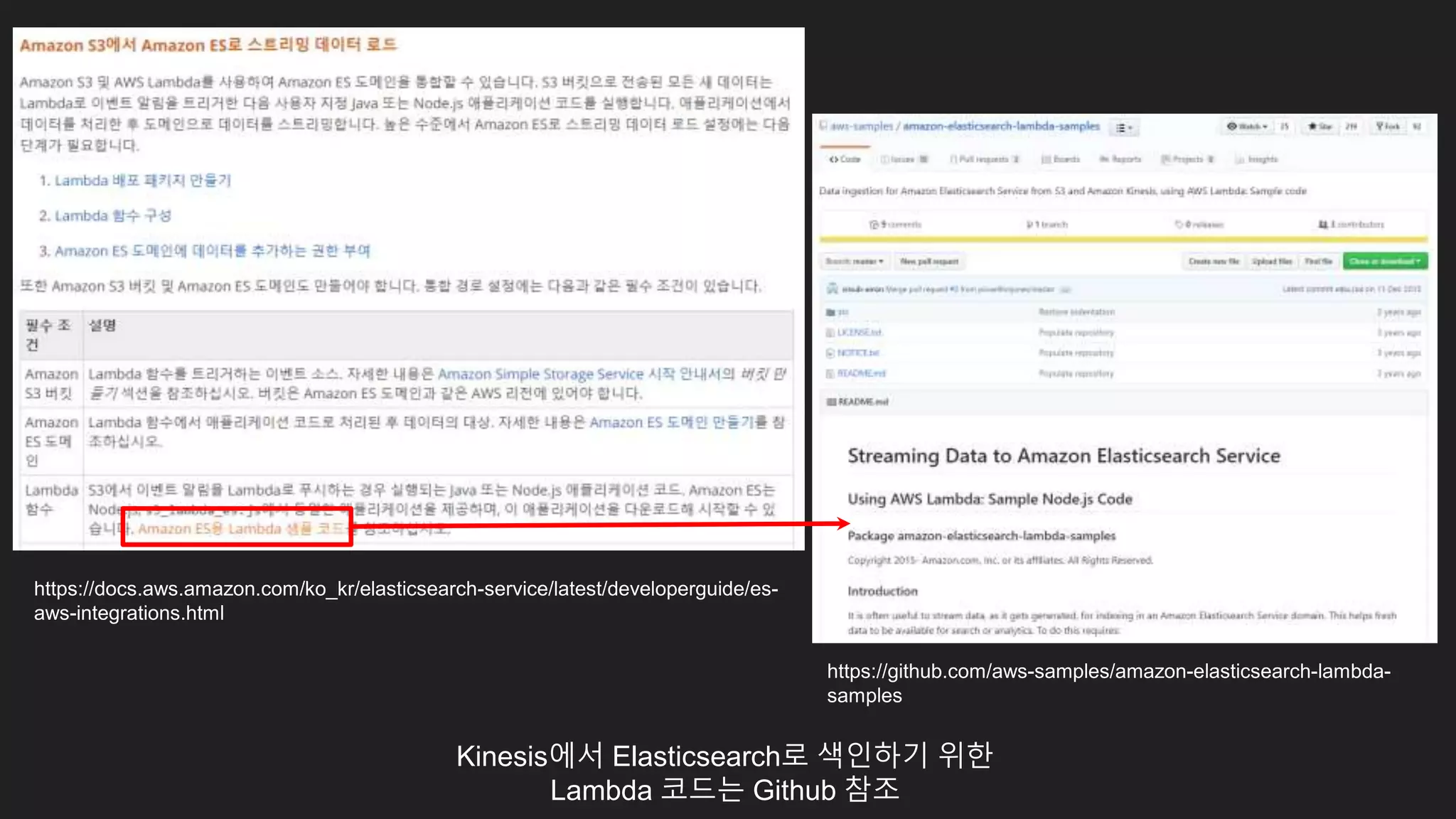
Filebeat 대신 KinesisAgent 사용
ElasticsearchAmazon
Kinesis
Streams
Lambda
function
Amazon
Kinesis–
enabled app
84.
Logstash 대신 Kinesis를통해 데이터를 받아
Lambda를 통해 데이터 가공
ElasticsearchAmazon
Kinesis
Streams
Lambda
function
Amazon
Kinesis–
enabled app
85.
EC2 인스턴스에 설치형Elasticsearch 대신 Amazon Elasticsearch Service 사용
ElasticsearchAmazon
Kinesis
Streams
Lambda
function
Amazon
Kinesis–
enabled app
86.
AWS 빅데이터 아키텍처패턴 및 모범 사례
- 남궁영환 빅데이터 컨설턴트(AWS 코리아)
https://www.youtube.com/watch?v=D1yxmpD4VDc
AWS Summit Seoul 2016 - Amazon Kinesis 와 Elasticsearch 서
비스로 만드는 실시간 데이터 분석 플랫폼 (박철수, AWS)
https://www.youtube.com/watch?v=SHVWcAW4RQ8&t=1645s
VPC
Availability Zone 1
Privatesubnet
Public subnet
Availability Zone 2
Private subnet
Public subnet
Elastic Beanstalk container
Auto Scaling group
instance instanceAurora ElastiCache
Redis
ElastiCache
Redis
Aurora
instance
Classic
Load
Balancer
NAT
Gateway
Route 53
User
CloudFront S3
ElasticsearchAmazon
Kinesis
Streams
Lambda
function
Web
Serv
er
Web
Server
Operating
Tool
instance
Statistics
Server
Amazon
CloudWatch
SMS
API Provider
Admin
Amazon
Athena
Log data
Statistics
data
Client Resource
instance
Bastion
X-ray
































![AWS와 Docker Swarm을 이용한 쉽고 빠른 컨테이너 오케스트레이션 -
김충섭 개발자(퍼플웍스)
https://youtu.be/16LNWMqphOA
[AWS] EC2 인스턴스에서 docker swarm 서비스를 통해 웹서버 구동 및 확장
http://yongho1037.tistory.com/729](https://image.slidesharecdn.com/mobilegamehiveyonghochoi-180228094004/75/slide-36-2048.jpg)




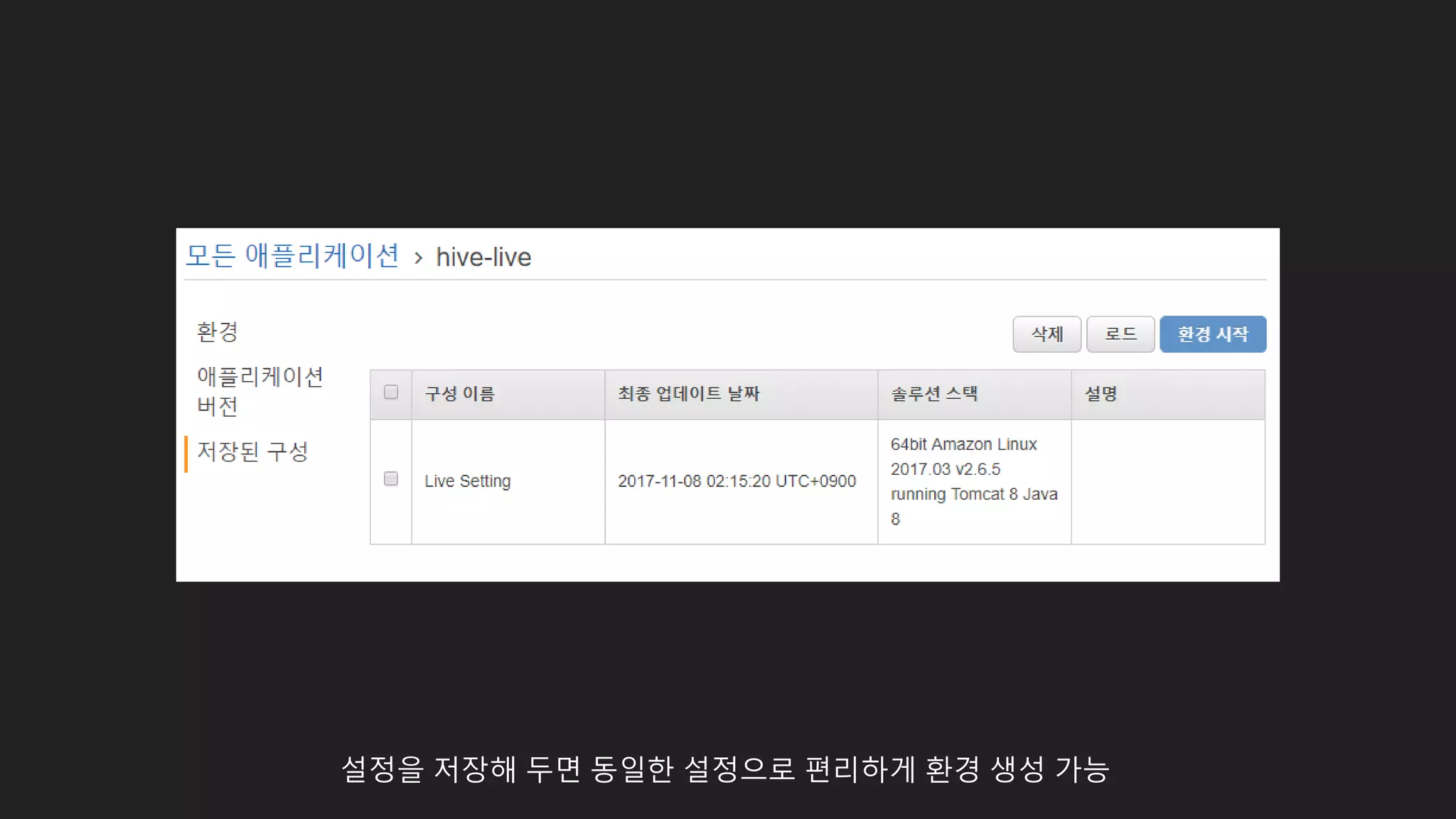


![[AWS] Elastic Beanstalk 생성과 Hook, .ebextensions를 통해 EC2 인스턴스 설정
http://yongho1037.tistory.com/731](https://image.slidesharecdn.com/mobilegamehiveyonghochoi-180228094004/75/slide-44-2048.jpg)


















![final int SHARD_SIZE = 5;
int[] shards = new int[SHARD_SIZE];
for(int i = 0; i < 100000; i++) {
int hash =
Math.abs(Murmur3HashFunction.hash(String.valueOf(i)));
int shardId = hash % SHARD_SIZE;
shards[shardId]++;
Thread.sleep(1);
}
for(int i = 0; i < SHARD_SIZE; i++) {
System.out.println(String.format("shardId : %d,
count : %d", i, shards[i]));
}
엘라스틱서치에서 샤드 분배하는 로직을 가져다 테스트](https://image.slidesharecdn.com/mobilegamehiveyonghochoi-180228094004/75/slide-68-2048.jpg)
![final int SHARD_SIZE = 5;
int[] shards = new int[SHARD_SIZE];
for(int i = 0; i < 100000; i++) {
int hash =
Math.abs(Murmur3HashFunction.hash(String.valueOf(i)));
int shardId = hash % SHARD_SIZE;
shards[shardId]++;
Thread.sleep(1);
}
for(int i = 0; i < SHARD_SIZE; i++) {
System.out.println(String.format("shardId : %d,
count : %d", i, shards[i]));
}
// 결과
shardId : 0, count : 19740
shardId : 1, count : 20016
shardId : 2, count : 19905
shardId : 3, count : 20032
shardId : 4, count : 20307
거의 균등하게 document가 분배됨](https://image.slidesharecdn.com/mobilegamehiveyonghochoi-180228094004/75/slide-69-2048.jpg)
![final int SHARD_SIZE = 5;
int[] shards = new int[SHARD_SIZE];
for(int i = 0; i < 100000; i++) {
int hash =
Math.abs(Murmur3HashFunction.hash(String.valueOf(i)));
int shardId = hash % SHARD_SIZE;
shards[shardId]++;
Thread.sleep(1);
}
for(int i = 0; i < SHARD_SIZE; i++) {
System.out.println(String.format("shardId : %d,
count : %d", i, shards[i]));
}
// 결과
shardId : 0, count : 19740
shardId : 1, count : 20016
shardId : 2, count : 19905
shardId : 3, count : 20032
shardId : 4, count : 20307
id 필드를 따로 만들지 않고 샤드 분배 걱정 없이
_id를 직접 할당해서 사용하는 것이 더 효율적일 듯](https://image.slidesharecdn.com/mobilegamehiveyonghochoi-180228094004/75/slide-70-2048.jpg)


























![[AWSKRUG] 모바일게임 하이브 런칭기 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/awskrugawsformobilegame-190419125248-thumbnail.jpg?width=640&height=640&fit=bounds)







![[NDC2017 : 박준철] Python 게임 서버 안녕하십니까 - 몬스터 슈퍼리그 게임 서버](https://cdn.slidesharecdn.com/ss_thumbnails/ndc17python-0425v08-170426123108-thumbnail.jpg?width=640&height=640&fit=bounds)













![[KGC 2013] Online Game Security in China](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2013-20130926-23-f-s-130926030828-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AWS Summit 2018] 모바일 게임을 만들기 위한 AWS 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/awssummit2018awsformobilegame-190419125927-thumbnail.jpg?width=640&height=640&fit=bounds)
![[넥슨토크] 모바일게임 하이브 런칭기 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/nexontalkawsformobilegame-190419125718-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DDD] 모바일 게임을 만들기 위한 AWS 고군분투기 (2019)](https://cdn.slidesharecdn.com/ss_thumbnails/dddawsformobilegame-190420044903-thumbnail.jpg?width=640&height=640&fit=bounds)








![[Partner TechShift 2017] 클라우드 시대 기존 Legacy에서 벗어나는 방법](https://cdn.slidesharecdn.com/ss_thumbnails/6-171101053200-thumbnail.jpg?width=640&height=640&fit=bounds)
![PUBG: Battlegrounds 라이브 서비스 EKS 전환 사례 공유 [크래프톤 - 레벨 300] - 발표자: 김정헌, PUBG Dev...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s2-221108101842-328d500f-thumbnail.jpg?width=640&height=640&fit=bounds)















![[For.D] 개발자 경력을 위한 소프트 스킬 (2019)](https://cdn.slidesharecdn.com/ss_thumbnails/softskill-for-developer-190430012136-thumbnail.jpg?width=640&height=640&fit=bounds)
![[자바카페] Elasticsearch Aggregation (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/javacafeelasticsearchaggregation-190419163225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GCP Summit 2018] Kubernetes with Nginx and Elasticsearch on GCP](https://cdn.slidesharecdn.com/ss_thumbnails/gcp-summit-2018-javacafe-190419130459-thumbnail.jpg?width=640&height=640&fit=bounds)
![[넥슨] kubernetes 소개 (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/gcdkubernetes-190419130148-thumbnail.jpg?width=640&height=640&fit=bounds)
![[자바카페] Infra CI (2018)](https://cdn.slidesharecdn.com/ss_thumbnails/infraci-190419125511-thumbnail.jpg?width=640&height=640&fit=bounds)
![[자바카페] 람다 아키텍처, 더 깊이 살펴보기](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatastudylabdadeepdive-190419125137-thumbnail.jpg?width=640&height=640&fit=bounds)
![[자바카페] 람다 일괄처리 계층 사례](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatalambdabatchexample-190419125030-thumbnail.jpg?width=640&height=640&fit=bounds)
![[자바카페] 람다 일괄처리 계층](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatalambdabatch-190419124939-thumbnail.jpg?width=640&height=640&fit=bounds)
![[자바카페] Amazon Elastic Beanstalk 소개 (2017)](https://cdn.slidesharecdn.com/ss_thumbnails/amazonelasticbeanstalkv2-190419124246-thumbnail.jpg?width=640&height=640&fit=bounds)
![[자바카페] 자바 객체지향 프로그래밍 (2017)](https://cdn.slidesharecdn.com/ss_thumbnails/javacafejavaoop2017-190419123905-thumbnail.jpg?width=640&height=640&fit=bounds)
