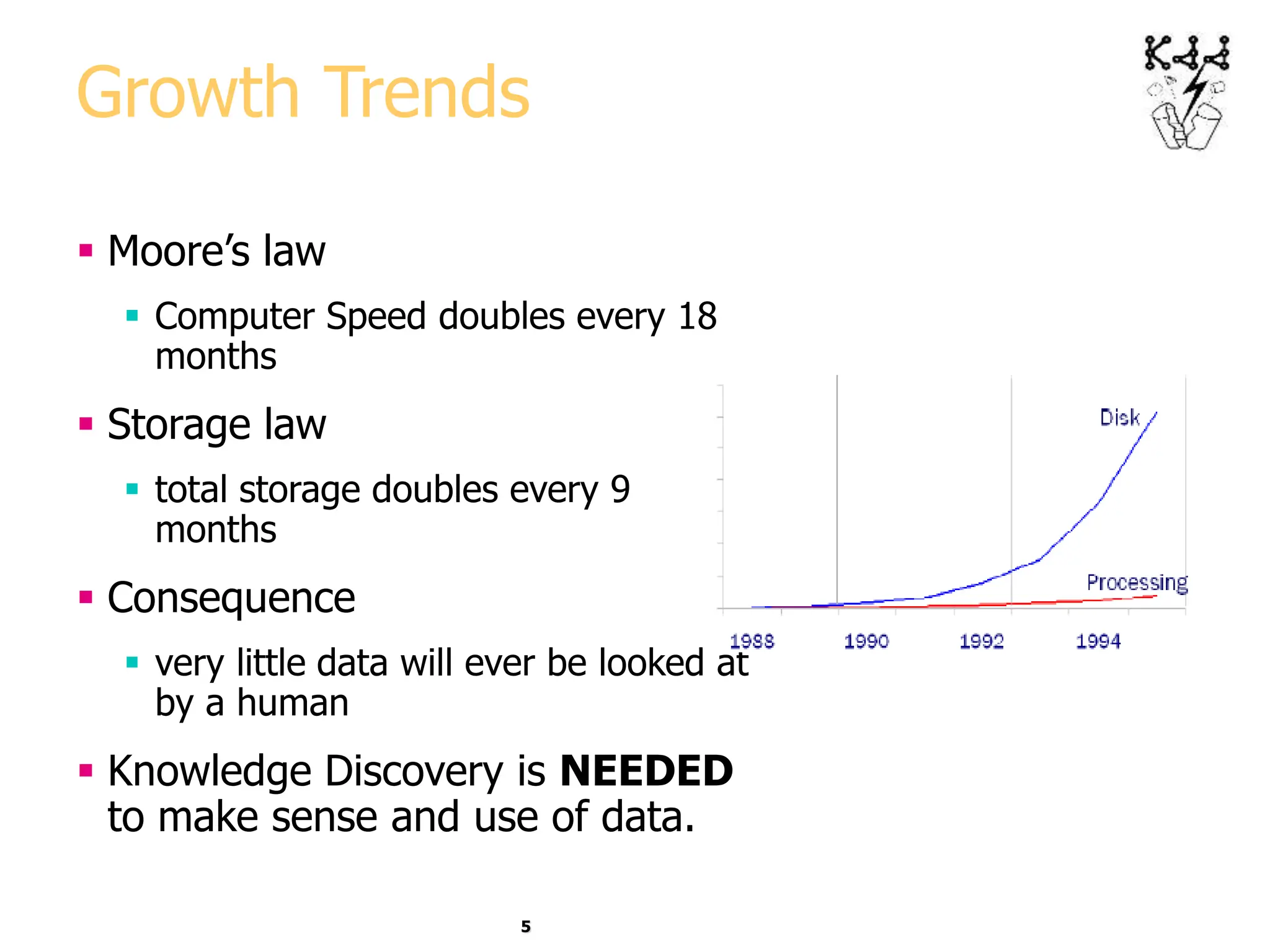
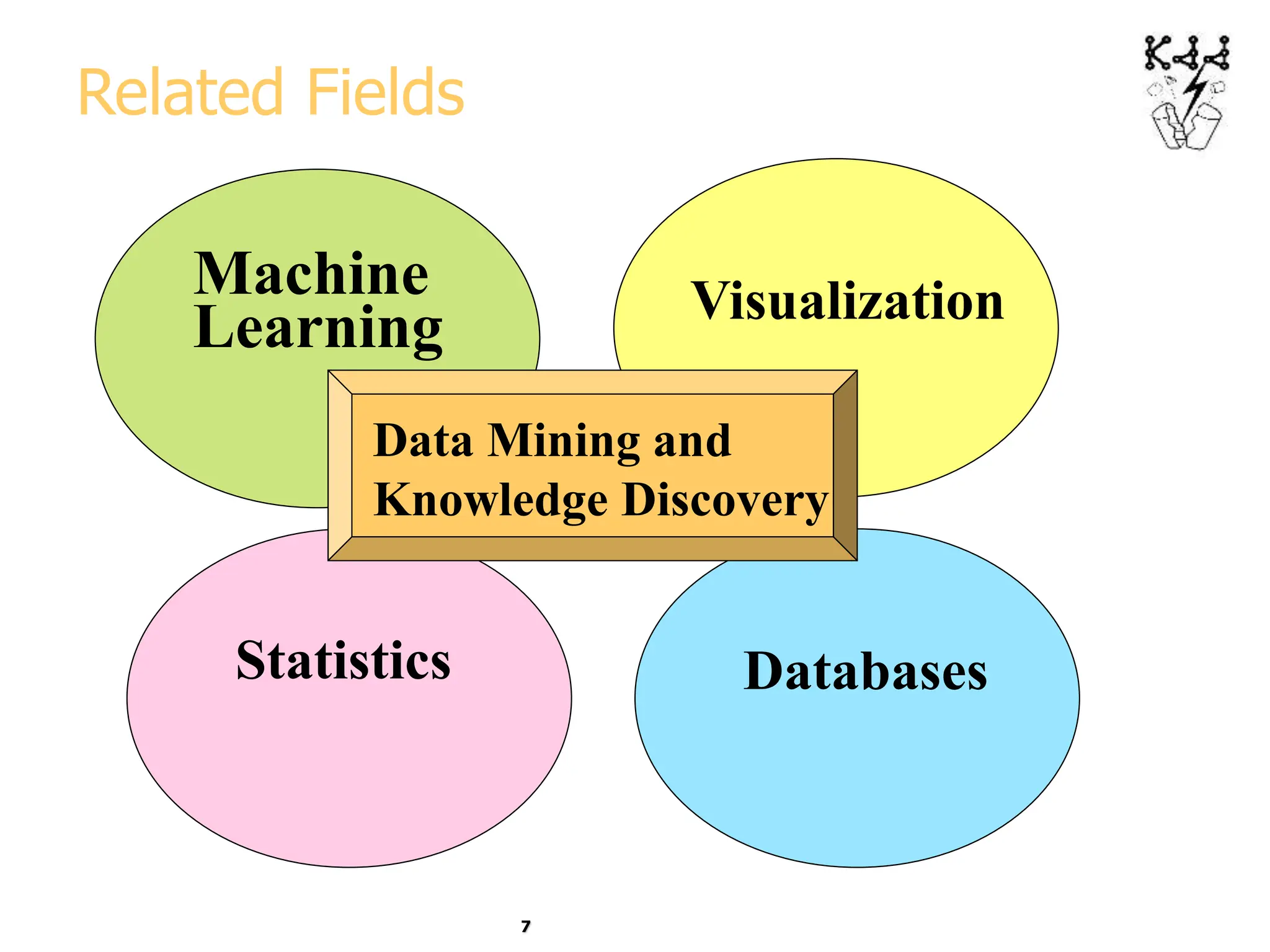
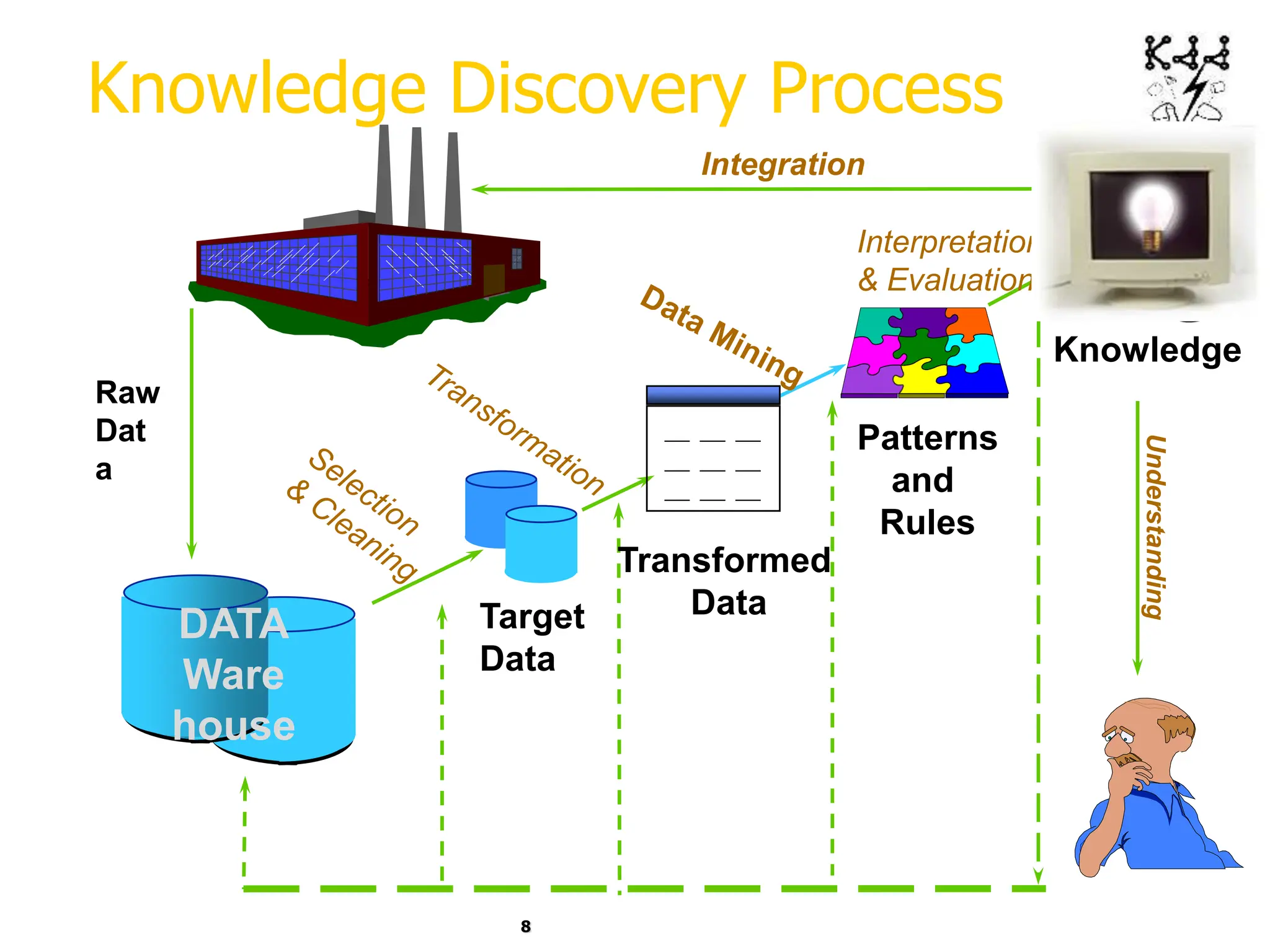
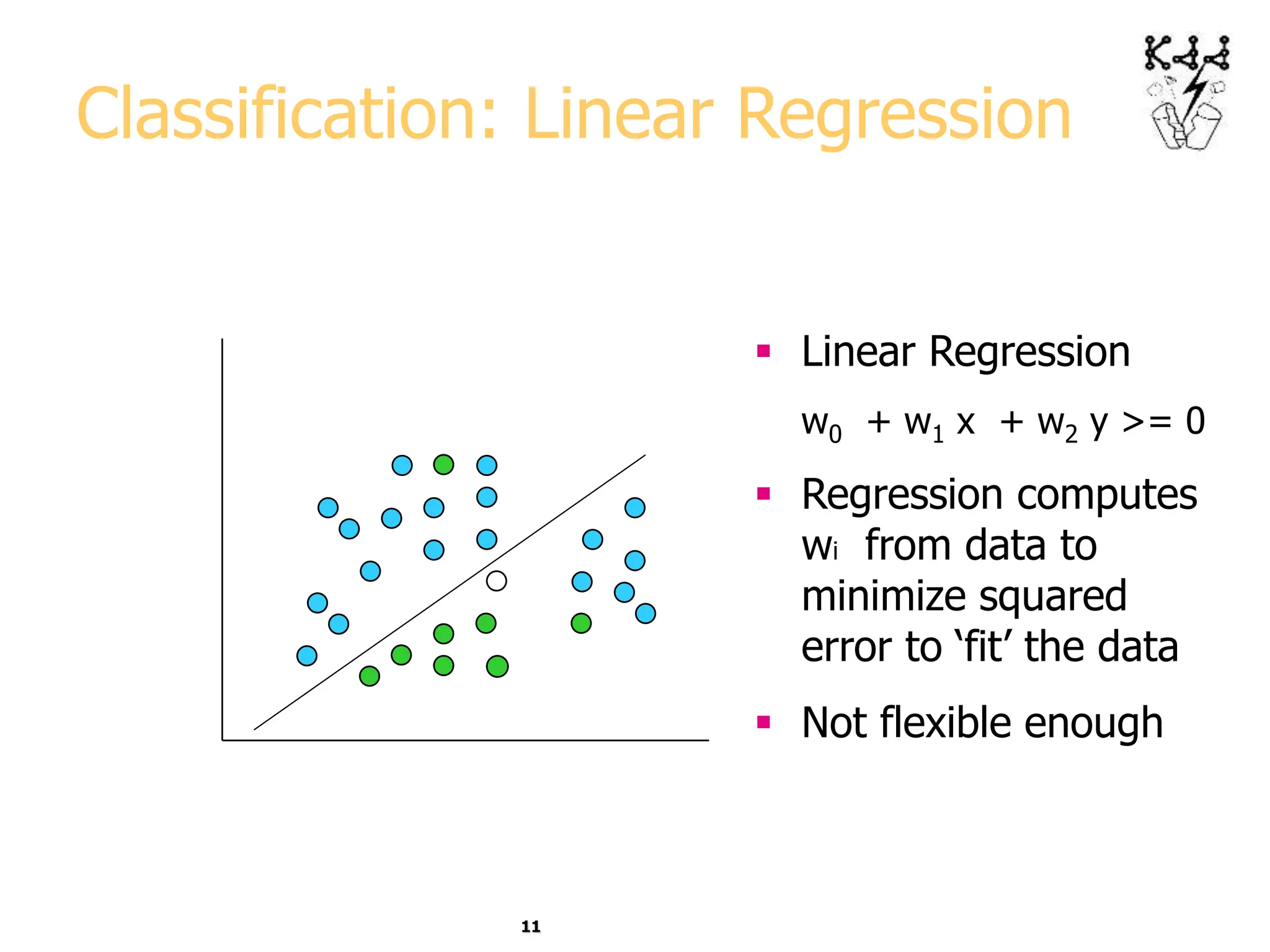
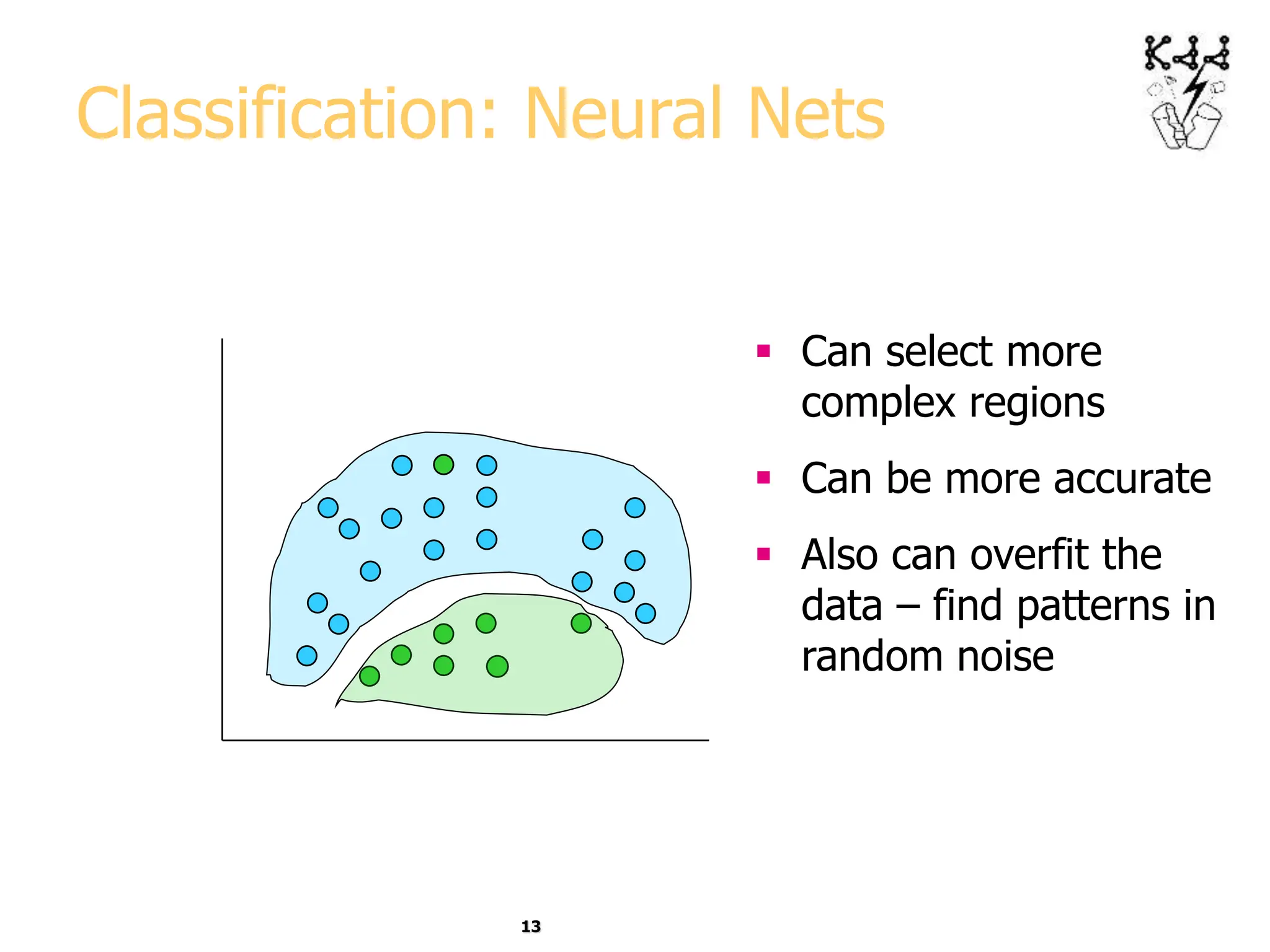
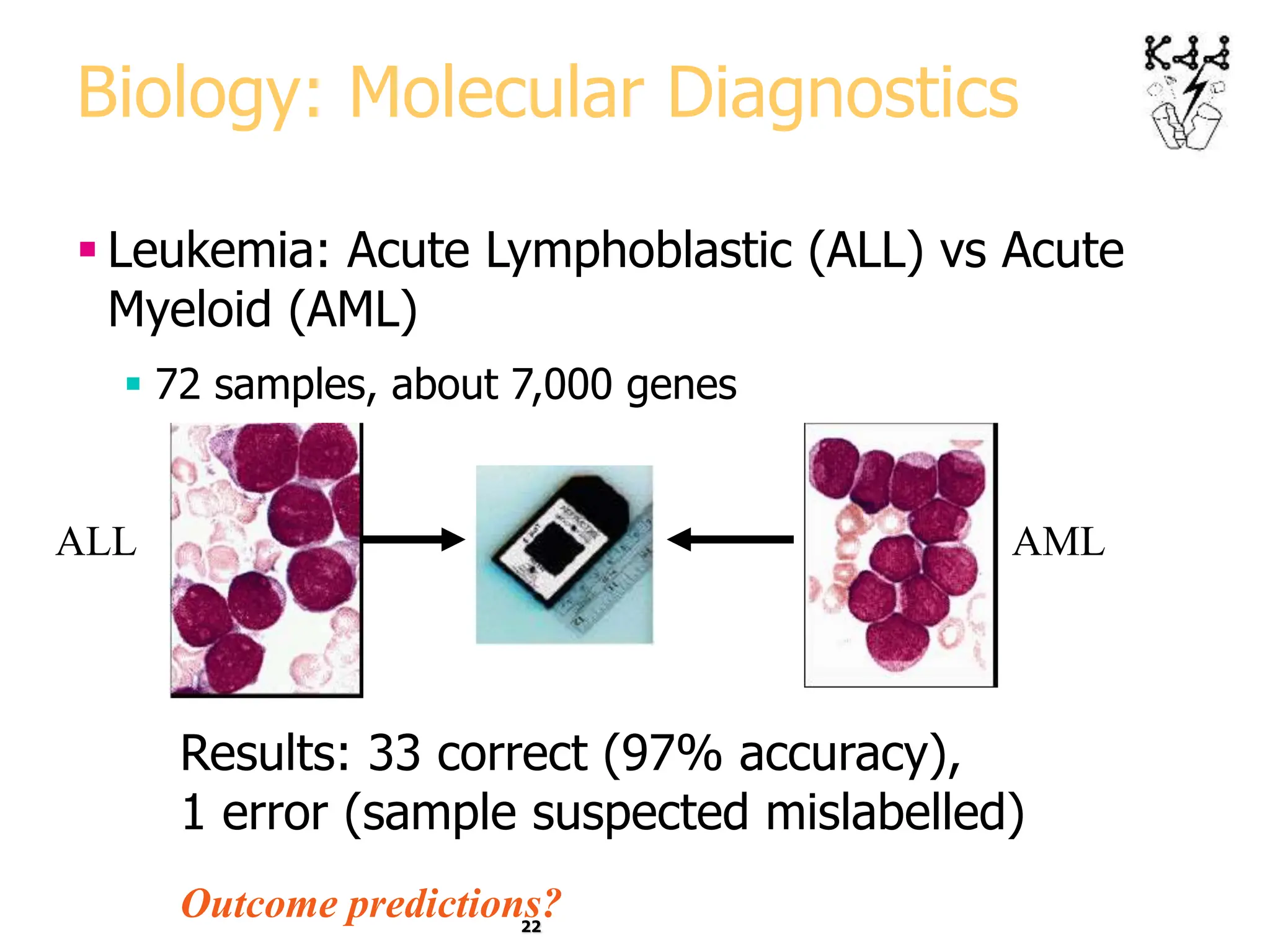
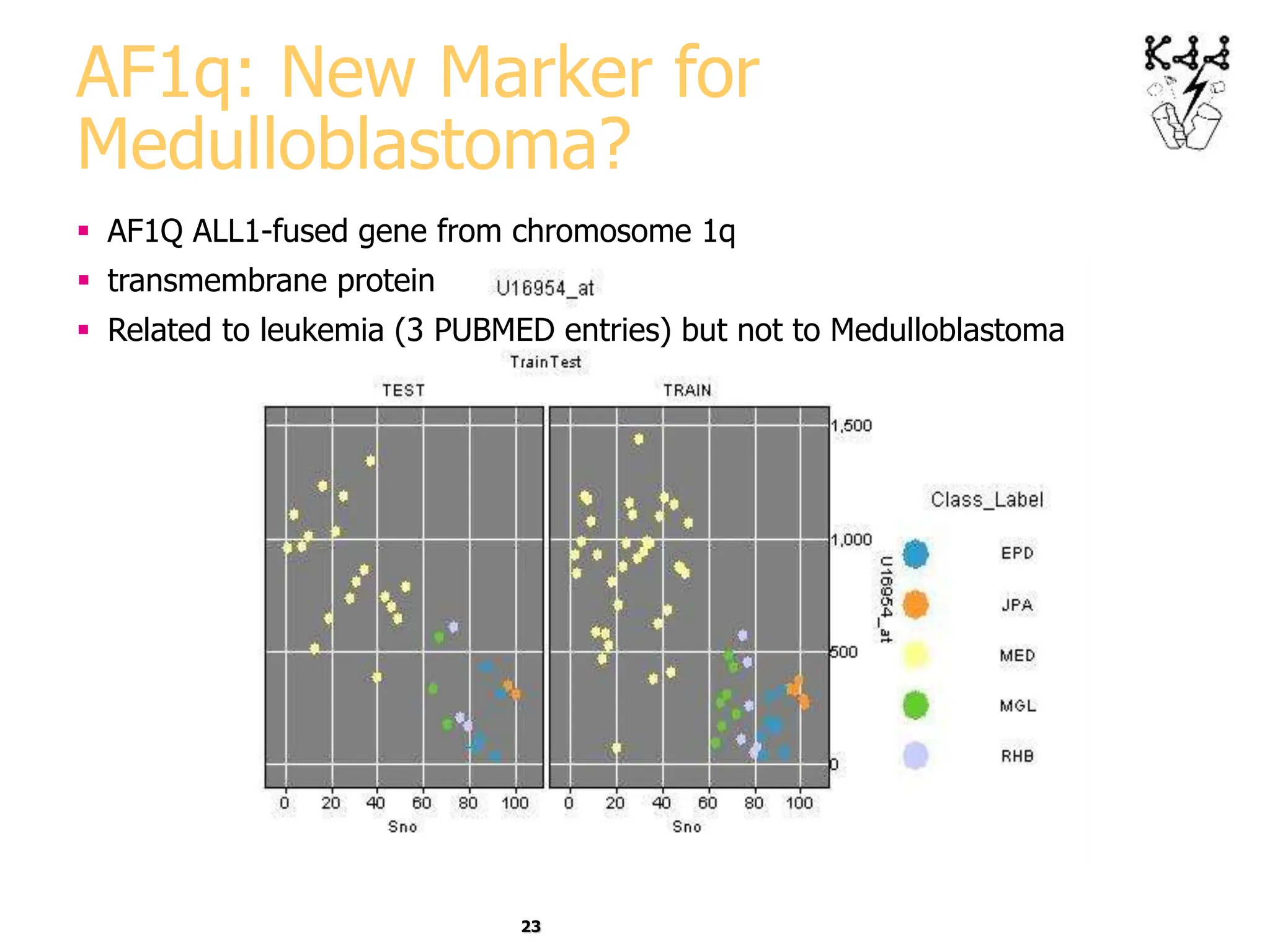
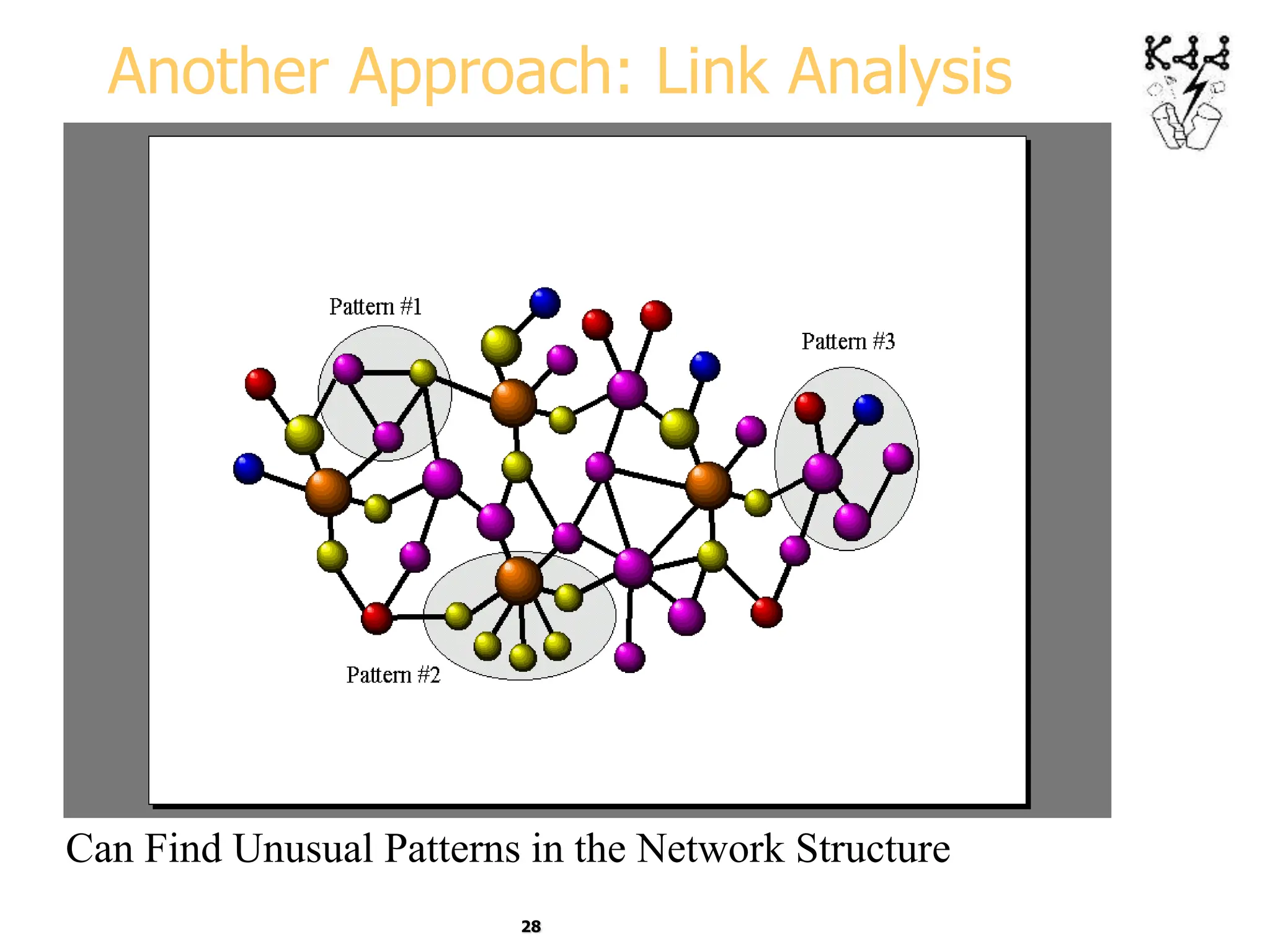
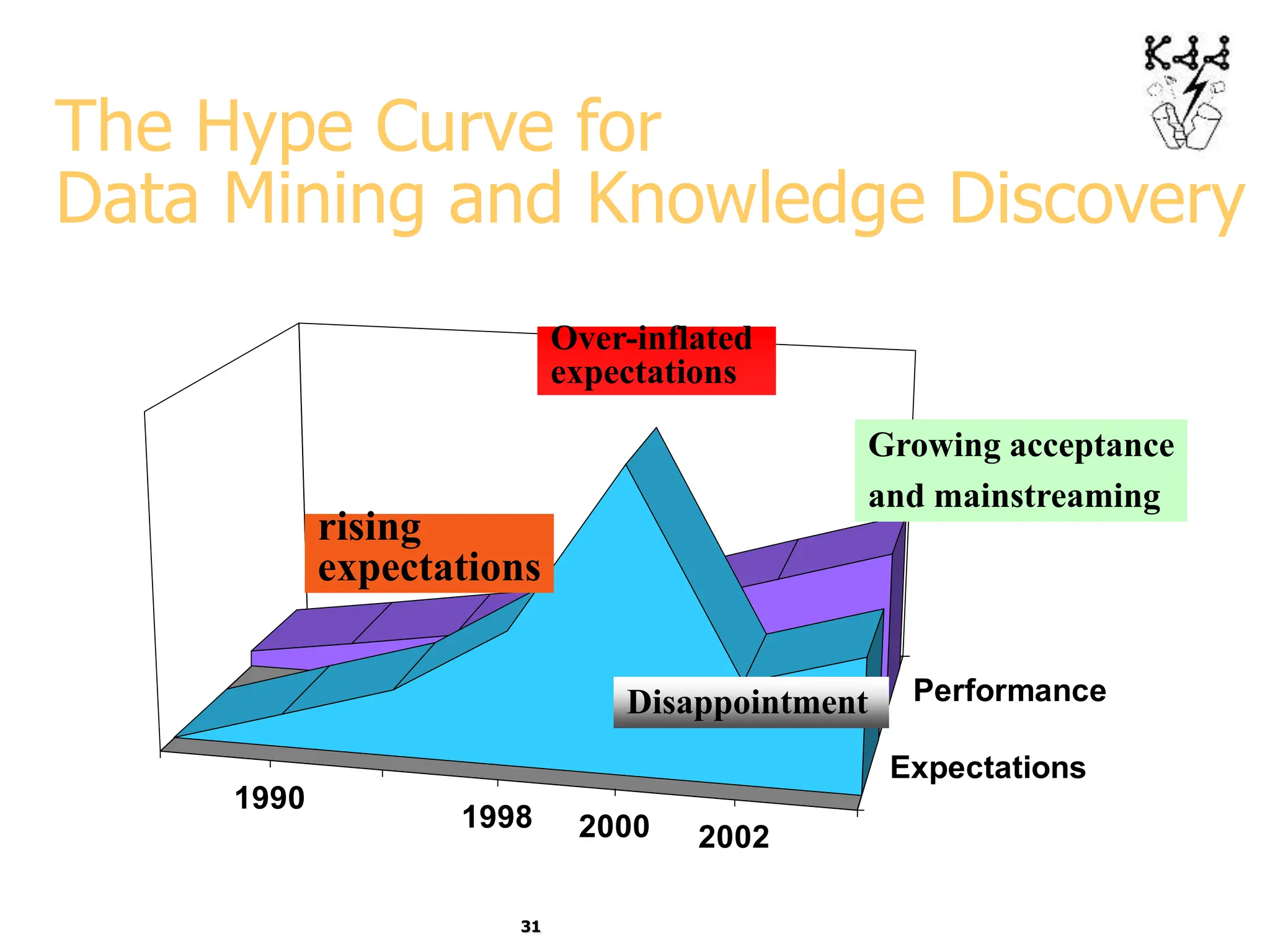
This document introduces data mining and knowledge discovery. It discusses how the growth of data from various sources has led to a data flood that makes it impossible for humans to analyze on their own. Data mining aims to discover useful patterns in large data sets through techniques like classification, clustering, and association rule mining. Major application areas are described such as customer relationship management, fraud detection, and bioinformatics. The document also covers controversies around using data mining for security and privacy concerns.