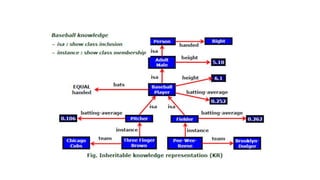
#6 The entities are related to each other in many different ways. The figure shows attributes (isa, instance, and team), each with a directed arrow, originating at the object being described and terminating either at the object or its value.
The specific details of the consistency check are not shown in the image, but it is likely that the check is being performed to ensure that the new value being added to the attribute is consistent with the existing values of other attributes.
For example, if the attribute being modified is "age" and the new value being added is "25", the consistency check might ensure that the value of the attribute "date of birth" is consistent with the new value of the "age" attribute.
In general, consistency checks are important for ensuring that data is accurate and reliable. They can help to prevent errors from being introduced into data sets and can also help to identify errors that have already been introduced
#7 . Represent two relationships in a single representation:
This could be done using a logical representation, such as a statement about two entities. For example, the statement "John is a member of the Red Sox team" could be used to represent the relationships between John, the Red Sox team, and the concept of membership.
This approach can be efficient, but it may not be flexible enough to represent all types of relationships.
2. Use attributes that focus on a single entity but use them in pairs:
This could be done by using attributes that are inverse of each other. For example, the attribute "member" could be used to represent the relationship between John and the Red Sox team, and the attribute "team" could be used to represent the inverse relationship between the Red Sox team and John.
This approach is more flexible than the first approach, but it can be more complex to implement.
The image also mentions that the second approach is followed in semantic net and frame-based systems, which use a knowledge acquisition tool to guarantee the consistency of inverse slots.
This means that when a value is added to one attribute, the corresponding value is automatically added to the inverse attribute.
This can help to ensure that the data is consistent, but it can also lead to errors if the inverse relationship is not correctly defined.