This document discusses an economic report for Iowa with a focus on Dubuque. Code is provided to import and organize labor data. Three main analyses are conducted: 1) An ANOVA test finds significant differences in median salaries between town types. 2) A chi-squared test finds no significant association between town type and occupation type. 3) A chi-squared test finds a highly significant association between occupation title and type.


![library(cowplot)
## Warning: package 'cowplot' was built under R version 3.2.5
##
## Attaching package: 'cowplot'
## The following object is masked from 'package:ggplot2':
##
## ggsave
library(scales)
## Warning: package 'scales' was built under R version 3.2.5
Labor <- read_excel("C:/Users/mp518563/Documents/FINALE.xlsx")
tbl_df(Labor)
## Source: local data frame [2,635 x 17]
##
## AREA_NAME OCC_CODE
## (chr) (chr)
## 1 Ames, IA 11-0000
## 2 Ames, IA 13-0000
## 3 Ames, IA 15-0000
## 4 Ames, IA 17-0000
## 5 Ames, IA 19-0000
## 6 Ames, IA 21-0000
## 7 Ames, IA 23-0000
## 8 Ames, IA 25-0000
## 9 Ames, IA 27-0000
## 10 Ames, IA 29-0000
## .. ... ...
## Variables not shown: OCC_TITLE (chr), GROUP (chr), A_PCT10 (dbl), A_PCT25
## (dbl), A_MEDIAN (dbl), A_PCT75 (dbl), A_PCT90 (dbl), YEAR (time),
## Occupation Type (chr), total area emp for year (dbl), share of area
## employment (dbl), town type (chr), new occ title (chr), Total employment
## by town type (dbl), share of total employment by town type (dbl)
Labor<-tbl_df(Labor)
#ASSIGNING NAME TO DATA SET IN NEW TABLE FUCNTION
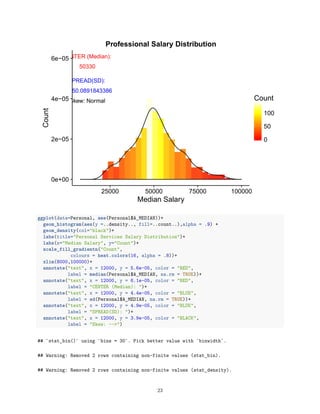
Labor %>% filter(`Occupation Type`=="Professional")
## Source: local data frame [1,078 x 17]
##
## AREA_NAME OCC_CODE
## (chr) (chr)
## 1 Ames, IA 11-0000
## 2 Ames, IA 13-0000
2](https://image.slidesharecdn.com/427707a0-5c02-4f64-bed5-1e016c40aa3e-160518070648/85/Iowa_Report_2-2-320.jpg)

![and medians of attendance for all of these divisions are equivalent to one another. When Looking at the
results:
aov(Labor$A_MEDIAN~as.factor(Labor$`town type`))
## Call:
## aov(formula = Labor$A_MEDIAN ~ as.factor(Labor$`town type`))
##
## Terms:
## as.factor(Labor$`town type`) Residuals
## Sum of Squares 15973478269 588171751750
## Deg. of Freedom 4 2615
##
## Residual standard error: 14997.41
## Estimated effects may be unbalanced
## 15 observations deleted due to missingness
anova <- aov(Labor$A_MEDIAN~as.factor(Labor$`town type`))
summary(anova)
## Df Sum Sq Mean Sq F value Pr(>F)
## as.factor(Labor$`town type`) 4 1.597e+10 3.993e+09 17.75 2.17e-14 ***
## Residuals 2615 5.882e+11 2.249e+08
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## 15 observations deleted due to missingness
Our p-value is less than 0.05. Hence we can conclude, for our confidence interval, the Alternative Hypothesis:
not all means are equal and that there is a relationship between town types and their median salaries. We
can also reject the null hypothesis that all of the means are the same and that there is no difference in annual
median salary between the town types.
This can be depicted numerically with the following code, displaying the media
mean(DBQ$A_MEDIAN, na.rm = TRUE)
## [1] 36155.21
mean(college$A_MEDIAN, na.rm = TRUE)
## [1] 40332.53
mean(metro$A_MEDIAN, na.rm = TRUE)
## [1] 40374
mean(rural$A_MEDIAN, na.rm = TRUE)
## [1] 34782.75
4](https://image.slidesharecdn.com/427707a0-5c02-4f64-bed5-1e016c40aa3e-160518070648/85/Iowa_Report_2-4-320.jpg)
![mean(small$A_MEDIAN, na.rm = TRUE)
## [1] 36794.75
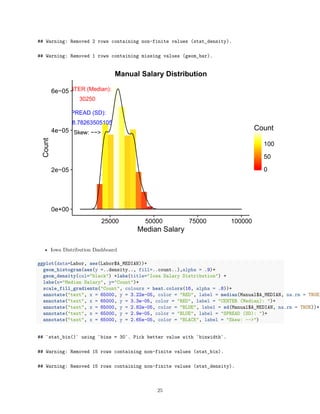
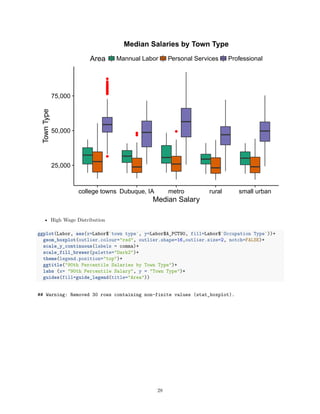
And Visually displayed with a box and whisker plot, showing the values as categorized by division:
ggplot(Labor, aes(x=Labor$`town type`, y=Labor$A_MEDIAN, fill=`town type`))+
geom_boxplot(outlier.colour="red", outlier.shape=16,outlier.size=2, notch=FALSE)+
coord_flip()+
scale_y_continuous(labels = comma)+
scale_fill_brewer(palette="Dark2")+
theme(legend.position="top")+
ggtitle("Attendance by LDiv")+
labs( x = "Median Salary", y = "Town Type")
## Warning: Removed 15 rows containing non-finite values (stat_boxplot).
college towns
Dubuque, IA
metro
rural
small urban
25,000 50,000 75,000
Town Type
MedianSalary
town type college towns Dubuque, IA metro rural small urban
Attendance by LDiv
*Note: College towns and metro areas seem to have higher annual median salaries as compared to the other
areas.
2) Chi-squared test between town type and occupation type
The Null hypothesis in the following chunk of code is that the two variables are independent and do not have
any statistically significant correlation.
5](https://image.slidesharecdn.com/427707a0-5c02-4f64-bed5-1e016c40aa3e-160518070648/85/Iowa_Report_2-5-320.jpg)


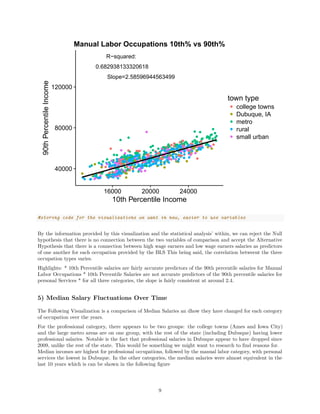
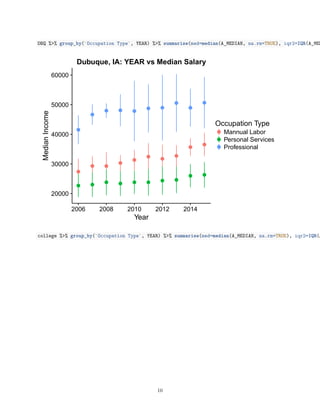
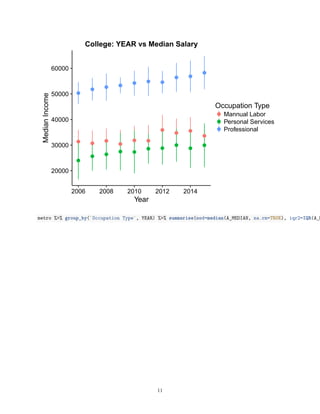
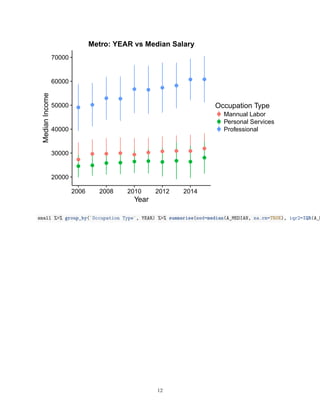
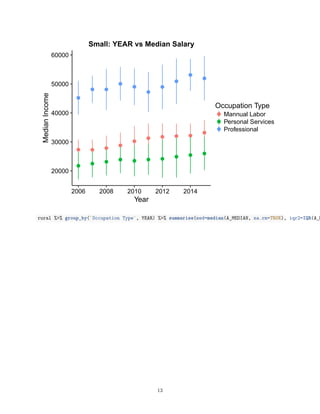
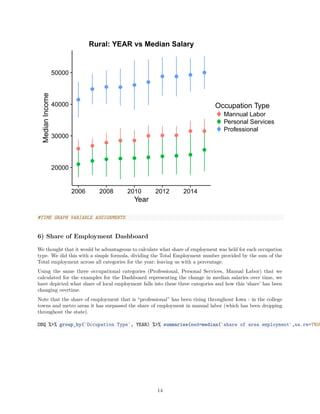
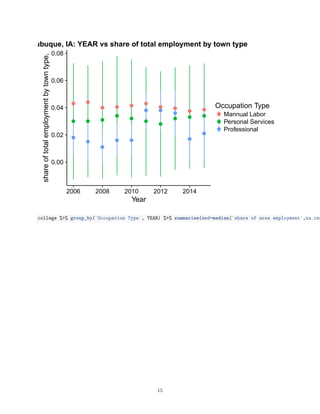
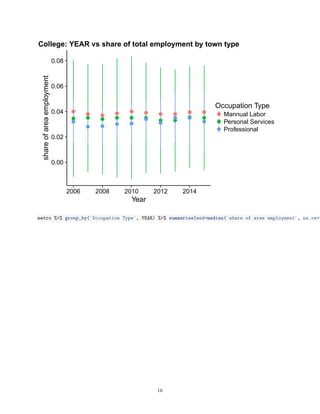
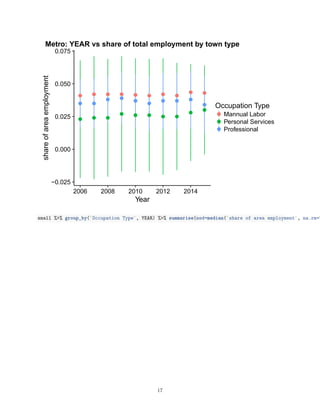
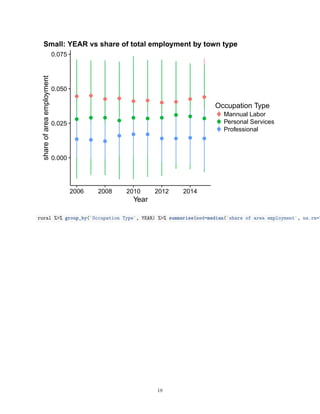
![0.00
0.02
0.04
0.06
0.08
2006 2008 2010 2012 2014
Year
shareofareaemployment
Occupation Type
Mannual Labor
Personal Services
Professional
Rural: YEAR vs share of total employment by town type
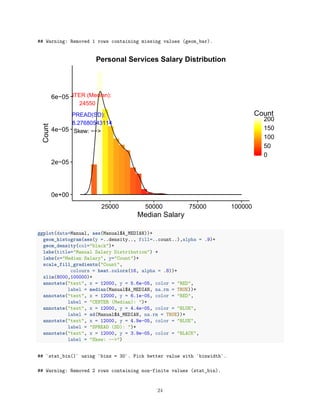
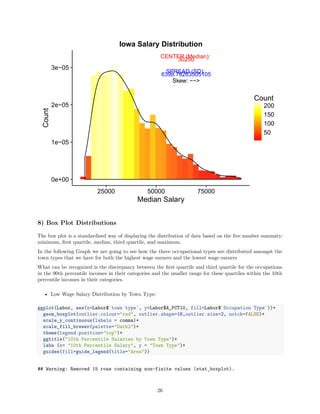
7) Histogram Distributions
A Histogram is diagram consisting of rectangles whose area is proportional to the frequency of a variable and
whose width is equal to the class interval.
• Center and Spread Statistics by town-
Dubuque:
sd(DBQ$A_MEDIAN, na.rm = TRUE)
## [1] 13975.85
median(DBQ$A_MEDIAN, na.rm = TRUE)
## [1] 32920
College Towns:
sd(college$A_MEDIAN, na.rm = TRUE)
## [1] 15748.84
19](https://image.slidesharecdn.com/427707a0-5c02-4f64-bed5-1e016c40aa3e-160518070648/85/Iowa_Report_2-19-320.jpg)
![median(college$A_MEDIAN, na.rm = TRUE)
## [1] 37985
Metro Areas:
sd(metro$A_MEDIAN, na.rm = TRUE)
## [1] 17485.75
median(metro$A_MEDIAN, na.rm = TRUE)
## [1] 36220
Rural Areas:
sd(rural$A_MEDIAN, na.rm = TRUE)
## [1] 12970.85
median(rural$A_MEDIAN, na.rm = TRUE)
## [1] 32400
Small Urban Areas:
sd(small$A_MEDIAN, na.rm = TRUE)
## [1] 14432.68
median(small$A_MEDIAN, na.rm = TRUE)
## [1] 34230
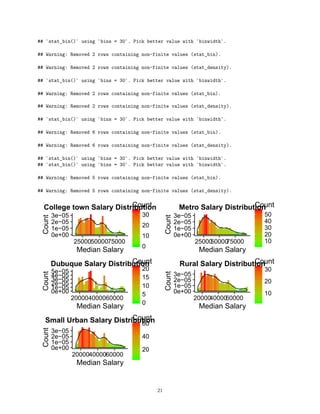
• College Towns have the highest annual median alary
• Rural towns have the lowest
• Dubuque is towards the lower end
• In regards to Salary remember, Dubuque also has less data points due to the lack of aggregation in this
category
The visualization bellow depicts the statistics above (Town Type Distribution Dashboard):
DBQhist <- ggplot(data=DBQ, aes(DBQ$A_MEDIAN))+geom_histogram(aes(y =..density.., fill=..count..),alpha
Collegehist <- ggplot(data=college, aes(college$A_MEDIAN))+geom_histogram(aes(y =..density.., fill=..cou
Metrohist <- ggplot(data=metro, aes(metro$A_MEDIAN))+geom_histogram(aes(y =..density.., fill=..count..),
Smallhist <- ggplot(data=small, aes(small$A_MEDIAN))+geom_histogram(aes(y =..density.., fill=..count..),
Ruralhist <- ggplot(data=rural, aes(rural$A_MEDIAN))+geom_histogram(aes(y =..density.., fill=..count..),
grid.arrange (Collegehist, Metrohist, DBQhist, Smallhist, Ruralhist, ncol=2)
20](https://image.slidesharecdn.com/427707a0-5c02-4f64-bed5-1e016c40aa3e-160518070648/85/Iowa_Report_2-20-320.jpg)