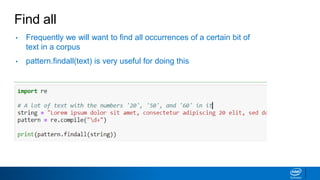
This document provides an introduction to natural language processing (NLP). It defines NLP as teaching computers to process human language. The two main components of NLP are natural language understanding (NLU), which is deriving meaning from language, and natural language generation (NLG), which is generating language from meaning representations. The document discusses the history of NLP from early rule-based systems to current deep learning approaches. It also outlines several applications of NLU like classification and summarization, and of NLG like machine translation and caption generation. Finally, it introduces regular expressions as a tool for text processing in NLP.





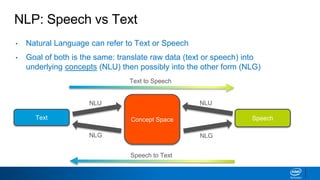























![More Metacharacters
• { m,n} specify number of times character is matched between m
and n times
• [ ] list characters to be matched
• escape character
• | or
• ( ) capture group inside parenthesis](https://image.slidesharecdn.com/introtonlp-1902180955231-221102100455-5207f994/85/introtonlp-190218095523-1-pdf-32-320.jpg)
![Metacharacters: Examples
• { m,n} specify number of times character is matched between m
and n times
• [ ] list characters to be matched](https://image.slidesharecdn.com/introtonlp-1902180955231-221102100455-5207f994/85/introtonlp-190218095523-1-pdf-33-320.jpg)

![Character Classes
• s - matches any whitespace
• w - matches any alpha character. Equivalent to [A-Za-z]
• d - matches any numeric character. Equivalent to [0-9]
You may negate these by capitalizing. For example, D matches
anything not a digit](https://image.slidesharecdn.com/introtonlp-1902180955231-221102100455-5207f994/85/introtonlp-190218095523-1-pdf-35-320.jpg)



![Lookaheads/Lookbehinds
• Allow you to keep the cursor in place, but still check to see if
certain conditions are met before or after that character
• Look ahead: (?=d) checks to see if the character is followed by a
number
• Look Behind: (?<=[aeiou]) checks to see if the character is
preceded by a vowel
examples](https://image.slidesharecdn.com/introtonlp-1902180955231-221102100455-5207f994/85/introtonlp-190218095523-1-pdf-39-320.jpg)