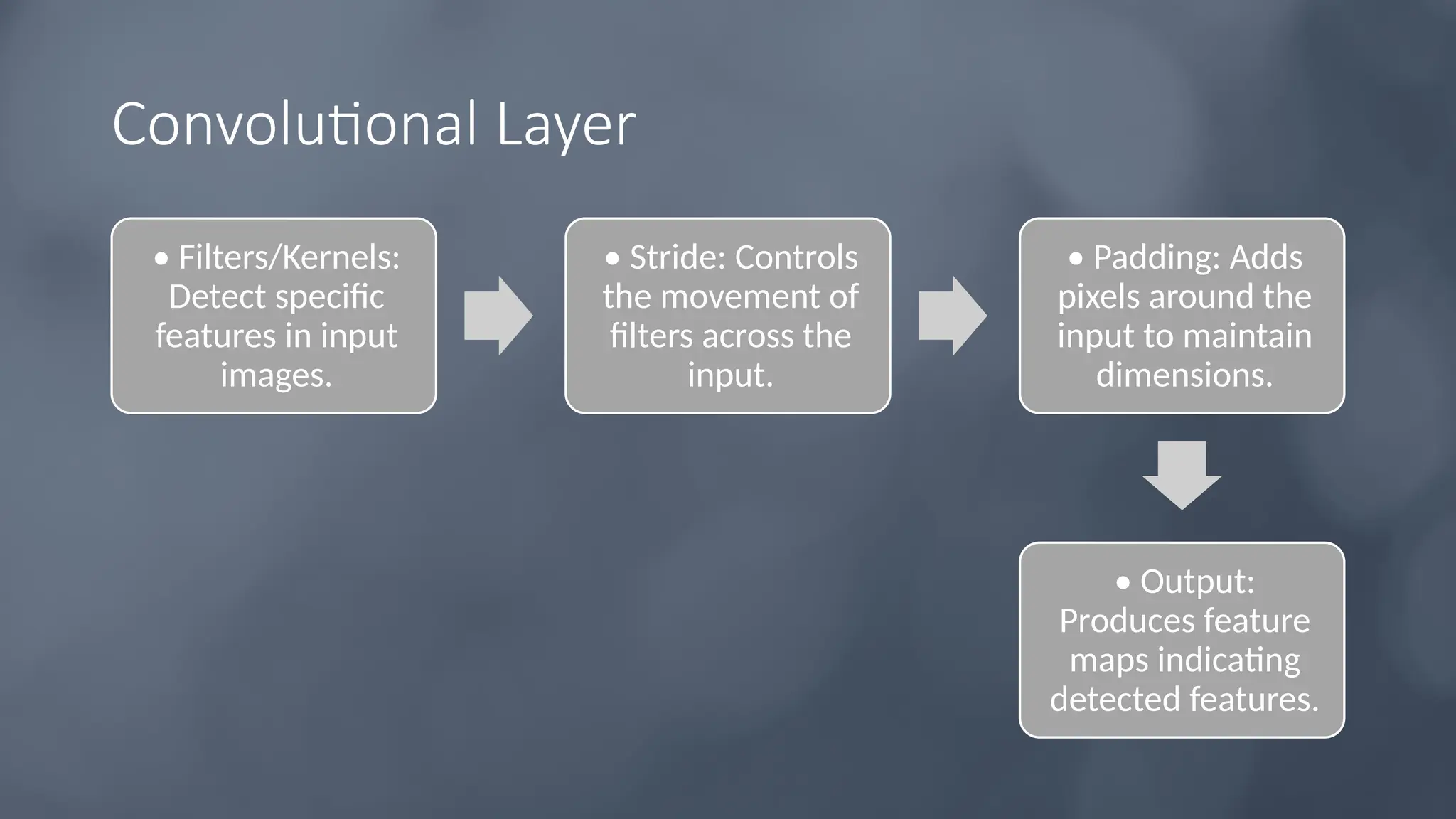
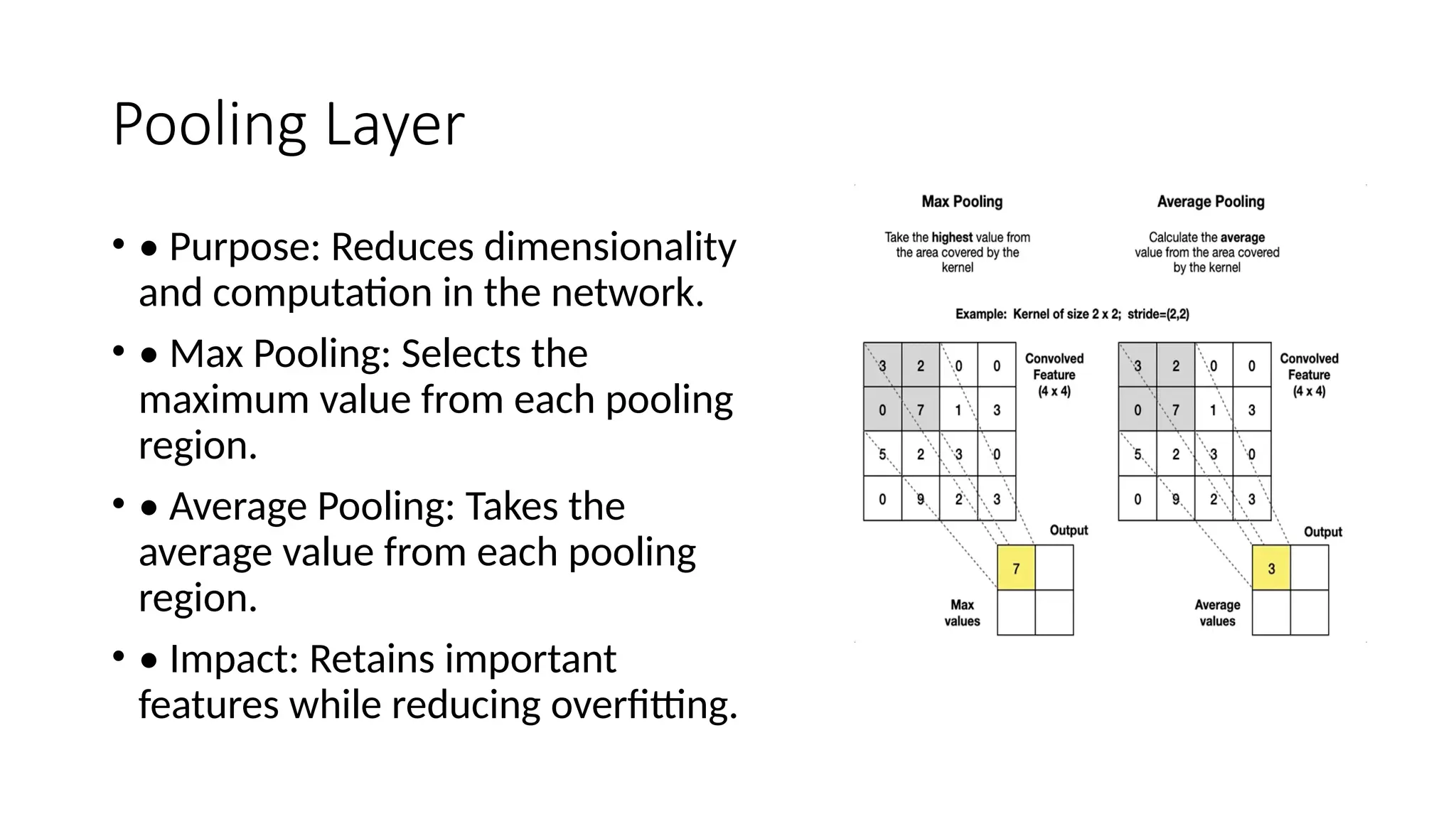
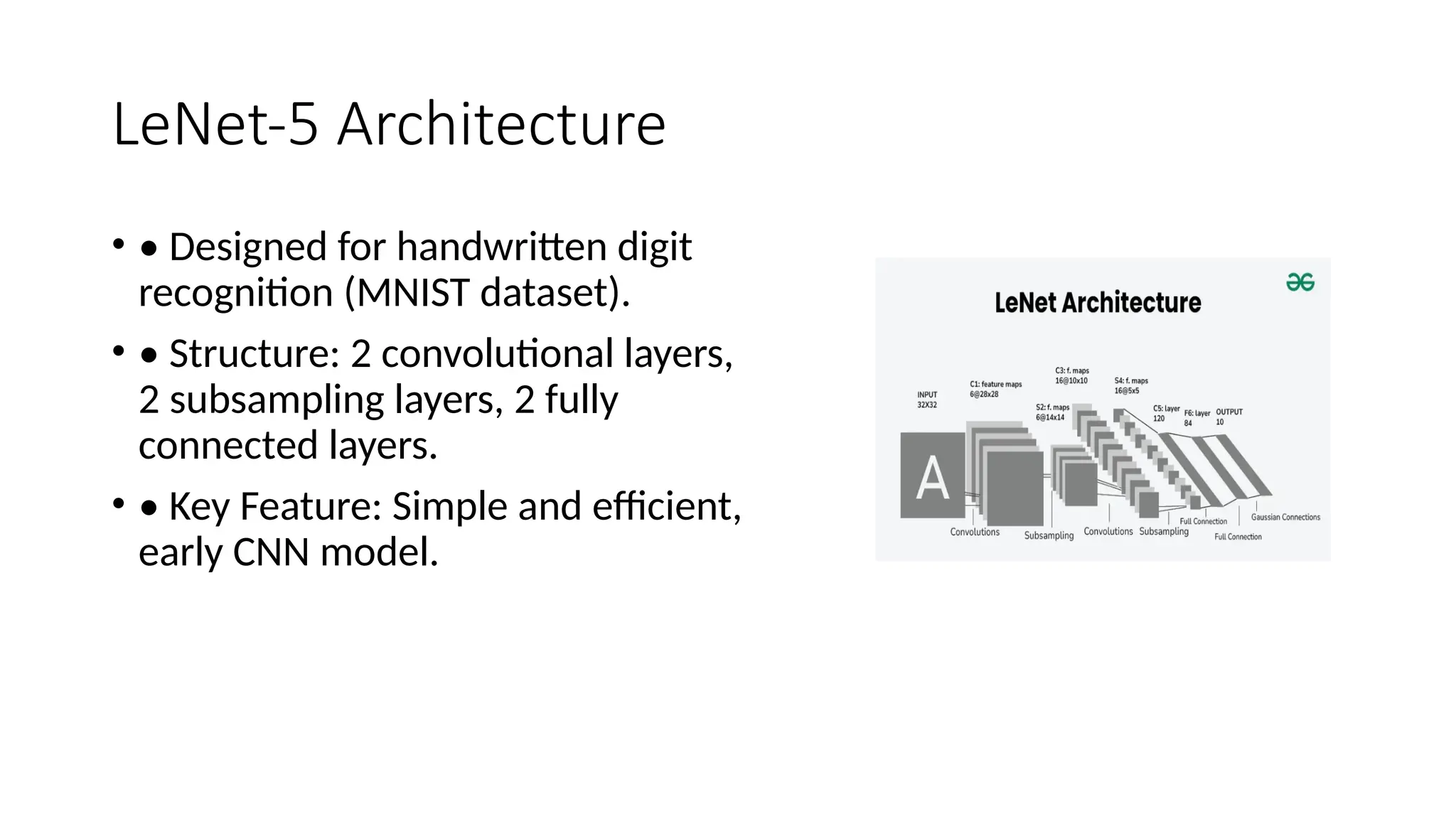
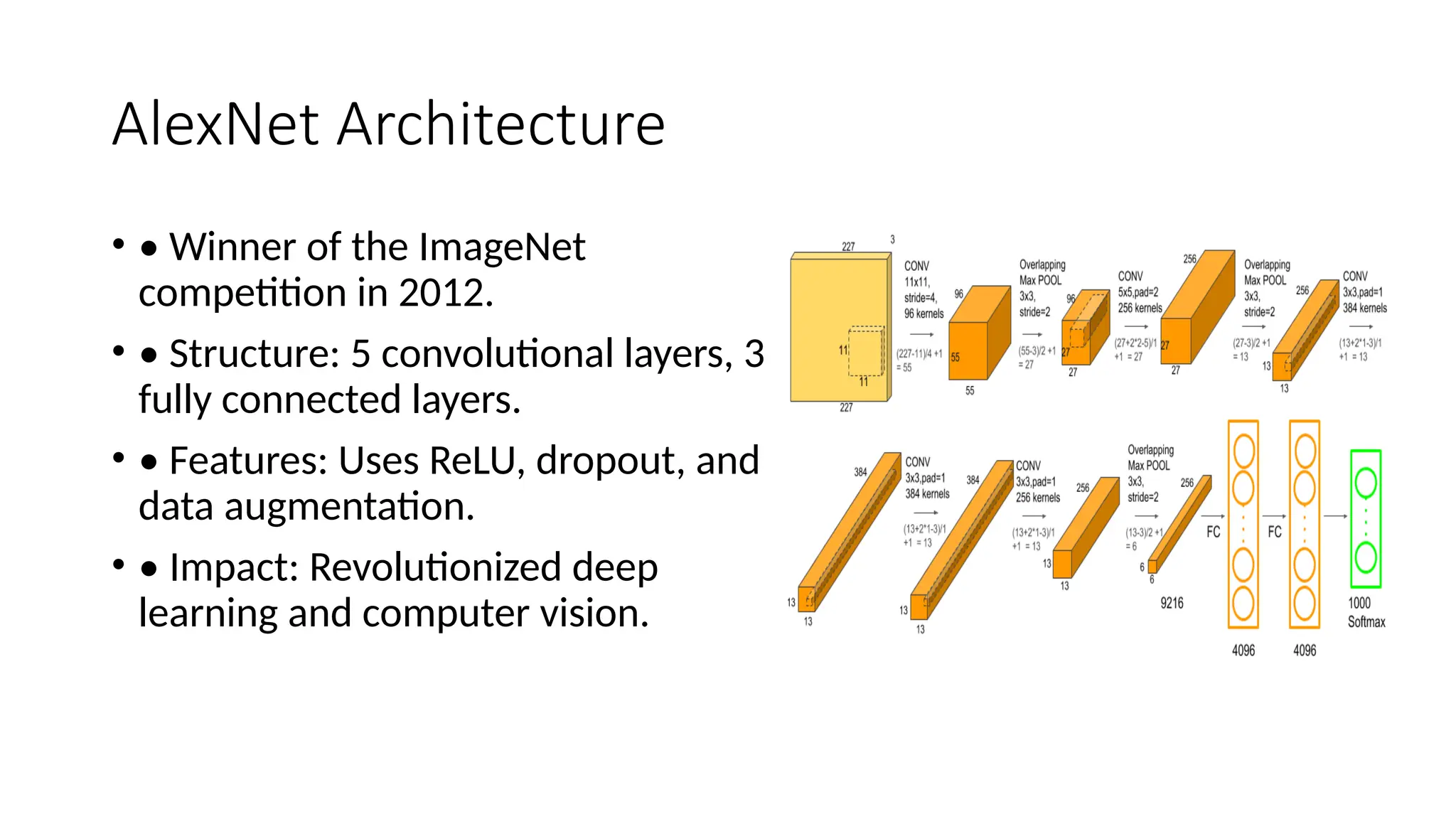
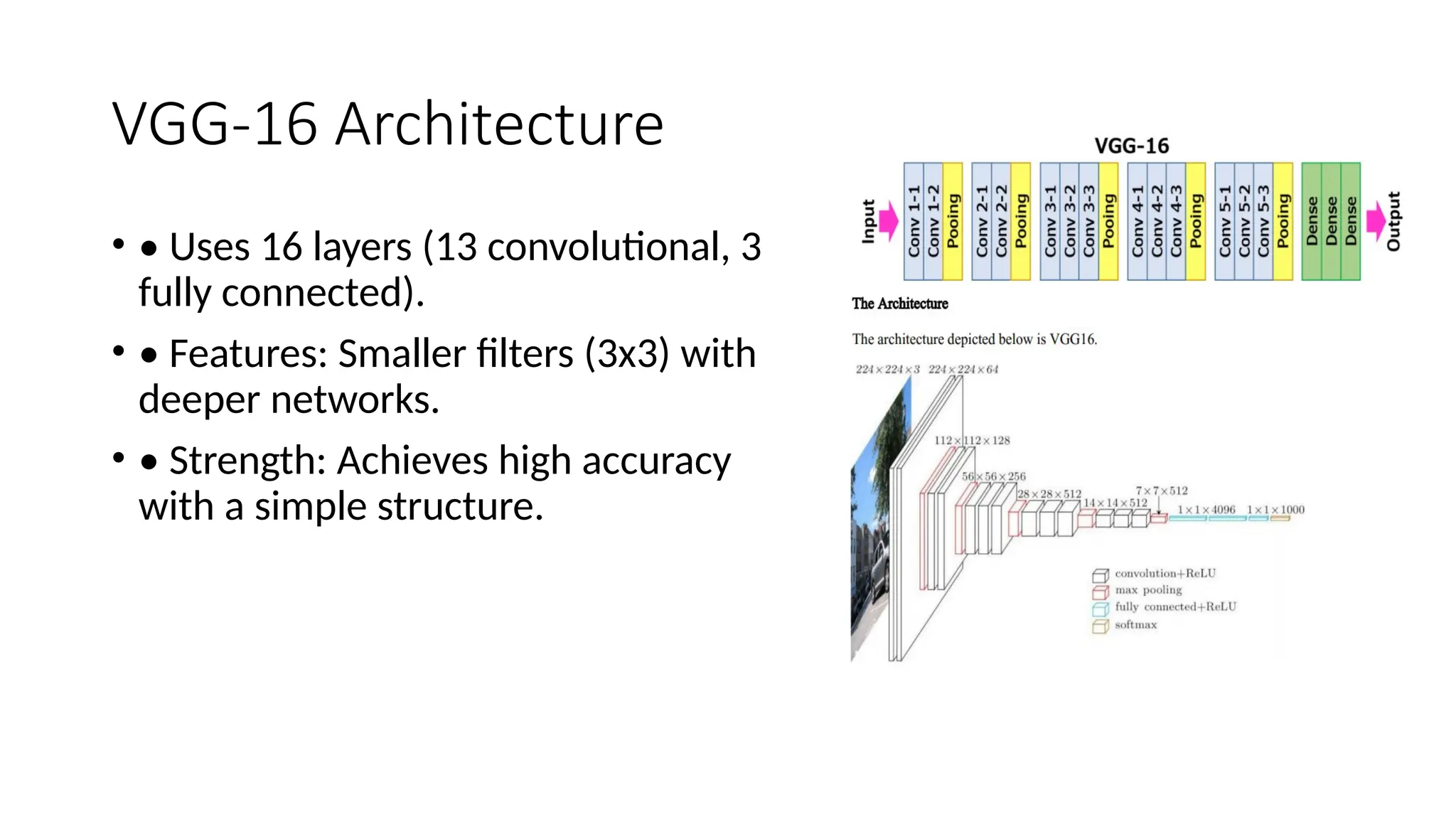
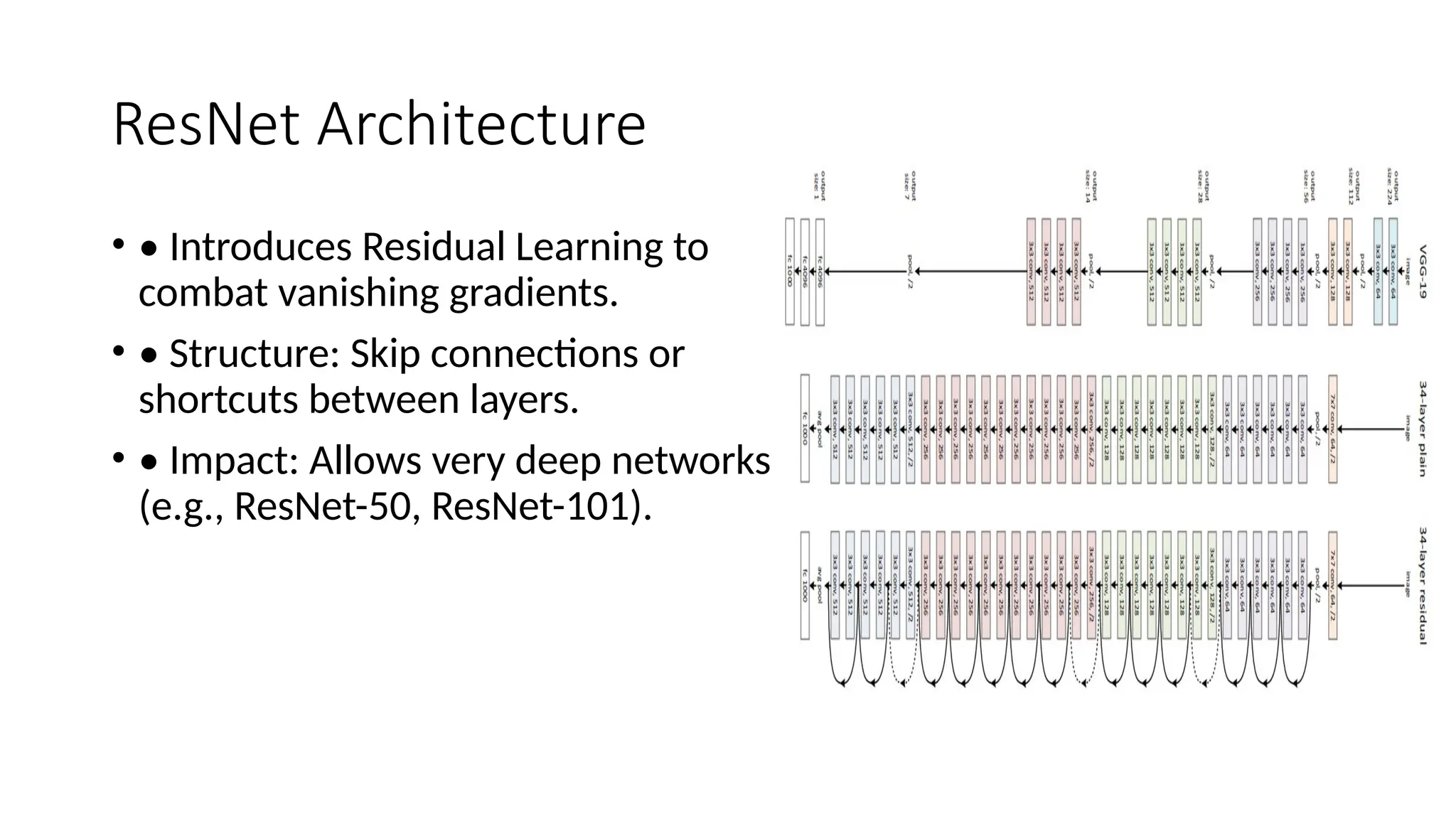
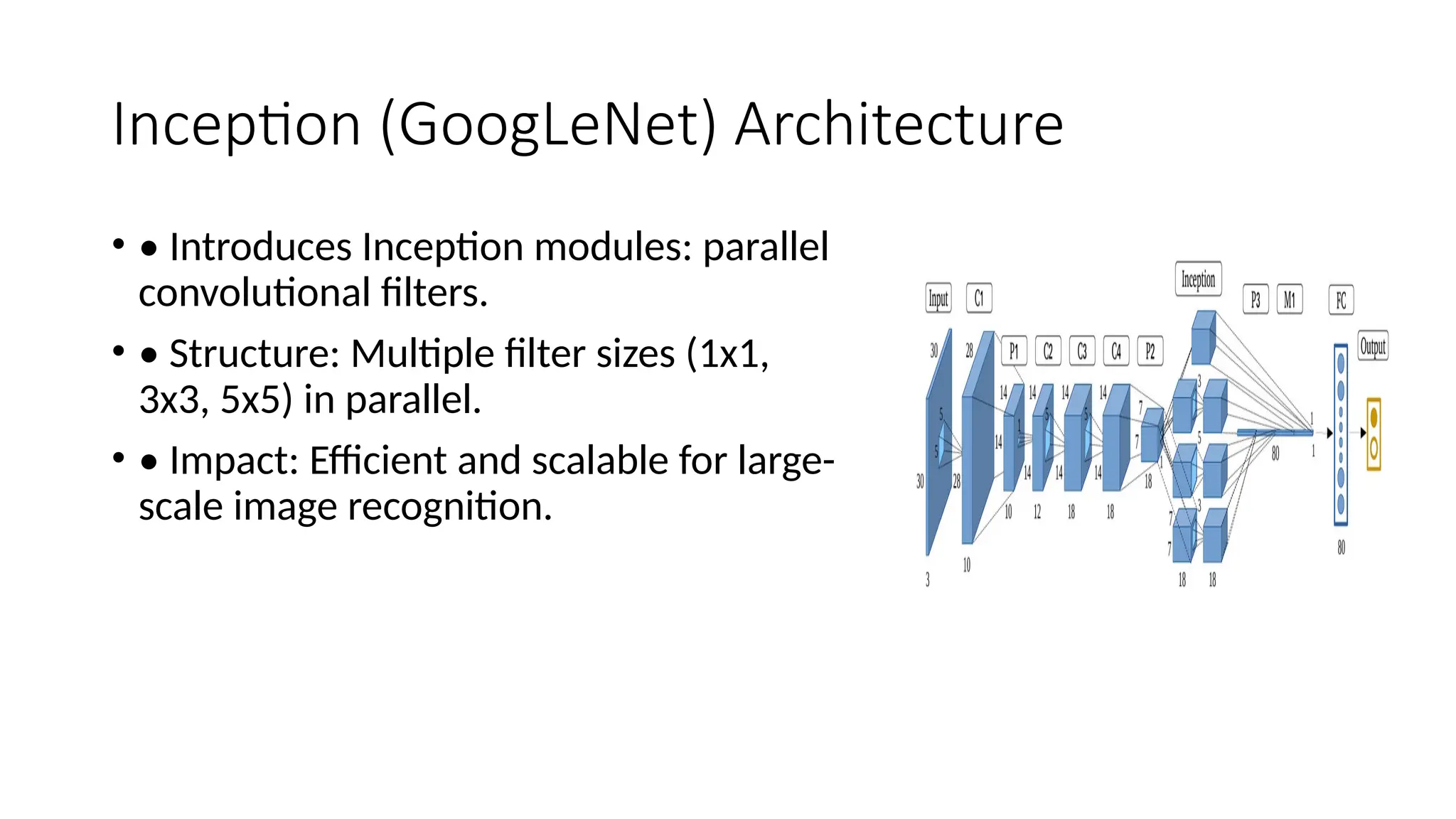
The document provides an overview of convolutional neural networks (CNNs), detailing their basic structure and functions, including layers such as input, convolutional, ReLU, pooling, and fully connected layers. It highlights significant CNN architectures like LeNet-5, AlexNet, VGG-16, ResNet, and Inception, as well as concepts like transfer learning, object localization, and landmark detection, showcasing their impact on computer vision. Overall, it emphasizes how CNNs have transformed image processing and related fields.