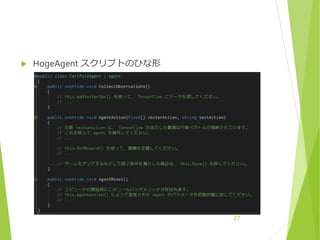
Space Type とSpace Size
Space Type
Discrete か Continuous
Space Size
Space Type = Discrete の場合
1次元ベクトル
範囲は [0, …, Space Size – 1]
離散量(攻撃 or 防御 など)に使用
Space Type = Continuous の場合
Space Size 次元ベクトル
範囲は決まってない?
連続量(座標や角度)に使用
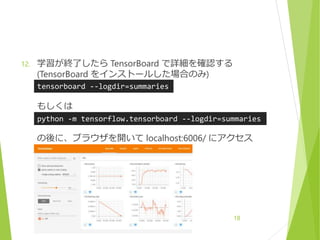
30
31.
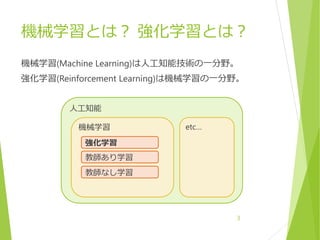
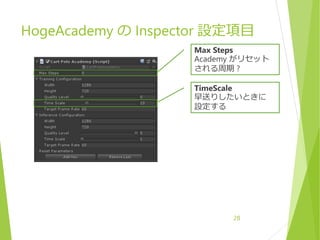
Brain Type
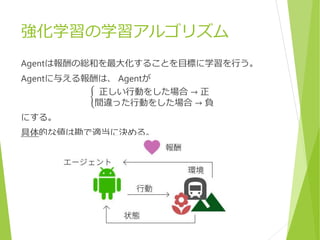
Agent の動かし方を表す
Player
プレイヤーが を直接動かす
デバッグ用
Heuristic
HogeDecision スクリプトの記述通りに動かす
デバッグ用
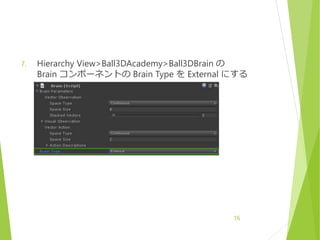
External
AI の学習をするビルド時はこれにする
Internal
学習済みの AI を使うリリースビルド時はこれにする
Graph Model に学習済み AI パラメータファイルを
指定すること
31























![Space Type と Space Size
Space Type
Discrete か Continuous
Space Size
Space Type = Discrete の場合
1次元ベクトル
範囲は [0, …, Space Size – 1]
離散量(攻撃 or 防御 など)に使用
Space Type = Continuous の場合
Space Size 次元ベクトル
範囲は決まってない?
連続量(座標や角度)に使用
30](https://image.slidesharecdn.com/introductionofunityml-agents-180531113111/85/Introduction-of-Unity-ML-Agents-30-320.jpg)








![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Learning to Act by Predicting the Future](https://cdn.slidesharecdn.com/ss_thumbnails/20171113dl-171114045641-thumbnail.jpg?width=640&height=640&fit=bounds)

![運用中のゲームにAIを導入するには〜プロジェクト推進・ユースケース・運用〜 [DeNA TechCon 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/techcon2019okumuraokada-190214063249-thumbnail.jpg?width=640&height=640&fit=bounds)


















