Download as PDF, PPTX





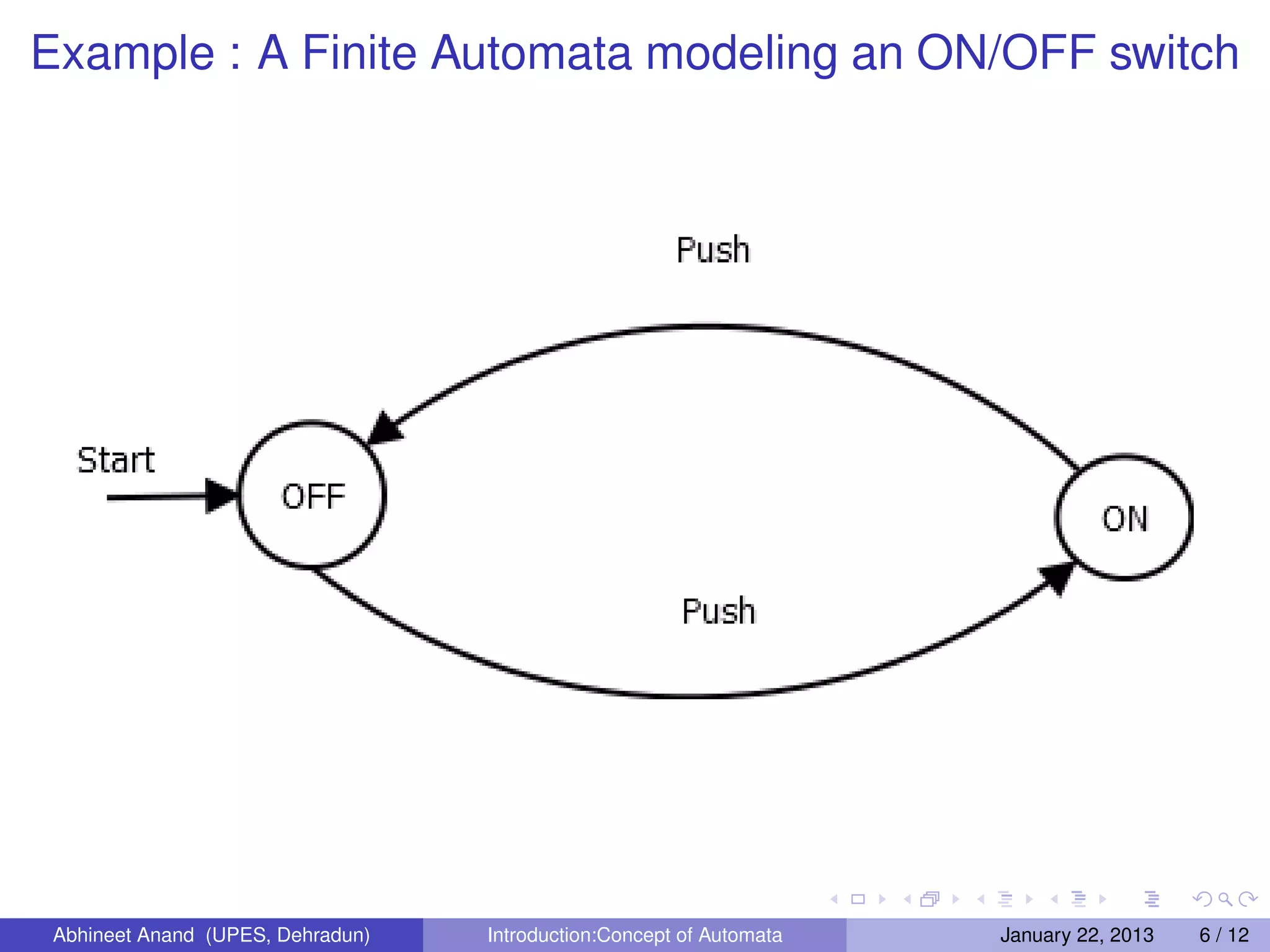







This document introduces the concept of automata. It discusses that automata theory studies abstract computing devices and was originally proposed to model brain function but proved useful for other purposes like designing digital circuits. Automata can model systems that have a finite number of states. There are two important notations used in automata theory - grammars and regular expressions. Automata are essential for studying the limits of computation in terms of what problems are decidable and what problems are intractable. The central concepts of automata theory include alphabets, strings, concatenation of strings, reverse of strings, and Kleene closure.







































