Download as PDF, PPTX






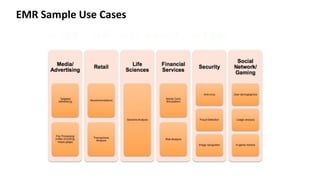







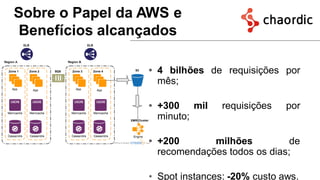


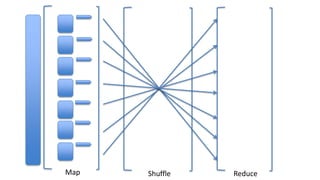

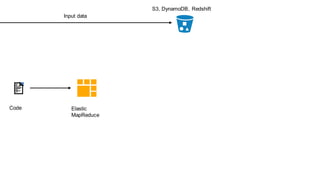
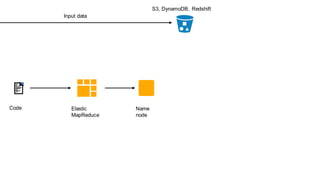
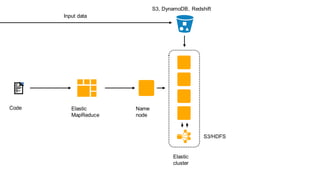
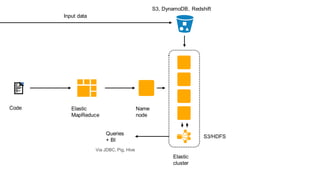
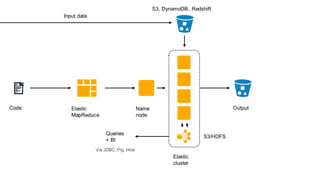
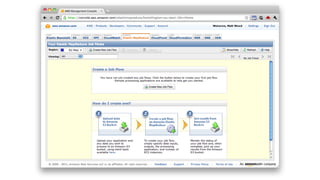
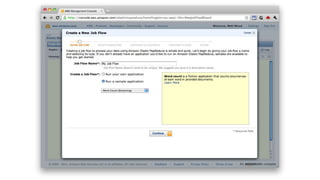
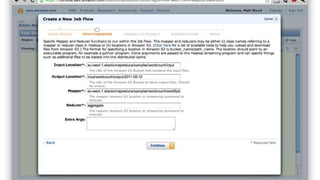
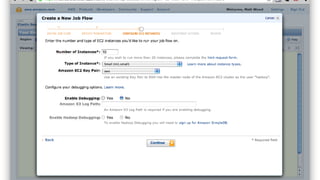
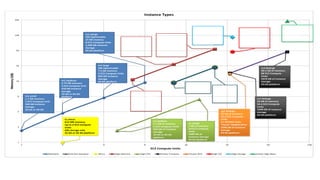
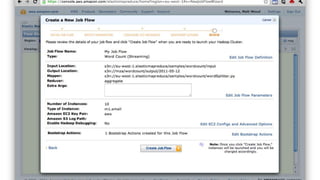
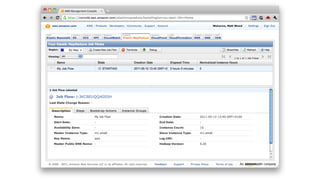
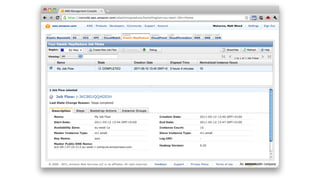
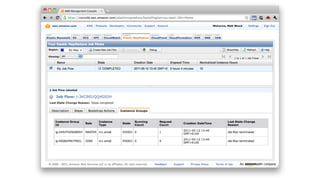
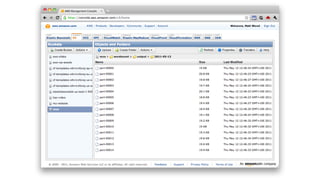















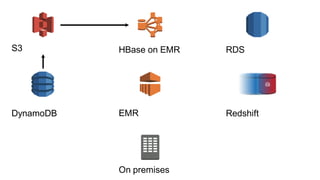
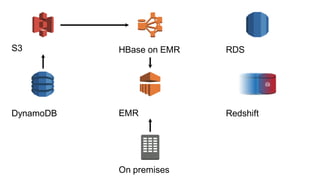
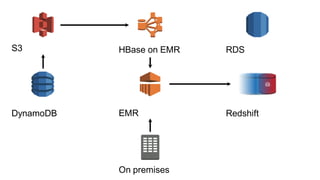


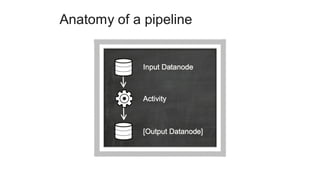
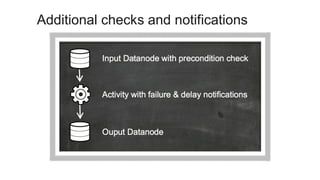
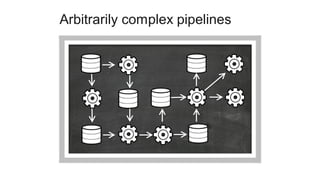




1. The document introduces Amazon Elastic MapReduce (EMR), a managed cluster computing service that supports open-source frameworks like Hadoop, Hive, Pig, and Spark. 2. EMR allows customers to easily process vast amounts of data by eliminating the undifferentiated heavy lifting of cluster provisioning, configuration, and management. 3. The document provides examples of how customers use EMR for big data use cases like processing web server logs, personalized recommendations, and real-time analytics.
































































































