Downloaded 20 times



![Diversity Maximization Speedup
Interactive Fault Localization
Leveraging Simple User Feedback
for Fault Localization
Debugging
Software errors cost the US economy
59.5 billion dollars (0.6% of 2002's GDP) [1]
Testing and debugging activities are
labor-intensive (30% to 90% of a Project) [2]
Problem
Presented by
Liang Gong
School of Software
Tsinghua University
[1] National Institute of Standards and Technology (NIST). Software Errors Cost
U.S. Economy $59.5 Billion Annually, June 28, 2002.
[2] B. Beizer. Software Testing Techniques. International Thomson Computer
Press, Boston, 2nd edition, 1990.](https://image.slidesharecdn.com/icsmpresentationv1-140227191641-phpapp01/85/Interactive-fault-localization-leveraging-simple-user-feedback-by-Liang-Gong-3-320.jpg)










![Diversity Maximization Speedup
Interactive Fault Localization
for Fault Localization
Leveraging Simple User Feedback
Fault Localization (state-of-the-arts)
Related Works
Introduction
WHITHER[Renieris and Reiss]
Liblit05[Liblit]
Delta Debugging[Zeller]
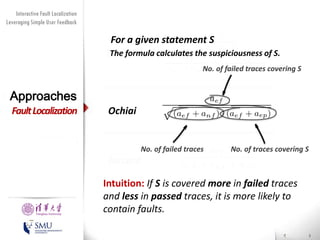
Tarantula[Harrold], Ochiai etc.
Interactive Fault Localization
Hao et al. propose an technique [JCST]
Record sequential execution trace
Judge whether the fault is executed before or after
the checking point.
Presented by
Liang Gong
School of Software
Tsinghua University
Lucia et al. adopt user feedback for clone-based bug
detection approaches [ICSE 12]
Insa et al. propose a strategy for algorithmic
debugging which asks user questions concerning
program state. [ASE 11]](https://image.slidesharecdn.com/icsmpresentationv1-140227191641-phpapp01/85/Interactive-fault-localization-leveraging-simple-user-feedback-by-Liang-Gong-23-320.jpg)



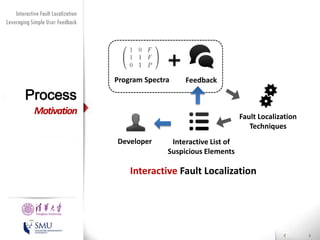
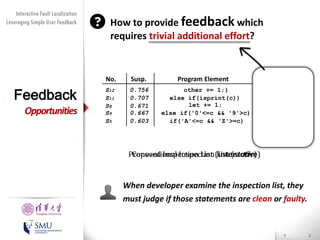
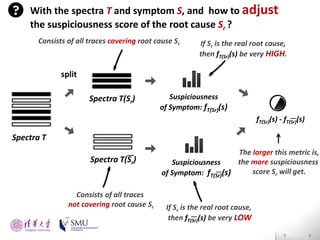
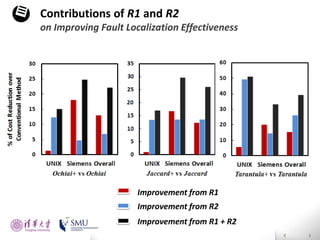
The document presents an interactive fault localization technique called TALK that leverages simple user feedback to improve upon existing static spectrum-based fault localization approaches. TALK iteratively updates its fault localization model based on user feedback on whether examined program elements are buggy or clean. An evaluation on 12 C programs found that TALK significantly improved fault localization accuracy over conventional techniques. The two main rules of TALK are identifying likely root causes of reported false positives and prioritizing elements covered in execution profiles with fewest covered elements.










![[Tho Quan] Fault Localization - Where is the root cause of a bug?](https://cdn.slidesharecdn.com/ss_thumbnails/thoquanfaultlocalization-whereistherootcause-140717230902-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












































































