Downloaded 15 times








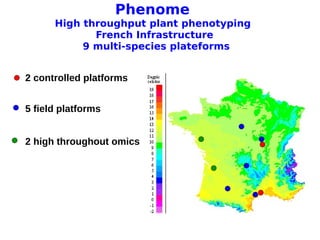

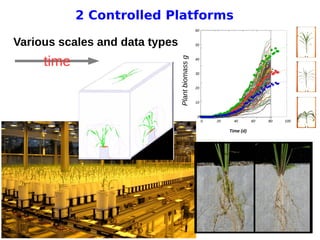






The document discusses INRA's role as a French agricultural research institute focusing on big data challenges in agronomic sciences, particularly in high throughput phenotyping. It highlights issues such as data volume, variety, velocity, and validity, and the importance of integrating diverse data types for effective agricultural research and decision-making. The conclusion emphasizes the complexities of producing, managing, and analyzing high throughput phenotyping data.



































































