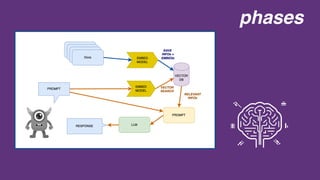
This document discusses building a conversational agent for a restaurant using a language model with no framework. It describes prompting an AI model with contextual information about the restaurant to improve responses. Integrating a vector database to store company information allows retrieving relevant facts to include in responses. The document outlines phases like storing embeddings, searching the database, and embedding results in prompts. Areas for improvement include chunking large inputs, checking for prompt injection, and using feedback or an assistant framework.
![Marco De Nittis
marco.denittis [a] gmail.com
LLM-ize your apps 101](https://image.slidesharecdn.com/aiheroes-2023-llm101-slideshare-231204171741-a5526d6e/85/Integrate-LLM-in-your-applications-101-1-320.jpg)

























![thank you!
Marco De Nittis
marco.denittis [a] gmail.com
https://speakerscore.it/AIHEROES-101
https://github.com/mdnmdn/aiheroes-2023](https://image.slidesharecdn.com/aiheroes-2023-llm101-slideshare-231204171741-a5526d6e/85/Integrate-LLM-in-your-applications-101-28-320.jpg)



































































