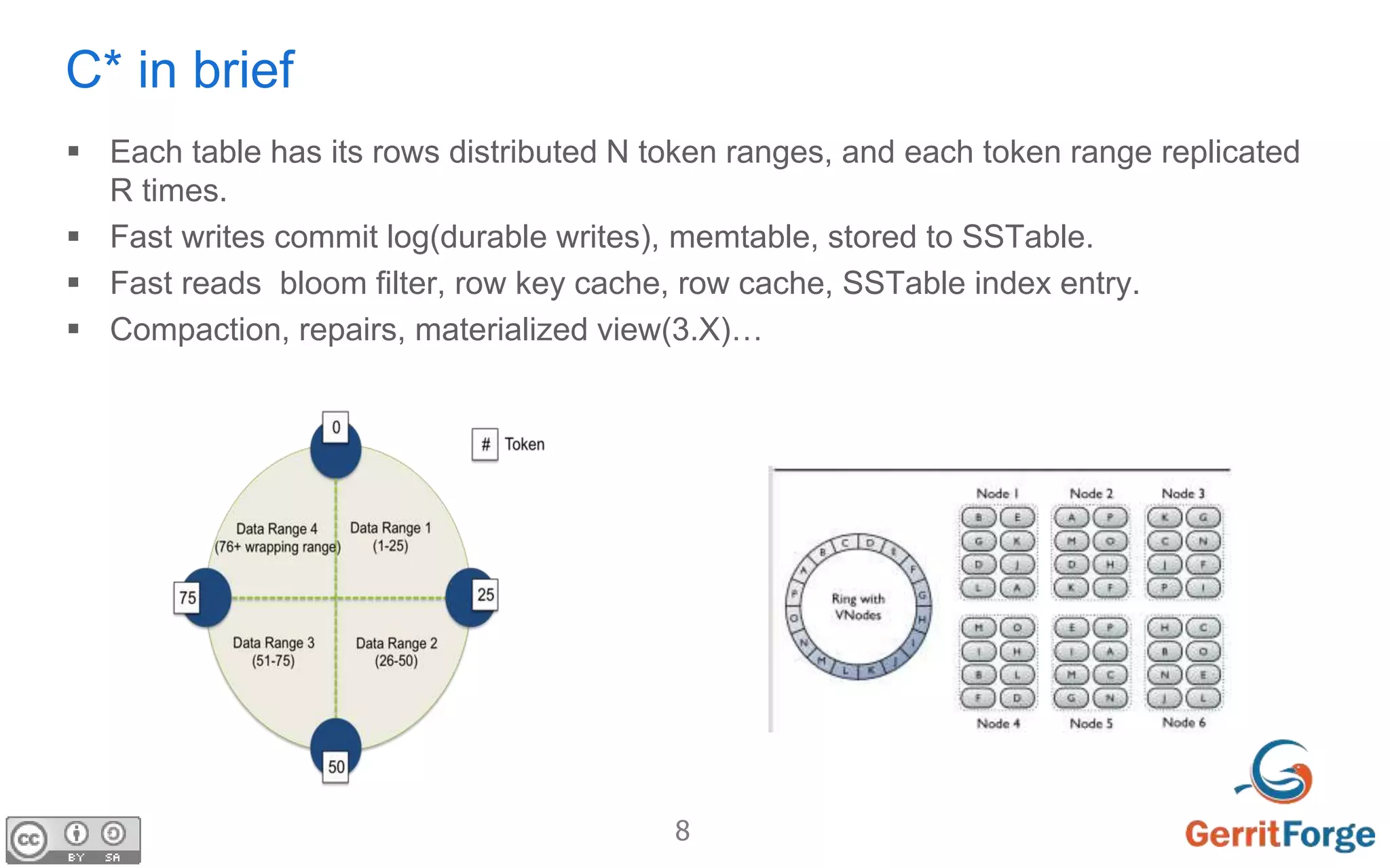
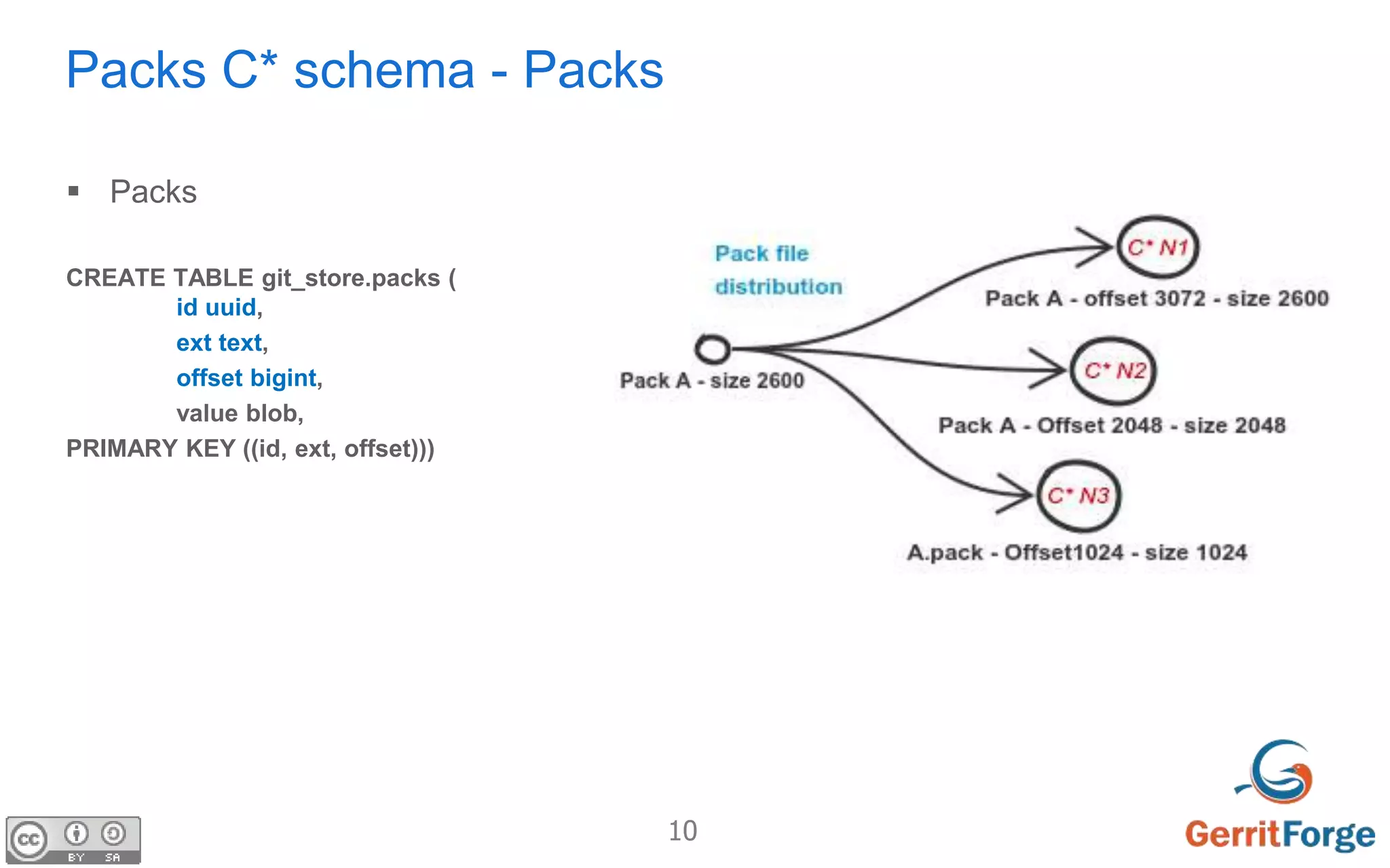
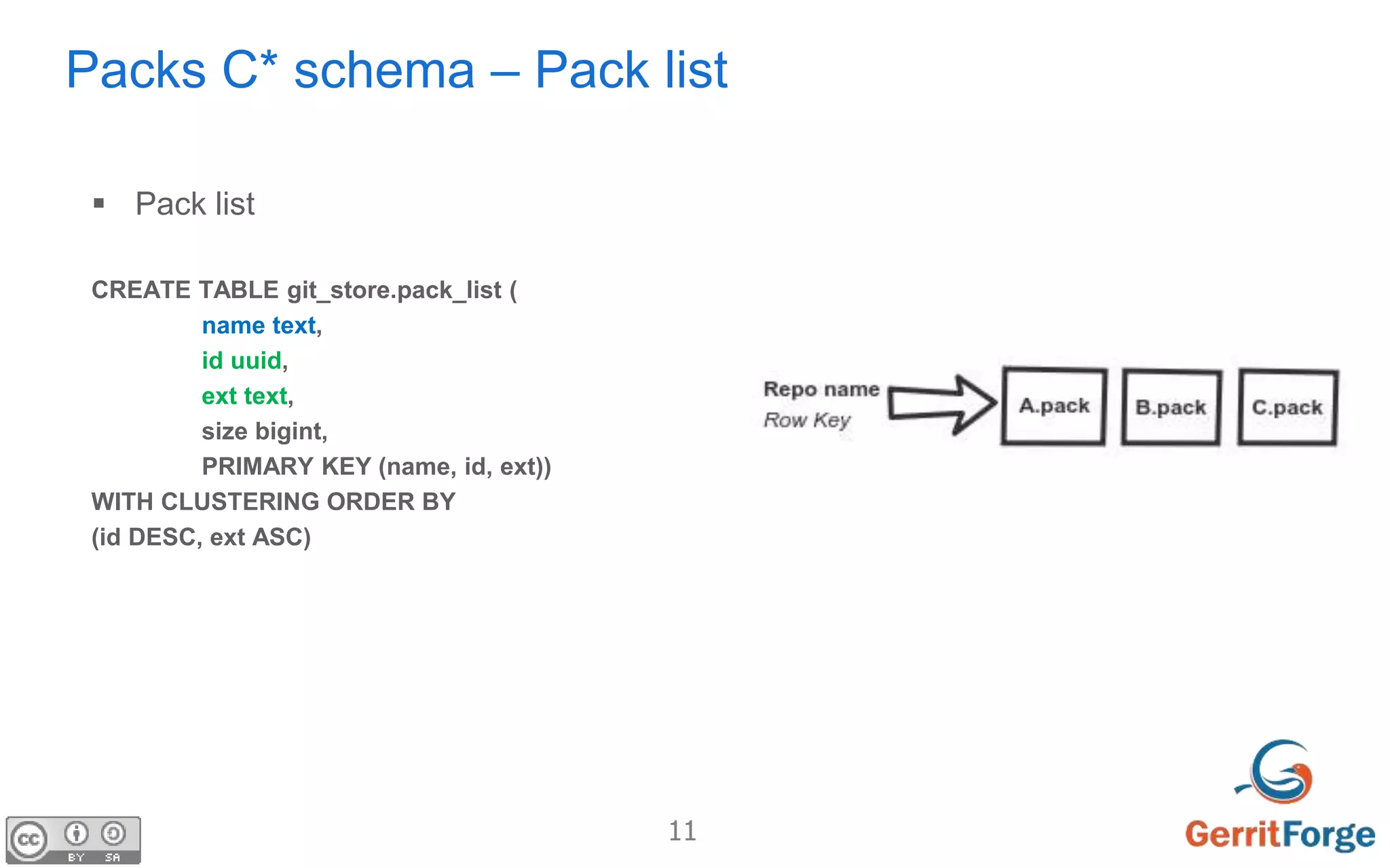
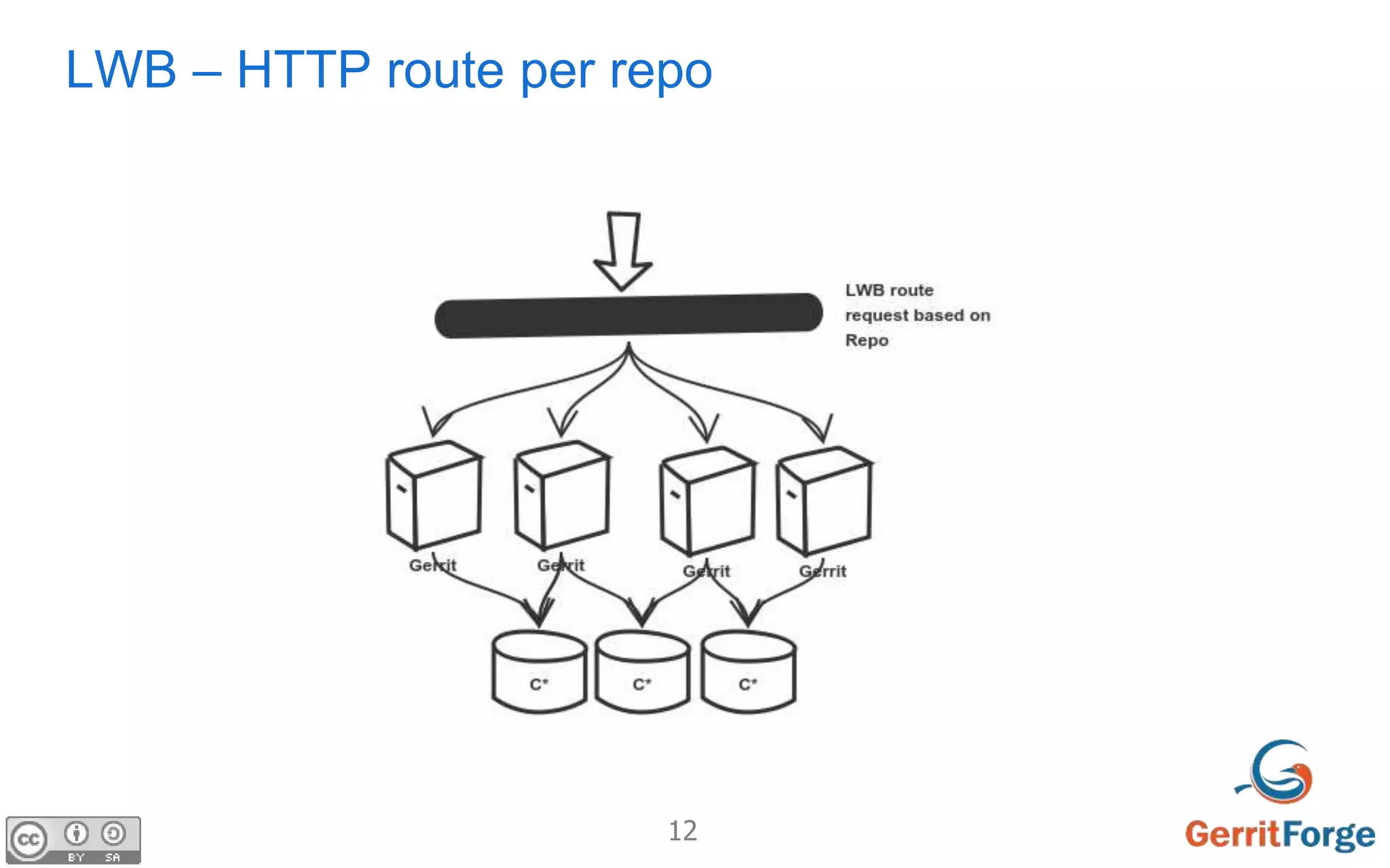
The document discusses using Apache Cassandra as the distributed database for Gerrit to address challenges of distributed storage, replication, concurrent updates and cache consistency. It proposes using Cassandra to store Git pack and pack list data with specific schema. The goal is to allow all Gerrit masters to accept writes, increase throughput and flexibility while ensuring zero downtime and data loss through auto-scaling. Challenges of distributed agreement and shared sessions are also discussed.






















![[Public] gerrit concepts and workflows](https://cdn.slidesharecdn.com/ss_thumbnails/publicgerrit-conceptsandworkflows-200829034112-thumbnail.jpg?width=640&height=640&fit=bounds)
![Giacomo Tirabassi [InfluxData] | Istio at InfluxData | InfluxDays Virtual Exp...](https://cdn.slidesharecdn.com/ss_thumbnails/istio-at-influxdata-giacomo-tirabassi-200623171845-thumbnail.jpg?width=640&height=640&fit=bounds)




























![Governance, Deployment & Methodologies for Agentic Automation [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day2-251112135038-a386476d-thumbnail.jpg?width=640&height=640&fit=bounds)














