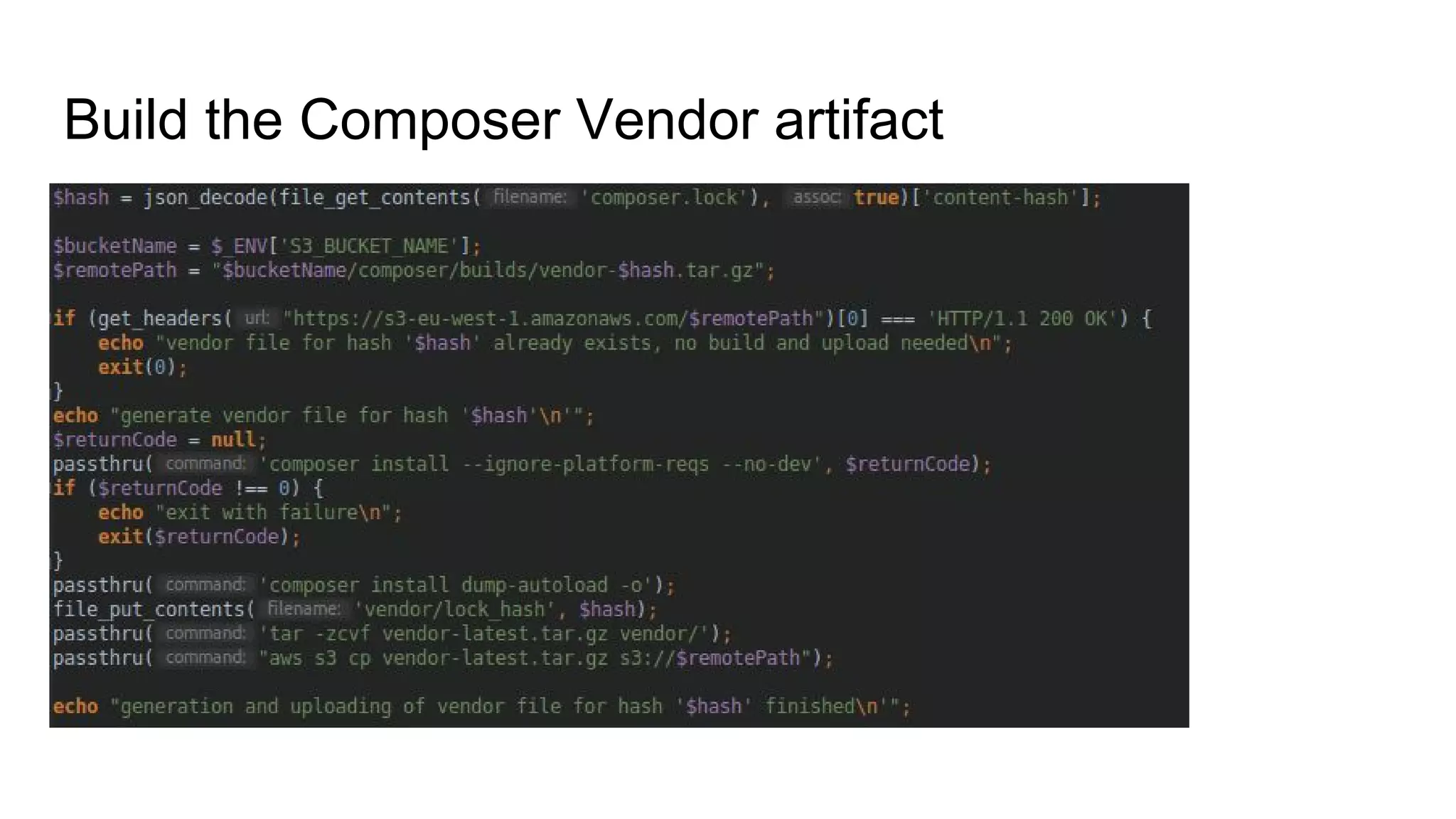
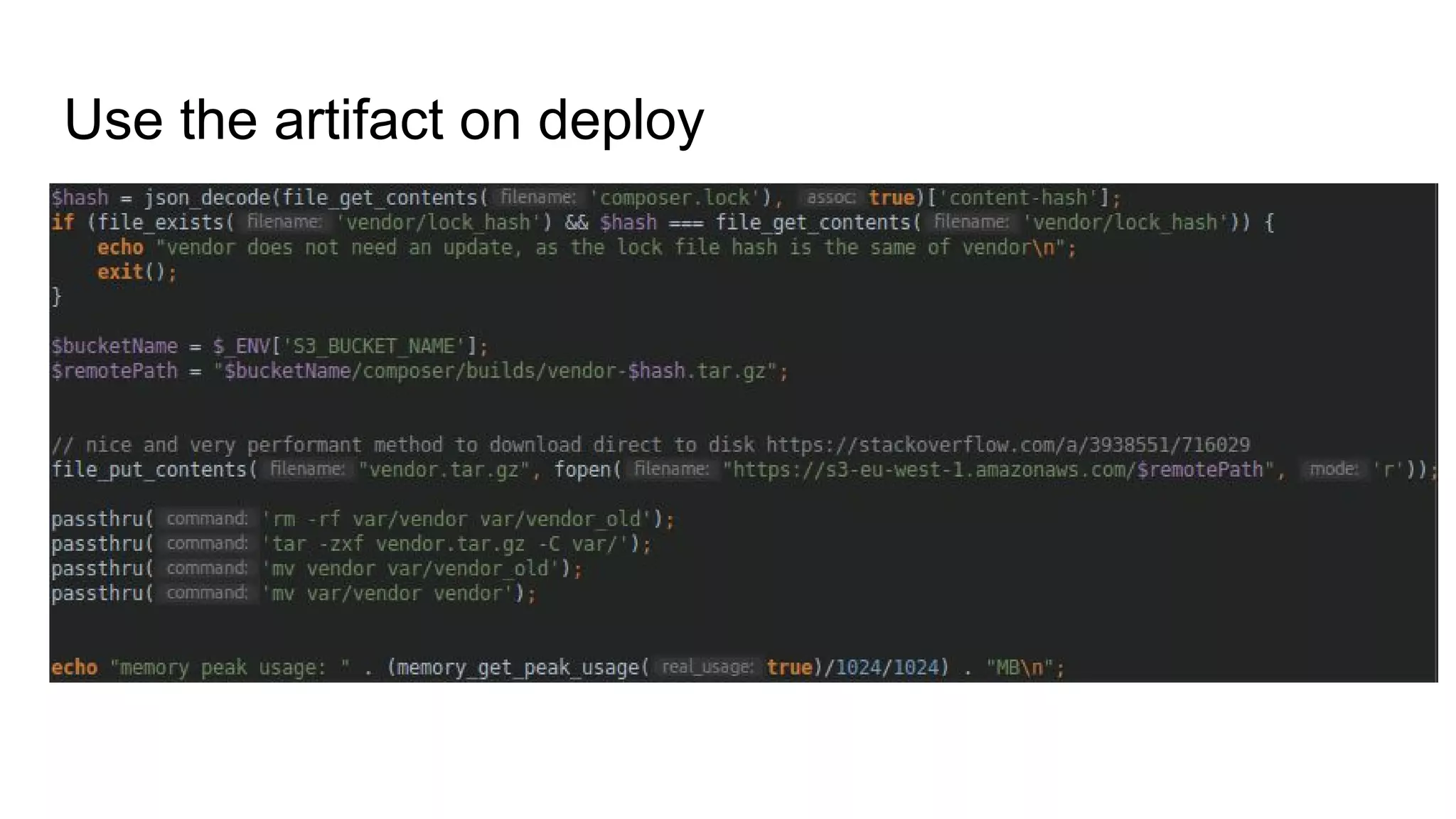
This document summarizes steps to improve the software deployment process. It recommends using Git for deployment to enable faster switching between versions. It also discusses techniques like blue/green deployments to prevent errors from file changes during requests and maintaining two identical environments that can be switched between. The document stresses the importance of making database migrations harmless and avoiding code that doesn't work without migrations. It provides tips for measuring deployment success and reducing fear of deployments.