Downloaded 12 times











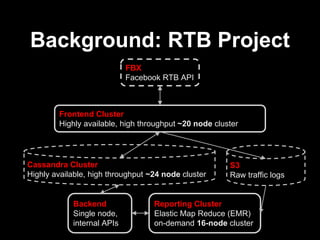








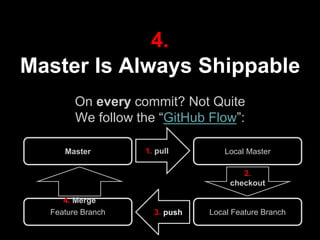


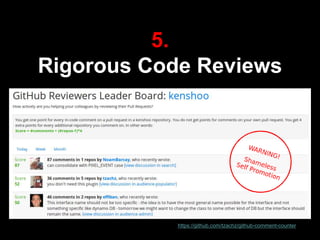
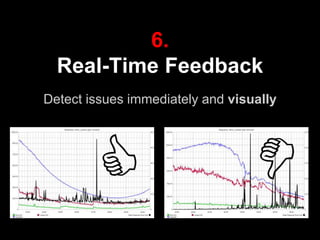
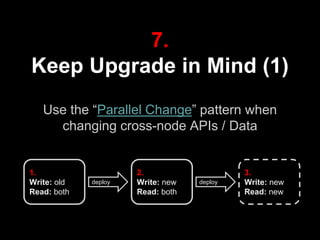







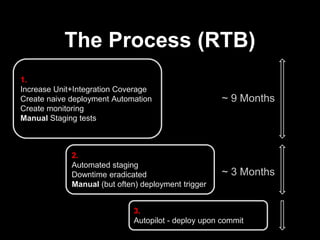

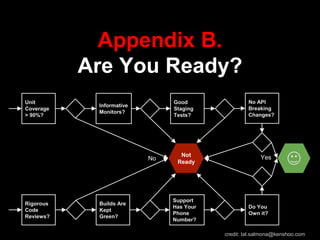


The document discusses continuous delivery (CD) principles and practices within Kenshoo's real-time bidding (RTB) project, emphasizing its importance in delivering incremental changes to users. It outlines a practical approach to CD, including ten field-tested tips such as full deployment automation, rigorous code reviews, and maintaining stable builds. The document also highlights the technical and organizational setup of the RTB project, which involved a small team and a robust infrastructure to achieve high availability and responsiveness.






















































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)












